本文涉及源码基于kotlinx-coroutines-core-jvm:1.7.1
kotlin 协成系列文章:
你真的了解kotlin中协程的suspendCoroutine原理吗?
Kotlin Channel系列(一)之读懂Channel每一行源码
kotlin Flow系列之-SharedFlow源码解析
kotlin Flow系列之-StateFlow源码解析
Kotlin Flow系列之-ChannelFlow源码解析之 -操作符 buffer & fuse & flowOn线程切换
文章目录
- 目标
- 一,初识SafeFlow
- 二,SafeFlwo创建以及collect调用流程
- 三,何为Safe
- SafeCollector源码
目标
通过本文的学习你将掌握以下知识:
- 对冷流SafeFlow的基本使用
- 从通过flow{}函数创建,到collect整个调用流程
- SafeFlow中的Safe是什么意思?这里的安全是指的什么方面的安全
一,初识SafeFlow
一个简单的Flow实例:
flow<Int> {
emit(1)
}.collect{
println(1)
}
flow()函数:
public fun <T> flow(@BuilderInference block: suspend FlowCollector<T>.() -> Unit): Flow<T> = SafeFlow(block)
flow()函数接收一个带接收者FlowCollector的suspend Function. 返回一个SafeFlow:
//FlowCollector
public fun interface FlowCollector<in T> {
public suspend fun emit(value: T)
}
//SafeFlow
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {
override suspend fun collectSafely(collector: FlowCollector<T>) {
collector.block()
}
}
SafeFlow继承了AbstractFlow:
@FlowPreview
public abstract class AbstractFlow<T> : Flow<T>, CancellableFlow<T> {
public final override suspend fun collect(collector: FlowCollector<T>) {
val safeCollector = SafeCollector(collector, coroutineContext)
try {
collectSafely(safeCollector)
} finally {
safeCollector.releaseIntercepted()
}
}
public abstract suspend fun collectSafely(collector: FlowCollector<T>)
}
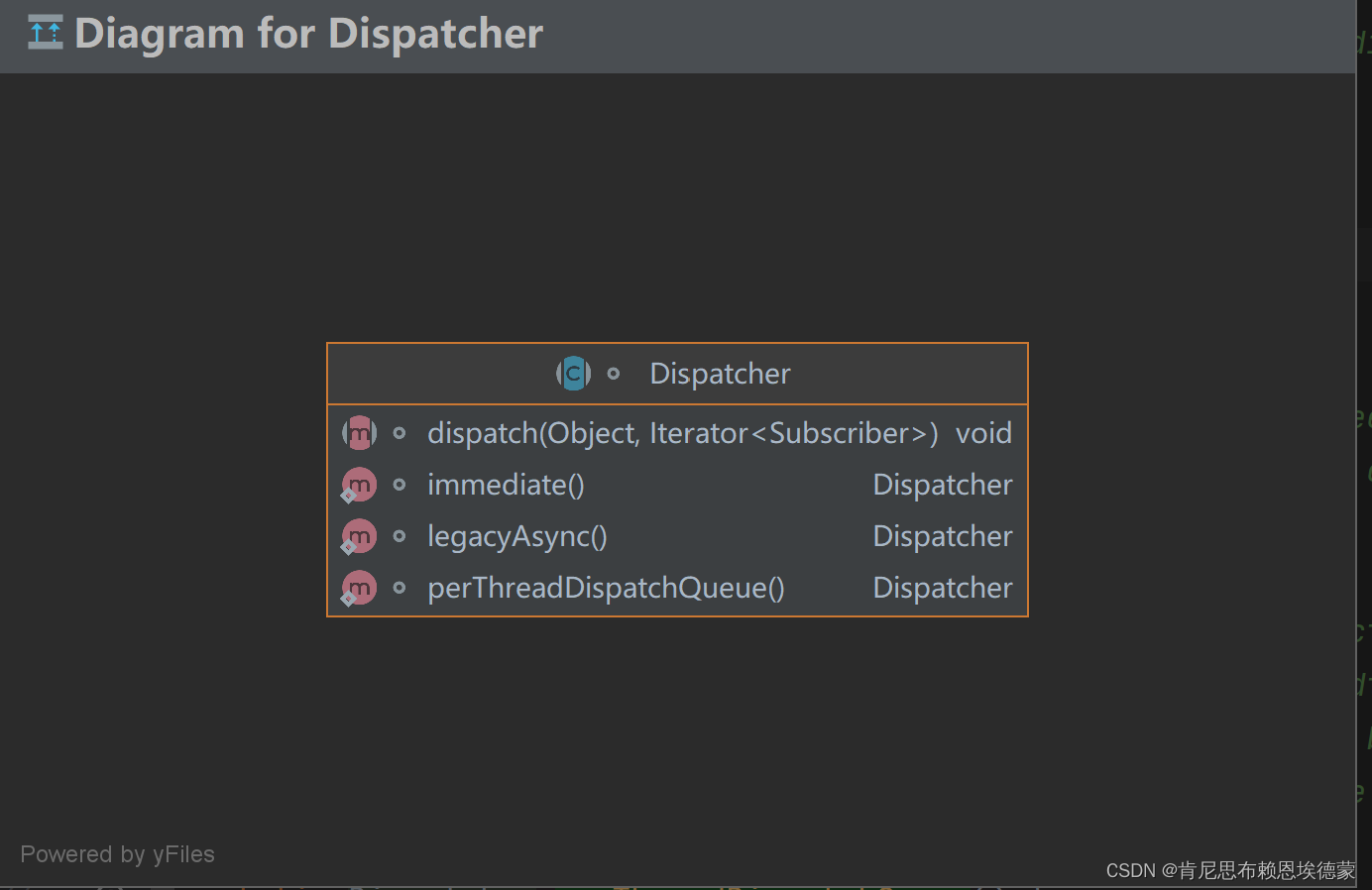
AbstractFlow实现了两个接口Flow 和 CancellableFlow<out T>
public interface Flow<out T> {
public suspend fun collect(collector: FlowCollector<T>)
}
internal interface CancellableFlow<out T> : Flow<T>
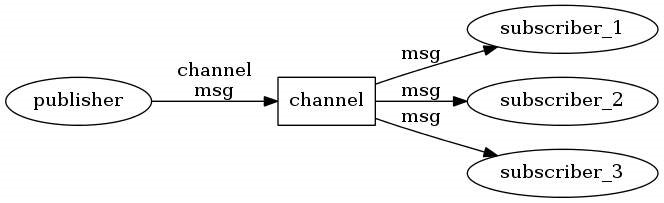
他们之间的关系类图:

Flow的思想很简单,就是一个流,分为上游和下游,上游数据生产者,下游数据消费者。上游生成数据,然后把数据交给下游。如果把Flow比作上游,那么FlowCollector就是下游。Flow自己没有生产数据的功能,真正生成数据的是调用flow()函数时传进去的Function : block: suspend FlowCollector<T>.() -> Unit,
调用上游Flow的collect方法传入一个FlowColletor对象,这样就把下游和上游对接上,上游开始工作。
Step1:当我们调用flow()方法,并传入一个Function后,就返回了一个Flow的子类SafeFlow对象,SafeFlow持有Function的引用,这样Flow就可以通过Function来生成数据了。到此完成了上游的创建。
val upStream = flow{
emit(1)
}
//上面的代码拆开来看,
//1先定义一个suspend 的Function类型,真正生产数据的是它
val realProducer : suspend FlowCollector<Int>.() -> Unit = {flowCollector ->
//生成数据
val data = 1
//把数据交给下游
flowCollector.emit(data)
}
//2.调用flow函数,传入function,获得了一个Flow对象。·
val upStream = flow<Int>(realProducer)
Step2:调用Flow的collect()函数,传入一个FlowCollector打通上下游。
