目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python 环境
- 模块实现
- 1. 数据爬取
- 2. 去噪与分割
- 3. 模型训练及保存
- 4. 准确率验证
- 系统测试
- 工程源代码下载
- 其它资料下载

前言
本项目利用Python爬虫技术,通过网络爬取验证码图片,并通过一系列的处理步骤,包括去噪和分割,以实现对验证码的识别和准确性验证。
首先,我们使用Python爬虫技术自动从目标网站上获取验证码图片。这些验证码通常是为了防止机器人自动访问或提交表单而设计的。通过爬虫技术,我们可以获取这些验证码图片用于后续处理。
接下来,我们对获取的验证码图片进行去噪和分割处理。去噪操作可以帮助去除图片中的干扰信息,使得验证码更清晰易读。分割操作将验证码中的每个字符单独提取出来,以便后续进行识别。
随后,我们采用KNN算法(K-Nearest Neighbors)来训练一个模型。KNN算法是一种常用的监督学习算法,可以根据样本的特征和标签来进行分类。我们将使用KNN算法对分割后的验证码字符进行训练,以便模型能够识别不同的字符。
最后,我们对训练好的模型进行准确率验证。通过将一部分已知标签的验证码图片输入模型,我们可以得到模型的预测结果。将预测结果与实际标签进行比较,可以计算出模型的准确率,从而评估模型的性能。
这个项目的目标是通过爬虫技术和图像处理算法,实现对验证码图片的自动识别和准确率验证。它可以应用于需要处理大量验证码的场景,如自动化测试、数据采集等。通过训练和验证模型的过程,我们可以不断提升验证码识别的准确性和稳定性,提高验证码处理的效率。
总体设计
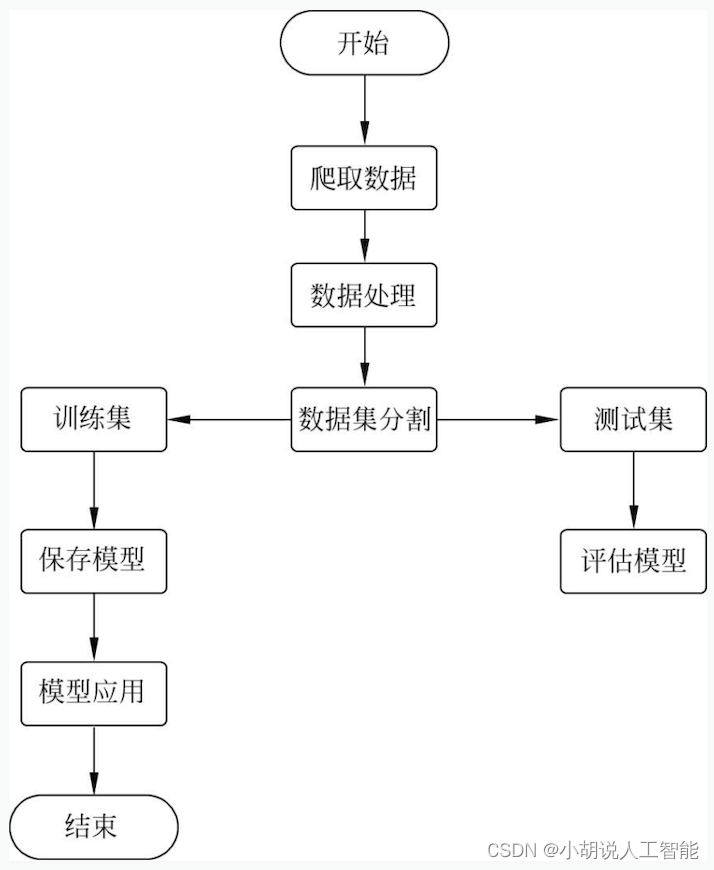
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。

系统流程图
系统流程如图所示。
运行环境
本部分主要为 Python 环境
Python 环境
需要Python 2.7配置,在Windows环境下下载Anaconda完成Python所需的配置,下 载地址为https://www.anaconda.com/,也可以下载虚拟机在Linux环境下运行代码。
模块实现
本项目包括4个模块:数据爬取、去噪与分割、模型训练及保存、准确率验证,下面分别介绍各模块的功能及相关代码。
1. 数据爬取
本部分用request库爬虫抓取验证码1200张,并做好标注。相关代码如下:
from __future__ import unicode_literals
import requests
import time
if __name__ == "__main__":
#获取图片总数设置number
number = 100
for num in range(number):
img_url='http://run.hbut.edu.cn/Account/LogOn?ReturnUrl=%2f '
data={'timestamp':unicode(long(time.time()*1000))}
#print (img_url)
res = requests.get(img_url,params=data)
#这是一个get请求,获取图片资源
with open("./download_image/%d.jpg" % num, "wb") as f:
#将图片保存在本地
f.write(res.content)
print("%d.jpg" % num + "获取成功")
2. 去噪与分割
图片爬取成功后进行去噪与分割。
1)去除背景噪声
转换成灰度图后对图片进行分割,去掉边框和部分噪声,分成4张图,统计每张图的灰度直方图(自己设置bins),找到第二大对应的像素范围(即某一-像素范围内像素数第二多,对应的像素范围。像素最多的应该是白色,空白处),取像素范围中位数模式,然后保留(mode土biases)的像素,去除大部分噪声。
def del_noise(im_cut):
bins = 16
num_gray = math.ceil(256 / bins)
#函数返回大于或等于一个给定数字的最小整数
hist = cv2.calcHist([im_cut], [0], None, [bins], [0, 256])
lists = []
for i in range(len(hist)):
#print hist[i][0]
