一、说明
我知道transformer 架构可能看起来很可怕,你可能在网上或博客上遇到了各种解释。但是,在我的博客中,我将通过提供一个全面的数值示例来努力澄清它。通过这样做,我希望简化对变压器架构的理解。
二、输入和位置编码
让我们解决初始部分,我们将确定输入并计算它们的位置编码。
2.1 步骤 1(定义数据)
第一步是定义我们的数据集(语料库)。

在我们的数据集中,有 3 个句子(对话)取自《权力的游戏》电视节目。虽然这个数据集可能看起来很小,但它的大小实际上有助于我们使用即将到来的数学方程找到结果。
2.2 第 2 步(查找词汇大小)
为了确定词汇量,我们需要确定数据集中唯一单词的总数。这对于编码(即将数据转换为数字)至关重要。
![]()
其中 N 是所有单词的列表,每个单词都是单个标记,我们将数据集分解为标记列表,即找到 N。

获得标记为 N 的标记列表后,我们可以应用公式来计算词汇量。

使用 set 操作有助于删除重复项,然后我们可以计算唯一的单词以确定词汇量。因此,词汇量为 23,因为给定列表中有 23 个唯一单词。
2.3 步骤 3(编码和嵌入)
我们很好地为数据集的每个唯一单词分配一个整数。
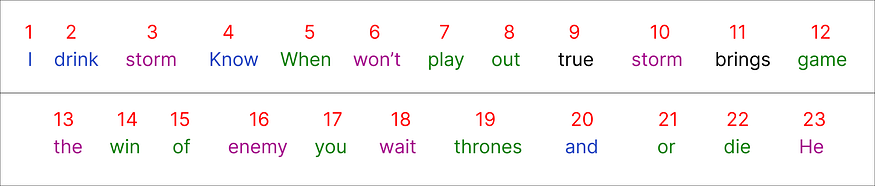
对整个数据集进行编码后,是时候选择我们的输入了。我们将从语料库中选择一个句子开始:
“当你玩权力的游戏”