upStream.collect{
println(it)
}
//代码拆开
//1.创建一个FlowCollector作为下游消费者
val downStream = object : FlowCollector<Int>{
override suspend fun emit(value: Int) {
println(value)
}
}
//2.通过Flow的collect方法打通上下游
upStream.collect(downStream)
二,SafeFlwo创建以及collect调用流程
通过基本认识中,我们知道了什么是上游,下游,以及如何把上下游打通。Flow是一个冷流,也可以叫做懒流,其意思就是Flow只有在使用它的时候才会工作。也就是说只调用了Flow.collect()函数,Flow才开始生产工作(创建Flow时传入的Function才开始执行)。上游为每一个下游消费者单独启动(执行Function的的代码)接着上面的代码。我们进入源码继续分析:
Step1:flow<Int>(realProducer) 通过flow函数传入名为realProducer的Function创建一个流:
//直接实例化了一个SafeFlow对象返回,并把realProducer作为SafeFlow构造函数参数传入
public fun <T> flow(@BuilderInference block: suspend FlowCollector<T>.() -> Unit): Flow<T> = SafeFlow(block)
发现flow{}函数返回了一个SafeFlow对象:
//block作为SafeFlow的私有属性。这里的block 就是是realProducer
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {
override suspend fun collectSafely(collector: FlowCollector<T>) {
collector.block()
}
}
在实例化SafeFlow对象时,realProducer作为构造函数参数传给了SafeFlow,被SafeFlow的block属性持有。这样就相当与SafeFlow持有了realProducer的引用。realProducer作为一个Function,具有生产数据的能力,也就是说SafeFlow就可以调用realProducer来生产数据了,这就意味着一个具备生产能力的上游被构造好了。
Step2: 调用upStream.collect(collector),打通上下游,upStream 实际上是一个SafeFlow,SafeFlow代码中并没有重写collect()方法,继续往上找。找到父类AbstractFlow。发现其重写了collect()方法:
public abstract class AbstractFlow<T> : Flow<T>, CancellableFlow<T> {
//所以upStream.collect(collector)真正调用到了此处,参数就是我们传进来的downStream
public final override suspend fun collect(collector: FlowCollector<T>) {
//downStream作为构造函数参数被SafeCollector持有
//这里为什么要用SafeCollector?在西面”何为Safe“小结里面会讲解。
val safeCollector = SafeCollector(collector, coroutineContext)
try {
//step3:接通上下游
collectSafely(safeCollector)
} finally {
safeCollector.releaseIntercepted()
}
}
public abstract suspend fun collectSafely(collector: FlowCollector<T>)
}
在collect()方法中,发现传进去的downStream对象并没有直接和上游对接,而是被进行了一次包装或者代理,变成了一个SafeCollector对象。由SafeCollector对象和上游Flow对接。Flow中生成的数据交给了SafeCollector。然后在由SafeCollector交给我们下游也就是downStreamd对象。SafeCollector是FlowCollector的子类,同时它内部有一个colletor的属性,持有了我们下游的引用:
internal actual class SafeCollector<T> actual constructor(
@JvmField internal actual val collector: FlowCollector<T>, //指向下游
@JvmField internal actual val collectContext: CoroutineContext
) : FlowCollector<T>, ContinuationImpl(NoOpContinuation, EmptyCoroutineContext), CoroutineStackFrame {
}
到此真正的下游downStream被包装成了一个SafeCollector对象。
