计算机视觉
文章目录
- 计算机视觉
- 摘要
- 1.介绍
- 2.相关工作
- 3.方法
- 3.1框架
- 3.2 多层次特征表示
- 3.3 多路径融合体系结构
- 3.4 弱监督学习
- 4.实验
- 4.1 数据集
- 4.2 细节
- 4.3消融实验
- 4.4 与最新的形状文本检测方法的比较
- 5. 结论
论文地址:https://www.ijcai.org/Proceedings/2020/72
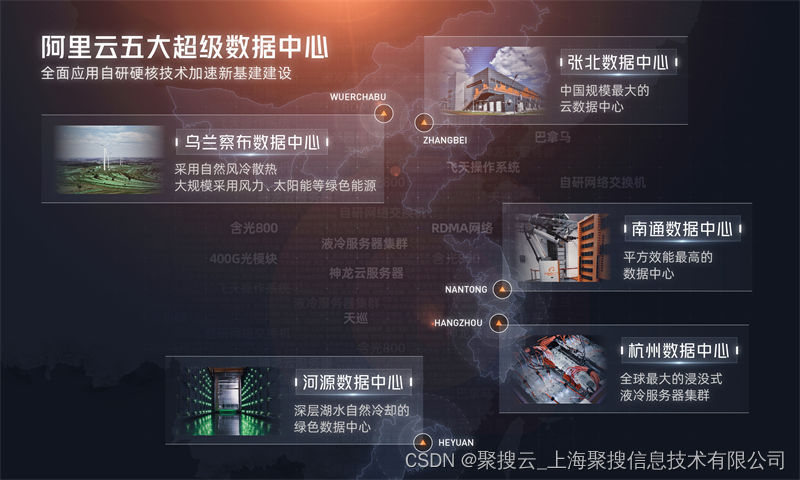
TextFuseNet:具有更丰富融合功能的场景文本检测
摘要
自然场景中任意形状文本的检测是一个极具挑战性的问题任务。不像现有的文本检测方法都是基于有限的特征表示,本文提出了一种新的文本检测框架TextFuseNet,以探索利用更丰富的特征融合进行文本检测。更具体地说,我们提出从字符、单词和全局三个层次的特征表示来感知文本,然后引入一种新的文本表示融合技术来实现鲁棒的任意文本检测。多层次特征表示可以在保持文本整体语义的同时,通过将文本分解为单个字符来精确地描述文本。然后,TextFuseNet通过一个多路径融合架构从不同的层次收集和融合文本的特征,有效地对齐和融合不同的文本陈述。在实践证明,我们提出的文本Fusenet可以对任意形状的文本进行更充分的描述,抑制假阳性,产生更准确的检测结果。我们提出的框架也可以通过弱监督来训练缺少字符级注释的那些静态集。多个数据集的实验表明,本文提出的TextFuseNet达到了最先进的性能。具体而言,2013年ICDAR2015年的F指标为94.3%,2015年为92.1%,总文本为87.1%,CTW-1500为86.6%。
1.介绍
场景文本检测在计算机视觉领域引起了越来越多的关注。随着深度学习的快速发展,我们取得了许多进展。然而,这项任务仍然具有挑战性,因为文本通常具有多种形状,文本检测器容易受到复杂背景、不规则形状和纹理干扰等问题的影响。

图1:常用的基于实例分割的方法(a)和我们提出的TextFuseNet(b)的结果的图示。绿色多边形表示正确的,红色多边形表示误报。
现有的方法主要有两种类型:基于字符的方法和基于单词的方法。基于字符的方法将文本视为多个角色。他们首先用精心设计的字符检测器提取字符,然后将它们分组成单词。然而,基于字符的方法通常是耗时的,因为文本检测产生大量的候选字符。与基于字符的方法不同,基于通用对象检测管道的基于词的方法被用来直接检测单词。这些方法虽然简单高效,但通常很难有效地检测任意形状的文本。为了解决这一问题,一些基于词的方法进一步应用到姿态分割中来进行文本检测。在这些方法中,估计前景分割蒙版有助于确定各种文本形状。现有的基于实例分割的方法虽然取得了良好的效果,但仍存在两个主要的局限性。首先,这些方法只检测基于单个感兴趣区域(RoI)的文本,而没有考虑全局上下文,因此在有限的视觉信息的基础上,往往会产生不准确的检测结果。其次,目前流行的方法没有对不同层次的单词语义进行建模,这会给文本检测带来误报的风险。图1显示了这些方法的一个示例。
