问题来源:
版本:5.7.25。
现象:备机主从延迟不断变大,无法登陆数据库,建立连接时卡住,但很快恢复正常了。
分析:
常规分析:
通常情况下,这类问题无法分析,来的快去的快,日志中不会记录太多有效信息,但这次DBA同学在数据库hang住时把数据库运行堆栈打印保存了,这就有了分析根因的可能性。
查看error log在hang住时间节点附近没有有效信息,慢查询记录也为空,查看监控发现当时写入insert非常高,这是slave机,写入来源于SQL线程回放,io利用率当时也跑满,但cpu也比较高,内存使用量在事发前后没有变化。如果简单的把这个故障归结到写入压力大,io资源不够,很难说的过去,压力大主从延迟变大可以理解,但是无法登陆数据库就不能解释了。
MySQL堆栈分析:
由于有堆栈,进一步分析当时堆栈,整理如下:

当时已经累积有753个尝试建立的连接的线程被卡住无法登陆,其它除sql线程外,都无明显异常。
从堆栈上看,sql线程正在对一个分区表做insert数据,当时正在做内存申请操作,这就是比较诡异了,内存申请通常来说都是纳秒微秒级能完成的任务,这里居然能被打印出来,显然这个动作卡的时间比较长。
查看一下内存使用率,当前MySQL进程居然占用了90%的内存,注意这是现在非故障时,现在没有业务流量,仅有几个复制线程在跑,而故障时作为读库有大量业务连接,内存占用量肯定更高。
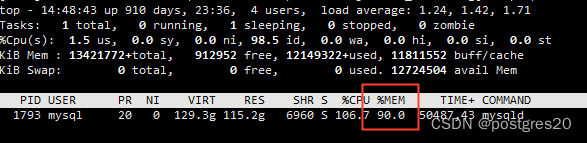
此时立马有个问题浮现:为什么mysqld进程没有OOM?查看一下规格,64c128G,如此强悍的机器,故障时还有富余内存,不至于OOM,但是这个内存使用率必然导致数据库进程在生死边缘挣扎了,同时也能解释为什么会卡在申请内存这了。
linux系统内存将耗尽时,大概会采取以下措施:
(1)系统内核会尝试通过回收不用的内存页(page)来为该进程分配内存。
(2)如果回收内存页后仍无法满足该进程的内存需求,Linux 内核会尝试通过交换空间(swap)来腾出更多的物理内存。
(3)如果交换空间不足以满足该进程的内存需求,Linux 内核会选择杀死某些进程来释放物理内存。
数据库进程此时就处在第1-2阶段,而本机内存又比较大,操作系统进行这个过程可能比较慢,导致申请内存的线程一直在等,同样建立连接的线程也全需要申请内存,自然无法成功建立,但总体上运气不错,没有走到第3阶段就恢复了,mysqld没有被系统kill。
MySQL为什么会占如此多内存
至此基本上确定了是内存不够,系统重分配慢所至,似乎可以至此为止了,但是这样的结论没有什么实际用处,下次业务高峰照样发生故障,所以有必要继续分析内存哪去了,是否可以避免再次故障。
那么内存去哪了?
-
buffer_pool 64G,减掉64G仍然有五六十G。
-
当前没有业务连接,thread_pool_size才64,不会缓存太多线程,顶天不会超过1G。
-
table_open_cache、table_definition_cache 参数配的8192,看了下data目录,好家伙,3.9TB,并且全是分区表,9万多个ibd文件,那么这些表的缓存文件会占不少内存,可能会占到几个G。
-
再加上其它一些其它内存,所有这些额外内存估计最多能占10多G,加上buffer pool内存后,总的往多算也就七八十GB。而当前没有业务连接的情况下,占用90%*128GB=115G,显然是不正常的。
难道是MySQL的内存泄漏bug?
MySQL 5.1、5.5时代是存在一些内存泄漏bug的,但5.6开始极少了,5.7更是少之又少,目前没遇到过被证实的MySQL5.7内存泄漏bug。看再这个实例运行时间:900多天,要是mysqld本身有泄漏很难坚持这么久的。
那么内存到底去哪了?直接给结论,这是glibc默认内存分配库ptmalloc的缺陷,有大量内存碎片无法被利用,导致进程内存使用量越来越大。那么是如何认定是该问题的?直接调gdb释放内存碎片命令看结果认定。
直接执行:gdb -p 1793 -batch -ex 'call malloc_trim(0)'
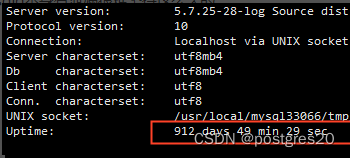
1793为mysqld进程,执行时可能会卡一两秒,但无其它影响,malloc_trim是专门用来释放内存碎片的,执行完之后内存占用情况:

内存使用量瞬间从90%掉到62.5%,回到健康状态。
该问题多年前首次在MySQL上遇到时,全过程花了数月才定位到,因为这个碎片内存涨的非常慢,导致定位分析周期长,像本次的案例就用了900多天才涨到这个量。
ptmalloc库缺陷介绍
ptmalloc的这个缺陷也简单介绍下,不光MySQL,所有的用glibc内存库的c/c++程序都可能遇到,尤其多线程高并发长期运行的服务程序,一定有内存碎片,只是多少的区别。
为了提高多线程并发情况下的内存分配效率,glibc 的ptmalloc维护了多个内存管理单元,每一个称作一个 arena,每个arena都使用 malloc_state来描述(malloc_state主要用于维护空闲的chunk 链表),只有main_arena 是通过 sbrk 来获得和管理内存的,其他arena是通过mmap 获取的;arena 可以包含多个heap,每个heap是通过mmap 获取的一个线性区,heap的最大大小是HEAP_MAX_SIZE(在64位系统是64M)。
分配内存时,按照TLS(线程私有数据)中的arena –>main_arena ->arena1 ->arena2->… 的顺序进行遍历,依次进行trylock,如果 trylock成功,则在对应的arena中分配内存,若都不成功新建一个arena 来分配。
当进程长期运行时,一个大内存块被不断被拆分成小碎片,这些小碎片内存会越来越多,也越来越难被重用,导致“内存泄漏”。
另一方面,glibc的多线程运行也会带来一些问题,假设当前有3个arena,进程需要20kb内存,当前3个arena都有20kb的内存块,但是这些个arena都在使用中,try_lock加不上锁,此时进程就会增加一个arena来分配内存。同样假如arena2有符合要求的20kb内存块,但在arena1上try_lock成功,arena1又没有20kb的内存块,就会直接新分配一块挂在arena1上。总的来说,多线程下,存在原来的内存碎片无法利用反而去申请新的arena或者 heap的情况,导致内存碎片越来越多。
想了解详细的可以找下相关glibc内存库相关的资料进行研究分析,参考文档:glibc内存管理ptmalloc源代码分析
总结与建议
-
ptmalloc在多线程并发的情况下,容易产生内存碎片,日积月累容易占用大量不可利用内存,等同于内存泄露。
-
malloc_trim可以回收空闲碎片内存,对于长期内存高水位实例,可以定期(如按月)在业务低谷时执行。
-
可以考虑更换mysql内存分配库,事实上,国内公有云mysql基本都用jemalloc代替了ptmalloc,除了能避免内存碎片问题,它的性能也好很多。
-
另外,这个实例单库3.9T,近10万个数据文件,可以考虑优化一下空间。