Step3:collectSafely(safeCollector)把包装好的下游对象和上游对接上。collectSafely()方法在SafeFlow中被重写:
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {
//collectSafely(safeCollector)方法调用了此处,参数为包装后的下游
override suspend fun collectSafely(collector: FlowCollector<T>) {
//此处的block就是realProducer。负责生产数据。
//此处的colector就是包装后的SafeCollector.
//开始调用block指向的Function,
collector.block()//相当于 block(collector)
}
}
包装后的SafeCollector作为参数传给了Flow中真正用来生产数据的Function。这样Function内部就可以通过调用SafeCollector的emit方法把数据交给SafeCollector:
val realProducer : suspend FlowCollector<Int>.() -> Unit = { flowCollector ->
//生成数据
val data = 1
//flowCollector实际上就是SafeCollector
flowCollector.emit(data)
}
Step4:flowCollector.emit(data) 生产数据的Function。把数据生成好后,交给了SafeCollector对象:
internal actual class SafeCollector<T> actual constructor(
@JvmField internal actual val collector: FlowCollector<T>,//指向真正的下游对象
@JvmField internal actual val collectContext: CoroutineContext
) : FlowCollector<T>, ContinuationImpl(NoOpContinuation, EmptyCoroutineContext), CoroutineStackFrame {
//flowCollector.emit(data)调用该方法。
override suspend fun emit(value: T) {
return suspendCoroutineUninterceptedOrReturn sc@{ uCont ->
try {
//继续调用,先不用管协第一个参数,
emit(uCont, value)
} catch (e: Throwable) {
lastEmissionContext = DownstreamExceptionContext(e, uCont.context)
throw e
}
}
}
//继续调用了此处
private fun emit(uCont: Continuation<Unit>, value: T): Any? {
val currentContext = uCont.context
currentContext.ensureActive()
val previousContext = lastEmissionContext
if (previousContext !== currentContext) {
checkContext(currentContext, previousContext, value)
lastEmissionContext = currentContext
}
completion = uCont
//相当于调用了下游对象的emit方法。collector指向的就是下游真正的对象。
val result = emitFun(collector as FlowCollector<Any?>, value, this as Continuation<Unit>)
if (result != COROUTINE_SUSPENDED) {
completion = null
}
return result
}
}
//emitFun是FlowCollctor的emit方法的一个引用。
private val emitFun =
FlowCollector<Any?>::emit as Function3<FlowCollector<Any?>, Any?, Continuation<Unit>, Any?>
emitFun 指向了真正的下游的emit方法:
val downStream = object : FlowCollector<Int>{
//emitFun执行了该emit方法
override suspend fun emit(value: Int) {
//下游消费上游的数据。
println(value)
}
}
到此一个最基础版的Flow的上游下游的创建,生产消费过程就完成了。

三,何为Safe
在官方的文档中对实现Flow子类(cold flow)提出了两点约束:

关于这两点的详细解释,感兴趣的可以自行车查阅官网文档:
第一点 Context preservation:
意思就是说上游发送和下游接收(直接下游)只能运行在同一个CoroutineContext(协成上下文)里面。fowOn是唯一可以切换上游下游在不同context的方式。
