🥳🥳Welcome Huihui's Code World ! !🥳🥳
接下来看看由辉辉所写的关于MySQL数据库的相关操作吧
目录
🥳🥳Welcome Huihui's Code World ! !🥳🥳
导读:
一.数据库的连表查询是什么
二.连表查询有几种常见类型
1. 内连接(INNER JOIN):
概念:
适用场景:
语法:
2. 左连接(LEFT JOIN):
概念:
适用场景:
语法:
3. 右连接(RIGHT JOIN):
概念:
适用场景:
语法:
4. 全连接(FULL JOIN):
概念:
适用场景:
语法:
5. 自连接(Self Join):
概念:
适用场景:
语法:
三. 高级子查询和连表查询有什么区别和联系
四.聚合函数怎么使用
五. 常见的CRUD面试题
1.查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数
代码
结果
2.查询同时存在" 01 "课程和" 02 "课程的情况
代码
结果
3.查询存在" 01 "课程但可能不存在" 02 "课程的情况(不存在时显示为 null )
代码
结果
4.查询不存在" 01 "课程但存在" 02 "课程的情况
代码
结果
5.查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
代码
结果
6.查询在t_mysql_score表存在成绩的学生信息
代码
结果
7.查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )
代码
结果
8.查询「李」姓老师的数量
代码
结果
💡💡辉辉小贴士:(面试题)drop,delete,truncate有什么区别与联系?
💡💡辉辉小贴士:为什么要使用行转列,怎么操作
导读:
前面两篇已经讲到了数据库的增删改查等基本的sql语句,以及数据库引擎的讲解。那么这一片我们就来讲一讲关于MySQL的综合练习(常见的增删改查的面试题)在进行练习之前,我们还需要了解一些专业知识!!👇👇
一.数据库的连表查询是什么
- 数据库的连表查询是一种在关系型数据库中使用多个表进行查询的技术。当数据库中的数据分布在不同的表中,但这些表之间存在关联关系时,我们可以使用连表查询来获取所需的数据结果
- 连表查询通过使用表之间的关联键(常见的是主键和外键)来连接多个表,并根据指定的条件来匹配相关的数据行。这样可以从多个表中获取需要的数据,并将它们组合成一个结果集
- 连表查询可以实现更复杂、更灵活的数据分析和处理。通过连接多个表,我们可以按照不同的条件进行数据筛选、排序、分组和统计。这使得我们能够更精确地检索和分析数据,从而满足更复杂的查询需求
- 使用连表查询时,常见的操作包括内连接(INNER JOIN)、左连接(LEFT JOIN)、右连接(RIGHT JOIN)和全连接(FULL JOIN)。这些操作根据表之间的关联方式和数据需求来确定所需的查询类型
⭐⭐总之,连表查询是一种强大的数据库查询技术,可以在多个表之间建立关联,实现跨表查询和数据分析。它有助于提高数据处理的灵活性和效率
二.连表查询有几种常见类型
1. 内连接(INNER JOIN):
概念:
内连接是最常用的连表查询类型之一。它返回两个表中满足连接条件的匹配行。只有在连接条件匹配的情况下,两个表中的数据才会被返回,即两个表中连接字段的值相等的行
