目录
- 环境信息
- 1. 准备
- 1.1 服务器规划
- 1.2 主机名及hosts文件修改
- 1.2.1 hostname修改
- 1.2.2 hosts文件修改
- 1.3 创建hadoop用户(建议)
- 1.4 为hadoop用户添加sudo权限
- 1.5 互信免密登录
- 1.6 快速文件同步(可选)
- 2. 安装
- 2.1 下载并安装jdk
- 2.2 下载并安装hadoop
- 2.2.1 下载完成后放置到需要安装的目标目录并解压
- 2.2.2 配置环境变量
- 3. 配置hadoop并启动
- 3.1 配置文件说明
- 3.2 core-site.xml
- 3.3 hdfs-site.xml
- 3.4 yarn-site.xml
- 3.5 mapred-site.xml
- 3.6 workers
- 3.7 格式化NameNode
- 3.8 启动hdfs
- 3.9 启动yarn
- 3.10 配置历史服务器mapred-site.xml
- 3.11 配置日志聚集(yarn-site.xml)
- 4. 测试
- 4.1 创建文件夹并上传文件
- 4.2 查看
- 4.3 下载
- 4.4 删除
- 4.5 yarn任务提交
- 5. 常用端口清单
- 6. 常用命令清单
- 6.1 集群启停
- 6.1.1 HDFS
- 6.1.1 yarn
- 6.2 按模块
- 6.2.1 HDFS组件
- 6.2.1 YARN组件
- 6.3 历史服务器
环境信息
JDK: 1.8
Hadoop: 3.3.4
Linux: Centos7.5
防火墙状态: 关闭
1. 准备
下载地址:Index of /apache/hadoop/common/hadoop-3.3.4 (tsinghua.edu.cn)
1.1 服务器规划
HDFS的NameNode和SecondaryNameNode 不可安装在同一台主机
YARN的ResourceManager不要和HDFS的NameNode和SecondaryNameNode 安装在同一台主机(资源平衡考虑)
| 主机名 | ip | 用途 |
|---|---|---|
| centos7-hadoop-130 | 192.168.1.130 | HDFS:NameNode+DataNode YARN: NodeManager |
| centos7-hadoop-131 | 192.168.1.131 | HDFS:DataNode YARN: NodeManager + ResourceManager |
| centos7-hadoop-132 | 192.168.1.132 | HDFS:SecondaryNameNode + DataNode YARN: NodeManager |
1.2 主机名及hosts文件修改
使用root用户完成以下操作
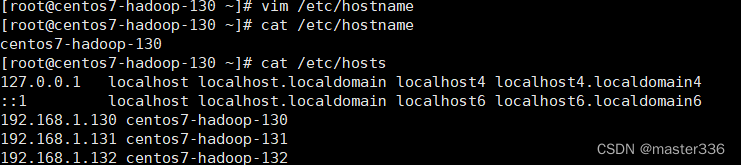
1.2.1 hostname修改
分别修改三台服务的hostname文件,写入对应主机名
vim /etc/hostname
1.2.2 hosts文件修改
建议客户机(后续测试使用)也同样配置,window x64 hosts文件位置C:\Windows\System32\drivers\etc\hosts
192.168.1.130 centos7-hadoop-130
192.168.1.131 centos7-hadoop-131
192.168.1.132 centos7-hadoop-132
效果如下(以centos7-hadoop-130为例):
1.3 创建hadoop用户(建议)
三台规划的机器上均执行此操作
这里不建议直接使用root用户
#创建hadoop用户
useradd hadoop
#设置hadoop用户密码
passwd hadoop
#连续两次输入要设置的hadoop用户密码即可
1.4 为hadoop用户添加sudo权限
三台规划的机器上均执行此操作
此步骤的目的是在需要特殊权限时可方便使用
#修改文件
vim /etc/sudoers
#添加用户
修改效果如下:
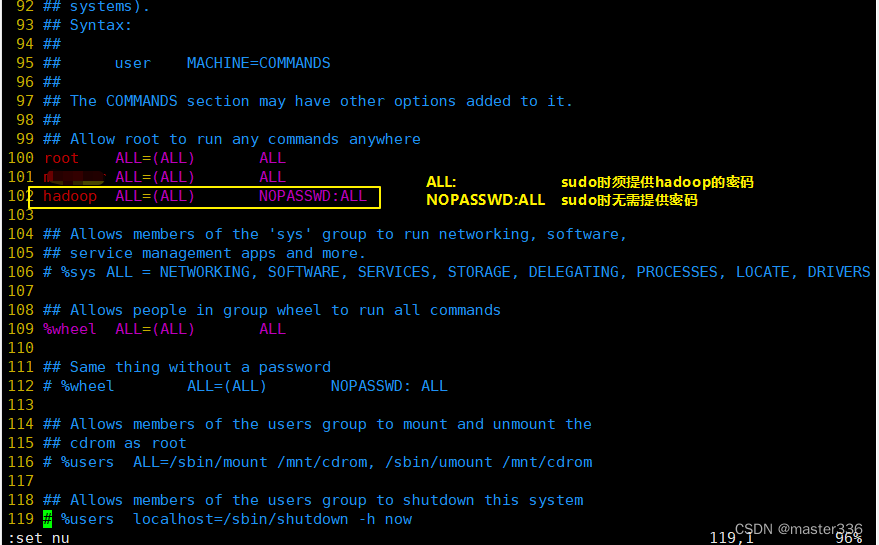
NOPASSWD:ALL 表示无需密码即可切换root用户,一般不建议这么搞
参考:[linux]sudo的简单设置-CSDN博客
1.5 互信免密登录
三台规划的机器上均执行此操作,完成三个节点中任意节点到其他节点均可免密
参考: 【linux】ssh免密登录-CSDN博客
1.6 快速文件同步(可选)
基于sync的文件同步
参考: [rsync] 基于rsync的同步_-CSDN博客
本此使用脚本参考
#!/bin/bash
#判断参数
if [ $# -lt 1 ]
then
echo 请传入要同步的文件
exit;
fi
#要同步的目标服务器清单
for host in centos7-hadoop-130 centos7-hadoop-131 centos7-hadoop-132
#for host in 192.168.1.2 192.168.1.3 192.168.1.4
do
echo ==================== $host ====================
#向下遍历所有目录,依次发送
for file in $@
do
#获取父目录,用于创建不存在的目录
pdir=$(cd -P $(dirname $file); pwd)
#获取当前文件的名称
fname=$(basename $file)
#创建目录,如果这一步里对应的服务器没有进行免密设置,则需要输入密码
ssh -p 50022 $host "mkdir -p $pdir"
#执行同步,如果这一步里对应的服务器没有进行免密设置,则需要输入密码
echo "rsync -av -e 'ssh -p 50022' $pdir/$fname hadoop@$host:$pdir"
rsync -av -e 'ssh -p 50022' $pdir/$fname hadoop@$host:$pdir
done
done
2. 安装
三台规划的机器上均执行此操作,如无特殊说明,使用hadoop用户操作
2.1 下载并安装jdk
略
2.2 下载并安装hadoop
下载地址:Index of /apache/hadoop/common/hadoop-3.3.4 (tsinghua.edu.cn)
2.2.1 下载完成后放置到需要安装的目标目录并解压
这里以放置在/app目录下为例
mkdir -p /app
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
tar -xvf hadoop-3.3.4.tar.gz
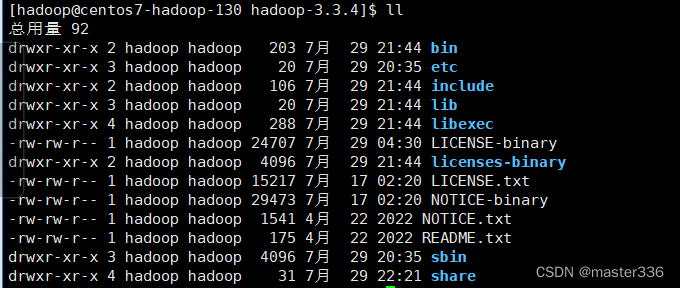
目录说明:
| 文件夹 | 说明 |
|---|---|
| bin | 相关服务的操作脚本 |
| etc | 配置文件目录 |
| lib | hadoop本地库 |
| sbin | 启、停等相关脚本 |
| share | 依赖包、文档、示例 |
2.2.2 配置环境变量
使用root用户操作
像配置JAVA_HOME一样配置HADOOP_HOME,值为Hadoop安装的根目录
#HADOOP的根目录
export HADOOP_HOME=/app/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
以上内容可配置到/etc/profile文件中,亦可在/etc/profile.d/下创建.sh的脚本单独放置,前提是/etc/profile文件包含如下内容:
for i in /etc/profile.d/*.sh /etc/profile.d/sh.local ; do
if [ -r "$i" ]; then
if [ "${-#*i}" != "$-" ]; then
. "$i"
else
. "$i" >/dev/null
fi
fi
done
生效配置
source /etc/profile
3. 配置hadoop并启动
三台机器均执行此配置(可使用1.6中的rsync进行同步),使用hadoop用户
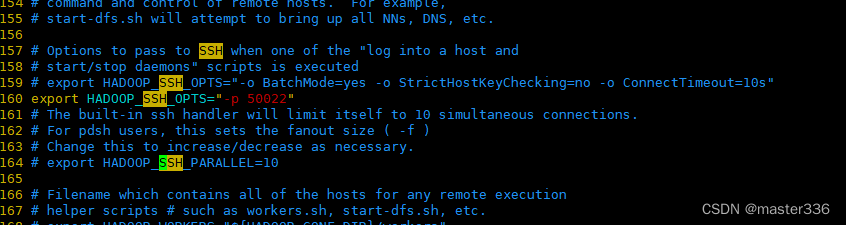
hadoop集群工作时会通过ssh通讯,如果ssh默认不是22端口则通过修改 文件$HADOOP_HOME/etc/hadoop/hadoop-env.sh指定ssh连接时的配置选项.
