一、事务 ACID 原则
什么是事务呢?事务通常是一个或一组 SQL 组成的,组成一个事务的 SQL 一般都是一个业务操作,例如下单操作:【扣库存数量、增加订单详情记录、插入物流信息】,这一组 SQL 就可以组成一个事务。
而数据库的事务一般也要求满足 ACID 原则,ACID 是关系型数据库实现事务机制时必须要遵守的原则。
ACID 主要涵盖四条原则,即:
-
A / Atomicity:原子性
-
C / Consistency:一致性
-
I / Isolation:独立性 / 隔离性
-
D / Durability:持久性
那这四条原则分别是什么意思呢?
1.1、Atomicity 原子性
指组成一个事务的一组 SQL 要么全部执行成功,要么全部执行失败,事务中的一组 SQL 会被看成一个不可分割的整体,当成一个操作看待。只要其中任意一条 SQL 执行失败,此时就会导致该事务中的所有操作全部失败。
1.2、Consistency 一致性
一个事务中的所有操作,要么一起改变数据库中的数据,要么都不改变,举个栗子:
假设此时有一个事务 A,这个事务隶属于一个下单操作,由【1扣库存数量、2增加订单详情记录、3插入物流信息】这三条 SQL 操作组成。
一致性的含义是指:在这个事务执行前,数据库中的数据是处于一致性状态的,而 SQL 执行完成之后事务提交,数据库中的数据依旧处于一个“一致性状态”,也就是库存数量 + 订单数量永远是等于最初的库存总数的,比如原本的总库存是 10000个,此时库存剩余 8888 个,那也就代表着必须要有 1112 条订单数据才行。不可能说库存减了,但订单没有增加,这样就会导致数据库整体数据出现不一致。
如果出现库存减了,但订单没有增加的情况,就代表着事务执行过程中出现了异常,此时 MySQL 就会利用事务回滚机制,将之前减得库存再加回去,确保数据的一致性。
1.3、Isolation 独立性 / 隔离性
指多个事务之间都是独立的,相当于每个事务都被装在一个箱子中,每个箱子之间都是隔开的,相互之间并不影响,同样上个栗子
假设数据库的库存表中,库存数量剩余8888个,此时有 A、B 两个并发事务,这两个事务都是相同的下单操作,由【1扣库存数量、2增加订单详情记录、3插入物流信息】这三条 SQL 操作组成。
此时A、B 两个事务一起执行,同一时刻执行减库存的 SQL,因为这里是并发执行的,那两个事务之间是否会相互影响,导致扣的是同一个库存呢?答案是不会,ACID 原则中的隔离性保障了并发事务的顺序执行,一个未完成事务不会影响另外一个未完成事务。
隔离性在底层是如何实现的呢?基于 MySQL 的锁机制和 MVCC 机制做到的。
1.4、Durability 持久性
指一个事务一旦被提交,它会保持永久性,所更改的数据都会被写入到磁盘做持久化处理,就算 MySQL 宕机也不会影响数据改变,因为宕机也可以通过日志恢复数据。
二、MySQL 的事务机制综述
