一、前言
此示例演示如何使用计算机视觉工具箱中的函数执行光学字符识别。
二、实例
识别图像中的文本在许多计算机视觉应用程序中非常有用,例如图像搜索、文档分析和机器人导航。该函数提供了一种将文本识别功能添加到各种应用程序的简单方法。

函数返回已识别的文本、识别置信度以及文本在原始图像中的位置。您可以使用此信息来标识图像中错误分类文本的位置。

在这里,名片中的徽标被错误地归类为文本字符。在进行任何进一步处理之前,可以使用置信度值识别这些类型的 OCR 错误。
三、获得准确结果的挑战
ocr当文本位于统一背景上并且格式类似于浅色背景上带有深色文本的文档时,性能最佳。当文本出现在不均匀的深色背景上时,需要额外的预处理步骤才能获得最佳 OCR 结果。在示例的这一部分中,您将尝试在键盘上定位数字。虽然键盘图像对于 OCR 来说似乎很容易,但实际上非常具有挑战性,因为文本位于不均匀的深色背景上。

空表示无法识别任何文本。在键盘图像中,文本稀疏且位于不规则背景上。在这种情况下,用于内部文档布局分析的启发式方法可能无法在图像中找到文本块,因此文本识别失败。在这种情况下,使用该参数禁用自动布局分析可能有助于改进结果。
调整参数没有帮助。要了解 OCR 继续失败的原因,您必须调查在 中执行的初始二值化步骤。您可以使用 来检查此初始二值化步骤,因为两者和默认的“全局”方法都使用 Otsu 的图像二值化方法。

阈值化后,二进制图像不包含任何文本。这就是为什么无法识别原始图像中的任何文本的原因。您可以通过预处理图像来改进文本分割来帮助改进结果。示例的下一部分将探讨两种有用的预处理技术。
四、改善结果的图像预处理技术
上面看到的糟糕的文本分割是由图像中的不均匀背景引起的,即浅灰色键被深灰色包围。您可以使用以下预处理技术来删除背景变体并改进文本分割。

删除背景变体后,数字现在在二进制图像中可见。但是,按键边缘和数字旁边的小文本有一些伪影,可能会继续阻碍整个图像的准确 OCR。

现在,反转干净的二值化图像,以在浅色背景上生成包含深色文本的图像,以便进行 OCR。

在这些预处理步骤之后,数字现在与背景很好地分割并产生一些结果。
除了少数字符外,结果看起来基本上不准确。这是由于键盘中字符大小的差异导致自动布局分析失败。
改善结果的一种方法是利用有关图像中文本的先验知识。在此示例中,您感兴趣的文本仅包含数字和 '*#' 字符。您可以通过限制仅从集合“0123456789*#”中选择最佳匹配来改进结果。
结果现在更好,并且仅包含给定字符集中的字符。但是,识别结果中仍然缺少图像中感兴趣的字符。
五、基于投资回报率的处理以改善结果
为了进一步改善这种情况下的识别结果,请确定图像中应处理的特定区域。在键盘示例图像中,这些区域将是仅包含数字、* 和 # 字符的区域。您可以使用 手动选择区域,也可以自动执行该过程。

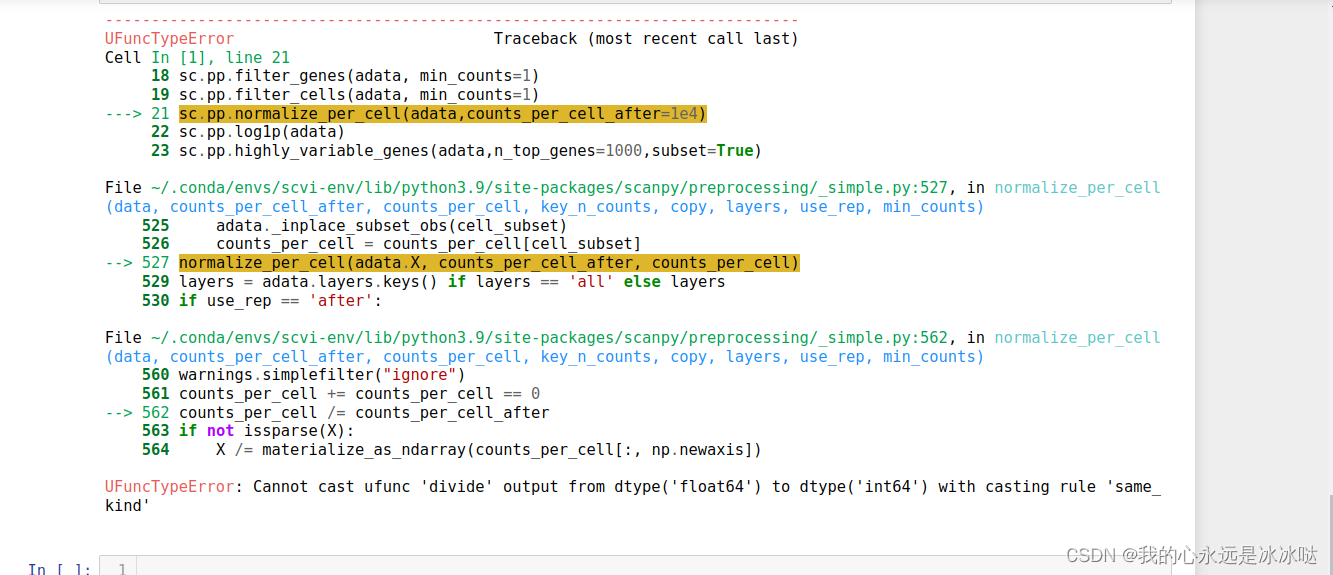
此示例中感兴趣的最小字符是数字“1”。使用其区域过滤任何异常值。

基于区域的纵横比进行进一步处理,以识别可能包含单个字符的区域。这有助于删除数字旁边混杂在一起的较小文本字符。通常,文本越大越容易识别。

其余区域可以传递到函数中,该函数接受感兴趣的矩形区域作为输入。区域的大小略有增加,以在文本字符周围包含其他背景像素。这有助于改进用于确定背景上文本极性的内部启发式方法(例如,深色背景上的浅色文本与浅色背景上的深色文本)。
通过设置为“无”来禁用自动布局分析。手动提供ROI输入时,设置为“块”,“单词”,“文本行”,“字符”或“无”可能有助于改善结果。需要实证分析来确定最佳布局分析值。
可以使用 在原始图像上显示识别出的文本。该函数用于删除任何尾随字符,例如空格或换行符。

虽然使您能够在键盘图像中找到数字,但它可能不适用于除文本之外还有许多对象的自然场景图像。
六、总结
此示例展示了如何使用该功能来识别图像中的文本,以及看似简单的 OCR 图像如何需要额外的预处理步骤才能产生良好的结果。
七、程序
使用Matlab R2022b版本,点击打开。(版本过低,运行该程序可能会报错)
程序下载:基于matlab使用光学字符识别技术识别文本资源-CSDN文库