添加配置
export SPARK_SSH_OPTS="-p 50022"
3.1 配置文件说明
Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认 配置值时,才需要修改自定义配置文件,更改相应属性值。
- 默认配置文件:
| 配置文件 | 所在 jar 包中的位置 | 参考文件位置 |
|---|---|---|
| [core-default.xml] | $HADOOP_HOME/share/hadoop/common/hadoop-common-3.3.4.jar/core-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-common/core-default.xml |
| [hdfs-default.xml] | $HADOOP_HOME/share/hadoop/hdfs/hadoop-hdfs-3.3.4.jar/hdfs-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml |
| [yarn-default.xml] | $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-common-3.3.4.jar/yarn-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-yarn/hadoop-yarn-common/yarn-default.xml |
| [mapred-default.xml] | $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.3.4.jar/mapred-default.xml | $HADOOP_HOME/share/doc/hadoop/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml |
- 自定义配置文件:
$HADOOP_HOME/etc/hadoop 这个路径下core-site.xml、 hdfs-site.xml、 yarn-site.xml、 mapred-site.xml 、workers五个配置文件用户可以根据项目需求重新进行修改配置。
3.2 core-site.xml
三台机器均执行此配置(可使用1.6中的rsync进行同步),使用hadoop用户
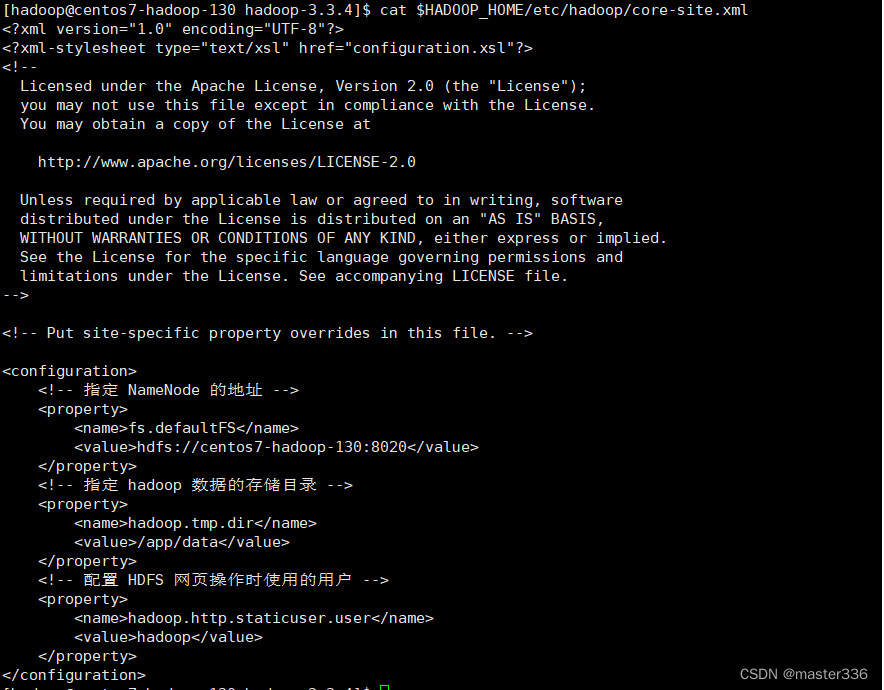
path:$HADOOP_HOME/etc/hadoop/core-site.xml
configuration节点下增加如下配置
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos7-hadoop-130:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/app/data</value>
</property>
<!-- 配置 HDFS 网页操作时使用的用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
[
3.3 hdfs-site.xml
三台机器均执行此配置(可使用1.6中的rsync进行同步),使用hadoop用户
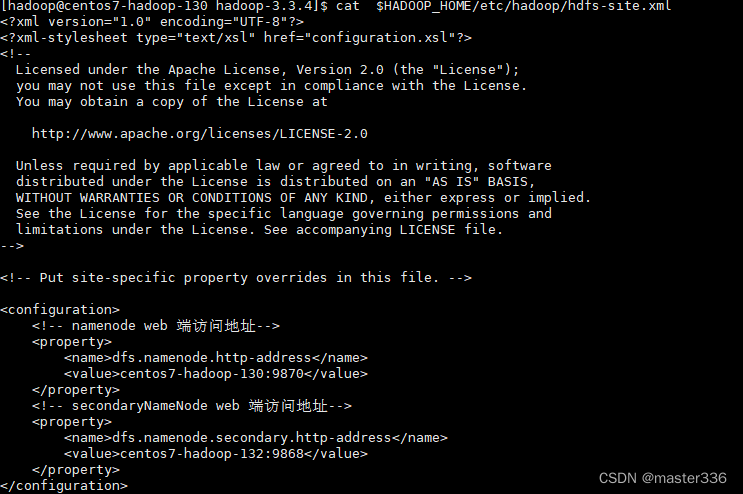
path:$HADOOP_HOME/etc/hadoop/hdfs-site.xml
configuration节点下增加如下配置
<!-- namenode web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>centos7-hadoop-130:9870</value>
</property>
<!-- secondaryNameNode web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>centos7-hadoop-132:9868</value>
</property>
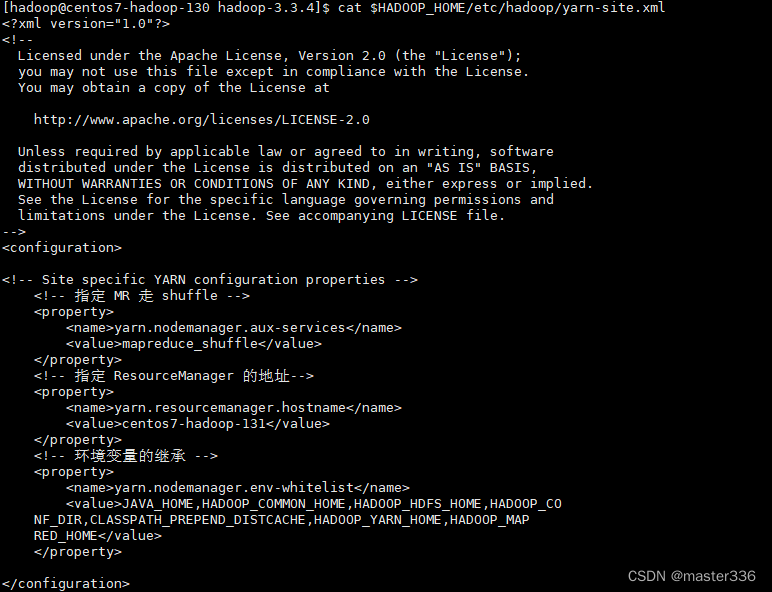
3.4 yarn-site.xml
