如有错误,恳请指出。
参考网上资料,对一些经典论文进行快速思路整理
文章目录
- 1. SA-SSD
- 2. CIA-SSD
- 3. SE-SSD
1. SA-SSD
paper:《Structure Aware Single-stage 3D Object Detection from Point Cloud》(2020CVPR)
结构图:

问题:
One-stage的算法网络为的是追求速度与精度的权衡,但是利用3d稀疏卷积对特征进行下采样后的特征无法避免地丢失了空间的信息,不能充分利用点云中的结构信息,降低了定位精度。此外,预测的置信度与预测框之间存在不一致问题。不过这个问题一直存在,包括在two-stage里面。不一致问题出现的关键在于分类置信度相关的当前位置使用的特征图一般与预测边界框所在的位置存在偏移。目前为止我看见过两种解决的办法:1)利用3d iou来作为分类置信度的监督值(代表方法:PartA2);2)增加一个iou分支,将分类得分与iou预测相乘,作为最后的objectness值,利用nms进行筛选(代表方法:STD)。
SA-SSD为了解决这两个问题,前者提出了利用辅助损失,利用两个point-level的子任务监督进行联合优化backbone中得到的特征,引导主干网络中的卷积特征了解目标的结构信息,这里的两个point-level辅助任务是前景分割(使特征对目标边界敏感)以及逐点中心估计(使特征知道目标内部关系)。后者抛开提到的两种方法,选择是提出了一个part-sentive warping(PS Warp)操作对分类特征图进行空间变换实现分类置信度与预测的边界框对齐。
思路:
1)在SA-SSD中不采用voxel的量化操作,因为体素化是一种比较耗时的预处理方法。为了简化预处理,这里将点坐标量化为张量的索引,迭代的地对每个点分配给输入张量中。如果多个点共享同一索引,则用最新的点来覆盖填充信息,这里就不需要对voxel进行点的element-wise平均操作。获取了张量形式的输入特征,就可以利用4 Stage的3d稀疏卷积进行特征提取,然后最z轴信息进行拼接转化为2d的bev特征图,后面使用6个3x3的2d卷积构建成rpn网络。
2)Auxiliary network:在backbone进行稀疏卷积处理后,其实获得了原始点云的多尺度信息。为了补全这些原始点云的特征,采用与PointNet++的反距离加权平均,计算每一个原始点在每个stage特征上的一定半径内的特征加权值,来进行多尺度信息的concat(在PV-RCNN中的主要思路也是利用多尺度信息对原始点特征进行补全)。在对原始点特征进行补全后,进行前景点语义分割以及逐点中心估计两个辅助任务,使得backbone可以学习到结构特征。ps:这里的逐点中心估计可以借鉴PartA2,也提到了利用标注框的内部相对位置信息。
3)Part-sensitive warping:这部分看不懂,借鉴一下其他资料
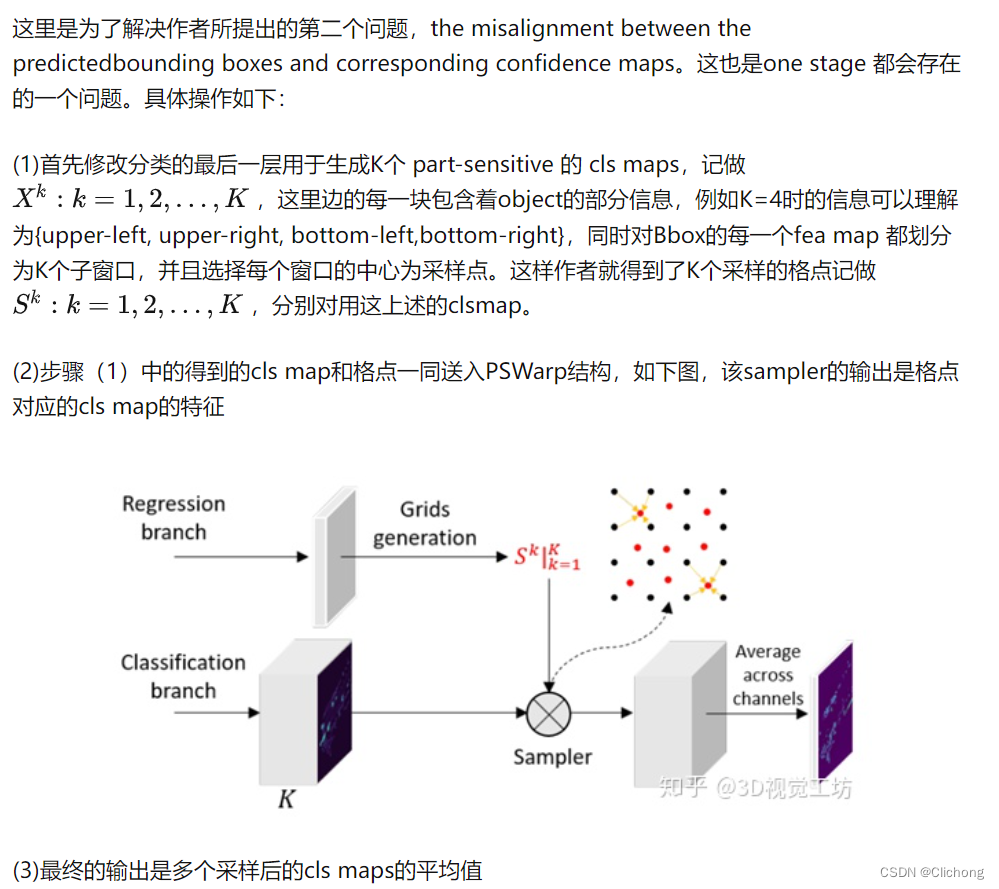
总结:
自从GoogleNet提出以来,一直觉得辅助任务是个好东西。利用了两个辅助任务让主干网络更加关注结构信息,这让我联想到了之前做推荐系统的跨域ctr估计。也是利用源域数据与目标域数据进行一个联合训练来优化结果。在论文的创新上,可以考虑一下如何设置辅助任务来提升性能,或者是考虑多任务的一个联合优化。
ps:SA-SSD的Abstract和Introduction写得很好
参考资料:
CVPR2020| 阿里达摩院最新力作SA-SSD
2. CIA-SSD
paper:《CIA-SSD: Confident IoU-Aware Single-Stage Object Detector From Point Cloud》(2021AAAI)
结构图:

背景:
单机检测器对目标的定位和类别预测一般是分开处理,所以会出现定位的精度以及分类置信度不能很好的匹配,这个问题在上述的SA-SSD中也有提及到。此外,CIA-SSD还设计了一个轻量级的空间语义特征聚合模块,自适应融合高层抽象语义特征以及底层空间特征,以提高边界框的预测精度和分类置信度。对于离视点处较远的距离回归框,经常存在较多冗余的假阳性预测以及震荡,又提出了一个种新的DI-NMS来解决这个问题。
网络结构:
1. Point Cloud Encoder
常规操作,将点云空间体素化。每个voxel的初始特征是voxel内点的位置与反射强度的均值。随后,利用SECOND的backbone进行3d稀疏卷积(这里称为SPConvNet)。最后得到的特征图中将z方向特征拼接获得bev特征图,来输入到下一个空间语义特征聚合(SSFA)模块。
2. Spatial-Semantic Feature Aggregation
对于物体的回归与分类,高层语义信息以及底层的空间信息同样重要,但是二者一般存在矛盾。一般来说,当对卷积层进行堆叠以获得丰富的高层语义特征时,底层空间信息质量会严重下降,为此CIA-SSD提出SSFA模块来解决这个问题。
对于语义信息处理分支,以spatial feature为输入,用一个卷积实现channels翻倍,尺寸减半。对于空间信息处理分支,输入输出尺寸不变,并与上采样后的语义信息特征进行element-wise addition的操作,作为融合后新的spatial feature。此外,对于semantic feature上采样与空间特征层融合外,还会上采样构成另外一个分支作为新的semantic feature。为了自适应融合丰富后的spatial feature以及上采样后的semantic feature,这里提出了Attention Fusion模块处理。简单来说,就是构建两个bev权重特征图分别对spatial feature以及semantic feature处理,然后相加进行融合。详细看结构图与代码。
3. IoU-Aware Confidence Rectification
由于单阶段检测的anhor特征不一致,所以预测出的iou往往不如two-stage检测器的准确。同时,作者在实验中得到了一个观察的结果,就是一般来说但预测的iou比较高时期真实的iou也会比较高,基于这个想法提除了confidence function:f = c*i^β。 其实本质上就是多一个β冥指数作用于置信度预测中,用来抑制低iou的预测,随后和分类score进行相乘。不过,这里的confidence function只在测试阶段使用。训练阶段的iou预测分支是利用真实的iou值来做监督值的。
4. Distance-Variant IoU-Weighted NMS
对于远距离的目标由于稀疏性,一般具有低分类置信度以及高回归不确定性。同时,回归边界框存在震荡现象,以及出现冗余的假阳性。为了解决这两个问题,CIA-SSD提出了DI-NMS的解决方案。具体的算法流程查看论文。
ps:论文的结构非常清晰,写论文时值得参考。实验部分,包含数据增强的消融实验、提出模块的消融实验、超参数的消融实验、以及精度与速度的对比。实验相比其他顶会做的不算多,但是该有的都有,感觉比较精炼与狡猾。这里提到了5种数据增强方式:

3. SE-SSD
paper:《SE-SSD: Self-Ensembling Single-Stage Object Detector From Point Cloud》(2021CVPR)
结构图:

SE-SSD与CIA-SSD是同一批大佬,在CIA-SSD的基础上进行了拓展,在保持速度不变的情况下精度更高,在paperwithcode的KITTI榜单上排名第三,效果可以说是相当亮眼了。截止今天,仍然是KITTI榜单上最快的,不过性能排30+,详细榜单见:https://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d

背景:
在3D目标检测中,预定义anchor点中的点云模式可能因距离远近和遮挡而发生显著差异。因此SE-SSD的想法是利用teacher网络生成的soft label以及原本标注的hard label来对student网络进行联合训练优化。同时引入形状感知方式的数据增强方法来提高对遮挡、形状多样性的鲁棒性。
思路:
SE-SSD结构如上图所示。左边是 teacher SSD,右边是 student SSD,同时部署和训练两个SSDs(相同架构,其实两个就是CIA-SSD模型),这样 student SSD就可以通过增强样本得到更多的数据,并根据teacher SSD预测的 soft 目标更好的优化。训练过程,我们先用预训练好的SSD模型来初始化teacher SSD和 student SSD。然后,从一个输入点云开始,框架包含两个处理路径:
- 第一条路径(蓝色箭头)中,teacher SSD从原始输入点云生成相对精确的预测。然后,对预测结果进行全局转换(global transformations),并将其作为 soft 目标来监督 student SSD。
- 第二条路径(绿色箭头)中,通过与第一条路径相同的全局变换来扰动同一点云,再加上具有形状感知的数据增强。然后,向student SSD输入增强后的数据,并利用以下训练:用于对齐student 预测和 soft 目标的一致性损失;当增加输入时,我们也用它的 hard 目标(上图右上角)来监督student的方向感知的distance-IoU损失。也就是用soft label以及hard label来对student网络进行联合训练。
训练中,迭代更新两个SSD模型:优化有上述两个损失(即用于对齐的一致性损失和方向感知的distance-IoU损失)的student SSD,并仅使用student SSD参数通过标准指数移动平均(EMA)更新teacher SSD。因此,teacher SSD可以从student SSD那里获得蒸馏知识,并产生 soft 目标来监督student SSD。因此,最终训练的student SSD称为Self-Ensembling single-stage 目标检测。
网络细节:
1. Consistency Loss
相比hard label,teacher网络的soft label信息更加丰富,有助于揭示同类的数据样本之间的差异。为此,SE-SSD核心思路是联合soft label与hard laebl同时对student网络进行一致性联合优化训练。提出iou-based匹配策略对其teacher与student的边界框。与hard label相比,soft label目标通常更加接近student预测。因此soft label信息可以更好地引导 student 微调预测,减少梯度方差,以获得更好的训练。损失如下所示,与SECOND是类似的,只不过换成了soft label信息。