本文提出了一种新的场景文本检测框架TextFuseNet,利用更丰富的融合特征有效地检测任意形状的文本。总之,我们遵循Mask R-CNN[Heet al.,2017]和MaskTextSpotter[Lyuet al.,2018]的方法,将文本检测任务作为一个实例分割任务。与这些方法不同,我们重铸了Mask R-CNN的原始管道,以能够分析和融合三个级别的特征表示,即字符,单词和全局级别的特征,以进行文本检测。特别是,我们首先在检测管道中引入了另一个语义分割分支,以帮助感知和提取全局级别的表示。 全局语义特征以后可以用来指导检测管道的检测和掩码分支。接下来,我们尝试在Mask R-CNN管道的检测和Mask分支内提取字符和单词级别的特征。 与原始Mask R-CNN不同,在检测和mask分支中,我们不仅检测并分割了单词实例,而且还检测了字符实例,并提供了字符级和词级表示形式。 在了解了三层表示之后,我们介绍了多路径特征融合体系结构,该体系结构通过多路径融合网络融合了字符,单词和全局层的特征,以促进TextFuseNet的学习 在实践中,考虑到一些现有的数据集缺少字符注释,我们进一步开发了一种弱监督学习方案,通过从词级学习来生成字符级注释。 带注释的数据集。 总体而言,TextFuseNet的体系结构如图2所示。
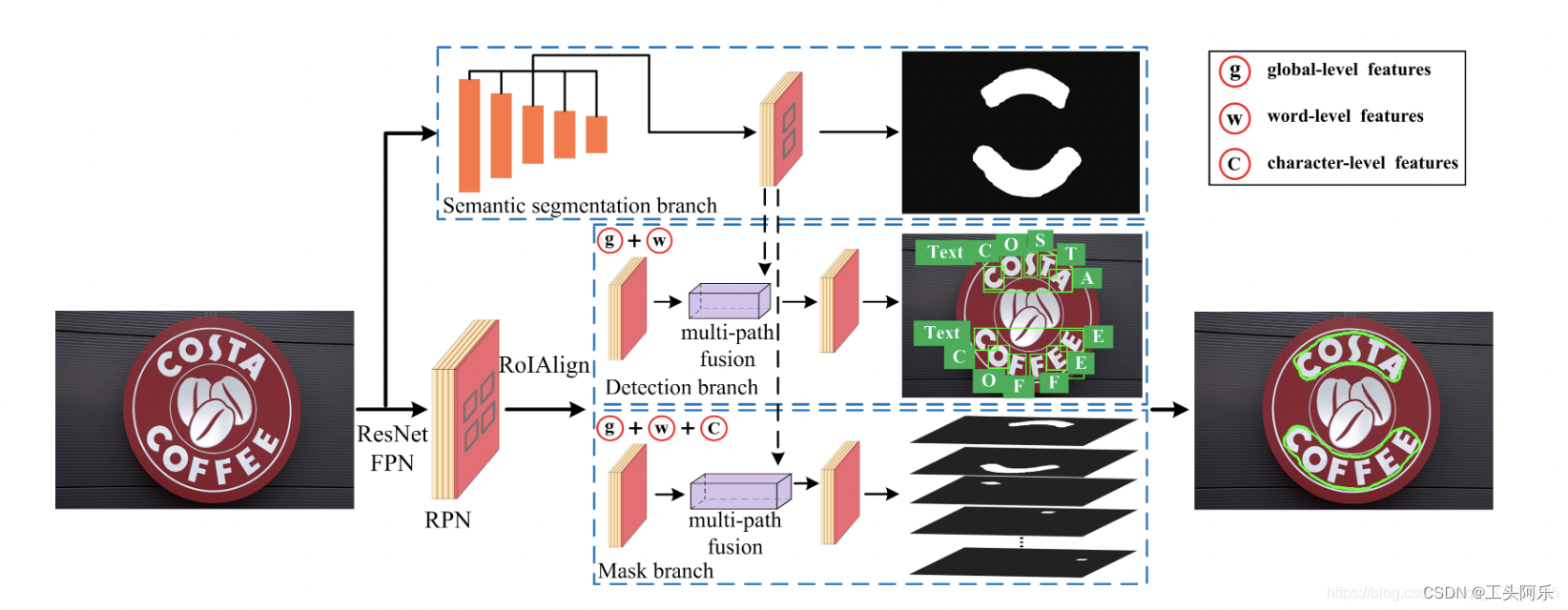
图2:拟议框架的总体流程。 我们提取并利用三个级别的特征表示,即文本的字符,词和全局级别特征。 我们还提出了多路径融合架构,以获取更丰富的融合特征以进行文本检测
这项工作的贡献包括三个方面:
(1)我们提出了一个新颖的框架TextFuseNet,该框架提取字符,单词和全局级别的特征,并引入多路径融合体系结构以融合它们以实现准确的融合。 文本检测
(2)基于提出的框架,引入了一种弱监督学习方案,该方案利用词级注解指导字符训练样本的搜索,实现了无注解的字符实例的有效学习。
(3)我们提出的框架可在包含任意形状文本的几个著名基准上实现最先进的性能。
2.相关工作
如上所述,现有的方法大致可以分为两大类,即基于字符的方法以及基于单词的方法。