适用场景:
- 当你只需要获取两个表中匹配的数据,并且丢弃不匹配的数据时,内连接是最常用的类型。例如,查询订单表中与产品表中匹配的订单信息
语法:
SELECT 列名 FROM 表A INNER JOIN 表B ON 表A.列 = 表B.列;2. 左连接(LEFT JOIN):
概念:
- 左连接返回左表中的所有行以及右表中与左表满足连接条件的匹配行。如果右表中没有匹配的行,将返回 NULL 值
适用场景:
- 当你想获取左表的所有数据,并根据连接条件获取右表的匹配数据时,使用左连接。例如,查询所有客户的订单信息,即使客户没有下过订单
语法:
SELECT 列名 FROM 表A LEFT JOIN 表B ON 表A.列 = 表B.列;3. 右连接(RIGHT JOIN):
概念:
- 右连接是左连接的反向操作。它返回右表中的所有行以及左表中与右表满足连接条件的匹配行。如果左表中没有匹配的行,将返回 NULL 值
适用场景:
- 和左连接类似,右连接适用于当你想获取右表的所有数据,并根据连接条件获取左表的匹配数据的场景
语法:
SELECT 列名 FROM 表A RIGHT JOIN 表B ON 表A.列 = 表B.列;4. 全连接(FULL JOIN):
概念:
- 全连接返回两个表中的所有行,无论是否满足连接条件。如果某个表中没有匹配的行,将返回 NULL 值
适用场景:
- 当你想获取两个表的所有数据,并且不关心数据是否匹配的场景。需要注意的是,全连接在一些数据库中可能比较少用
语法:
SELECT 列名 FROM 表A FULL JOIN 表B ON 表A.列 = 表B.列;5. 自连接(Self Join):
概念:
- 自连接是指将一个表与自身进行连接。通常在表中存在层次结构或者需要与自身进行比较时使用。自连接能够模拟树状结构或者其他层次结构,使用自连接可以解决一些具有层级关系或者需要对比自身行的查询需求
适用场景:
- 自连接通常在表中存在层次结构或者需要与自身进行比较时使用。例如,获取员工与其直接上级的关联信息,或者获取产品的父产品和子产品等
语法:
SELECT 列名 FROM 表名 AS A JOIN 表名 AS B ON A.列 = B.列;⭐⭐除了上述常见的类型,还可以使用多种连表查询的组合和嵌套来实现更复杂的查询需求。综合运用这些查询类型,可以满足不同场景下的数据关联和分析需求
三. 高级子查询和连表查询有什么区别和联系
众所周知,高级子查询和连表查询都可以处理多个表的连接查询,那么它们之间有什么联系吗?
- 区别:
- 1. 查询的方式:连表查询是通过连接两个或多个表的字段来检索数据,以获取关联数据。而子查询是将一个查询嵌套在另一个查询中,并利用内部查询的结果作为外部查询的条件或数据源
- 2. 返回的结果:连表查询返回的结果是经过连接后的数据集,包含多个表中的关联数据。而子查询返回的结果是用于外部查询的条件或数据源的单个列、单行或单个值
- 联系:
- 1. 组合使用:连表查询和子查询可以结合使用,以便更灵活地获取所需的数据。例如,在连表查询的基础上,使用子查询来进一步过滤数据或进行计算
- 2. 数据分析需求:连表查询和子查询在处理复杂的数据分析或报表需求时经常结合使用。通过连表查询可以获取多个表之间的关联数据,而子查询则可以对这些数据进行进一步的筛选、过滤、排序或计算操作