三台机器均执行此配置(可使用1.6中的rsync进行同步),使用hadoop用户
path:$HADOOP_HOME/etc/hadoop/yarn-site.xml
configuration节点下增加如下配置
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>centos7-hadoop-131</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
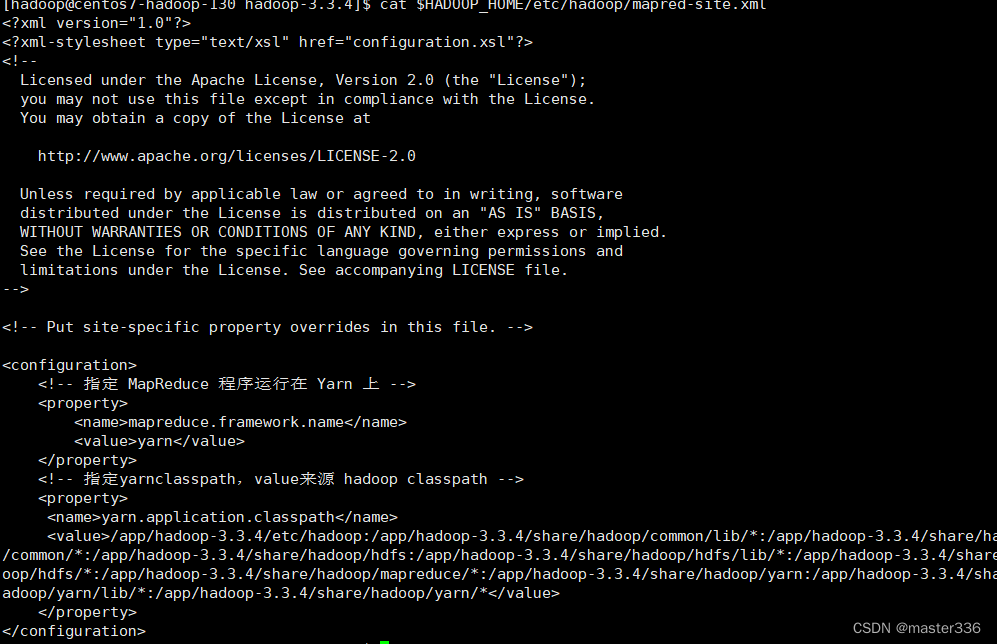
3.5 mapred-site.xml
三台机器均执行此配置(可使用1.6中的rsync进行同步),使用hadoop用户
path:$HADOOP_HOME/etc/hadoop/mapred-site.xml
查询classpath作为yarn.application.classpath对应的value
hadoop classpath

configuration节点下增加如下配置
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定yarnclasspath,value来源 hadoop classpath -->
<property>
<name>yarn.application.classpath</name>
<value>/app/hadoop-3.3.4/etc/hadoop:/app/hadoop-3.3.4/share/hadoop/common/lib/*:/app/hadoop-3.3.4/share/hadoop/common/*:/app/hadoop-3.3.4/share/hadoop/hdfs:/app/hadoop-3.3.4/share/hadoop/hdfs/lib/*:/app/hadoop-3.3.4/share/hadoop/hdfs/*:/app/hadoop-3.3.4/share/hadoop/mapreduce/*:/app/hadoop-3.3.4/share/hadoop/yarn:/app/hadoop-3.3.4/share/hadoop/yarn/lib/*:/app/hadoop-3.3.4/share/hadoop/yarn/*</value>