al myFlow = flow {
// GlobalScope.launch { // 禁止
// launch(Dispatchers.IO) { // 禁止
// withContext(CoroutineName("myFlow")) { // 禁止
emit(1) // OK
coroutineScope { //这个相当于创建了一个作用于,同样的supervisorScope也可以
emit(2) // OK -- 可以,仍然是同一个协成
}
}
简而言之,flow{}里面的emit必须是顺序发送的,不能并发发送。如果想要实现上下游在不同context里面可以使用channelFlow来创建流。
注意,这里指的上游和下游在同一个协成上下文里面。在kotlin里面,不要把协成和线程混为一谈,比如:
suspend fun main() {
val flow = flow<Int> {
log("emit 1")
emit(1)
log("emit 2")
emit(2)
}
flow.collect {
log("receive $it")
delay(1000)
}
Thread.sleep(1000000)
}
//
20:35:45:018[ main ] emit 1
20:35:45:051[ main ] receive 1
20:35:46:071[ kotlinx.coroutines.DefaultExecutor ] emit 2
20:35:46:071[ kotlinx.coroutines.DefaultExecutor ] receive 2
上面代码collect 和 emit 运行的协成的context 为 EmptyCouroutinecContext,emit(1) 和emit(2) 不在同一个线程。
第二点 Exception transparency:
当emit或者emitAll发生异常(也就是下游处理数据时发生异常),上游必须停止继续发送新的数据,并以异常结束。流的实现永远不要捕获或者处理下游流中发生的异常。 从实现的角度来看,这意味着永远不要将对 emit 和 emitAll 的调用包裹在 try {…} catch {…} 块中。 流中的异常处理应由 catch 运算符执行,并且旨在仅捕获来自上游流的异常,而传递所有下游异常。 类似地,终端运算符如 collect 会抛出在其代码或上游流中发生的任何未处理的异常,例如:
flow { emitData() }
.map { computeOne(it) }
.catch { ... } // 能捕获上游 computeOne 和emitData里面的溢出
.map { computeTwo(it) }
.collect { process(it) } //抛出未被处理的溢出,比如process 和 computeTow中发生了未捕获的溢出。
在前面我们知道了flow{}函数返回了一个SafeFlow,一个安全的流,安全是指的哪方面安全?是线程安全吗?答案不是的。这里的安全有两点,第一是指emit数据发送顺序的安全(禁止并发emit),第二下游发生了异常,即使在上游try catch了,也不会继续emit。如果你写的代码让emit和collect不是在同一个coroutine里面,那就是不安全的,就会抛异常。比如说:
- 顺序发送,禁止并发送
//加入说代码可以这样写,那就会存在下游先收到数据3。实际上这样写了会抛出一个异常:
val flow<Int>{
emit(1)
launch(Dispatchers.IO){
//TODO 做一些复杂的计算,需要销号一定的时间
emit(2)
}
emit(3)
}

这个异常信息里面也说的比较明白
Flow invariant is violated: //违背了流的不可改变的特性
//检查到了emit在别的协成被调用(意思就是不是collect函数所在的协成)
Emission from another coroutine is detected.
//emit被调用在StandaloneCoroutine这个Job里面。emit期望的是调用在BlockingCoroutine这个Job里面。
//launch启动的协成的Job是StandaloneCoroutine
//collec函数运行在runBlockiing代码块里面,因此Job为BlockingCoroutine
//在抛出异常的代码里面是通过 === 来比较两个Job的,所以你就算把collect调用写在同样的launch也是不行的。
//比如上面代码在collect调用的地方也加一个launch。这样Job也是StandaloneCoroutine,但是他们是不是同一个对象
//虽然是同一个类。两个Job的 === 为false.
Child of StandaloneCoroutine{Active}@4dd11322, expected child of BlockingCoroutine{Active}@2302b8ed.
//FlowCollector不是线程安全的,并且禁止并发emit。上面emit(2)和emit(3)就相当于并发执行
FlowCollector is not thread-safe and concurrent emissions are prohibited.
