作者:Thomas Veasey,Quentin Herreros

在本博客中,我们讨论了我们一直在使用预先训练的语言模型增强 Elastic® 开箱即用检索功能所做的工作。
在本系列的上一篇博客文章中,我们讨论了在零样本设置中应用密集模型进行检索的一些挑战。 这是众所周知的,BEIR 基准测试也强调了这一点,该基准测试汇集了不同的检索任务,作为人们对应用于不可见数据集的模型所期望的性能的代理。 零样本设置中的良好检索正是我们想要实现的,即一键式体验,允许使用预先训练的模型搜索文本字段。
这项新功能适合 Elasticsearch _search 端点,就像另一个查询子句,即 text_expansion 查询。 这很有吸引力,因为它允许搜索工程师继续使用 Elasticsearch® 已经提供的所有工具来调整查询。 此外,为了真正实现一键式体验,我们将其与新的 Elasticsearch 相关性引擎集成。 然而,本博客不是专注于集成,而是深入研究我们选择的模型架构以及我们为训练它所做的工作。
在这个项目开始时我们还有另一个目标。 自然语言处理(NLP)领域正在快速发展,新的架构和训练方法正在迅速引入。 虽然我们的一些用户将掌握最新的发展并希望完全控制他们部署的模型,但其他用户只是想使用高质量的搜索产品。 通过开发自己的训练管道,我们拥有了一个用于实施和评估最新想法的平台,例如新的检索相关预训练任务或更有效的 distillation 任务,并将最好的想法提供给我们的用户。
最后,值得一提的是,我们认为此功能是对 Elastic Stack 中现有模型部署和向量搜索功能的补充,而这些功能是那些更自定义的用例(例如跨模式检索)所需要的。
测试结果
在查看架构的一些细节以及我们如何训练我们的模型(Elastic Learned Sparse Encoder)之前,回顾一下我们得到的结果是很有趣的,因为最终布丁的证明在于吃。
正如我们之前讨论的,我们使用 BEIR 的子集来评估我们的性能。 虽然这绝不是完美的,并且不一定代表模型在你自己的数据上的行为方式,但我们至少发现在此基准上做出重大改进具有挑战性。 因此,我们相信我们在这方面取得的改进会转化为模型的真正改进。 由于基准测试的绝对性能数据本身并没有特别丰富的信息,因此很高兴能够与其他强大的基准进行比较,我们将在下面进行比较。
下表显示了 Elastic Learned Sparse Encoder 与带有英语分析器的 Elasticsearch BM25 的性能比较,按我们评估的 12 个数据集细分。 我们取得了 10 胜 1 平 1 负的成绩,NDCG@10 的平均进步为 17%。

在下表中,我们将我们的平均表现与其他一些强基线进行了比较。 Vespa 结果基于 BM25 的线性组合及其 ColBERT 实现(如此处报告),Instructor 结果来自本文,SPLADEv2 结果取自本文,OpenAI 结果报告此处。 请注意,我们已将 OpenAI 结果分开,因为它们使用 BEIR 套件的不同子集。 具体来说,他们对 ArguAna、Climate FEVER、DBPedia、FEVER、FiQA、HotpotQA、NFCorpus、QuoraRetrieval、SciFact、TREC COVID 和 Touche 进行平均。 如果你点击该链接,您会发现他们还会报告以百分比表示的 NDCG@10。 我们建议读者访问上面的链接以获取有关这些方法的更多信息。

最后,我们注意到,人们广泛观察到,统计(BM25)和基于模型的检索或混合搜索的集成往往在零样本设置中表现优于任一方法。 在 8.8 中,Elastic 已经允许通过线性增强对 text_expansion 执行此操作,如果你校准数据集,则效果很好。 我们还在研究倒数排序融合(RRF),它在没有校准的情况下表现良好。 请继续关注本系列的下一篇博客,其中将讨论混合搜索。
在了解了我们的模型的表现之后,我们接下来讨论它的架构以及它如何训练的一些方面。
什么是学习稀疏模型以及它们为什么有吸引力?