刚刚说到的 ACID 原则是数据库事务的四个特性,也可以理解为实现事务的基础理论,那接下来一起看看 MySQL 所提供的事务机制。在 MySQL 默认情况下,一条 SQL 会被视为一个单独的事务,同时也无需我们手动提交,因为默认是开启事务自动提交机制的,如若你想要将多条 SQL 组成一个事务执行,那需要显示的通过一些事务指令来实现。
2.1、手动管理事务
在 MySQL 中,提供了一系列事务相关的命令,如下:
-
Start transaction | begin | begin work:开启一个事务
-
commit:提交一个事务
-
rollback:回滚一个事务
-- 开启一个事物
start transaction;
-- 第一条 sql 语句
-- 第二条 sql 语句
-- 第三条 sql 语句
-- 提交或回滚事物
commit || rollback开启事务后一定要做提交或回滚处理,,事务是基本当前数据库连接的,每个连接之间的事务是具备隔离性的。
我们经常用的 Navicat 数据库可视化工具,新建两个查询,新建一个查询时,本质上他就是给你建立了一个数据库连接,每一个新查询都是一个新的连接。
-- 先查询一次表数据
select * from student;
-- 开启事物
start transaction;
-- 修改 id=3的姓名为:熊猫
update student set name = '熊猫'
-- 删除 id=1 的数据
delete from student where id = 1;
-- 再次查询一次数据
select * from student;观察上面的结果,对比开启事务前后的表数据查询,在事务中分别修改、删除一条数据后,再次查询表数据时会观察到表数据已经变化,此时再去查询窗口2中查询表数据
-- 查询表数据
select * from student;观察结果,还是原来的三条完整数据。在查询窗口2中,也就相当于在第二个连接中查询数据时,会发现第一个连接(窗口1)改变的数据并未影响到第二个连接,啥原因呢?这是因为窗口1中还未提交事务,所以第一个连接改变的数据不会影响第二个连接。
其实具体的原因是由于 MySQL 事务的隔离机制造成的。
此时在查询窗口1中,输入 rollback 命令,让当前事务回滚:
-- 回滚当前连接中的事务
rollback;
-- 再次查询一次数据
select * from student;结果很明显,当事务回滚后,之前所做的数据更改操作全部都会撤销,恢复到事务开启前的表数据。
-- 查看 自动提交事务 是否开启
show variables like 'autocommit';
-- 关闭或开启自动提交
set autocommit = 0|1|ON|OFF;上述的 【0/ON】是相同的意思,表示开启自动提交,【1/OFF】则表示关闭自动提交。
2.3、MySQL 事务的隔离机制
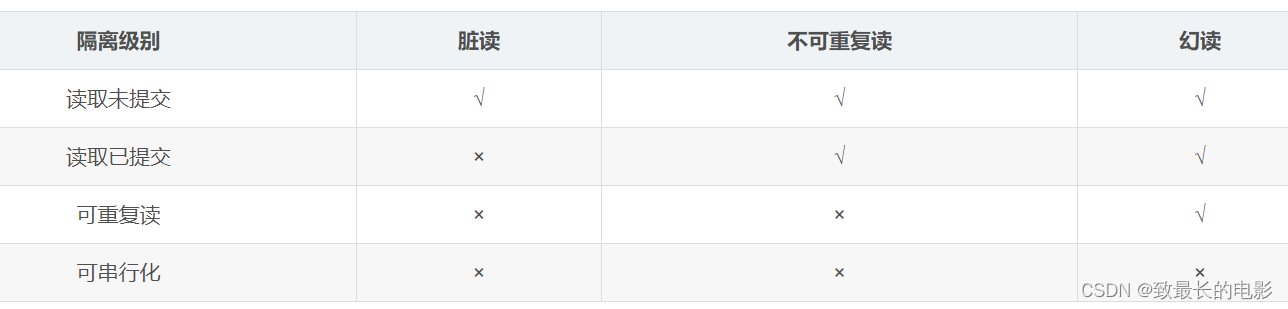
在前面做的小测试中,我们会发现不同的数据库连接中,一个连接的事务并不会影响其他连接,这是基于事务隔离机制实现的,其实在 MySQL 中,事务隔离机制分为了四个级别:
-
Read uncommitted / RU:读未提交