</property>
3.6 workers
三台机器均执行此配置(可使用1.6中的rsync进行同步),使用hadoop用户
path:$HADOOP_HOME/etc/hadoop/workers
删除原有的一条localhost记录
增加集群的主机清单,如下内容:
centos7-hadoop-130
centos7-hadoop-131
centos7-hadoop-132

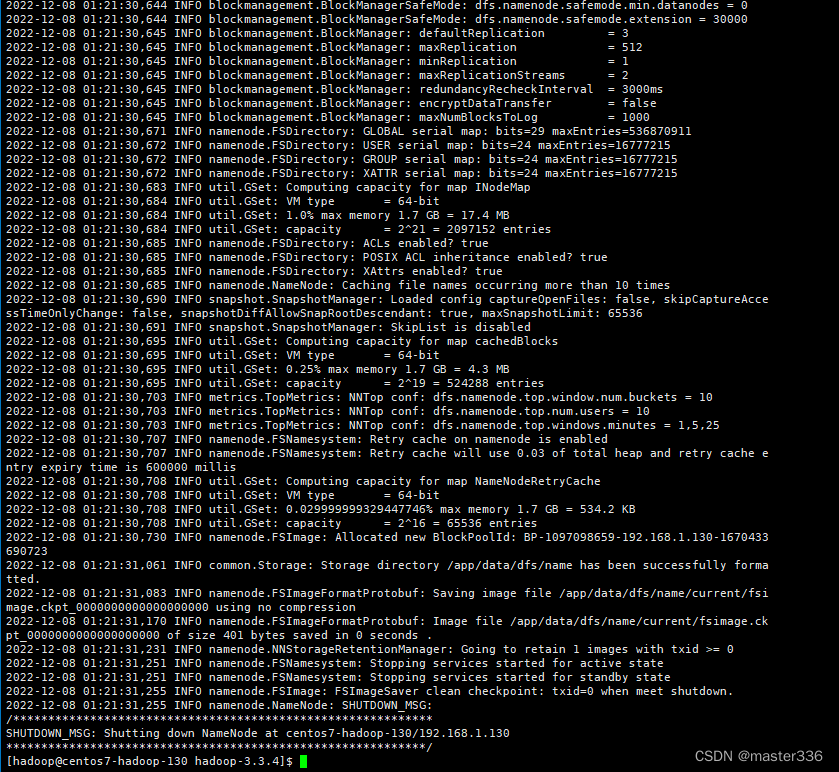
3.7 格式化NameNode
在centos7-hadoop-130上执行格式化命令,使用hadoop用户执行
仅在首次启动集群前执行一次,多次执行会导致重复生成namenode的集群id,当namenode和datanode的集群id不一致时将导致整个集群报错。重新格式化namenode前应停止namenode和datanode进程,并删除data和log目录,必要时/tmp相关进程信息文件也应删除。
格式化命令:
hdfs namenode -format
3.8 启动hdfs
entos7-hadoop-130 使用hadoop用户启动hdfs
启动命令:
cd $HADOOP_HOME
sbin/start-dfs.sh
启动完成进程信息
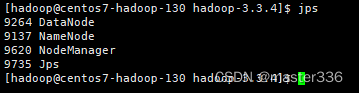
注: NodeManager进程在yarn启动后出现
访问NameNode:http://192.168.1.130:9870/
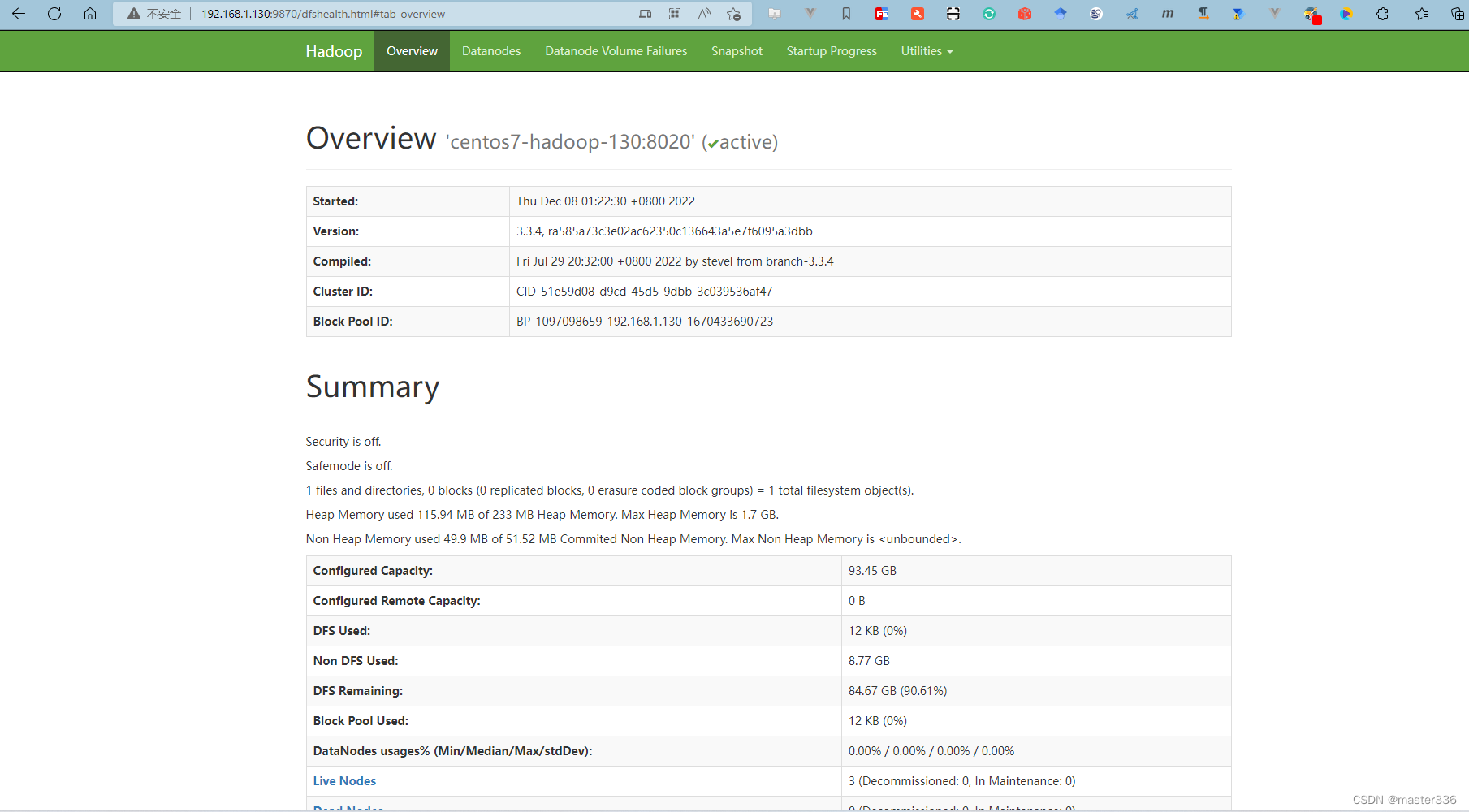
访问SecondaryNameNode http://192.168.1.132:9868/

3.9 启动yarn
entos7-hadoop-131 使用hadoop用户启动yarn
启动命令:
cd $HADOOP_HOME
sbin/start-yarn.sh
启动完成进程信息