作为输入传递的每个单词都将表示为编码整数,并且每个相应的整数值都将附加一个关联的嵌入。

- 这些嵌入可以使用Google Word2vec(单词的矢量表示)找到。在我们的数值示例中,我们将假设每个单词的嵌入向量填充 (0 到 1) 之间的随机值。
- 此外,原始论文使用512维的嵌入向量,我们将考虑一个非常小的维数,即5作为数值示例。
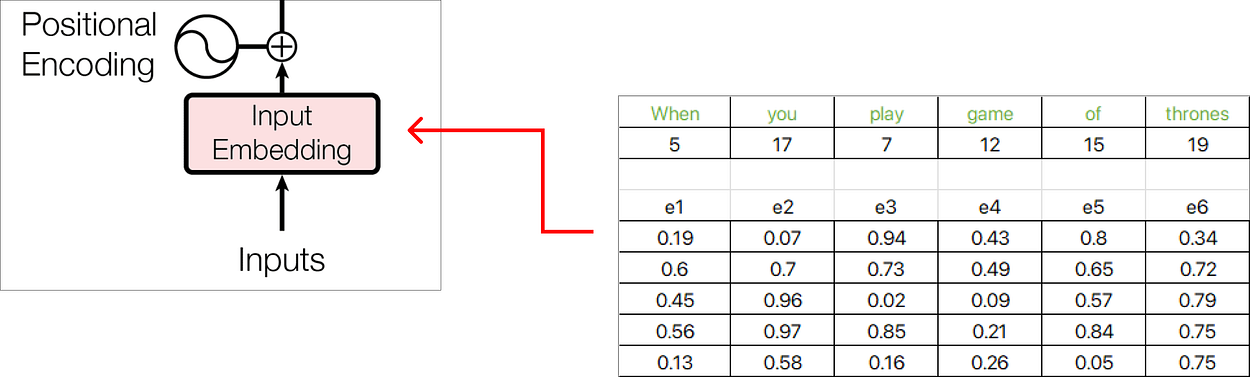
现在,每个单词嵌入都由维度为 5 的嵌入向量表示,并且使用 Excel 函数 RAND() 用随机数填充这些值。
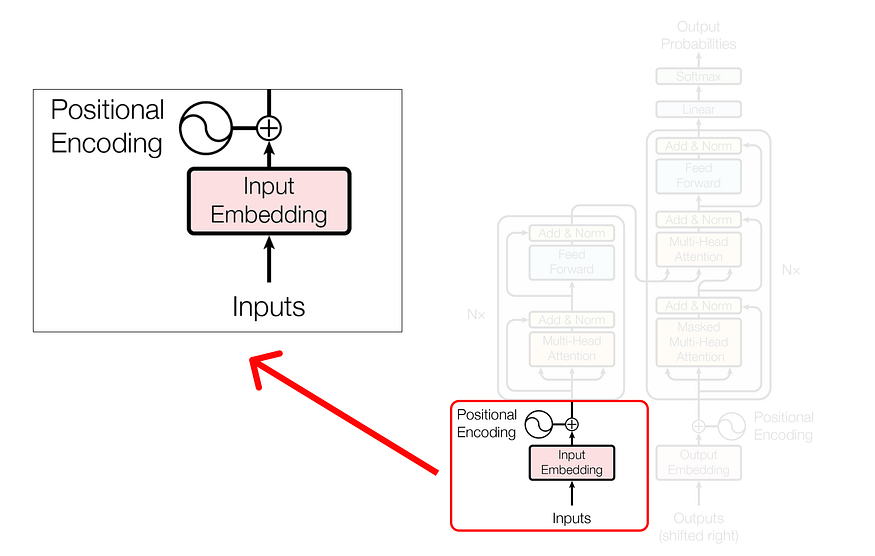
2.4 步骤 4(位置嵌入)
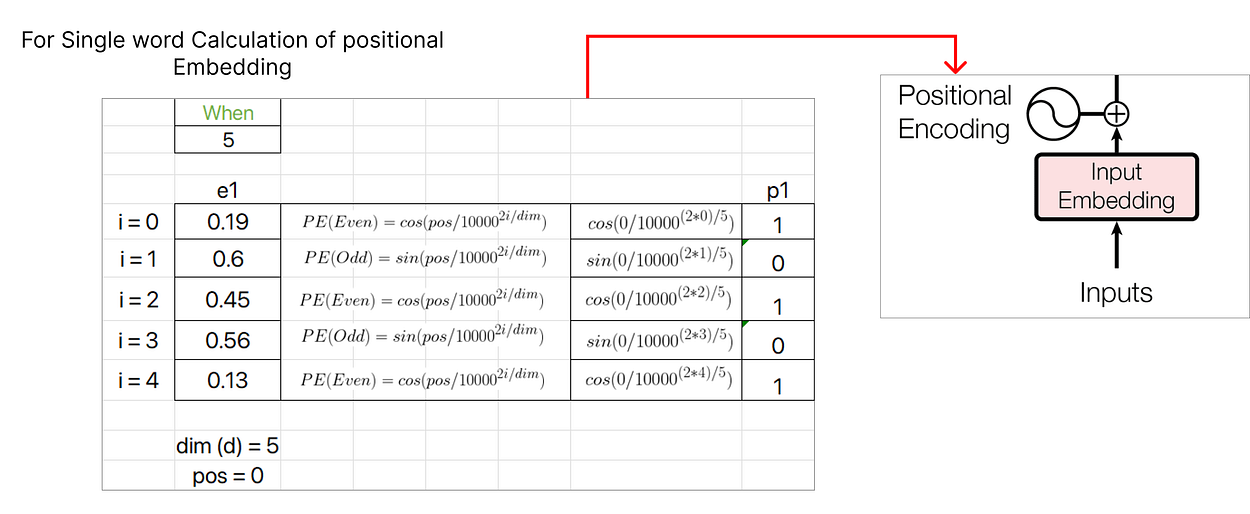
让我们考虑第一个单词,即“When”,并计算它的位置嵌入向量。
位置嵌入有两个公式:
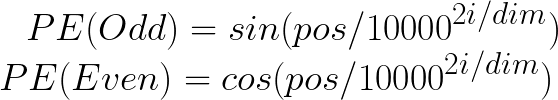
第一个单词“When”的 POS 值将为零,因为它对应于序列的起始索引。此外,i 的值(无论是偶数还是奇数)决定了用于计算 PE 值的公式。维度值表示嵌入向量的维度,在本例中为 5。
继续计算位置嵌入,我们将为下一个单词“you”分配一个 pos 值 1,并继续递增序列中每个后续单词的 pos 值。