基于字符的方法首先应用一些复杂的字符检测器,如SWT、MSER和FAS文本来提取候选字符。这些字符可以被字符/非字符分类器过滤以去除错误的候选字符。最后,根据先验知识或某些聚类/分组模型将剩余的字符分组为单词。然而,大多数基于字符的方法需要精心设计,涉及多个处理阶段,非常复杂,会导致误差积累。因此,基于字符的方法的性能总是非常耗时和次优的。
基于词的方法直接检测单词,主要受一般对象检测方法的启发。[Tianetal.,2016]提出了一个由CNN和RNN组成的连接主义文本建议网络(CTPN),通过连接一系列小文本框来检测整个文本行。受SD的启发,[Liao et al.,2018a]通过添加多个文本框层,提出了文本框及其扩展文本框+。[Shietal.,2017]提出了SegLink,通过使用全卷积网络(FCN)来检测文本段及其链接关系。根据文本段之间的关系,将文本段链接起来作为最终的检测结果。然而,这些方法只适用于水平或多方向的文本。
为了应对任意形状的文本的挑战,人们提出了许多基于实例分割的方法来检测任意形状的文本。[Dengetal。,2018]通过CNN进行文本/非文本预测和链接预测,并连接正样本 具有正向链接的像素,可以直接获取文本框而不进行回归。[Xieet等人,2019]提出了一种基于金字塔R-CNN的监督金字塔上下文网络(SPCNet)。[Wanget等人,2019a]提出了ProgressiveScale Expansion Network(PSENet)来检测具有任意形状的文本。[Tianet al。,2019]将像素映射到浮雕空间上,并引入了形状感知损失以使训练自适应地适应文本实例的各种长宽比。与以前的作品相比,我们分析和融合了更多不同层次的特征,以获得更丰富的融合特征,从而有效地提高了文本检测的性能。
3.方法
在这一节中,我们将描述如何通过语义分割、检测和掩模分支来提取多层次特征表示,以及如何使用多路径融合架构来融合它们。同时,我们还探讨了弱监督学习的字符级标注生成策略。
3.1框架
图2描述了TextFuseNet的总体架构。 在TextFuseNet中,我们首先提取多级特征表示,然后执行多路径融合以执行文本检测。 该框架主要由以下五个部分实现:以要素金字塔网络(FPN)作为提取多尺度特征图的主干;用于生成文本建议的区域建议网络(RPN);用于利用全局语义的语义分段分支;以及 用于检测单词和字符的检测分支以及用于对单词和字符进行分段的mask分支。
在TextFuseNet中,我们首先遵循Mask R-CNN和MaskTextSpotter,并使用ResNet作为FPN的主干。此外,我们使用RPN生成用于后续检测和Mask分支的文本建议。然后,为了提取多级特征表示,我们主要建议应用以下实现。首先,我们引入一个新的语义分割分支,对输入图像进行语义分割,并帮助获得全局级别的特征。