//要想不受此限制,请使用“channelFlow”构建器而不是“flow”。
To mitigate this restriction please use 'channelFlow' builder instead of 'flow'
。
Tips: 关于”channelFlow“的相关讲解,不出意外下一篇博客就是它了。感兴趣的先关注,第一时间收到通知,不过想搞搞懂channelFlow函数的前提是先要搞懂ChannelFlow这个类。关于ChannelFlow的讲解,我已经发布了,大家可以自行查看学习,连接在文章顶部。
- 下游发生异常,上游try catch后,也不能继续发送。
suspend fun main() {
val flow = flow<Int> {
emit(1)
try {
emit(2)
} catch (e: Exception) {
println(e)
}
println("我还能继续执行,但是不能emit")
emit(3) //会抛出异常
}
flow.collect {
println(it)
if (it == 2) {
throw NullPointerException("ddd")
}
}
Unit
}

输出的溢出信息还是比较直观容易理解的,接不做翻译解释了。
知道了Safe是何物后,那SafeFlow是通过什么来实现的呢?从前第二节的调用流程里面,我们知道调用SafeFlow的collect函数后,会把我们下游的FlowCollector包装进一个SafeCollector。这个SafeCollector就是用来保证”safe“的关键。
SafeCollector源码
SafeCollector不光实现了FlowCollector接口,同样它还继承了ContinuationImpl,至于CoroutineStackFrame这个接口里面的函数编译器会实现,用来在debugger时获取一个stack frame,我们不用去关心它,对我们来首CoroutineStackFrame没啥用。
SafeCollector为什么要实现ContinuationImpl呢?
internal actual class SafeCollector<T> actual constructor(
//这使我们下游的collector
@JvmField internal actual val collector: FlowCollector<T>,
//这是我们下游调用SafeFlow collect函数所在的协成的context
@JvmField internal actual val collectContext: CoroutineContext
) : FlowCollector<T>, ContinuationImpl(NoOpContinuation, EmptyCoroutineContext), CoroutineStackFrame {
override val callerFrame: CoroutineStackFrame? get() = completion as? CoroutineStackFrame
override fun getStackTraceElement(): StackTraceElement? = null
@JvmField //计算context中包含的Element个数,是为了后面对比emit和collect两个调用的context是否一样。
internal actual val collectContextSize = collectContext.fold(0) { count, _ -> count + 1 }
//用来保存上一次emit的context(每一次emit后就会把context保存在该属性中),或者如果下游处理数据发生异常了
//就把emit调用的的context包装成一个DownstreamExceptionContext保存在属性中。
private var lastEmissionContext: CoroutineContext? = null
// 上游的续体,因为flow{}里面的代码块会封装成一个续体(ContinuationImpl的子类)。当在flow{}里面
//被挂起后,调用completion.resume后能接着继续下一次emit。
private var completion: Continuation<Unit>? = null
/*
* This property is accessed in two places:
* * ContinuationImpl invokes this in its `releaseIntercepted` as `context[ContinuationInterceptor]!!`
* * When we are within a callee, it is used to create its continuation object with this collector as completion
*/
/**
* 这个属性会在两个地方被调用:
* 1. ContinuationImpl中调用 releaseIntercepted的时候在里面会context[ContinuationInterceptor]!!
* 2. 当SafeCollector作为一个被调用者时候,这个context作为创建continuation的completion.