lists.append(hist[i][0])
second_max = sorted(lists)[-2]
#查找第二多像素,最多的是验证码空白
bins_second_max = lists.index(second_max)
#取像素范围中位数mode,保留(mode±biases)的像素
mode = (bins_second_max + 0.5) * num_gray
for i in range(len(im_cut)):
for j in range(len(im_cut[0])):
#print im_cut[i][j]
if im_cut[i][j] < mode - 15 or im_cut[i][j] > mode + 15:]
#不在中位数附近的设为白(255)
im_cut[i][j] = 255
return im_cut
2)图片分割
分割1200张已标注好的图片,得到4800张子图片。相关代码如下:
def cut_image(image, num, img_name):
#image = cv2.imread('./img/8.jpg')
#将BGR格式图片转换成灰度图片
im = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#im_cut_real = im[8:47, 28:128]
im_cut_1 = im[8:47, 27:52]
im_cut_2 = im[8:47, 52:77]
im_cut_3 = im[8:47, 77:102]
im_cut_4 = im[8:47, 102:127]
im_cut = [im_cut_1, im_cut_2, im_cut_3, im_cut_4]
for i in range(4):
im_temp = del_noise(im_cut[i])
#将图片分割为4个
cv2.imwrite('./img_train_cut/'+str(num)+ '_' + str(i)+'_'+img_name[i]+'.jpg', im_temp)
if __name__ == '__main__':
img_dir = './img'
img_name = os.listdir(img_dir) #列出文件夹下所有的目录与文件
for i in range(len(img_name)):
path = os.path.join(img_dir, img_name[i])
image = cv2.imread(path)
name_list = list(img_name[i])[:4]
#name = ''.join(name_list)
cut_image(image, i, name_list)
print '图片%s分割完成' % (i)
print u'*****图片分割预处理完成!*****'
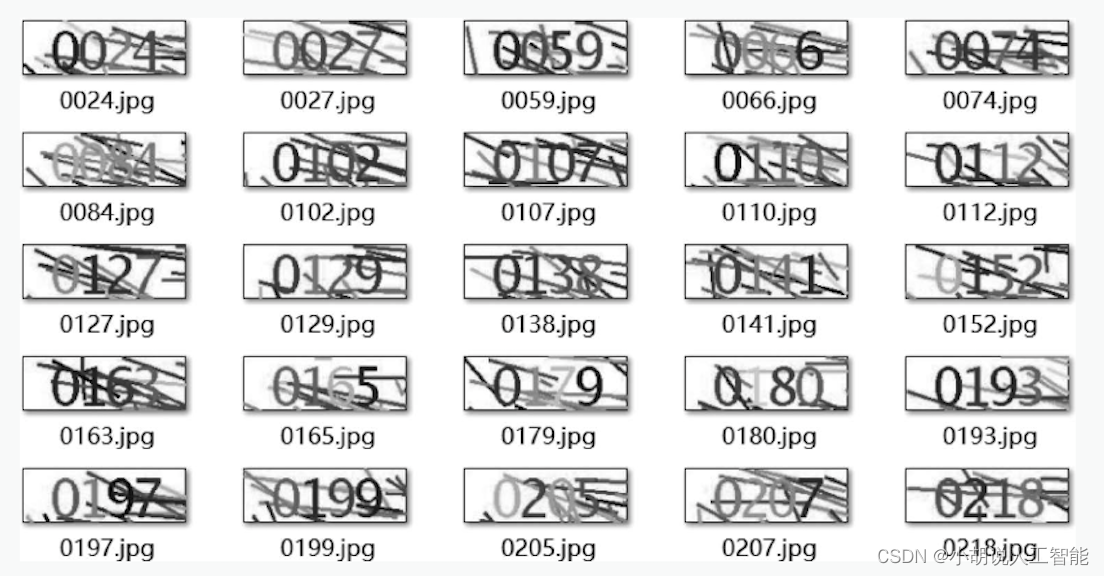
分割图片成功,如下图所示:

3. 模型训练及保存
处理数据后拆分训练集和测试集,训练并保存。相关代码如下:
_image(image, num, img_name):
#image = cv2.imread('./img/8.jpg')
#将BGR格式图片转换成灰度图片
im = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#im_cut_real = im[8:47, 28:128]
im_cut_1 = im[8:47, 27:52]
im_cut_2 = im[8:47, 52:77]
im_cut_3 = im[8:47, 77:102]
im_cut_4 = im[8:47, 102:127]
im_cut = [im_cut_1, im_cut_2, im_cut_3, im_cut_4]
for i in range(4):
im_temp = del_noise(im_cut[i])
#将图片分割为4个
cv2.imwrite('./img_train_cut/'+str(num)+ '_' + str(i)+'_'+img_name[i]+'.jpg', im_temp)
if __name__ == '__main__':
img_dir = './img'
img_name = os.listdir(img_dir) #列出文件夹下所有的目录与文件
for i in range(len(img_name)):