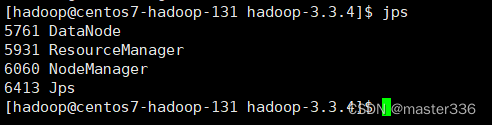
访问:http://192.168.1.131:8088/
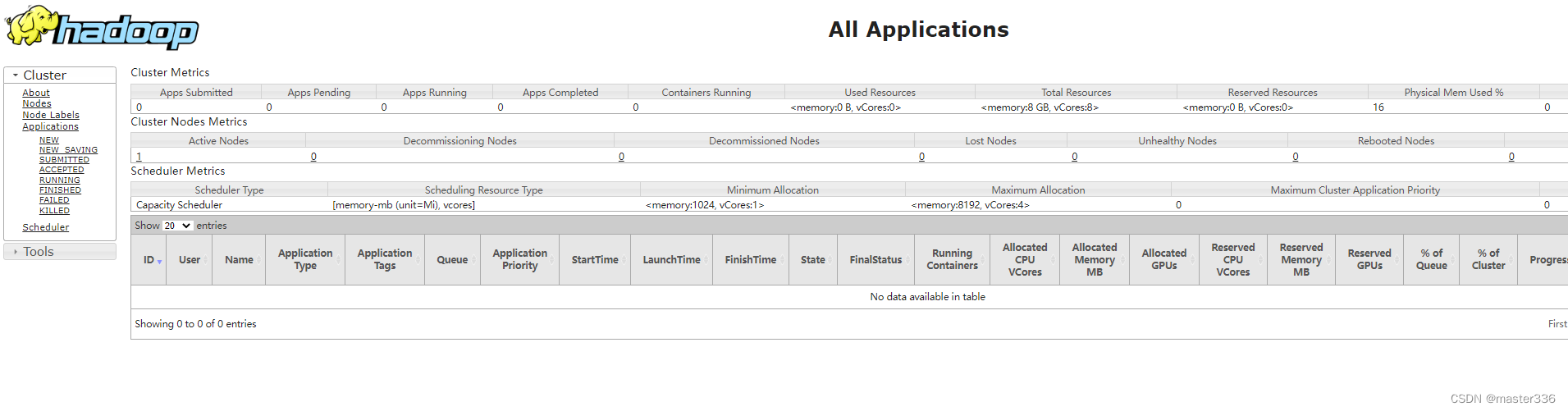
查看132节点进程信息
3.10 配置历史服务器mapred-site.xml
三台机器均执行此配置(可使用1.6中的rsync进行同步),使用hadoop用户
path:$HADOOP_HOME/etc/hadoop/mapred-site.xml
configuration节点下增加如下配置
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>centos7-hadoop-130:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>centos7-hadoop-130:19888</value>
</property>
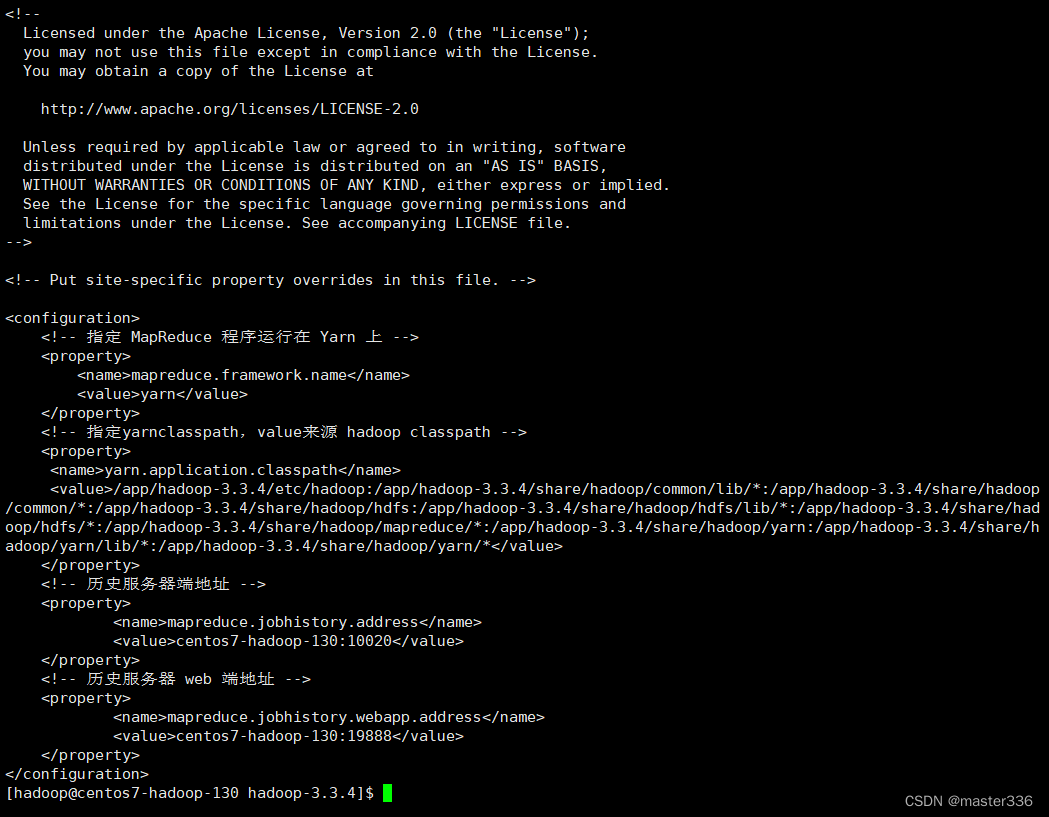
启动历史服务器
mapred --daemon start historyserver
进程信息

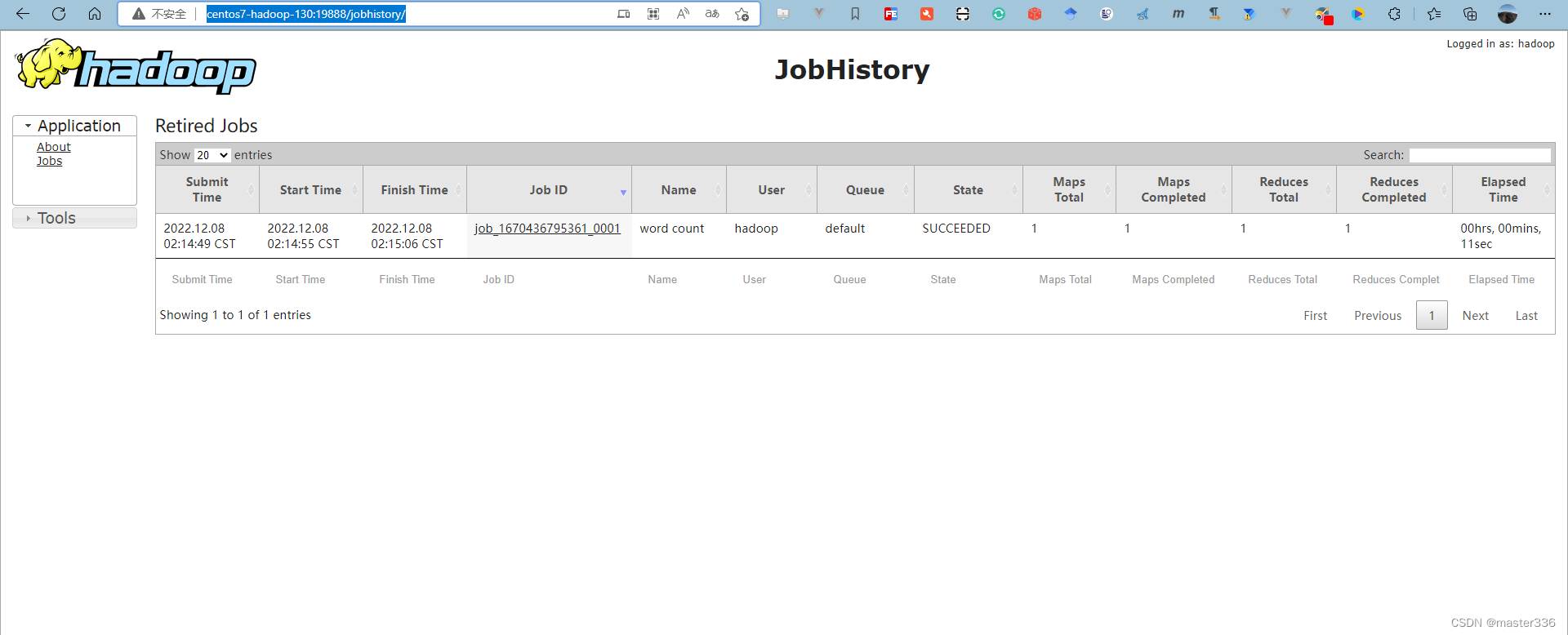
访问: http://centos7-hadoop-130:19888/jobhistory/
3.11 配置日志聚集(yarn-site.xml)
三台机器均执行此配置(可使用1.6中的rsync进行同步),使用hadoop用户
path:$HADOOP_HOME/etc/hadoop/yarn-site.xml
configuration节点下增加如下配置
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://centos7-hadoop-13:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
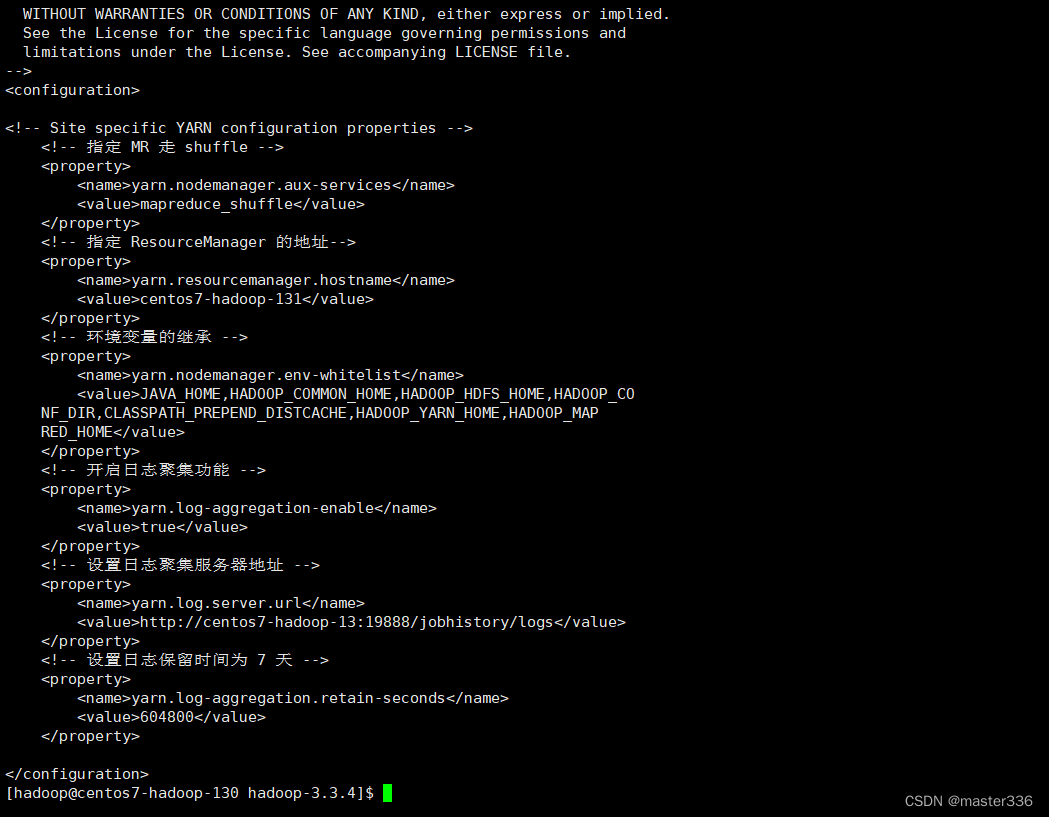
重启yarn和历史服务器
cd $HADOOP_HOME