* 比如说下游collect{} 里面调用了别的挂起函数,比如delay。在delay中就会创建一个SafeContinuation,
* SafeContinuation的构造函数参数需要调用 SafeCollector.intercepted()。在intercepted()里面
* 就会调用SafeCollector的context[ContinuationInterceptor].interceptContinuation()。
* 正因为这样,delay挂起恢复后,恢复后的代码才能继续执行在原来的协成的context环境里面。
*/
override val context: CoroutineContext
get() = lastEmissionContext ?: EmptyCoroutineContext
//SafeCollector作为ContinuationImpl的子类,当flow{}里面代用SafeCollector的emit函数,SafeCollector
//的emit里面继续调用下游collector的emit函数,如果下游collector的emit(也就是colelct代码块)被挂起了,那么
//flow{}里面的emit也被挂起了(SafeCollector的emit被挂起了),当下游collect{}里面挂起被恢复后,执行完colect
//代码块后就调用SafeCollector的resume函数,在BaseContinuationImpl的resumeWith里面会调用SafeCollector的
//invokeSupend,在其里面调用completion.resume就能上flow{}里面继续emit。
override fun invokeSuspend(result: Result<Any?>): Any {
//如果下游collect{}里面发生了异常(这个异常肯定是被try catch了,不然直接就泡出来了,也不会走到这里)
//调用了con.rresumeWithException(),这里con就是SafeCollector,那么result里面就会包含异常信息。
//result.onFailure里面就会把异常信息和context封装到DownstreamExceptionContext里面然后赋值给
//lastEmissionContext。这样上游再想继续emit时就会抛出异常。在SafeCollector的emit函数里面
//回去检查lastEmissionContext,如果lastEmissionContext是DownstreamExceptionContext
//就会抛出异常。
result.onFailure { lastEmissionContext = DownstreamExceptionContext(it, context) }
//恢复flow{}里面的挂起,继续emit
completion?.resumeWith(result as Result<Unit>)
//返回COROUTINE_SUSPENDED是为了让BaseContinuationImpl的resumeWith里面调用了invokeSuspend后
//就直接return掉。也可以说让是SafeCollector这个ContinuationImpl的子类挂起了,如果不返回
//返回COROUTINE_SUSPENDED,在BaseContinuationImpl的resumeWith里面就会继续执行releaseIntercepted
//函数。
//SafeCollector这个ContinuationImpl的子类,那他也是一个协成。它只有在Flow执行完成后,这个协成
//才能结束,调用releaseIntercepted。因此如果此处不返回COROUTINE_SUSPENDED就会导致Flow下一次emit挂起
//被恢复后调用BaseContinuationImpl的resumeWith->releaseIntercepted 或者Flow执行完成后
//在调用releaseIntercepted的时候就会抛出异常。
return COROUTINE_SUSPENDED
}
// 每一个协成执行完后都需要releaseIntercepted
public actual override fun releaseIntercepted() {
super.releaseIntercepted()
}
/**
* emit 的返回值为suspendCoroutineUninterceptedOrReturn的返回值。
* suspendCoroutineUninterceptedOrReturn的返回值为 try 表达式的返回值。
* 如果对这个不理解的可以看文章顶部列出的“[你真的了解kotlin中协程的suspendCoroutine原理吗?]
* 这篇文章。
* try 里面的emit 就是把把上游来的数据交给下游collector,并把SafeCollector作为协成续体传入到下游。
* 因此如果下游collect{}里面被挂起了emit就会返回COROUTINE_SUSPENDED,这样flow{} 里面的emit也就被挂起了。
*
* 下游collect{}里面挂起恢复后,执行完collect{}里面的代码后就会调用SafeCollector的invokeSuspend
* 让上游flow{}中挂起的emit(也就是SafeCollector的emit)恢复,继续执行,继续emit.
*/
override suspend fun emit(value: T) {
return suspendCoroutineUninterceptedOrReturn sc@{ uCont ->
try {
//调用内部自己的emit
emit(uCont, value)
} catch (e: Throwable) {
//如果下游collect{} 里面发生了未捕获的异常,这里把异常捕获,然后把context 和
//异常信息封装到DownstreamExceptionContext里面,赋值给lastEmissionContext。
//这样如果上游还想继续emit,因为lastEmissionContext为DownstreamExceptionContext
//类型,里面记录了下游抛出了异常,就会抛出异常。
//这个异常是在exceptionTransparencyViolated里面抛出。
lastEmissionContext = DownstreamExceptionContext(e, uCont.context)
throw e
}
}
}
/**
* 1,这个emit里面会对上游flow{}里面调用emit时所处的协成的context和下游collect函数所处的协成的context
* 通过checkContext函数做比较,如果发现emit 和 collect 不是同一个协成,那就会抛出异常。
* 2,如果下游抛collect{}里面抛出了未捕获的溢出,也会在 checkContext的时候调用
* exceptionTransparencyViolated抛出异常。阻止上游flow{}里面继续发送。
*/
private fun emit(uCont: Continuation<Unit>, value: T): Any? {
//上游flow{}里面调用emit时所处的协成的context
val currentContext = uCont.context
//相应协成取消。也就是说在collect上游数据的过程中如果外部协成被取消了。flow 也要停止继续发送。
currentContext.ensureActive()
// 要么是上一次emit时所处的协成的context,要么是DownstreamExceptionContext(代表上一次emit数据,下游
// 发生了未捕获的异常)。
val previousContext = lastEmissionContext
/**
* 如果两次的context 不相等。比如:
* flow {
* emit(1)
* launch{
* emit(2)
* }
* }
* 两次emit的context 肯定就不相等了。(原因1)
* 或者前一次emit时下游抛异常了,那也不相等。(原因2)
* 第一次emit lastEmissionContext = null。因此也不相等(原因3)
*/
if (previousContext !== currentContext) {
//如果两次不相等,就再做进一步检查,看看是什么原因导致的。
checkContext(currentContext, previousContext, value)
//记录本次emit的context,存入lastEmissionContext中。
lastEmissionContext = currentContext
}
//记录flow{}代码块的协成续体,当下游collect遇到挂起,挂起恢复执行完collect{}里面的代码后,需要
//通过completion来让上游flow{}里面继续执行。
completion = uCont
//emitFun指的是下游Collector的emit函数。这里为什么没有直接调用collector.emit。而是通过函数引用的
//方式,因为直接调用就没办法把协成续体(SafeCollector)传过去了。
val result = emitFun(collector as FlowCollector<Any?>, value, this as Continuation<Unit>)
/*
* If the callee hasn't suspended, that means that it won't (it's forbidden) call 'resumeWith` (-> `invokeSuspend`)
* and we don't have to retain a strong reference to it to avoid memory leaks.