- 3. 性能优化:在某些场景下,子查询可以用作优化连表查询的手段。通过使用子查询,可以将大型查询拆分成较小的、更容易优化和调整的子查询
⭐⭐总的来说,连表查询和子查询是处理复杂查询需求的两种常用方法。连表查询通过连接两个或多个表来检索数据,而子查询则将查询嵌套在另一个查询中,用于提供条件或数据源。它们可以独立使用,也可以结合使用,以满足更复杂的查询需求
四.聚合函数怎么使用
聚合函数用于对一组数据进行聚合计算,例如求和、计数、平均值等。使用聚合函数可以对数据进行汇总和分析,提供有关数据集的统计信息
在使用聚合函数时,需要满足以下要求和注意事项:
- 1. 适当的字段选择:聚合函数通常用于对特定字段进行计算。你需要选择合适的字段来进行聚合操作,例如求和的字段、计数的字段等。
- 2. GROUP BY 子句:当你希望对数据按照某个列进行分组计算时,需要使用 GROUP BY 子句。聚合函数会对每个分组中的数据进行计算,返回每个分组的聚合结果。在使用 GROUP BY 子句时,查询结果通常会包括 GROUP BY 中的列以及聚合函数的计算结果
- 3. 过滤条件(HAVING 子句):在进行聚合计算时,你可以使用 HAVING 子句来对分组后的数据进行过滤。HAVING 子句的使用方式与 WHERE 子句类似,但它作用于聚合后的结果
- 4. 区分聚合和非聚合列:聚合函数的计算结果会在每个分组中生成一行数据,而非聚合列的取值必须依赖于 GROUP BY 列。因此,你需要清楚区分哪些列是用于分组的列(GROUP BY 列),哪些列是聚合函数计算的结果
- 5. 注意 NULL 值:聚合函数在计算过程中会忽略 NULL 值,除非使用了相关的修饰符(如COUNT(*)可以计算NULL值的数量)。因此,在使用聚合函数时需要考虑 NULL 值的存在
常见的聚合函数:
SUM 计算指定列的总和 COUNT 计算指定列的非 NULL 值的数量 AVG 计算指定列的平均值 MAX 计算指定列的最大值 MIN 计算指定列的最小值
五. 常见的CRUD面试题
所有的题目基于下列表👇👇
-- 1.学生表-t_mysql_student
-- sid 学生编号,sname 学生姓名,sage 学生年龄,ssex 学生性别
-- 学生表
insert into t_mysql_student values('01' , '赵雷' , '1990-01-01' , '男');
insert into t_mysql_student values('02' , '钱电' , '1990-12-21' , '男');
insert into t_mysql_student values('03' , '孙风' , '1990-12-20' , '男');
insert into t_mysql_student values('04' , '李云' , '1990-12-06' , '男');
insert into t_mysql_student values('05' , '周梅' , '1991-12-01' , '女');
insert into t_mysql_student values('06' , '吴兰' , '1992-01-01' , '女');