找到位置嵌入后,我们可以将其与原始词嵌入连接起来。

我们得到的结果向量是 e1+p1、e2+p2、e3+p3 等的总和。
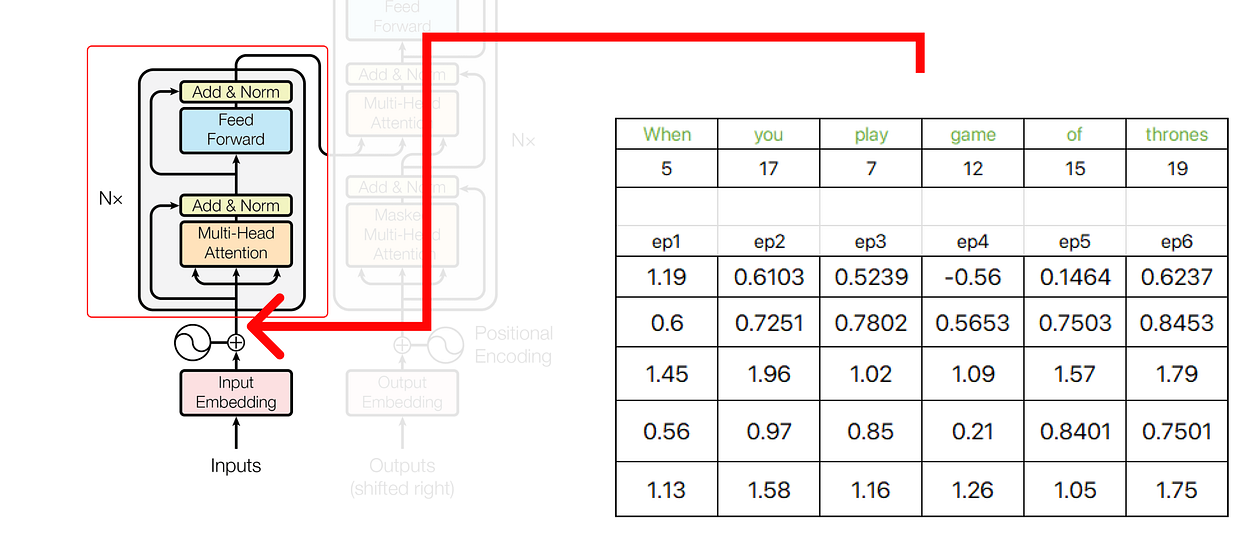
变压器架构初始部分的输出用作编码器的输入。
三、关于编码器
在编码器中,我们执行涉及查询、键和值矩阵的复杂操作。这些操作对于转换输入数据和提取有意义的表示至关重要。