然后,在通过预测文本提案的类别并采用边界框回归来优化文本提案的检测分支中,我们提取并融合了单词级和全局级特征以检测单词和字符。这与现有方法不同,现有方法仅侧重于为每个建议检测单个单词或字符。对于对从检测分支中检测到的对象执行实例分割的mask分支,我们提取并融合所有字符,单词和全局级别的功能以完成实例分割以及最终的文本检测任务。在3.2节中介绍了用于提取多级特征表示的详细网络配置。提取多特征后,我们提出了一种多路径融合架构,以融合不同特征以检测具有任意形状的文本。多路径融合体系结构可以有效地对齐和合并多级功能,以提供可靠的文本检测。第3.3节中介绍了多路径融合架构的实施细节。
3.2 多层次特征表示
通常,可以在检测器的检测和掩码分支内轻松获得字符和单词级别的功能。 我们可以通过检测建议中出现的单词和字符来实现此目的。 在此应用RoIAlign来提取不同的特征并同时检测单词和字符。
然而,我们需要一个新的网络在特征提取阶段帮助获得全局级的特征。因此,我们建议在检测器中进一步使用语义分割分支来提取全局级特征。 如图2所示,语义分割分支是基于FPN的输出构造的。 我们将所有要素的特征融合到一个统一的表示中,并对这个统一的表示进行分割,从而获得用于文本检测的全局分割结果。 在实践中,我们应用1 * 1卷积来对齐来自不同级别的特征的通道数,并将特征图的大小调整为相同的大小,以便以后统一。
3.3 多路径融合体系结构
获得多级特征后,我们在检测和掩码分支中均采用多路径融合。 在检测分支中,基于从RPN获得的文本建议,我们提取了全局和单词级别的特征以在不同路径上进行文本检测。 然后,我们将两种类型的功能融合在一起,以单词和字符的形式提供文本检测。 请注意,我们无法在检测分支中提取和融合字符级特征,因为在执行检测之前尚未识别出字符。 在实践中,给定生成的文本建议,我们使用RoIAlign从FPN的输出功能中提取7 * 7大小以内的全局和单词级功能。 我们通过逐元素求和将这些特征融合在一起,并将其馈入3 * 3卷积层和一个1 * 1层。 最终的融合特征用于分类和边界框回归。
在mask分支中,对于每个单词级别的实例,我们可以在多路径融合架构中融合相应的字符、单词和全局级别的特征,以进行站内分割。图3显示了多路径融合体系结构的详细说明。在该架构中,我们从不同的路径中提取多层次的特征,并将它们融合以获得更丰富的特征,以帮助学习更具区分性的表示。
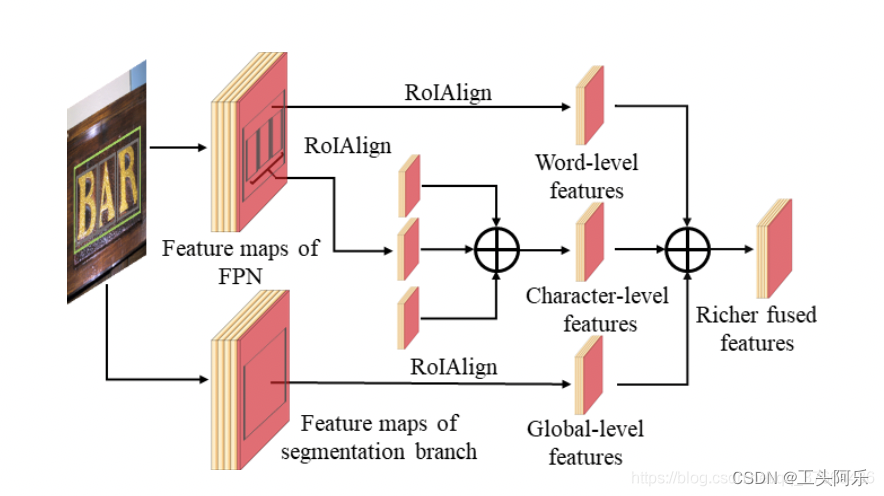
图3:mask分支中的多路径融合架构示意图。对于一个词的建议,我们在不同的路径上融合字符、单词和全局级别的特征,以获得更丰富的融合特征。