insert into t_mysql_student values('07' , '郑竹' , '1989-01-01' , '女');
insert into t_mysql_student values('09' , '张三' , '2017-12-20' , '女');
insert into t_mysql_student values('10' , '李四' , '2017-12-25' , '女');
insert into t_mysql_student values('11' , '李四' , '2012-06-06' , '女');
insert into t_mysql_student values('12' , '赵六' , '2013-06-13' , '女');
insert into t_mysql_student values('13' , '孙七' , '2014-06-01' , '女');
-- 2.教师表-t_mysql_teacher
-- tid 教师编号,tname 教师名称
-- 教师表
insert into t_mysql_teacher values('01' , '张三');
insert into t_mysql_teacher values('02' , '李四');
insert into t_mysql_teacher values('03' , '王五');
-- 3.课程表-t_mysql_course
-- cid 课程编号,cname 课程名称,tid 教师名称
-- 课程表
insert into t_mysql_course values('01' , '语文' , '02');
insert into t_mysql_course values('02' , '数学' , '01');
insert into t_mysql_course values('03' , '英语' , '03');
-- 4.成绩表-t_mysql_score
-- sid 学生编号,cid 课程编号,score 成绩
-- 成绩表
insert into t_mysql_score values('01' , '01' , 80);
insert into t_mysql_score values('01' , '02' , 90);
insert into t_mysql_score values('01' , '03' , 99);
insert into t_mysql_score values('02' , '01' , 70);
insert into t_mysql_score values('02' , '02' , 60);
insert into t_mysql_score values('02' , '03' , 80);
insert into t_mysql_score values('03' , '01' , 80);
insert into t_mysql_score values('03' , '02' , 80);
insert into t_mysql_score values('03' , '03' , 80);
insert into t_mysql_score values('04' , '01' , 50);
insert into t_mysql_score values('04' , '02' , 30);