path = os.path.join(img_dir, img_name[i])
image = cv2.imread(path)
name_list = list(img_name[i])[:4]
#name = ''.join(name_list)
cut_image(image, i, name_list)
print '图片%s分割完成' % (i)
print u'*****图片分割预处理完成!*****'
8.3.3 模型训练及保存
import numpy as np
from sklearn import neighbors
import os
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.externals import joblib
import cv2
if __name__ == '__main__':
#读入数据
data = []
labels = []
img_dir = './img_train_cut'
img_name = os.listdir(img_dir)
#number = ['0','1', '2','3','4','5','6','7','8','9']
for i in range(len(img_name)):
path = os.path.join(img_dir, img_name[i])
#cv2读进来的图片是RGB3维的,转成灰度图,将图片转化成1维
image = cv2.imread(path)
im = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = im.reshape(-1)
data.append(image)
y_temp = img_name[i][-5]
labels.append(y_temp)
#标签规范化
y = LabelBinarizer().fit_transform(labels)
x = np.array(data)
y = np.array(y)
#拆分训练数据与测试数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
#训练KNN分类器
clf = neighbors.KNeighborsClassifier()
clf.fit(x_train, y_train)
#保存分类器模型
joblib.dump(clf, './knn.pkl')
#测试结果打印
pre_y_train = clf.predict(x_train)
pre_y_test = clf.predict(x_test)
class_name = ['class0', 'class1', 'class2', 'class3', 'class4', 'class5', 'class6', 'class7', 'class8', 'class9']
print classification_report(y_train, pre_y_train, target_names=class_name)
print classification_report(y_test, pre_y_test, target_names=class_name)
#clf = joblib.load('knn.pkl')
#pre_y_test = clf.predict(x)
#print pre_y_test
#print classification_report(y, pre_y_test, target_names=class_name)
模型保存后,可以被重新使用,也可以移植到其他环境中使用。
4. 准确率验证
用验证码原图(4个数字)来测试准确率,相关代码如下:
from __future__ import division
import cv2
import math
import numpy as np
import os
from sklearn.externals import joblib
def del_noise(im_cut):
'''
变量bins:灰度直方图bin的数目
num_gray:像素间隔
方法:1.找到灰度直方图中像素第二多对应的像素,即second_max,因为图像空白处比较多,所以第一多的应该是空白,第二多的是想要的内容。2.计算mode。3.除了mode附近,全部变为空白。
'''
bins = 16