我们在之前的博客文章中表明,虽然经过微调非常有效,但密集检索在零样本设置中往往表现不佳。 相比之下,跨编码器架构不能很好地扩展检索,但它倾向于学习强大的查询和文档表示,并且在大多数文本上都能很好地工作。 有人认为,造成这种差异的部分原因是查询和文档仅通过相对较低维度的向量 “点积(dot product)” 进行交互的瓶颈。 基于这一观察,最近提出了一些模型架构来尝试减少这一瓶颈,它们是 ColBERT 和 SPLADE。
从我们的角度来看,SPLADE 还有一些额外的优势:
- 与 ColBERT 相比,它的存储效率极高。 事实上,我们发现文档段落平均扩展到大约 100 个标记,并且我们看到与正常文本索引的大小大致相同。
- 有一些注意事项,检索可以使用倒排索引,我们在 Lucene 中已经有非常成熟的实现。 与人工神经网络相比,它们对内存的使用效率非常高。
- 它在训练时提供自然控制,使我们能够以检索质量换取检索延迟。 特别是,我们下面讨论的 FLOPS 正则化器允许人们为预期恢复成本的损失添加一项。 我们计划在迈向 GA 时利用这一点。
与密集检索相比,最后一个明显的优势是 SPLADE 允许人们通过一种简单且计算高效的路线来突出显示生成匹配的单词。 这简化了长文档中相关段落的显示,并帮助用户更好地了解检索器的工作原理。 总而言之,我们认为这些为我们首次发布此功能提供了采用 SPLADE 架构的令人信服的案例。
关于这个架构有很多很好的详细描述 —— 如果你有兴趣深入研究,例如,这是创建模型的团队写的一篇很好的文章。 简而言之,这个想法不是使用分布式表示,比如平均 BERT 标记输出嵌入,而是使用标记逻辑或标记预测的对数概率来进行屏蔽词预测。
当语言模型用于预测屏蔽词时,它们通过预测词汇表标记的概率分布来实现这一点。 WordPiece 的 BERT 词汇表包含许多常见的真实单词,例如 cat、house 等。 它还包含常见的词尾 —— 比如 ##ing(## 只是表示它是延续)。 由于单词不能任意交换,因此对于任何给定的掩码位置将预测相对较少的标记。 SPLADE 将通过屏蔽文本中每个单词最强烈预测的标记作为表示一段文本的起点。 如前所述,这是该文本的自然解缠或稀疏表示。

将单词预测的这些标记概率视为粗略地捕获上下文同义词是合理的。 这导致人们将学习到的稀疏表示(例如 SPLADE)视为接近文本自动同义词扩展的东西,我们在该模型的多个在线解释中看到了这一点。
我们认为,这往好了说是过于简单化,往坏了说是误导。 SPLADE 以微调一段文本的最大 token logits 为起点,但随后会训练相关的预测任务,该任务至关重要地考虑了查询和文档中所有共享 token 之间的交互。 这个过程在某种程度上重新缠结了标记,这些标记开始表现得更像向量表示的组件(尽管在非常高维的向量空间中)。