-
Read committed / RC:读已提交
-
Repeatable read / RR:可重复读 (MySQL 默认级别)
-
Serializable:序列化 / 串行化
上述四个级别,越靠后并发控制度越高,也就是在多线程并发操作的情况下,出现问题的几率越小,但对应的也性能越差,MySQL 的事务隔离级别,默认为第三级别:Repeatable read / RR:可重复读,但如若想要真正理解这几个隔离级别,得先明白几个因为并发操作造成的问题。
2.3.1、脏读、不可重复读、幻读问题(严重性从高到低)
2.3.1.1、数据库的脏读问题(读到其他事务未提交的数据):
首先来看一下脏读,脏读的意思是指一个事务读到了其他事物还未提交的数据,也就是当前事务读到的数据,由于还未提交,因此有可能会回滚,如下:

比如上图中,DB 连接 1/ 事务A正在执行下单业务,目前扣减库存、增加订单两条 SQL 已经完成了。恰巧此时 DB 连接2 / 事务B跑过来读取了一下库存剩余数量,就将事务 A已经扣减之后的库存数量读回去了。但好巧不巧,事务 A 在添加物流信息时,执行异常导致事务 A 全部回滚,也就是原本扣的库存又会增加回去。这个过程被称为数据库脏读问题。这个问题很严重,会导致整个业务系统出现问题,数据最终错乱。
2.3.1.2、数据库的不可重复读问题(前后读取的数据不一致):
不可重复读问题是指在一个事务中,多次读取同一数据,先后读取到的数据不一致,如下:
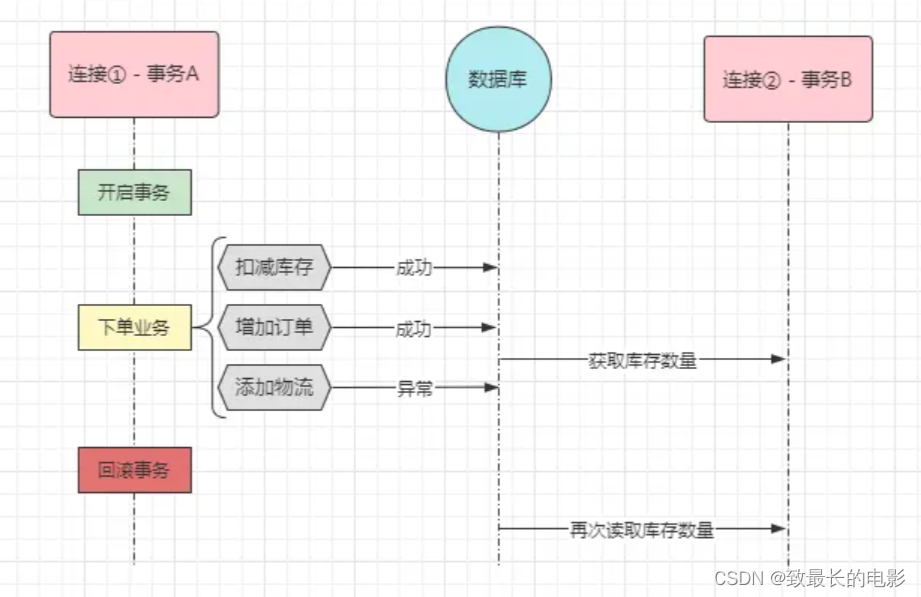
对前面那张图稍微做了一点改造,事务 A 在添加物流信息的时候出错了,导致整个事务回滚,事务 A 就结束了。但事务 B 却并未结束,在事务 B 中,在事务 A执行时读取了一次剩余库存,然后再事务回滚后又读取了一次剩余库存,仔细想一下:B 事务第一次读到的剩余库存是扣减之后的,第二次读到的剩余库存则是扣减之前的(因为 A 事务回滚又加回去了)
在上述这个案例中,同一个事务中读取同一数据,结果却并不一致,也就说明了该数据存在不可重复读问题。相对应的,可重复读的意思是:在同一事务中,不管读取多少次,读到的数据都是相同的。
2.3.1.3、数据库幻读问题(前后读取的记录数不一致):
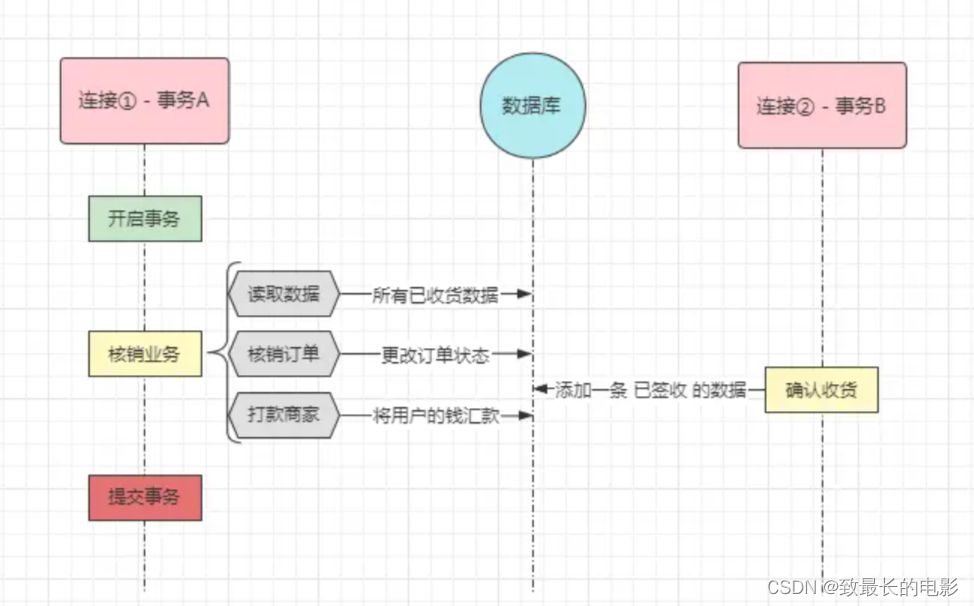
这是一个电商的大致逻辑,一般用户购买商品后付的钱会先冻结在平台上,然后由平台在固定的时间内结算用户款,例如七天一结算、半月一结算等方式,在结算业务中通常都会涉及到核销处理,也就是将所有为【已签收状态】的订单改为【已核销状态】。
此时假设连接 1 / 事务A 正在执行【半月结算】这个工作,那首先会读取订单表所有状态为【已签收】的订单,并将其更改为【已核销】状态,然后将用户款打给商家。但此时恰巧,某个用户的订单正好到了自动确认收货的时间,因此在事务 A 刚刚改完表中订单的状态时,事务 B 又向表中插入了一条【已签收状态】的订单并提交了,当事务 A 完成打款后,再次查询订单表,结果会发现表中还有一条【已签收状态】的订单数据未结算,这就好像产生了幻觉一样。