insert into t_mysql_score values('04' , '03' , 20);
insert into t_mysql_score values('05' , '01' , 76);
insert into t_mysql_score values('05' , '02' , 87);
insert into t_mysql_score values('06' , '01' , 31);
insert into t_mysql_score values('06' , '03' , 34);
insert into t_mysql_score values('07' , '02' , 89);
insert into t_mysql_score values('07' , '03' , 98);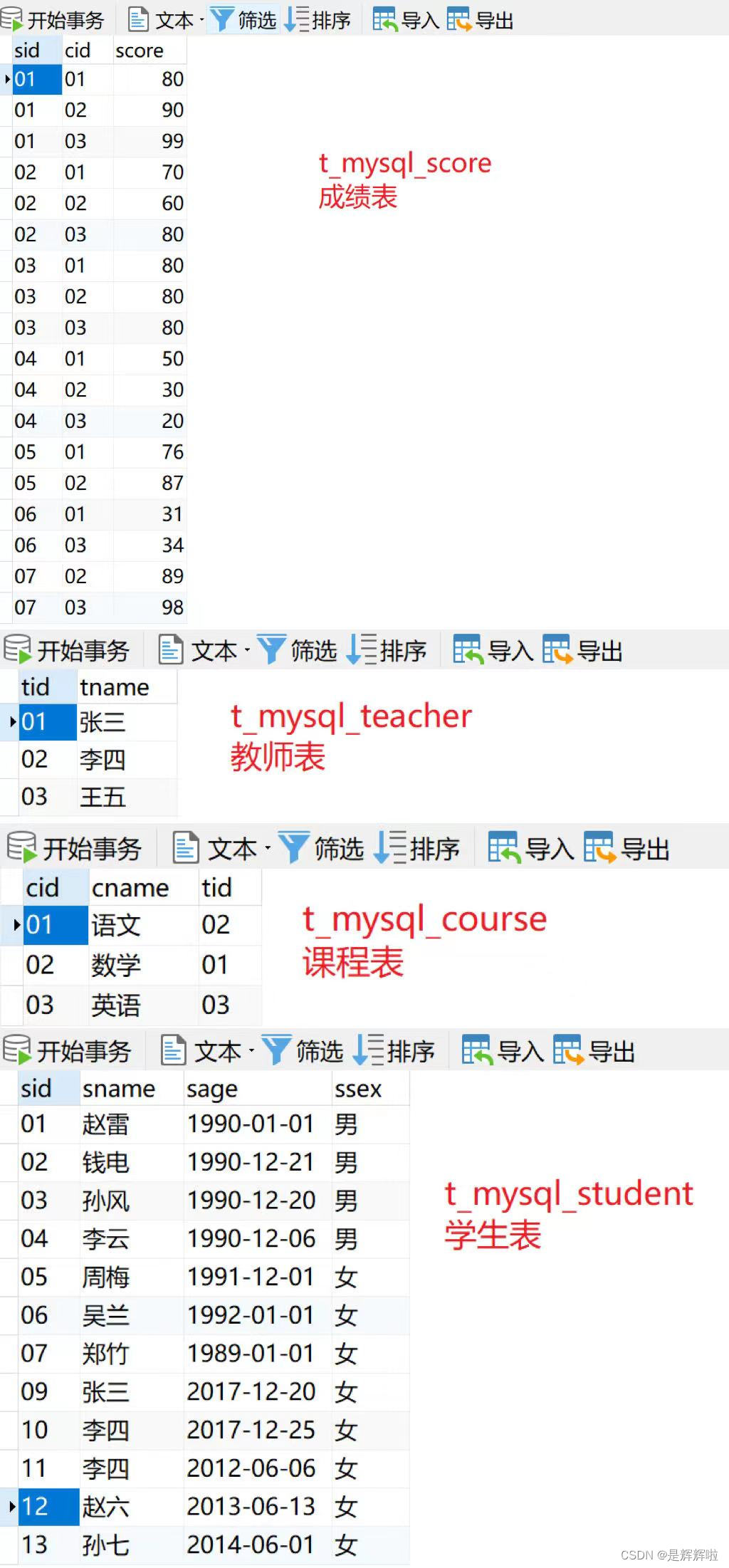
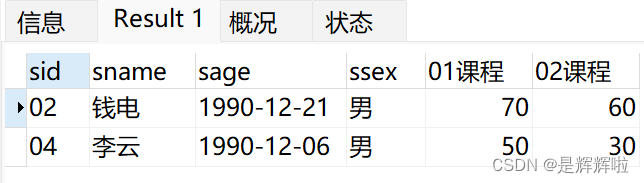
1.查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数
代码
分析:
t_mysql_score&t_mysql_student
1.先查询01课程的分数
2.再查询02课程的分数
3.比较成绩
4.然后查询学生的信息和分数
SELECT
t3.*,
t1.score 01课程,
t2.score 02课程
FROM
( SELECT * FROM t_mysql_score sc WHERE sc.cid = '01' ) t1,
( SELECT * FROM t_mysql_score sc WHERE sc.cid = '02' ) t2,
t_mysql_student t3
WHERE
t1.sid = t2.sid
AND t1.sid = t3.sid
AND t1.score > t2.score
结果
2.查询同时存在" 01 "课程和" 02 "课程的情况
代码
分析:
t_mysql_score&t_mysql_student
1.先查询01课程的分数
2.再查询02课程的分数
3.然后查询学生的信息和分数
SELECT
t3.*,
t1.score 01课程,
t2.score 02课程
FROM
( SELECT * FROM t_mysql_score sc WHERE sc.cid = '01' ) t1,
( SELECT * FROM t_mysql_score sc WHERE sc.cid = '02' ) t2,
t_mysql_student t3
WHERE
t1.sid = t2.sid
AND t1.sid = t3.sid
结果
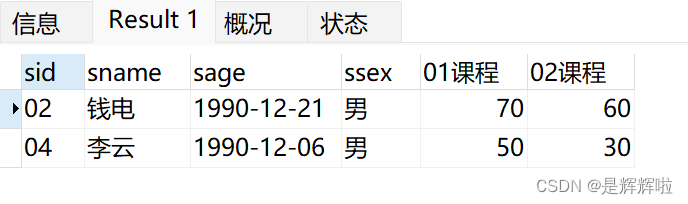
3.查询存在" 01 "课程但可能不存在" 02 "课程的情况(不存在时显示为 null )
代码
分析:
t_mysql_score&t_mysql_student
1.存在" 01 "课程但可能不存在" 02 "课程
2.➡连表(01为主表,02为从表)
SELECT
t1.* ,t2.score from ( SELECT * FROM t_mysql_score sc WHERE sc.cid = '01' ) t1