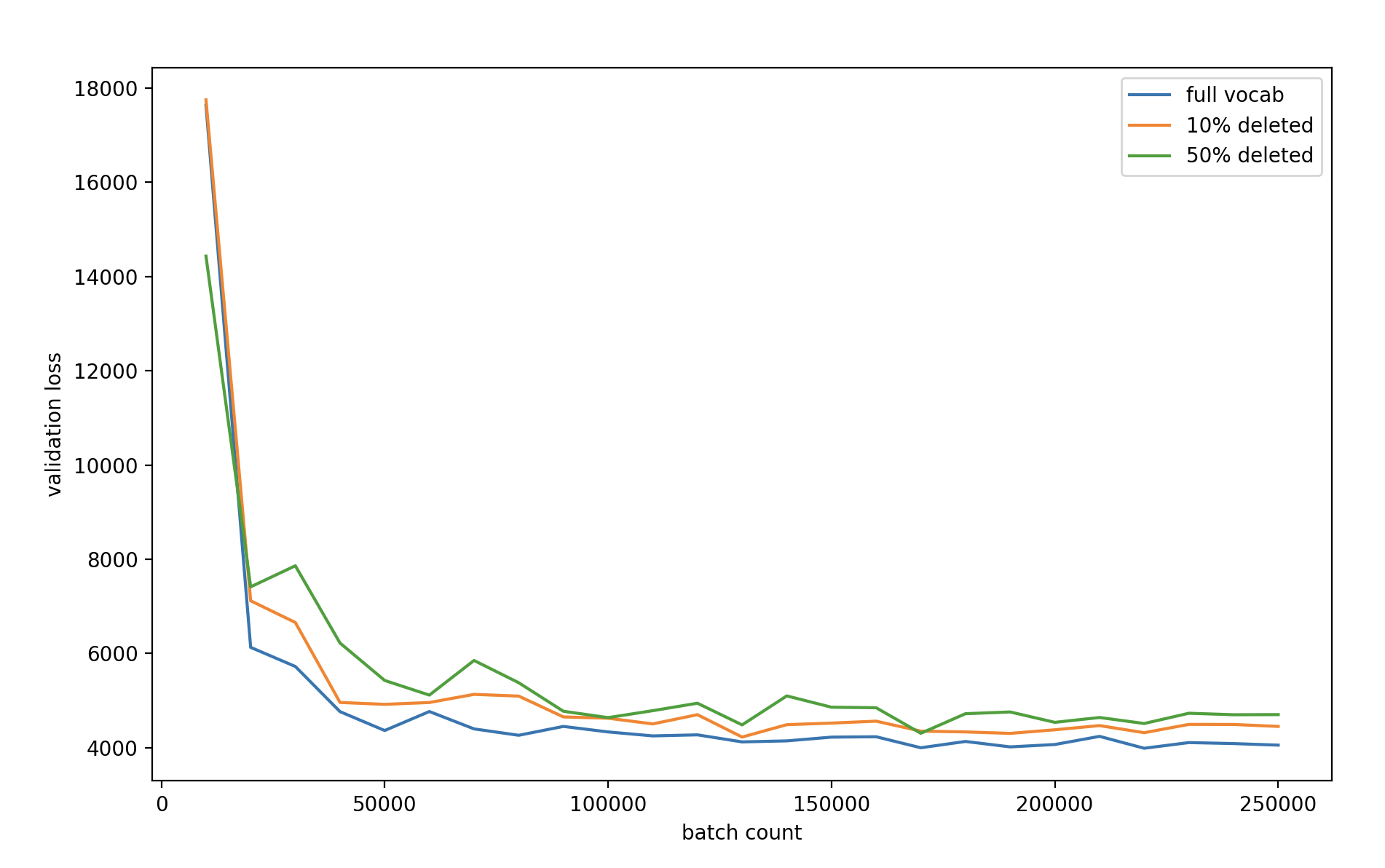
我们在开展这个项目时对此进行了一些探索。 当我们尝试在事后扩展中删除低分和明显不相关的标记时,我们发现它降低了基准套件中的所有质量指标,包括精度(!)。 如果它们的行为更像分布式向量表示,则可以解释这一点,其中将各个组件归零显然是无意义的。 我们还观察到,我们可以简单地随机删除 BERT 的大部分词汇,并且仍然训练高效的模型,如下图所示。 在这种情况下,必须重新调整部分词汇的用途,以弥补缺失的单词。
最后,我们注意到,与规模确实非常重要的生成任务不同,检索并没有明显受益于拥有庞大的模型。 我们在结果部分看到,与一些较大的生成模型中的数亿甚至数十亿参数相比,这种方法仅用 100M 参数就能实现近乎最先进的性能。 典型的搜索应用程序对查询延迟和吞吐量有相当严格的要求,因此这是一个真正的优势。
探索训练设计空间
在我们的第一篇博客中,我们介绍了有关训练密集检索模型的一些想法。 实际上,这是一个多阶段过程,通常会选择一个已经经过预训练的模型。 此预训练任务对于在特定下游任务上获得最佳结果非常重要。 我们不会进一步讨论这个问题,因为迄今为止这还不是我们的重点,但请注意,像许多当前有效的检索模型一样,我们从 co-condenser pre-trained model 开始。
设计训练管道时,有许多潜在的途径可供探索。 我们探索了很多,可以说,我们发现对基准进行持续改进具有挑战性。 许多在纸面上看起来很有希望的想法并没有带来令人信服的改进。 为了避免这篇博客变得太长,我们首先快速概述训练任务的关键要素,并重点介绍我们引入的一项新颖性,它提供了最显着的改进。 独立于具体因素,我们还对 FLOPS 正则化的作用进行了一些定性和定量观察,我们将在最后讨论。
在训练检索模型时,有两种常见的范式:对比方法和蒸馏方法。 我们采用蒸馏方法是因为这在本文中被证明对于训练 SPLADE 非常有效。 蒸馏方法与常见范式略有不同,后者将大型模型缩小为小型但几乎同样准确的 “副本”。 相反,这个想法是提取交叉编码器架构中存在的排名信息。 这提出了一个小小的技术挑战:由于表示不同,因此目前还不清楚应该如何通过正在训练的模型来模仿交叉编码器的行为。 我们使用的标准思想是用三元组(query、relevant docuemnt、irrelevent document)的形式呈现两个模型。 教师模型(teacher model)计算分数差,即 score(query, relevant document) − score(query, irrelevant document),我们训练学生模型(student model)使用 MSE 重现该分数差,以惩罚其所犯的错误。