在多头注意力机制内部,单个注意力层由几个关键组件组成。这些组件包括:
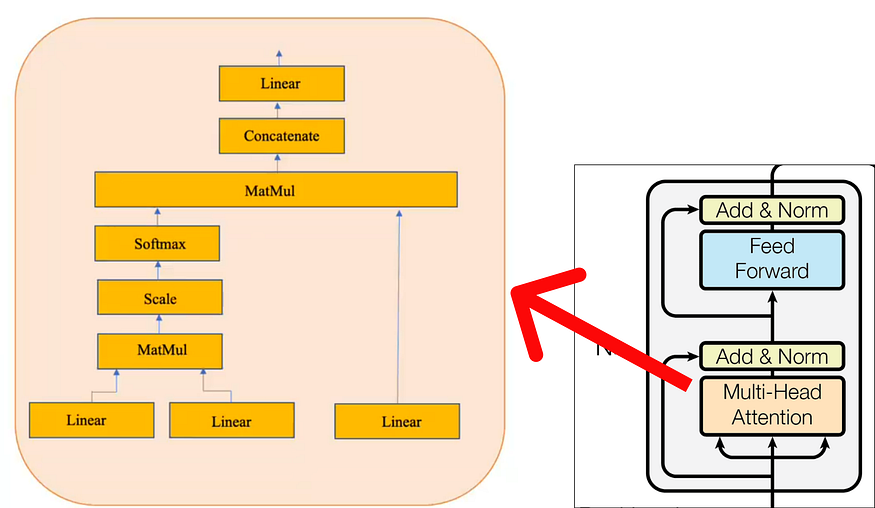
请注意,黄色框代表单一注意力机制。使它受到多头关注的是多个黄色框的存在。出于此数值示例的目的,我们将仅考虑上图中描述的一个(即单头注意力)。
3.1 第 1 步(执行单头注意力)
注意力层有三个输入:
- 查询
- 我?
- 价值
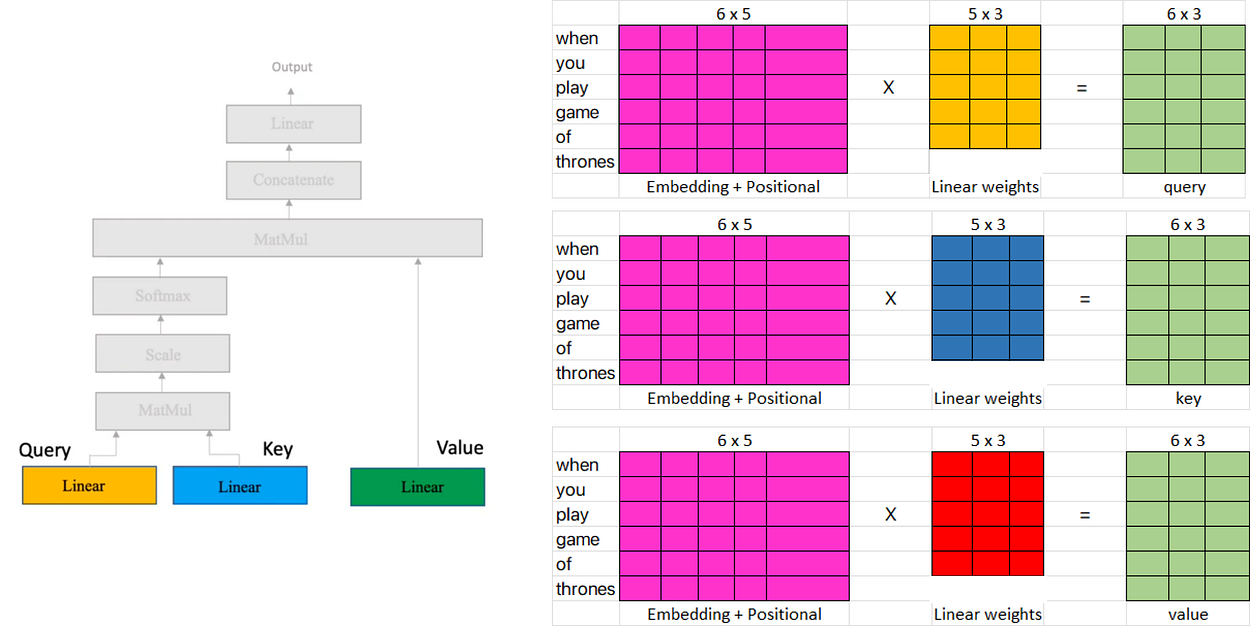
在上面提供的图中,三个输入矩阵(粉红色矩阵)表示从上一步将位置嵌入添加到单词嵌入矩阵中获得的转置输出。
另一方面,线性权重矩阵(黄色、蓝色和红色)表示注意力机制中使用的权重。这些矩阵可以具有相对于列的任意数量的维度,但行数必须与输入矩阵中的列数相同以进行乘法。
在我们的例子中,我们将假设线性矩阵(黄色、蓝色和红色)包含随机权重。这些权重通常是随机初始化的,然后在训练过程中通过反向传播和梯度下降等技术进行调整。
因此,让我们计算(查询、键和值指标):
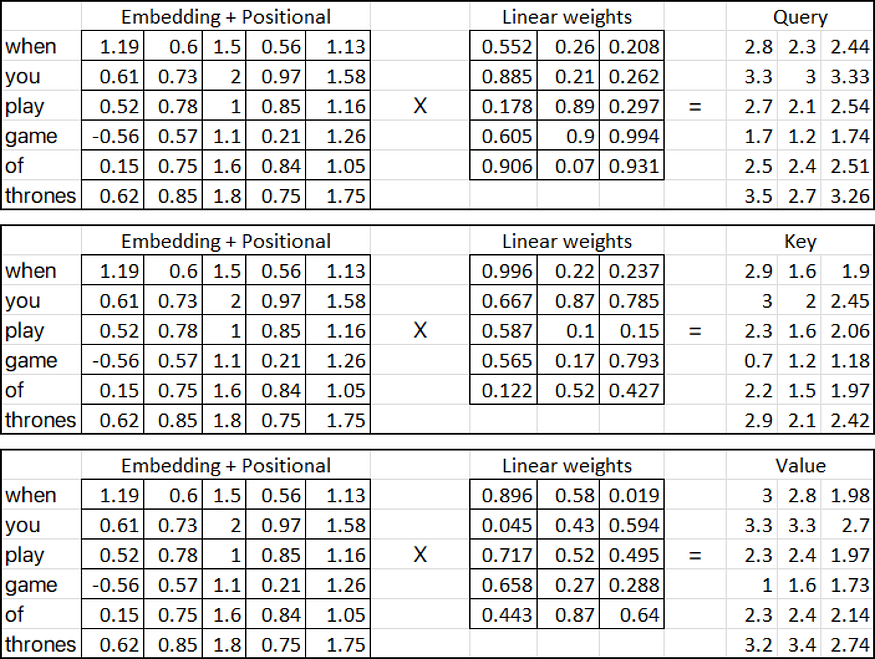
一旦我们在注意力机制中有了查询、键和值矩阵,我们就会继续进行额外的矩阵乘法。