*/
//如果下游
if (result != COROUTINE_SUSPENDED) {
completion = null
}
return result
}
//进一步检查是哪一种原因导致两次context不相等的
private fun checkContext(
currentContext: CoroutineContext,
previousContext: CoroutineContext?,
value: T
) {
//如果是前一次emit时下游抛出了未捕获的溢出
if (previousContext is DownstreamExceptionContext) {
//遵循官网提出的两个约束中的 Eexception Transparency,
//exceptionTransparencyViolated里面直接抛出异常,结束Flow。
exceptionTransparencyViolated(previousContext, value)
}
//如果不是下游抛出异常的,那就遍历context里面的每一个Element进行比较。
checkContext(currentContext)
}
//如果下游抛出异常,继续在emit,exceptionTransparencyViolated里面直接抛出异常,结束Flow.
private fun exceptionTransparencyViolated(exception: DownstreamExceptionContext, value: Any?) {
/*
* Exception transparency ensures that if a `collect` block or any intermediate operator
* throws an exception, then no more values will be received by it.
* For example, the following code:
* ```
* 上面的意思就是 Exception transparency 这个约束确保了如果collect{}代码块或者任何中间操作符里面
* 抛出了异常,下游就不应该再接收到任何数据。
* 比如:
* val flow = flow {
* emit(1)
* try {
* emit(2)
* } catch (e: Exception) { //中间操作符或者collect代码块里面抛出了异常
* emit(3) //继续发送
* }
* }
* // Collector
* flow.collect { value ->
* if (value == 2) { //让collect 代码块连抛出一个异常
* throw CancellationException("No more elements required, received enough")
* } else {
* println("Collected $value")
* }
* }
* ```
* is expected to print "Collected 1" and then "No more elements required, received enough"
* exception,
* 期望的是打印 “ollected 1” 和 异常信息“and then "No more elements required, received enough"
* exception”
* but if exception transparency wasn't enforced, "Collected 1" and "Collected 3" would be
* printed instead.
* 但是如果 exception transparency这个约束没有被强制执行的话,就会打印 “Collected 1” 和 “Collected 3”
*/
//因此为了确保 exception transparency的约束被应用,所以当collect里面抛出异常后,再想继续emit就
//直接抛出异常,终止Flow.
error("""
//Flow的exception transparency被违背了
Flow exception transparency is violated:
//上一次emit已经抛出了${exception.e},又检查到了继续emit ${value}
Previous 'emit' call has thrown exception ${exception.e}, but then emission attempt of value '$value' has been detected.
//在ty 的catch里面emit 是禁止的。 如果你想要做到下游抛出异常后,还想继续发送就用
//catch操作符代替。
Emissions from 'catch' blocks are prohibited in order to avoid unspecified behaviour, 'Flow.catch' operator can be used instead.
//更多的解释查阅 catch操作符的文档。
//catch操作符的源码在Errors.kt文件里面
For a more detailed explanation, please refer to Flow documentation.