让我们思考一下这个过程的作用,因为它激发了我们希望讨论的训练细节。 如果我们回想起使用 SPLADE 架构的查询和文档之间的交互是使用每个标记的非负权重的两个稀疏向量之间的点积来计算的,那么我们可以将此操作视为想要增加查询和得分最高的文档权重向量。 将此视为类似于将两个文档的权重向量跨越的平面中的查询 “旋转” 到最相关的一个,这不是 100% 准确,但不会产生误导。 在许多批次中,此过程逐渐调整权重向量的起始位置,以便查询和文档之间的距离捕获教师模型提供的相关性分数。
这导致了对复制教师分数的可行性的观察。 在正常的蒸馏中,我们知道只要有足够的能力,学生就能够将训练损失减少到零。 跨编码器蒸馏的情况并非如此,因为学生分数受到其权重向量上的点积引起的度量空间属性的约束。 交叉编码器没有这样的约束。 对于特定的训练查询 q1 和 q2 以及文档 d1 和 d2,我们很可能必须同时安排 q1 接近 d1 和 d2,以及安排 q2 接近 d1 但远离 d2。 这不一定是可能的,并且由于我们在分数中对 MSE 进行惩罚,因此一个效果是按照我们可以实现的最小余量对与这些查询和文档相关的训练三元组进行任意重新加权。
我们在训练模型时得到的观察之一是老师远非绝对正确。 我们最初通过手动调查被分配异常低分的查询相关文档对来观察到这一点。 在此过程中,我们客观地发现了遗漏的 query - document 对。 除了评分过程中的人工干预之外,我们还决定探索引入更好的老师。
根据文献,我们使用 SBERT 系列的 MiniLM L-6 作为我们的初始老师。 虽然这显示了在多种环境下的强劲表现,但根据他们的排名质量,有更好的教师。 一个例子是基于大型生成模型的排名器:monot5 3b。 下图中,我们比较了这两个模型的 query - document 得分对分布。monot5 3b 分布显然不太均匀,我们发现当我们尝试使用其原始分数训练学生模型时,性能饱和度明显低于使用 MiniLM L-6 作为老师的情况。 和以前一样,我们假设这归因于在零附近峰值中的许多重要分数差异,训练担心而不是与长下尾相关的无法解决的问题而迷失。
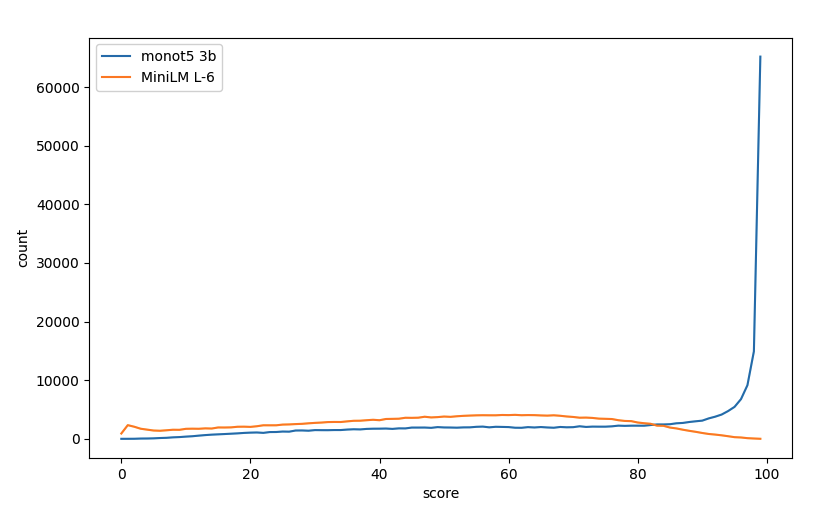
很明显,所有排名者在其分数的单调变换方面都具有相同的质量。 具体来说,只要 f 是单调递增函数,我们使用 Score(query, document) 还是 f(score(query, document)) 都没有关系; 任何排名质量衡量标准都是相同的。 然而,并非所有这些职能都是同等有效的教师。 我们利用这一事实来平滑 monot5 3b 分数的分布,突然间我们的学生模型经过训练并开始击败之前的最佳模型。 最后,我们使用了两位老师的加权合奏。