现在我们将结果矩阵与我们之前计算的值矩阵相乘:

如果我们有多个头部注意力,每个注意力产生一个维度(6x3)的矩阵,下一步涉及将这些矩阵连接在一起。

在下一步中,我们将再次执行类似于用于获取查询、键和值矩阵的过程的线性变换。这种线性变换应用于从多个头部注意力获得的级联矩阵。
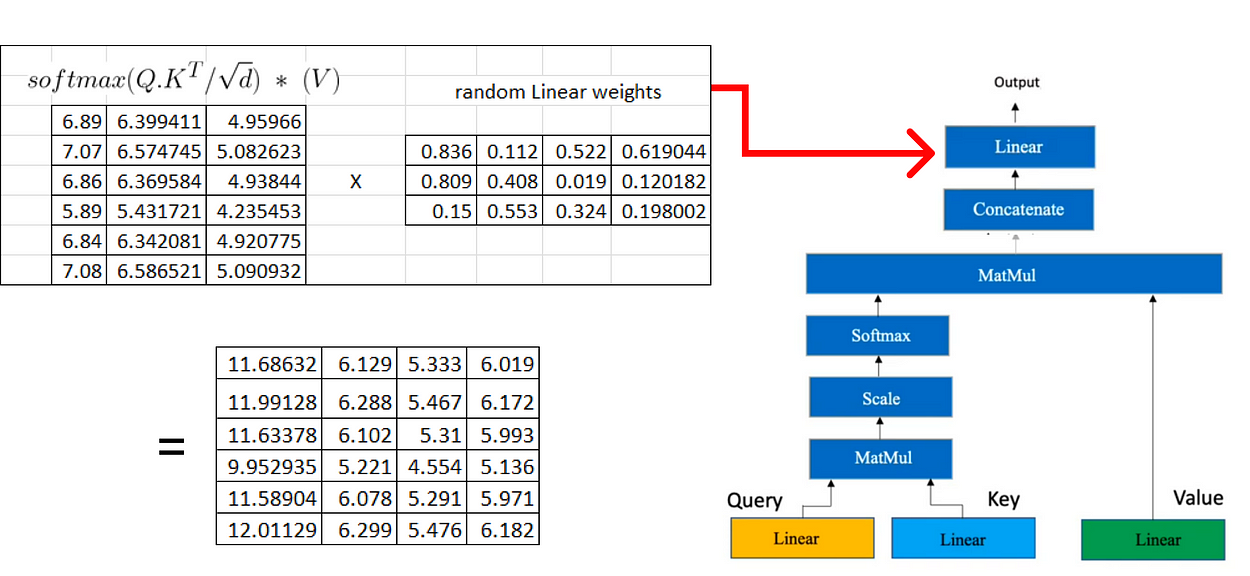
由于博客已经变得冗长,在下一部分中,我们将重点转移到讨论编码器架构中涉及的步骤。
(未完待续)

![[学习笔记] 扩散模型 Diffusion](https://img-blog.csdnimg.cn/4aa5900dbac2438c952d17f9f6e5672e.png)