发生幻读问题的原因是在于:另外一个事务在第一个事务要处理的目标数据范围之内新增了数据,然后先于第一个事务提交造成的问题。
幻读demo:
客户端1:
begin;
// 首次查询(数据为空)
select * from student where id = 5;
// 更新id = 5的这条数据
update student set name = 'hahah' where id = 5;
// 再次查询 id = 5这条记录(有数据)
select * from student where id = 5;
commit;客户端2:
begin;
// 插入id = 5这条数据
insert into student VALUES(6, '小花6', 30, '17766665555', NOW());
commit;解决幻读措施:
在客户端1,首次查询增加 for update; ,通过 next-key lock(记录锁+间隙锁)方式解决了幻读。
2.3.2、事务的四大隔离级别(隔离级别越高,性能效率就越低)
在上面连续讲了脏读、不可重复读以及幻读三个问题,那这些问题该怎么解决呢?其实四个事务隔离级别,解决的实际问题就是这三个,因为一起来看看个级别分别解决了什么问题:
前面提到过,MySQL 默认是处于第三级别的,可以通过如下命令查看目前数据库的隔离级别:
-- 查看方式
show variables like 'transaction_isolation';
-- 设置隔离级别为RU级别(当前连接生效)
set transaction isolation level read uncommitted;
-- 设置隔离级别为RC级别(全局生效)
set global transaction isolation level read committed;其实数据库不同的事务隔离级别,是基于不同类型、不同粒度的锁实现的,因为想要真正搞懂隔离机制,还需要弄明白 MySQL 的锁机制,事务与锁机制二者之间本身就是相辅相成的关系,锁就是为了解决并发事务的一些问题而存在的。
事务是基于数据库连接的,数据库连接本身会有一条工作线程来维护,也就是说事务的执行本质上就是工作线程在执行,因为所谓的并发事务也就是指多线程并发执行。因此结合多线程角度来看,脏读、不可重复读、幻读这一系列问题,本质上就是一些线程安全问题,因此需要通过锁来解决,而根据锁的粒度、类型,又分出了不同的事务隔离级别。
2.3.2.1、读未提交级别:
这种隔离级别是基于【写互斥锁】实现的,当一个事务开始写某一个数据时,另外一个事务也来操作同一个数据,此时为了防止出现问题则需要先获取锁资源,只有获取到锁的事务,才允许对数据进行写操作,同时获取到锁的事务具备排他性 / 互斥性,也就是其他线程无法再操作这个数据。
但虽然这个级别中,写同一数据时会互斥,但读操作却并不是互斥的,也就是当一个事务在写某个数据时,就算没有提交事务,其他事务来读取该数据时,也可以读到未提交的数据,因此就会导致脏读、不可重复读、幻读一系列问题出现。