在结束本节之前,我们想简单提一下 FLOPS 正则化器。 这是改进的 SPLADE v2 训练过程的关键要素。 本文提出了一种惩罚与倒排索引检索的计算成本直接相关的指标的方法。 特别是,它鼓励根据对倒排索引检索成本的影响,从查询和文档表示中删除那些提供很少排名信息的标记。 我们有三个观察结果:
- 我们的第一个观察结果是,当正则化器仍在预热时,绝大多数 token 实际上已被丢弃。 在我们的训练方案中,正则化器对前 50,000 个批次使用二次预热。 这意味着在前 10,000 个批次中,它不超过其最终值的 1/25 th,而且我们确实看到,此时分数裕度中 MSE 对损失的贡献比正则化损失大几个数量级。 然而,在此期间,训练数据激活的每批查询和文档标记的数量分别从平均 4k 和 14k 左右下降到 50 和 300 左右。 事实上,99% 的 token 修剪都发生在这个阶段,并且似乎很大程度上是由删除实际上损害排名性能的 token 驱动的。
- 我们的第二个观察结果是,我们发现它有助于检索模型的泛化性能。 减少正则化的数量并替换导致更多稀疏性的正则化器(例如绝对权重值的总和),都会降低我们基准测试的平均排名性能。
- 我们的最终观察结果是,较大批次和多样化批次都会对检索质量产生积极影响。
既然它的主要目的是优化召回成本,那么为什么会这样呢? FLOPS 正则化器定义如下:它首先对所有查询中的每个标记的权重进行平均,并分别对其包含的文档进行平均,然后将这些平均权重的平方相加。 如果我们认为该批次通常包含一组不同的查询和文档,那么这就像一种惩罚,鼓励类似的措施停止单词删除。 针对许多不同查询和文档出现的 token 将主导损失,因为很少激活的 token 的贡献除以批量大小的平方。 我们假设这实际上有助于模型找到更好的检索表示。 从这个角度来看,正则化项只能观察批次中查询和文档的 token 权重,这一事实是不可取的。 这是我们想重新审视的一个领域。
结论
我们简要概述了模型选择、其基本原理以及我们在新的 text_expansion 查询的技术预览中发布的功能背后的训练过程的某些方面,以及与新的 Elasticsearch 相关性引擎的集成。 迄今为止,我们专注于零样本设置中的检索质量,并在各种强大的基线上展示了良好的结果。 随着我们向 GA 迈进,我们计划在该模型的实施方面做更多的工作,特别是围绕提高推理和检索性能。
请继续关注本系列的下一篇博客文章,我们将在继续探索使用 Elasticsearch 的令人兴奋的新检索方法的同时,研究使用混合检索来组合各种检索方法。
Improving information retrieval in the Elastic Stack: Introducing Elastic Learned Sparse Encoder, our new retrieval model | Elastic Blog