形式上,给定以ri表示的输入单词,我们首先根据其与字符交点在字符区域的交集比率,确定属于该词提议的字符结果Ci,这意味着如果单词框完全覆盖了该字符则比率为1,否则为0。 我们使用cj表示字符。 然后可以基于以下条件收集属于单词ri的字符Ci的集合:
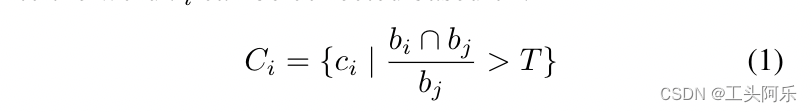
其中bi和bj分别是单词ri和字符实例cj的边界框,T是阈值。 在我们的实现中,我们将T = 0.8。
由于字符数量不是固定的,并且可能在零到数百之间,因此对于给定的检测词ri,我们将集合Ci中的字符特征融合为一个统一的表示形式。 特别是,我们首先使用RoIAlign为每个字符Ci提取大小为14 * 14的相应特征,然后通过逐元素求和将这些特征图融合在一起。 通过3 * 3卷积层和1 * 1卷积层,我们可以获得最终的字符级特征。
通过进一步应用RoIAlign来提取单词特征和相应的全局语义特征,我们通过逐元素求和将这三个级别的特征融合在一起,并将它们馈送到3 * 3卷积层和1 * 1层中以获得更丰富的特征。 最终的融合特征用于实例分割。 请注意,按照元素求和后的3 * 3卷积层和1 * 1卷积层用于进一步弥合不同特征之间的语义鸿沟。
总体目标。最后提出了一种解决文本检测问题的文本融合网络的总体目标:
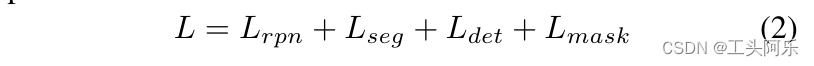
其中lrpn、Lseg、ldet 和lmask分别是rpn、语义分割分支、检测分支和掩码分支的损失函数。
3.4 弱监督学习
由于TextFuseNet是为了检测单词和字符而设计的,因此需要字符级注释来实现有效的训练。 但是,如前所述,某些现有数据集不提供字符级注释来训练TextFuseNet。 代替注释字符是一项费时费力的工作,我们受到弱监督学习的启发,并提出了一种基于弱监督的学习方案来帮助训练Text-FuseNet。 在提出的方案中,我们通过使用预先训练的模型从弱监督数据中学习来搜索角色级别的训练示例。 预训练模型是根据我们提出的框架在完全注释的数据集上进行训练的,该数据集同时提供字符级和单词级注释。 然后,对于仅具有单词级别注释的数据集A,我们开发的弱监督学习的目标是通过预训练的模型M在A中搜索字符训练样本。
更具体地说,我们首先将预训练模型M应用于单词级带注释的数据集A。 对于数据集A中的每个图像,我们可以获得一组字符候选样本:
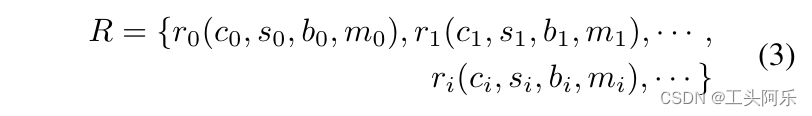
其中ci,si,bi和mi分别表示第i个字符候选样本ri的预测类别,置信度得分,边界框和掩码。 然后,我们根据置信度得分阈值和弱监督的单词级注释过滤R中的假阳性样本,并获得阳性字符样本:
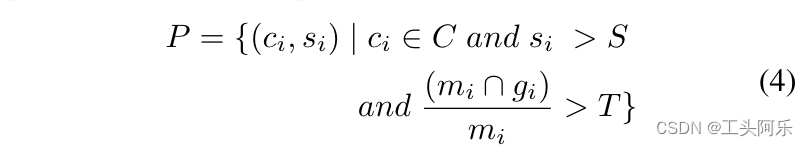