#停止yarn centos7-hadoop-131 上执行
sbin/stop-yarn.sh
#停止历史服务器 centos7-hadoop-130 上执行
mapred --daemon stop historyserve
# 启动yarn centos7-hadoop-131 上执行
sbin/start-yarn.sh
# 启动历史服务器 centos7-hadoop-130 上执行
mapred --daemon start historyserve
提交测试任务
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input.txt /output00.txt
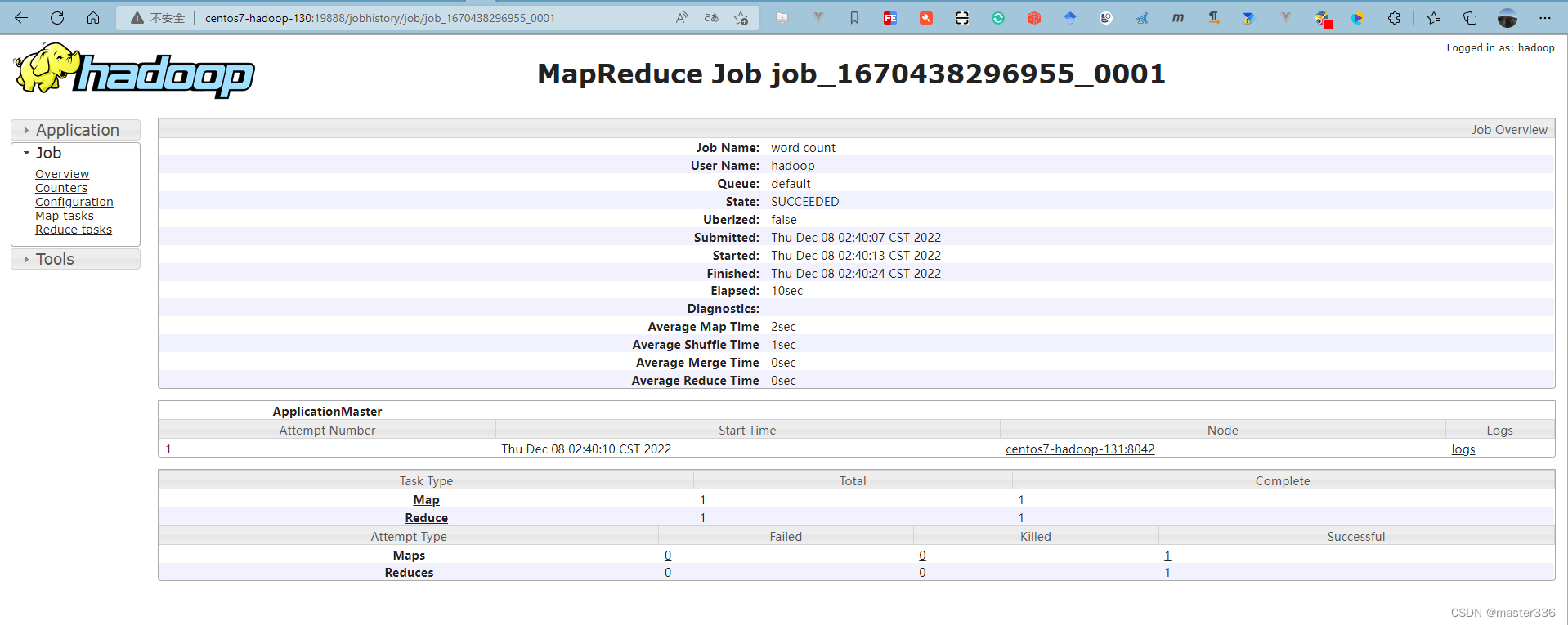
访问历史服务器:http://centos7-hadoop-130:19888/jobhistory
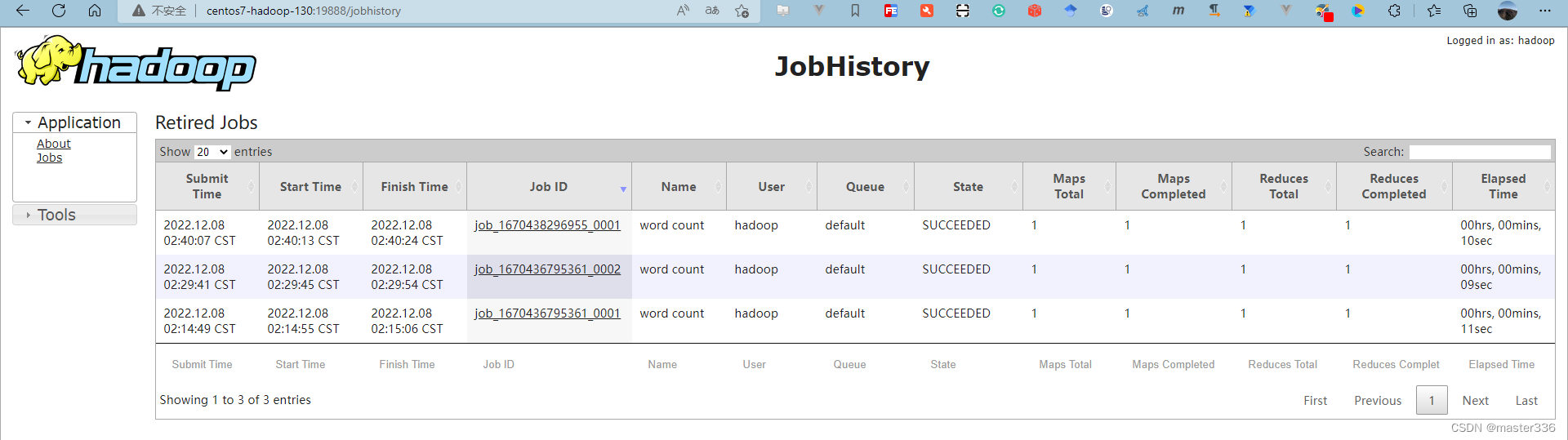
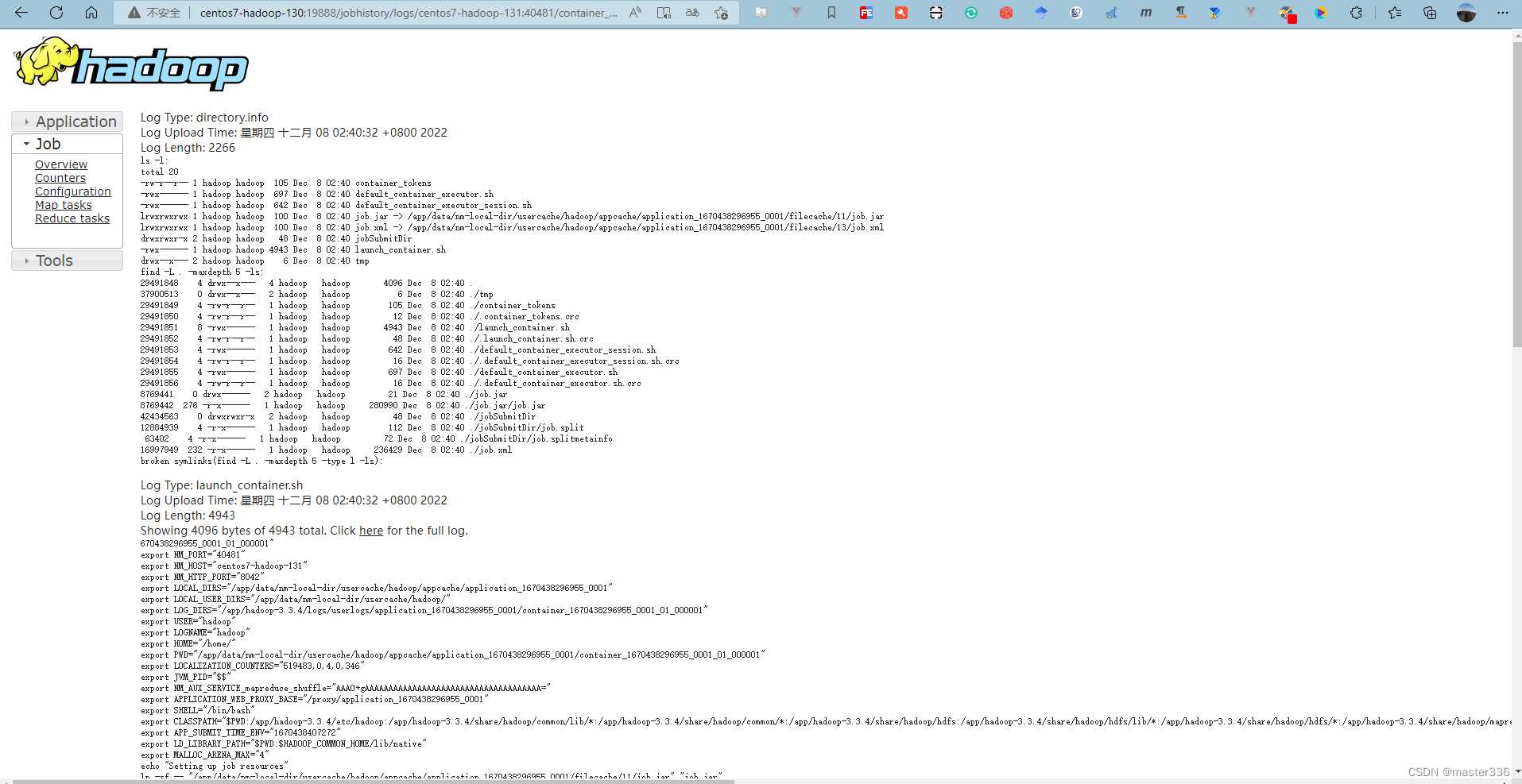
查看日志:
4. 测试
4.1 创建文件夹并上传文件
hadoop fs -ls /
hadoop fs -mkdir /test
hadoop fs -put node.tar.gz /test/
hadoop fs -put a.txt /


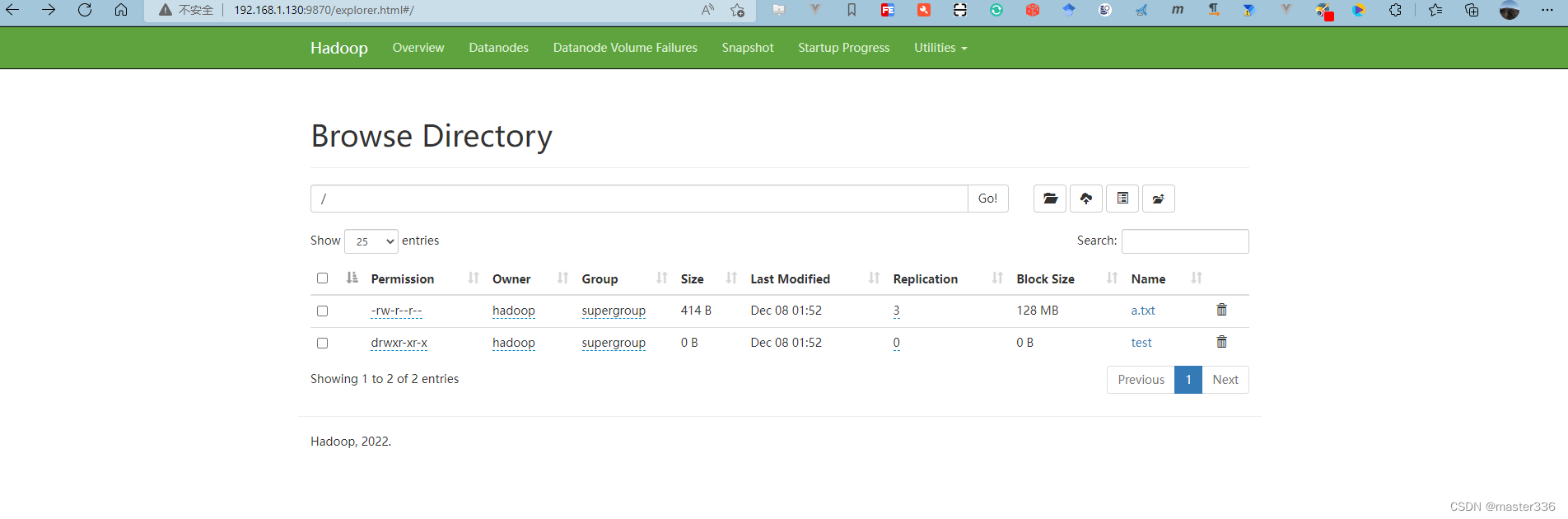
4.2 查看
hadoop fs -ls /
hadoop fs -ls /test

4.3 下载
hadoop fs -get /a.txt
hadoop fs -get /test/node.tar.gz

4.4 删除
hadoop fs -rm -r -f /test
hadoop fs -rm /a.tx

4.5 yarn任务提交
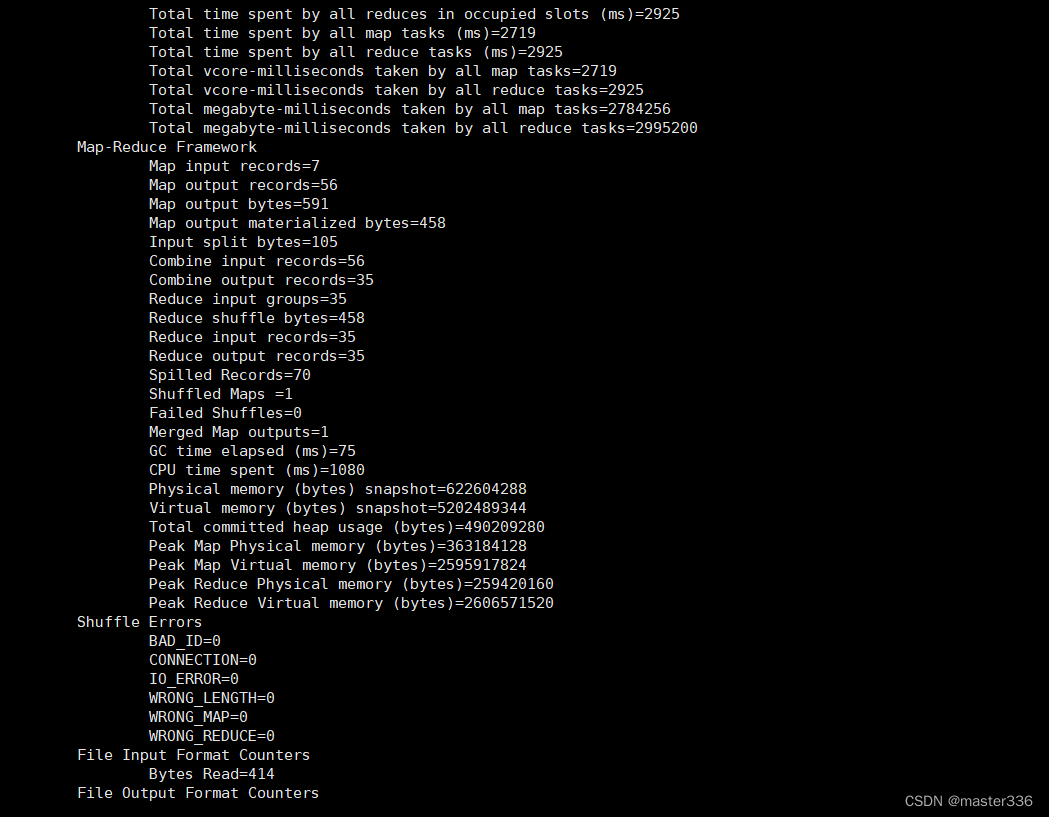
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input.txt /output.txt
