差分升级算法研究及改进
文件差分算法通过对不同文件的片段进行对比查找差异,将差异描述输出为差分文件。
差分算法是差分升级的关键技术,因此,差分算法的性能决定着整个升级系统的性能。
差分算法研究
差分更新又称为增量编码,差分字节升级文件仅包括固件版本间字节的差别描述,因此所形成的文件远比固件版本文件小。
可以通过无线固件升级的软件包括系统、驱动等。
字节差分算法通过降低升级包大小从而降低数据传输成本。
因此,如何将生成的差分文件压缩到最小,成为各软件技术提供商竞争的核心方面。
很大一部分的文件差分算法均基于LCS(最长公共子序列)问题,旨在找出醉相思的片段进行二进制文件之间的差异描述与字节替换。
在差分算法中,目前应用最广泛的是Bsdiff和Xdetla算法,在UNIX系统和一些现代软件例如Chrome中,就采用基于Bsdiff算法的方式进行文件的增量描述,并且被大量运用于移动互联网云存储领域、手机操作系统更新。
Bsdiff
Bsdiff是一种基于LCS问题的差分算法,采用近似匹配算法对文件进行比对。
Bsdiff中采用了后缀字典排序算法,使整个匹配过程可以按照二分查找进行,从而达到O(log N)的查找时间,具体流程如下:
- 输入旧版本文件OLD
- 获取文件的后缀数组
- 将后缀数组进行字典排序数组I
- 递归二分查找新版本文件的相似片段。
后缀排序使用qsufsort算法,例如,旧版本文件为“Bsdifff”,qsufsort算法会生成“f”,“ff”,“iff”,“diff”,“sdiff”,“Bsdiff”的完整后缀数组。
之后使用快速排序将数组按字典序排序,即为“Bsdiff”,“fidd”,“f”,“ff”,“iff”,“sdiff”。该算法生成的数组I即为字典序数组在old文件中所存在的起始位置,在本例中,数组为I={0,2,5,4,3,1}。
而Bsdiff就是利用qsufsort生成的数组进行文件之间的相似字节匹配。
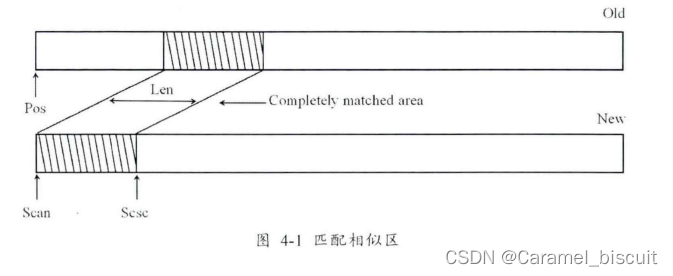
在新旧版本匹配时,新版本文件指针为Scan,旧版本文件指针为Pos,Scan每向前移动一步,就调用递归二分查找找到新旧版文件匹配字节数最长的位置并返回匹配匹配长度len。其中Completely matched area为完全匹配区域,代表这个区域的新旧版本文件是完全相同的。
递归二分查找算法search的关键代码如下,其中,newsize为新版本文件字节长度,oldsize为旧版本文件字节长度,scan为新版本文件中的文件指针,pos为旧版本文件中的文件指针,x为当前查找的数据在数组I中的位置,st代表二分区间起始位置,en代表二分区间结束位置。
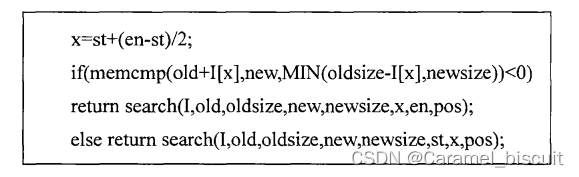
在Bsdiff算法中,关键步骤为寻找近似匹配区域,这个近似匹配区域“黏附”在完全匹配区的左右,近似匹配区域的存在是为了减小Patch差分文件的大小。

![单元测试报错 No tests found for given includes: [StudyApplicationTests.contextLoads]](https://img-blog.csdnimg.cn/27f52c21f2cf4bd1a0b3ae9336214576.png)