""".trimIndent())
}
}
//crrrentContext 为 本次emit时的context
internal fun SafeCollector<*>.checkContext(currentContext: CoroutineContext) {
//fold 遍历context 里面的每一个Element,
// result为遍历完后count的值,用于和 SafeCollector中的collectContextSize进行对比。如果两个
//值都不相等,说明两个context里面的Element个数不一样。那就是发生了context切换。
val result = currentContext.fold(0) fold@{ count, element ->
val key = element.key //拿到第一个element的Key。
//用这个Key去collectContext里面取Element。
val collectElement = collectContext[key]
//Job代表了这个协成的completion。每次创建一个协成,都需要为其创建一个Job类型的Continuation
//作为其completion。key != Job,意思就是其他非Job类型的Element的处理情况。
//比如CoroutineName,Dispatchers.xxx 都不是Job类型
if (key !== Job) {
//如果两个element 不相等。返回Int.MIN_VALUE
return@fold if (element !== collectElement)
Int.MIN_VALUE
else
//相等就加一。
count + 1
}
/**
* note : 如果不理解上面代码,那就需要你自行去恶补一下协成相关知识。
*/
//如果Element为Job类型
val collectJob = collectElement as Job? // collectContext中的Job
// 拿到currentContext中的Job
val emissionParentJob = (element as Job).transitiveCoroutineParent(collectJob)
/*
* Code like
* ```
* coroutineScope {
* launch {
* emit(1)
* }
*
* launch {
* emit(2)
* }
* }
* ```
* 上面的代码写法是错的,会抛异常。
* is prohibited because 'emit' is not thread-safe by default. Use 'channelFlow' instead if
* you need concurrent emission
* or want to switch context dynamically (e.g. with `withContext`).
*
* 如果你想要并发emit,意思就是在flow{}中开启子协成emit数据,或者想通过withContext来切换context
* 那么请使用 channelFlow来代替。
* Note that collecting from another coroutine is allowed, e.g.:
* ```
* //以下下代码出现在flow{}里面是可以的
* coroutineScope {
* //虽然这个Channel的send是在一个新的协成里面
* val channel = produce {
* collect { value ->
* send(value)
* }
* }
* //但是从channe中receive 数据还是发生在和collect{}同一个协成里面。
* //并且coroutineScope也没有切换context。
* channel.consumeEach { value ->
* emit(value)
* }
* }
* ```
* is a completely valid.
*/
//如果连个Job不相等,必然发生了context切换。直接抛出异常
if (emissionParentJob !== collectJob) {
error(
"Flow invariant is violated:\n" +
"\t\tEmission from another coroutine is detected.\n" +
"\t\tChild of $emissionParentJob, expected child of $collectJob.\n" +
"\t\tFlowCollector is not thread-safe and concurrent emissions are prohibited.\n" +
"\t\tTo mitigate this restriction please use 'channelFlow' builder instead of 'flow'"
)
}
/*
* If collect job is null (-> EmptyCoroutineContext, probably run from `suspend fun main`),
* then invariant is maintained(common transitive parent is "null"),
* but count check will fail, so just do not count job context element when
* flow is collected from EmptyCoroutineContext
* 针对collectJob == null,也就是 collect 函数被调用在”suspend fun main“的情况,
* 那就直接返回count。否则两个Job相等时对其加一,
* 因为在计算collectContextSize的时候,collectJob不为空时是算了一个数的。因此这里也需要加一。
*/
if (collectJob == null) count else count + 1
}
//如果context中element个数不相等,那也说明发生了context切换。抛出异常
if (result != collectContextSize的) {
error(
"Flow invariant is violated:\n" +
"\t\tFlow was collected in $collectContext,\n" +
"\t\tbut emission happened in $currentContext.\n" +
"\t\tPlease refer to 'flow' documentation or use 'flowOn' instead"
)
}
}
//
internal tailrec fun Job?.transitiveCoroutineParent(collectJob: Job?): Job? {
//如果currentContext没有Job。返回null。比如currentContext = EmptyCoroutineContext。
if (this === null) return null
//如果currentContext和collectContext中的两个Job是同一个对象,直接返回this.
if (this === collectJob) return this
//如果两个Job不是同一个对象。同时this 也不是ScopeCoroutine类型,意思就是在flow中发生了context
//切换,那也就意味着两个Job不相等。
if (this !is ScopeCoroutine<*>) return this
//如果上面都不是,那就说明this 是ScopeCoroutine类型,比如在flow{} 里面使用了
//coroutineScope 或者supervisorScope,这种是支持的,那就拿到this.parent,也是Job,继续递归调用
//再进行比较。如果在flow{}里面没有启动新协成或者切换context, tiis作为一个ScopeCoroutine类型,它的
//parent递归时是能返回一个collectJob相等(===)的对象的。
//当让this 不是ScopeCoroutinel类型时,
return parent.transitiveCoroutineParent(collectJob)
}
Flow的catch操作直接从代码里面点进取如果看不到源码,你可以试试双击Shift,搜索“Errors.kt"(一定要把后缀带上)
结语:本次发布比较充忙,没有来得及回顾,可能存在错别字和表述不清楚的地方,欢迎大家留言指出,谢谢