但是由于在这个隔离级别中加了【写互斥锁】,因此不会存在多个事务同时操作同一数据的情况,因此这个级别中解决了前面说到的脏写问题。
2.3.2.2、读已提交级别:
在这个隔离级别中,对于写操作同样会使用【写互斥锁】,也就是两个事务操作同一数据时,会出现排他性,而对于读操作则使用了一种名为 MVCC 多版本并发控制的技术处理,也就是有事务中的 SQL 需要读取当前事务正在操作的数据时,MVCC 机制不会让另一个事务读取正在修改的数据,而是读取上一次提交的数据(也就是读原本的老数据)。
举一个栗子:事务 A 的主要工作是负责更新 ID = 1 的这条数据,事务 B 中则是读取 ID = 1的这条数据。此时当 A 正在更新数据但还未提交时,事务 B 开始读取数据,此时 MVCC 机制则会基于表数据的快照创建一个 ReadView ,然后读取原本表中上一次提交的老数据。然后等事务 A 提交之后,事务 B 再次读取数据,此时 MVCC机制又会创建一个新的 ReadView,然后读取到最新的已提交的数据,此时事务 B 中两次读到的数据并不一致,因此出现了不可重复读问题。
2.3.2.3、可重复读级别:
在这个隔离级别中,主要就是解决上一个级别中遗留的不可重复读问题,但 MysQL 依旧是利用 MVCC 机制来解决这个问题的,只不过在这个级别的 MVCC 机制会稍微有些不同。
在可重复读级别中,则不会每次查询时都创建新的 ReadView,而是在一个事务中,只有第一次执行查询会创建一个 ReadView,在这个事务的生命周期内,所有的查询都会从这一个 ReadView 中读取数据,从而确保了一个事务中多次读取相同数据是一致的,也就是解决了不可重复读。
虽然在这个隔离级别中,解决了不可重复读问题,但依旧存在幻读问题,也就是事务 A 在对表中多行数据进行修改,比如前面的举例,将性别【男、女】改为【0、1】,此时事务 B 又插入了一条性别为男的数据,当事务 A提交后,再次查询表时,会发现表中依旧存在一条性别为男的数据。
2.3.2.4、序列化 / 串行化级别:
这个隔离级别是最高的级别,处于该隔离级别的 MySQL 绝不会产生任何问题,因为从它的名字上就可以得知:序列化意思是将所有的事务按序排队后串行化处理,也就是操作同一张表的事务只能一个一个执行,事务在执行前需要先获取表级别的锁资源,拿到锁资源的事务才能执行,其余事务则陷入阻塞,等待当前事务释放锁。
这种隔离级别解决问题的思想很简单,产生一系列问题的根本原因在于:多事务 / 多线程并发执行导致的,那在这个隔离级别中,直接将多线程化为了单线程,自然也就从根源上避免了问题产生。虽然我解决不了问题,但我可以直接解决制造问题的人。
2.3.2 、总结:
多线程并发执行自然就会出问题,也就是聊到的脏写、脏读、不可重复读以及幻读问题,而对于这些问题又可以通过调整事务的隔离级别来避免,那为什么调整事务的隔离级别后能避免这些问题产生呢?这是因为不同的隔离级别中,工作线程执行SQL语句时,用的锁粒度、类型不同。也就是说,数据库的锁机制本身是为了解决并发事务带来的问题而诞生的,主要是确保数据库中,多条工作线程并行执行时的数据安全性。