其中C表示要检测的所有字符类别,S表示用于识别正字符样本的置信度阈值,(mi \ gi)mi表示候选字符样本ri与其词级真相gj的交集重叠,T为 确定候选字符样本是否在单词内部的阈值。由于单词级别注释提供的约束,可以将置信度得分阈值S设置为相对较低,这也有利于保持字符样本的多样性 。 在我们的实现中,S和T分别设置为0.1和0.8。最后,将识别出的正字符样本作为字符级标注,并与单词级标注相结合,训练出更健壮、更准确的文本检测模型。
4.实验
在本节中,我们在四个具有挑战性的公共基准数据集:ICDAR2013、icdar2015、Total Text和CTW-1500评估TextFuseNet,并与以前的最新方法进行了比较。
4.1 数据集
synthextext是一个综合生成的数据集,通常用于文本检测模型的预训练。这个数据集由800000幅图像和800万个合成字组成,其中文字和字符级别的注释都以旋转矩形的形式出现。
ICDAR2013是一个典型的水平文本数据集,在ICDAR2013稳健阅读竞赛的挑战2中提出。它包含229个训练图像和233个测试图像。ICDAR 2013还提供字符和单词级别的注释。
ICDAR2015是一个多方向的文本数据集,在2015年ICDAR强劲阅读竞赛的挑战4中提出。它集中于附带场景文本,包含1000个训练图像和500个测试图像。此数据集仅提供用四边形标记的单词级注释。
Total text是一个用于场景文本读取的综合性任意形状文本数据集。全文包括1255个训练图像和300个测试图像。所有的图像都用单词级的多边形标注。
CTW-1500还专注于任意形状的文本读取,包含1000个训练图像和500个测试图像。与总文本不同,CTW-1500中的注释在文本行级别用多边形标注。
4.2 细节
我们在Maskrcnn基准测试的基础上实现了我们的框架,所有的实验都是在一个使用NVidia Tesla V100(16G)gpu的高性能服务器上进行的。该模型用4个gpu进行训练,用1GPU进行评价。
训练。整个训练过程分为三个阶段:对合成文本进行预训练,在弱监督下寻找特征训练样本,以及对实际数据进行精细调整。由于SynthText同时提供了单词和字符级别的注释,因此我们可以获得一个经过完全监督的预训练模型。经过预训练后,对于弱监督学习,我们应用IC-DAR 2015、Total Text和CTW-1500的预训练模型,搜索其对应的词级标注的特征训练样本。然后,识别出的字符样本与其原始的单词级注释相结合,对新数据集上的预训练模型进行微调。为了更好地分析所提出的TextFuseNet的能力,我们在每个数据集上采用了两个不同深度的ResNet作为主干。此外,为了增强网络的鲁棒性,采用了多尺度训练、随机旋转、随机颜色调整等数据增强策略应用。