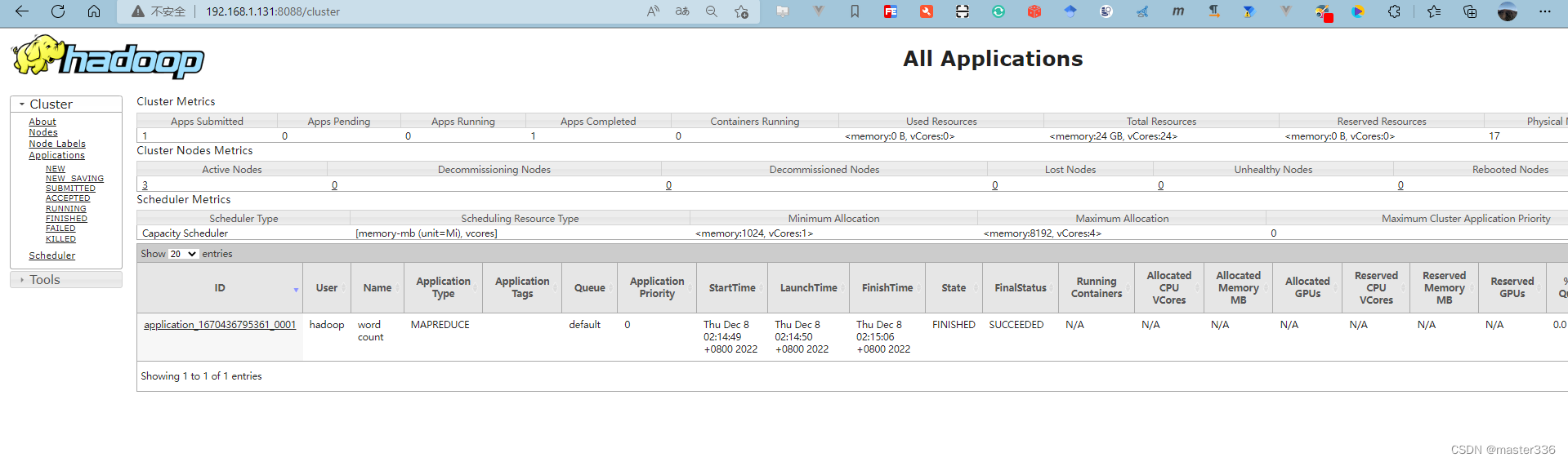
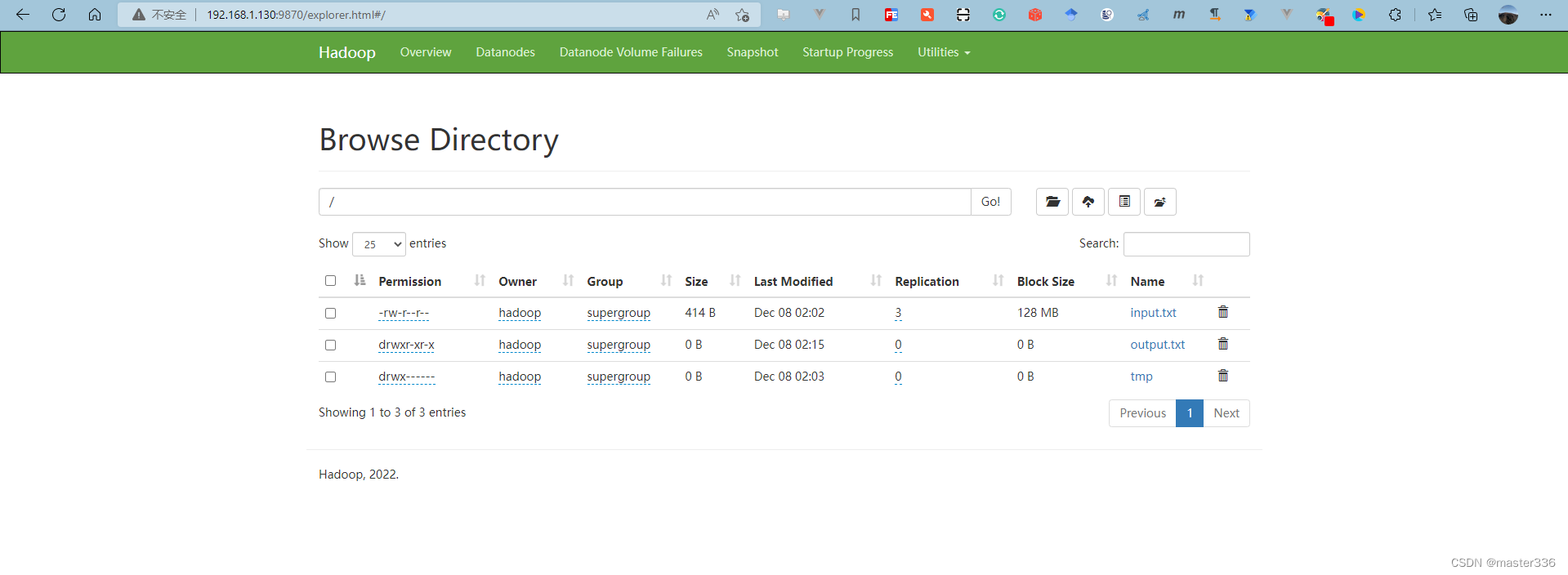
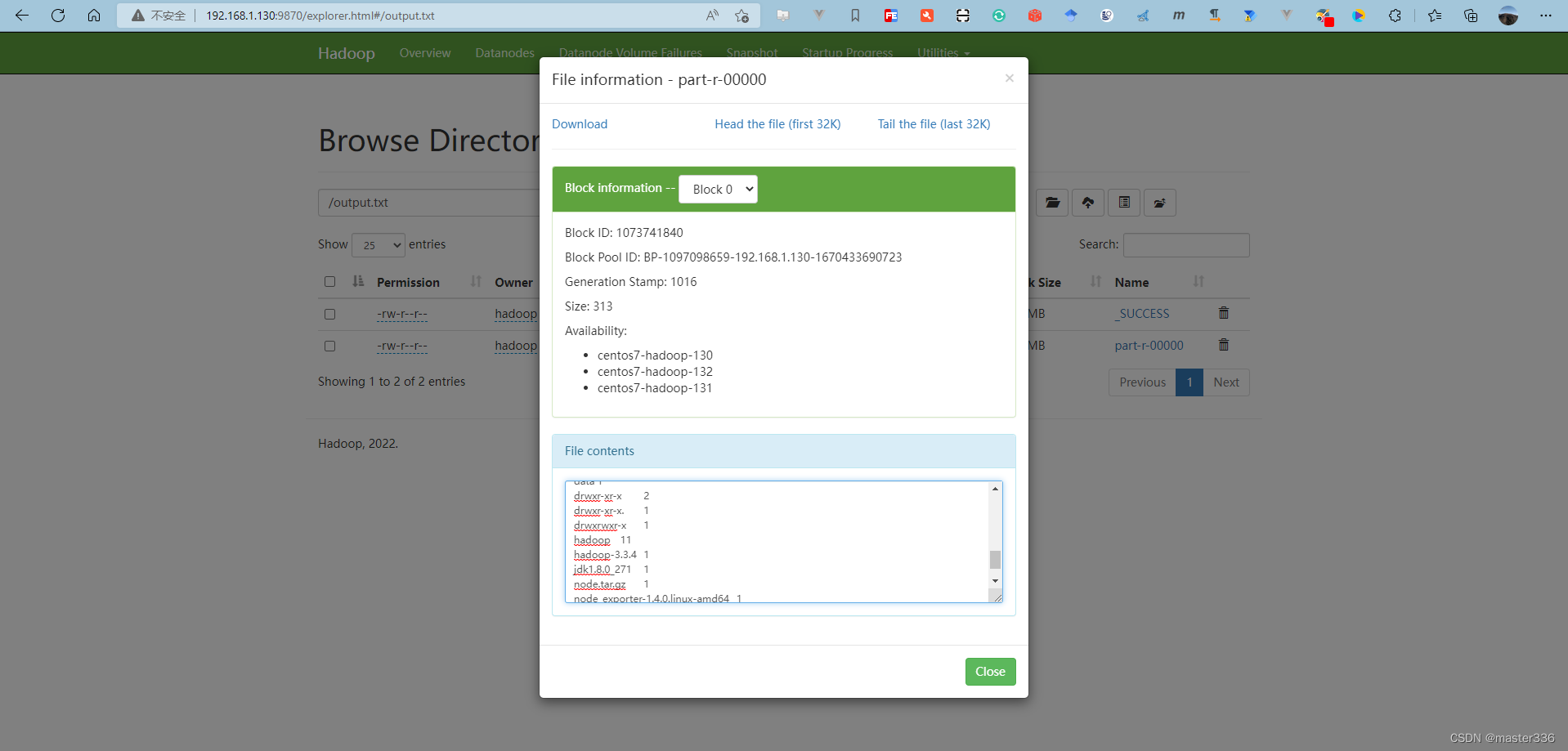
5. 常用端口清单
对比下hadoop2.x 与hadoop3.x 端口清单
| 端口用处 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode 内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce 查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
6. 常用命令清单
6.1 集群启停
6.1.1 HDFS
#启动
$HADOOP_HOME/sbin/start-dfs.sh
#停止
$HADOOP_HOME/sbin/stop-dfs.sh
6.1.1 yarn
#启动
$HADOOP_HOME/sbin/start-yarn.sh
#停止
$HADOOP_HOME/sbin/stop-yarn.sh
6.2 按模块
6.2.1 HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
6.2.1 YARN组件
yarn --daemon start/stop resourcemanager/nodemanager
6.3 历史服务器
mapred --daemon stop historyserver
mapred --daemon start historyserver
![[附源码]Python计算机毕业设计SSM基于云服务器网上论坛设计(程序+LW)](https://img-blog.csdnimg.cn/ede49777320d4a5fac73e110750b39d9.png)


![Docker[3]-Docker的常用命令](https://img-blog.csdnimg.cn/1a085b428ecf4a19a582f38aeed5cf06.png)