LEFT JOIN ( SELECT * FROM t_mysql_score sc WHERE sc.cid = '02' ) t2 ON t1.sid = t2.sid结果
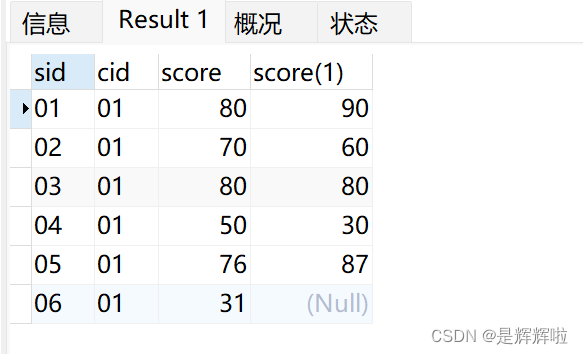
4.查询不存在" 01 "课程但存在" 02 "课程的情况
代码
分析:
1.先查询到01课程
2.排除有01课程的学生(id)
3.再查询选择了02课程的学生(id)
select * from t_mysql_score sc where sc.sid not in
( SELECT sc.sid FROM t_mysql_score sc WHERE sc.cid = '01' ) and sc.cid='02'结果
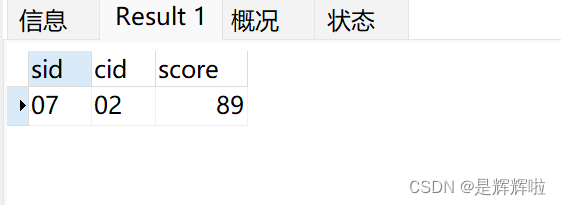
5.查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
代码
分析:
t_mysql_score&t_mysql_student
1.平均成绩➡聚合函数➡分组
2.分组的字段➡学生编号和学生姓名
SELECT
s.sid,
s.sname,
ROUND( AVG( sc.score ) )
FROM
t_mysql_student s,
t_mysql_score sc
WHERE
s.sid = sc.sid
GROUP BY
s.sid,
s.sname
HAVING
AVG( sc.score ) >= 60
结果
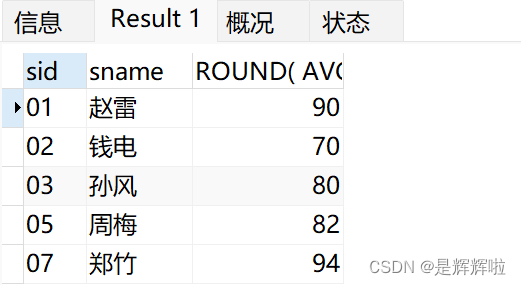
6.查询在t_mysql_score表存在成绩的学生信息
代码
分析:
t_mysql_score&t_mysql_student
1.学生的编号在t_mysql_score中➡说明此表中存在这个学生的信息
SELECT
*
FROM
t_mysql_student s
WHERE
s.sid IN ( SELECT sc.sid FROM t_mysql_score sc )结果
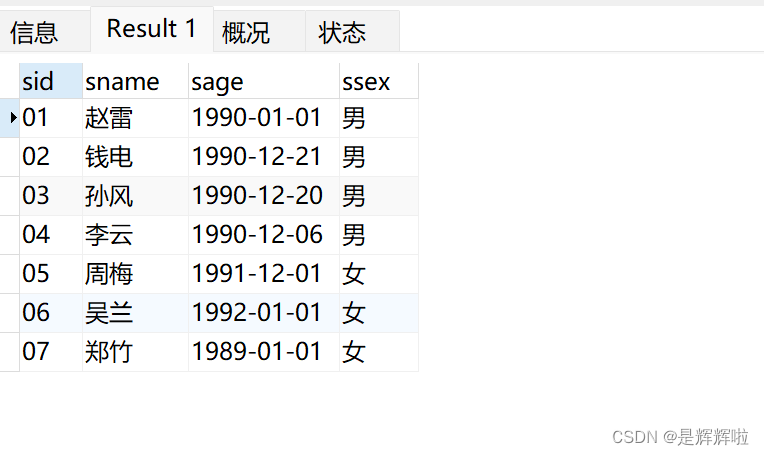
7.查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )
代码
分析:
t_mysql_score&t_mysql_student
1.题中出现的信息来源于两张表➡需要同时出现➡连表查询
2.总数,总成绩➡聚合函数➡分组
3.分组字段学生编号,学生姓名
select t1.sid,t1.sname,SUM(t2.score) 总成绩,COUNT(t2.cid)选课总数 from
(select * from t_mysql_student)t1 left join
(select * from t_mysql_score)t2 on t1.sid=t2.sid
GROUP BY t1.sid,t1.sname结果
8.查询「李」姓老师的数量
代码
select COUNT(*) from t_mysql_teacher where tname like '李%'结果

💡💡辉辉小贴士:(面试题)drop,delete,truncate有什么区别与联系?