随机采用梯度下降法(SGD)对框架进行优化。重量衰减设置为0.0001,动量设置为0.9,批量大小设置为8。在预训练阶段,我们在synthext上训练模型20个时期。前10个时期的学习率设为0.01,后10个时期除以10。在微调阶段,将每个数据集上的训练迭代次数设置为20K,在前10K次迭代中,学习率设置为0.005,最后除以10。
推理。在推断过程中,测试图像的短边被缩放到1000,同时保持纵横比不变。在语义分割分支中提取全局语义特征。对于RPN生成的文本方案,我们为detection分支选择前1000个建议。根据检测结果,采用软N-MS对冗余边界盒进行抑制。然后根据抑制的检测结果执行实例分段,我们仅保留单词实例的实例分割结果作为最终的文本检测结果。
4.3消融实验
与原始mask R-CNN相比,我们引入了两个模块来提高文本检测的性能。第一个模块是进行多层次特征表示(MFR)。另一种方法是引入多路径特征融合体系结构(MFA),以获得更丰富的文本检测融合特征。因此,我们对2015年ICDAR和全文进行了消融研究,以评估TextFuseNet中每个模块对最终性能的影响。对于ICDAR 2015的每个数据集和总文本,训练了三个模型,不同模型的比较结果如表1所示。“基线”指的是用原markr-CNN训练的模型。“MFR”表示用Mask R-CNN训练的多层次特征表示的模型,“MFR+MFA”是指完全实现TextFuseNet的模型。在这项消融实验中使用的主干网是一个带有ResNet-50的FPN。
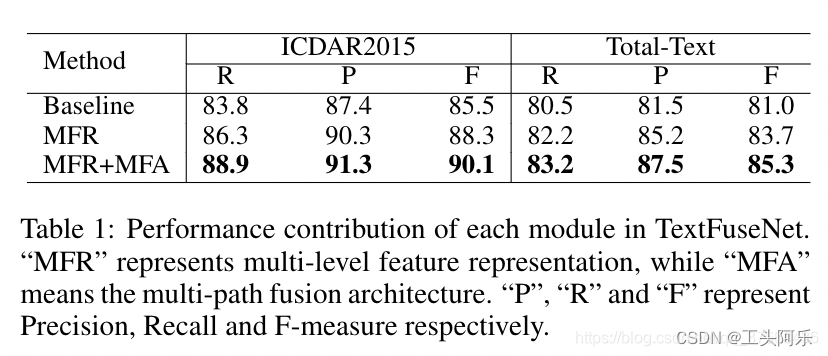
如表1所示,多层次特征表示1在查准率和查全率上都有显著提高,“MFR”的最终改进在ICDAR 2015和全文中都超过了2%。此外,“MFR”和“MFA”的组合可以进一步提高性能,并在2015年ICDAR基线和全文基础上分别提高4.6%和4.3%。这些结果验证了多级特征表示和多路径特征融合都可以帮助获得更丰富的融合特征和更具区分性的表示形式,这对文本检测很有帮助。
4.4 与最新的形状文本检测方法的比较
如前所述,CTW-1500和Total Text主要关注任意形状的文本,其中水平文本、多方向文本和曲线文本在大多数图像中同时存在。因此,我们使用这两个数据集来评估TextFuseNet对任意形状文本的有效性。表2的最后两列分别列出了TextFuseNet与之前在CTW-1500和Total Text上使用的一些方法的结果。注意,FPS仅供参考,因为不同的gpu采用不同的方法。如表2所示,我们提出的使用单尺度推理的TextFuseNet在CTW-1500和总文本上都达到了最先进的性能。