2. Orientation-Aware Distance-IoU Loss
为了更好地利用 hard 目标来回归边界框,设计了方向感知distance-IoU损失(OD-IOU),更多地关注边界框中心的对准以及预测和GT边界框之间的方向。引入预测框与GT框3D中心的约束,以最小化中心不对齐问题;同时,设计了在预测BEV角度上的朝向约束,以进一步减少朝向差别问题,在3D目标检测中,这种约束意味着鸟瞰视图(BEV)中的非轴对准框之间的精确对准。与smooth-L1损失相比,ODIOU损失增强了中心点和朝向上的对齐。

总损失如下所示:

3. Shape-Aware Data Augmentation
GT 目标的点云由于现实的遮挡、距离变化和物体形状的多样性等,差异很大。因此,设计了形状感知数据增强方案来模拟在数据增强时,点云如何受到这些因素的影响。在实现上,对于点云中的每个目标,找到它的GT边界框中心,并将中心与盒面(边界框的8个角点)连接起来形成金字塔体,将目标点分成六个子集(因为物体有6个表面)。这里的形状感知数据增强方案通过分解部件,来有效地增强每个目标的点云。如下所示:

具体而言,使用随机概率P1,P2,P3执行3个操作:
- 在随机选择的金字塔中随机删掉所有点(如上图所示蓝色点,左上),模拟对象被部分遮挡,以帮助网络从剩余的点推断出完整的形状。
- 随机交换在当前场景中随机选择另一个输入目标,并将点集(绿色)交换到另一个输入目标中的点集(黄色),从而利用目标间的表面相似性来增加目标样本的多样性。
- 使用最远点采样算法,在随机选择的金字塔中随机稀疏子样本点,模拟由于LIDAR距离变化引起的点的稀疏变化;参见图5中的稀疏点(红色)。
除此之外,在形状感知数据增强前,先在输入点云上执行全局转换,包括随机平移、翻转和缩放等。
总结:
SE-SSD是在CIA-SSD的基础上扩展而来,其实也可以理解为利用知识蒸馏对原始模型的进一步拓展。也就说,利用SE-SSD提出的知识蒸馏的方法,有可能对原有的模型带来进一步的提升,体现出利用soft label与hard label的性能强大之处,此外这里提到的数据增强方式也可以很好的进行移植,有机会可以在其他算法上进行测试,下图是SE-SSD在CIA-SSD上的提升,可以看见在几乎不影响速度的情况下,精度有2%+以上的提升,相当优秀。

参考资料:
1. 2021CVPR——SE-SSD: Self-Ensembling Single-Stage Object Detector From Point Cloud
2. Student-Teacher Network在3D目标检测中的应用
![[附源码]Python计算机毕业设计SSM基于云服务器网上论坛设计(程序+LW)](https://img-blog.csdnimg.cn/ede49777320d4a5fac73e110750b39d9.png)


![Docker[3]-Docker的常用命令](https://img-blog.csdnimg.cn/1a085b428ecf4a19a582f38aeed5cf06.png)

