every blog every motto: You can do more than you think.
https://blog.csdn.net/weixin_39190382?type=blog
0. 前言
对DBSCAN的补充,OPTICS聚类
1. 正文
1.0 DBSCAN的存在问题
前面我们介绍了DBSCAN,其能根据密度进行聚类。
但其存在这样一个问题:
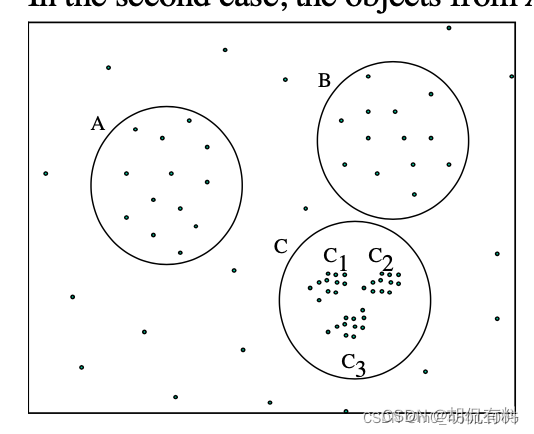
- 当eps较大时,会划分出A、B、C
- 当eps较小时,会划分出C1、C2、C3 (A、B会被认为是噪声)
无法得到A、B、C、C1、C2、C3
不同簇的密度大小可能不一样,二DBSCAN设置了一个固定了eps,会忽略掉其中的部分。
1.1 基础概念
核心点: 参考DBSCAN
核心距离: 使点p成为核心点的最小距离。
eg: eps=2,min_samples=5,p点,在半径eps=2时,有8个样本点。那么p是核心点。
距离p点最近的第5个点,其和核心点p的距离为0.8,那么p点的核心距离就是0.8。
注意: 计算min_samples时,包括核心点自身,所以上面只需要在邻域eps内找7个点,那么p就是核心点。
可达距离: 点p到核心点 o 的可达距离为,p 和o两点的距离和o的核心距离中的最大值。(和LOF算法中的可达距离类似,可参考)
说人话: 一个点可能在核心距离以内,也可能在核心距离以外。
eg1:
- p点在核心点o1的核心距离之外,所以,可达距离reach-dist=d(p,o1)
- p点在核心点02的核心距离之内,所以,可达距离reach-dist = d_5(o2)

eg2:
点1、2、3在核心距离内,所以他们到核心点的可达距离=核心距离

1.2 算法流程
总的来说还是发展下线的套路,只有一个下线关系亲疏的区别(可达距离)
- 定义两个队列
- 有序队列,存储核心点和密度直达点(核心点邻域内的点),按可达距离升序排列,待处理的样本
- 结果队列,存储样本点输出,处理后的样本
- 选取未处理的核心点放入结果队列,计算邻域内样本的可达距离,按可达距离升序放入有序队列
- 从有序队列中提取第一个样本,如果为核心点计算可达距离,将可达距离最小的放入结果队列;如果不为核心点则跳过该点,选取新的核心,重复步骤2
- 迭代步骤2、3,直到处理了所有样本点,输出结果队列中的样本及可达距离。
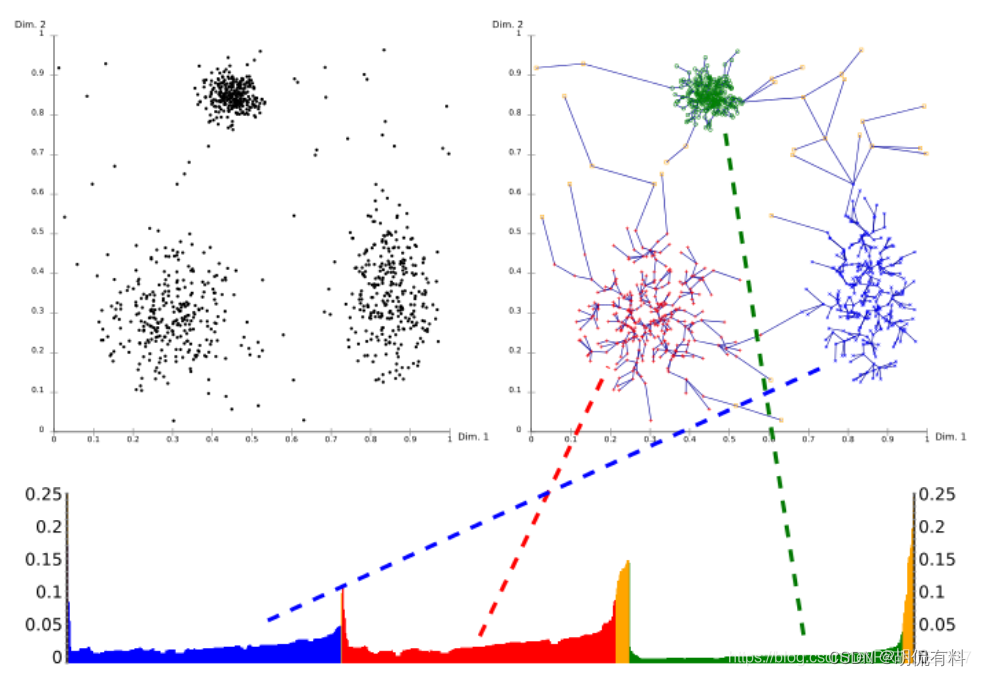
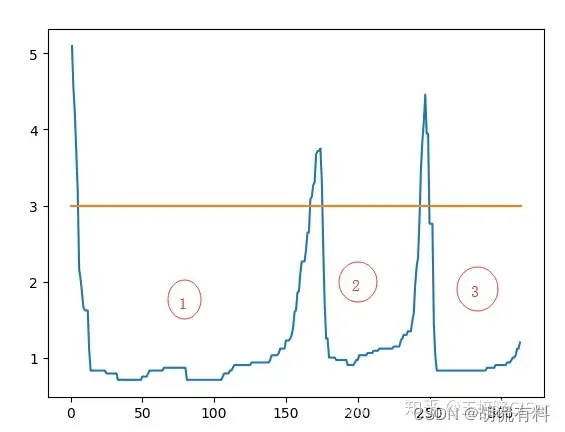
1.3 结果
输出的是可达距离和样本点次序
- 簇在图中表现为山谷,山谷越深,簇越紧密
- 黄色的代表噪声,不形成谷

参考
[1] https://zhuanlan.zhihu.com/p/408243818
[2] https://zhuanlan.zhihu.com/p/77052675
[3] https://blog.csdn.net/haveanybody/article/details/113782209
[4] https://zhuanlan.zhihu.com/p/395088759
[5] https://blog.csdn.net/PRINCE2327/article/details/110412944
[6] https://blog.csdn.net/markaustralia/article/details/120155061
[7] https://blog.csdn.net/m0_45411005/article/details/123251733#t1




![[PG]生成表注释SQL](https://img-blog.csdnimg.cn/a72ad5d8da2948968e43328361c4a33a.png)