具体地说,在CTW-1500中,用ResNet-50作为背骨的TextFuseNet达到了85.4%的F值,比目前最好的提高了1.7%。当主干网是resnet-101时,可以获得更令人信服的结果(F-measure:86.6%),比所有其他竞争对手至少高出2.9%。同样,对于总文本,我们的textfusenet加resnet-50已经达到了最先进的结果,它的ResNet-101版本比其他方法至少高出2.1%。以上实验结果表明,textfusenet在任意形状文本检测方面可以达到最新的性能。
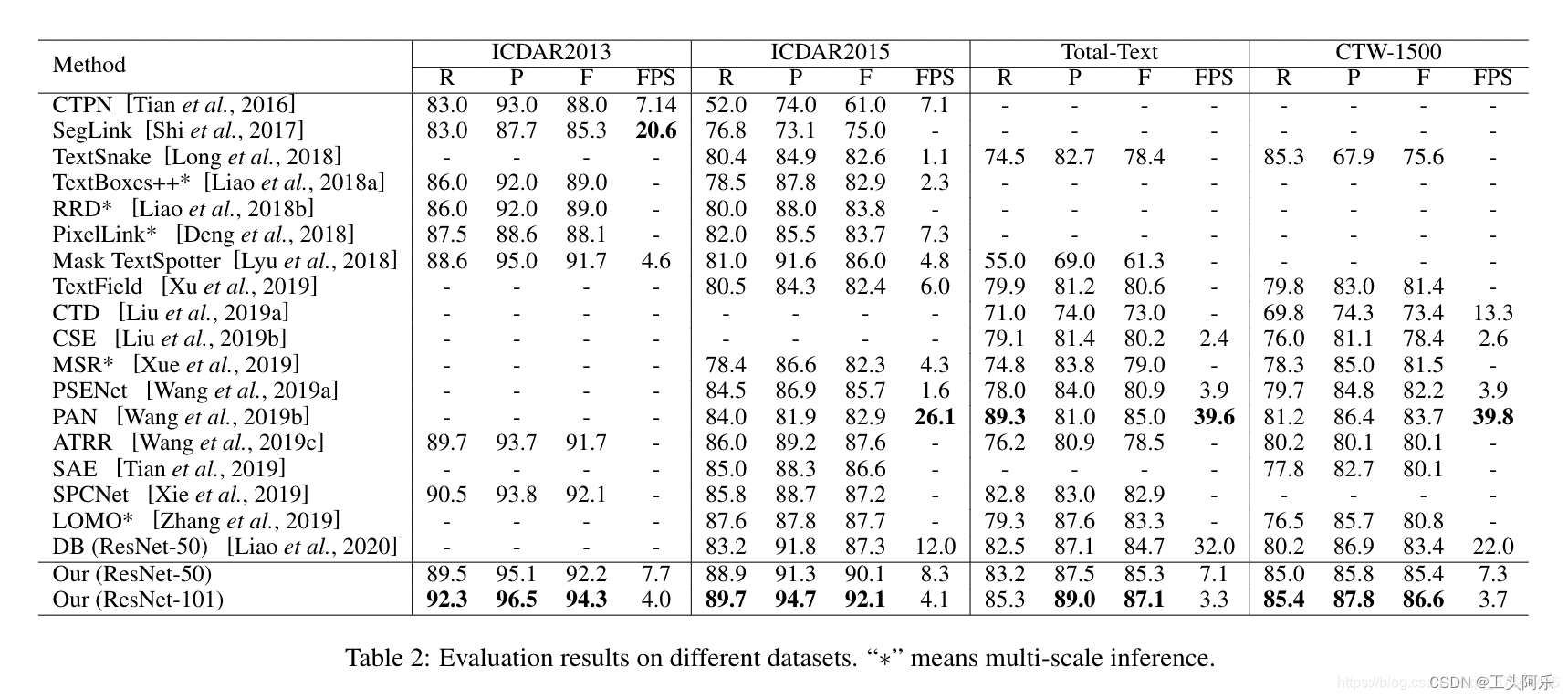
多方向文本检测 我们还评估了TextFuseNet在检测多方向文本ICDAR 2015中的有效性。我们的结果和与先前工作的比较如表2的第三列所示。如表2所示,以ResNet-50和ResNet-101为骨干的TextFuseNet实现了最先进的性能,其F-measure分别为90.1%和92.1%。与目前最好的版本相比,我们的ResNet-50和ResNet-101版本的性能分别超过了2.4%和4.4%。此外,据我们所知,我们提出的框架是ICDAR 2015的第一个框架,其F值超过90.0%。
水平文本检测。最后,我们评估了TextFuseNet在IC-DAR 2013上检测水平文本的有效性。TextFuseNet的结果以及与先前工作的比较见表2的第二列。以ResNet-50和ResNet-101为骨干的TextFuseNet都取得了很好的效果,F-测量值分别为92.2%和94.3%,优于之前的所有工作。
因此,从ICDAR2013、ICDAR 2015、Total Text和CTW-1500的这些实验结果来看,我们建议的TextFusenet达到了最先进的性能。另外,在速度上,TextFuseNet还可以以适当的速度进行推理,这与以前的一些方法相比具有一定的优势。图4显示了一些使用文本FuseNet的示例。

5. 结论
本文通过对字符、单词和全局特征三个层次特征的研究,提出了一种用于任意形状文本检测的新框架TextFuseNet。对不同层次的特征进行了充分细致的探索,获得了更丰富的融合特征,有利于文本检测。实验结果表明,textfusenet在检测任意形状文本方面达到了最先进的性能。
致谢
这项工作得到了中国国家自然科学基金会澳大利亚研究委员会项目(No.61822113,No.62041105)的部分资助(编号FL-170100117),湖北省自然科学基金资助项目(编号2018CFA050)和湖北省科技重大专项(下一代人工智能技术)项目(编号2019EA170),在超级计算中心的超级计算系统上进行了数值计算武汉大学的