- 1. 区别:
- - `DROP`用于删除数据库对象,可以是表、视图、索引、约束等。使用`DROP`命令后,相关的对象及其所有数据将被完全删除,无法恢复
- - `DELETE`用于从表中删除满足指定条件的行。使用`DELETE`操作后,被删除的数据被放入事务日志,可以使用回滚操作进行还原(如果事务未提交)
- - `TRUNCATE`用于删除表中的所有数据,但保留表的结构。与`DELETE`不同,`TRUNCATE`操作是直接清空表中的数据,不记录在事务日志中,也无法进行回滚操作。`TRUNCATE`操作比`DELETE`操作更快速
- 2. 联系:
- - `DROP``、`DELETE`和`TRUNCATE`都可以用于删除表中的数据,但`TRUNCATE`是最快的方法
- - `DELETE`、TRUNCATE`操作都可以包含条件,用于指定需要删除的数据。而`DROP``操作删除的是整个数据库对象,而非数据行
- - `DELETE`和`TRUNCATE`可以在事务内进行,可以进行回滚操作。而`DROP`操作是立即执行的,无法回滚
- -`DROP`操作删除数据表及其相关对象,需要重新创建表结构。而`DELETE`和`TRUNCATE`只删除数据,保留表结构
⭐⭐总之,`DROP`、`DELETE`和`TRUNCATE`是针对关系型数据库中表和数据的不同操作命令。`DROP`用于删除整个数据库对象,`DELETE`用于删除满足条件的数据行,并可进行回滚操作,而`TRUNCATE`用于快速清空整个表的数据,无法回滚。根据实际需求,选择合适的操作命令进行数据操作
💡💡辉辉小贴士:为什么要使用行转列,怎么操作
使用行转列的主要目的是将原始的行级数据转换为列级数据,以便更方便地进行数据分析和报表制作。行转列可以在以下情况下发挥重要作用:
- 1. 数据展示和可读性:行转列可以为数据提供更直观的展示方式,让人更容易理解和分析数据。通过将原始数据中的行数据转换为列,可以更清晰地比较和查看不同类别的数据
- 2. 数据分析和聚合:行转列可以将多个行级数据进行聚合和汇总。在某些情况下,我们可能需要将一组记录中的多个属性进行聚合,以便更好地了解其中的模式和趋势
- 3. 报表和可视化需求:行转列可以满足报表和可视化需求,以便更好地呈现数据。通过将行数据转换为列,可以更轻松地生成透视表、图表或其他类型的可视化工具
使用 CASE 表达式根据条件将行数据转换为新的列,并使用聚合函数(如 MAX、MIN、SUM)对这些列值进行聚合操作。通过 GROUP BY 子句,我们可以按照指定的列进行分组
-- 01)查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数 t_mysql_score&t_mysql_student 1.先查询01课程的分数 2.再查询02课程的分数 3.比较成绩 4.然后查询学生的信息和分数 SELECT t3.*, ( CASE WHEN t1.cid = '01' THEN t1.score END ) 01课程 , ( CASE WHEN t2.cid = '02' THEN t2.score END ) 02课程 FROM ( SELECT * FROM t_mysql_score sc WHERE sc.cid = '01' ) t1, ( SELECT * FROM t_mysql_score sc WHERE sc.cid = '02' ) t2, t_mysql_student t3 WHERE t1.sid = t2.sid AND t1.sid = t3.sid AND t1.score > t2.score ----------------------------------------------------------------------------------------- -- 02)查询同时存在" 01 "课程和" 02 "课程的情况 t_mysql_score&t_mysql_student 1.先查询01课程的分数 2.再查询02课程的分数 3.然后查询学生的信息和分数 SELECT t3.*, ( CASE WHEN t1.cid = '01' THEN t1.score END ) 01课程 , ( CASE WHEN t2.cid = '02' THEN t2.score END ) 02课程 FROM ( SELECT * FROM t_mysql_score sc WHERE sc.cid = '01' ) t1, ( SELECT * FROM t_mysql_score sc WHERE sc.cid = '02' ) t2, t_mysql_student t3 WHERE t1.sid = t2.sid AND t1.sid = t3.sid⭐⭐同时,也可以根据具体的需求和场景考虑其他的行转列的操作方法,例如使用 PIVOT 函数或其他数据库特定的语法和函数
⭐⭐总而言之,行转列可以提供更清晰、更具可读性和更可分析的数据格式。它适用于数据展示、数据分析和报表制作等场景,操作方法可以根据数据库系统和需求灵活选择
好啦,今天的分享就到这了,希望能够帮到你呢!😊😊