转眼间,自DETR被提出已经过去了2年了,如今又迎来了2023年,可以说,这是Transformer框架在CV领域发力的第3个年头了。时至今日,对Transformer的质疑声越来越小了,它的强大得到了越来越多、越来越广泛的认可。可以说,如今的CV领域,Transformer已经和CNN是各分半壁江山了。
现如今,目标检测技术继DETR的高潮后,又进入到了一个相对平稳的发展期,短时间内可能也看不到重要的突破了,更多的是在进一步挖掘现有工作的性能和可能性,比如近期爆火的Segment Anything(SAM),其网络结构就是常见的ViT结构搭配上Prompt技术等,没有花里胡哨的东西,但表现出的性能是极其不俗的。
1、paddledetection
基于paddledetection得rtdetr得输出结果,


2、ultralytics
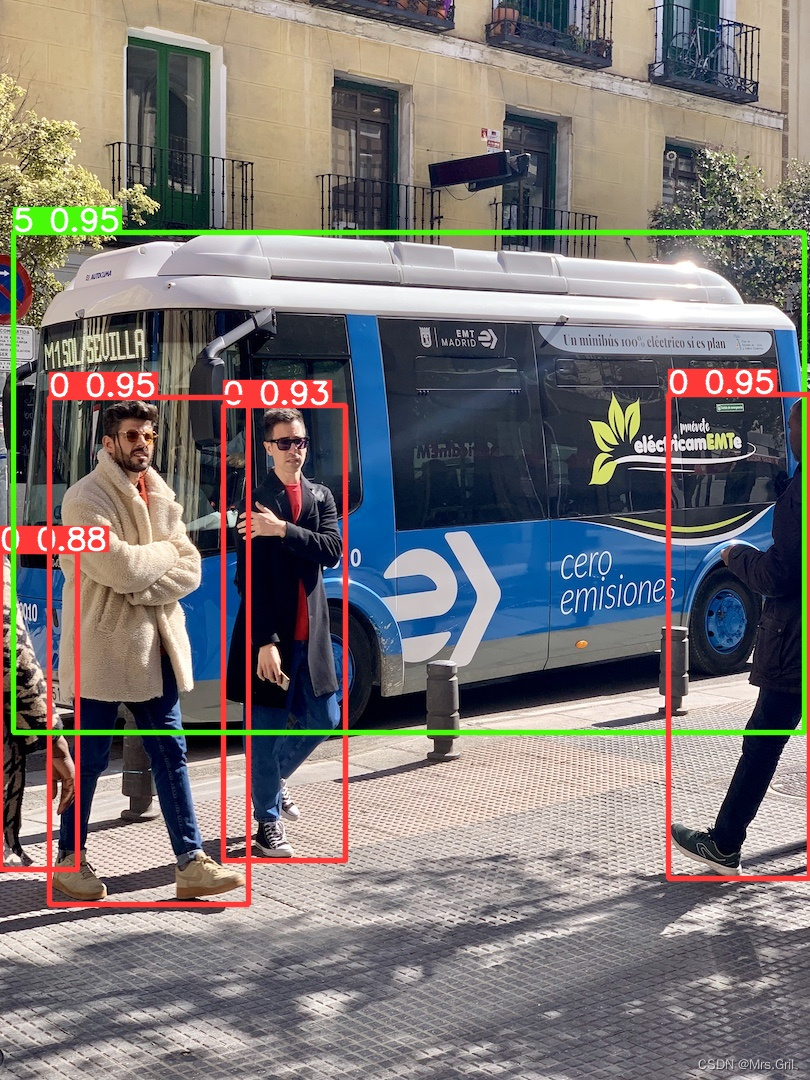

对比两者输出。。其实ultralytics得第二幅图那个truck其实还有个输出 car ...就是多检出一个,但是框得大小基本一致。
3、TensorRT 的输出对比
paddledetection导出的onnx:

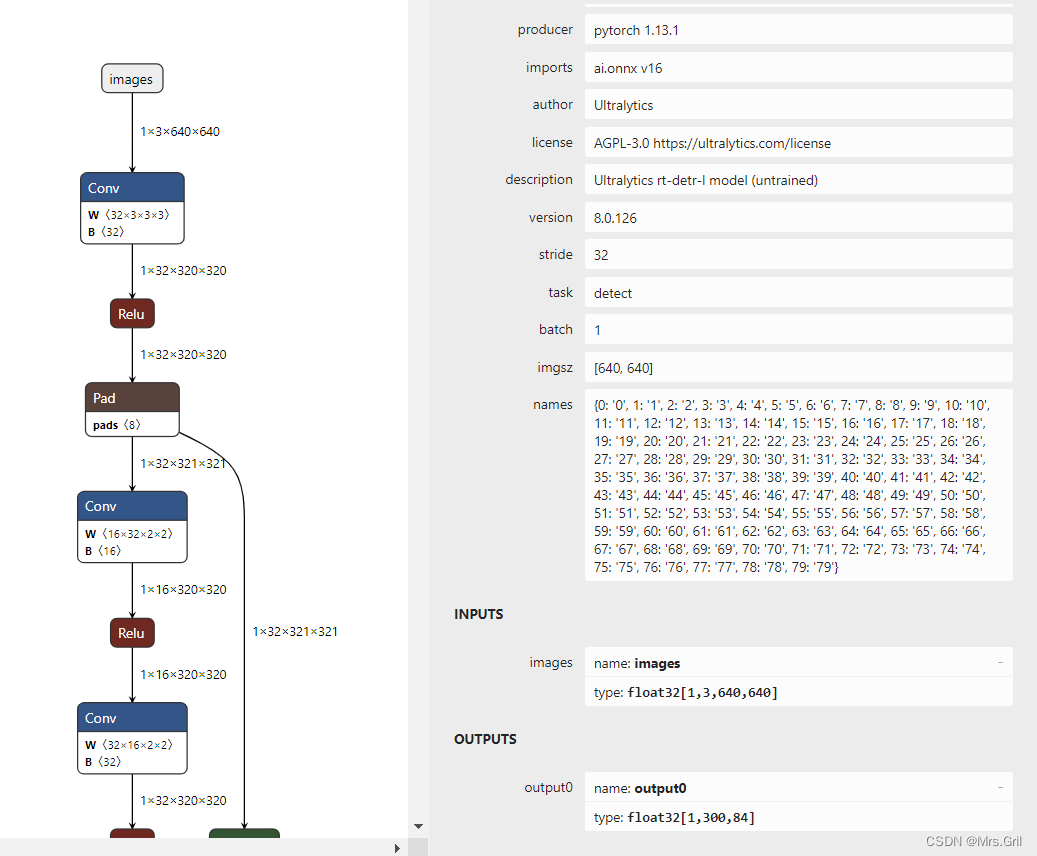
ultralytics导出得onnx:
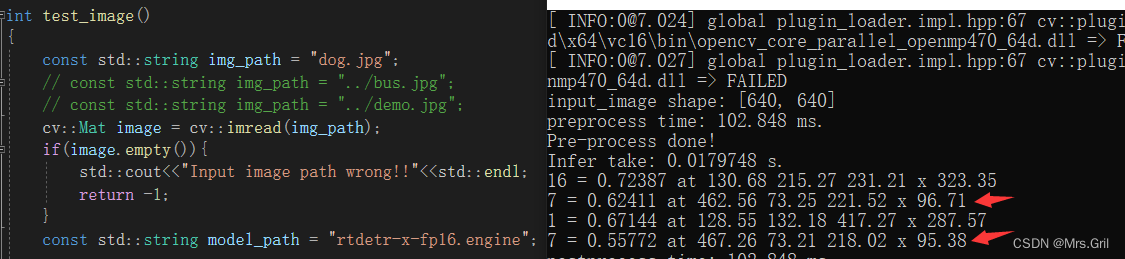
tensorrt输出对比:


paddle ultralytics
使用rtdetr-x.onnx进行推理的时候就可以看到了。多个框,,,置信度掉的好严重。。。