num_gray = math.ceil(256 / bins)
hist = cv2.calcHist([im_cut], [0], None, [bins], [0, 256])
lists = []
for i in range(len(hist)):
#print hist[i][0]
lists.append(hist[i][0])
#将 hist 列表添加到 lists
second_max = sorted(lists)[-2]
#查找第二多像素,最多的是验证码的空白
bins_second_max = lists.index(second_max)
#取像素范围中位数mode,然后保留(mode±biases)的像素
mode = (bins_second_max + 0.5) * num_gray
for i in range(len(im_cut)):
for j in range(len(im_cut[0])):
if im_cut[i][j]<mode - 15 or im_cut[i][j] > mode + 15:
# print im_cut[i][j]
im_cut[i][j] = 255
#不在中位数附近的设为白(255)
return im_cut
def predict(image, img_name):
#image = cv2.imread('./img/8.jpg')
im = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#将BGR格式转换成灰度图片
#im_cut_real = im[8:47, 28:128]
im_cut_1 = im[8:47, 27:52]
im_cut_2 = im[8:47, 52:77]
im_cut_3 = im[8:47, 77:102]
im_cut_4 = im[8:47, 102:127]
im_cut = [im_cut_1, im_cut_2, im_cut_3, im_cut_4]
pre_text = []
for i in range(4):
#图片转换成1维后,再转换成2维的输入变量x
im_temp = del_noise(im_cut[i])
#print type(im_temp)
image = im_temp.reshape(-1)
#print image.shape
tmp = []
tmp.append(list(image))
x = np.array(tmp)
pre_y = clf.predict(x)
pre_y = np.argmax(pre_y[0])
pre_text.append(str(pre_y))
#print pre_text
pre_text = ''.join(pre_text)
if pre_text != img_name:
print'label:%s'%(img_name),'predict:%s'%(pre_text),'\t','false'
return 0
else:
print 'label:%s'%(img_name),'predict:%s'%(pre_text)
return 1
if __name__ == '__main__':
img_dir = './img_test'
img_name = os.listdir(img_dir) #列出文件夹下所有的目录与文件
right = 0
global clf
clf = joblib.load('knn.pkl')
for i in range(len(img_name)):
path = os.path.join(img_dir, img_name[i])
image = cv2.imread(path)
name_list = list(img_name[i])[:4]
name = ''.join(name_list)
pre = predict(image, name)
right += pre
accuracy = (right/len(img_name))*100
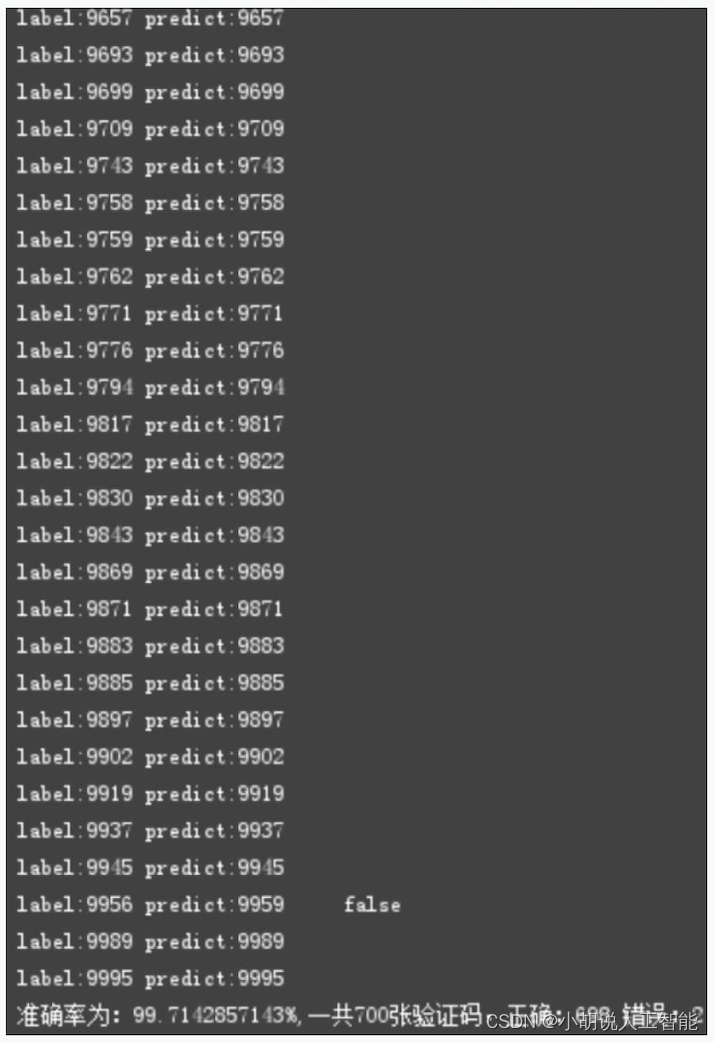
print u'准确率为:%s%%,一共%s张验证码,正确:%s,错误:%s'%(accuracy,len(img_name),right,len(img_name)-right)
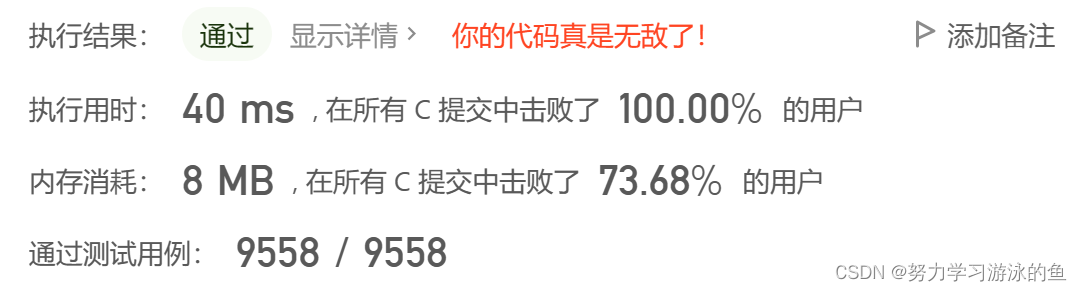
系统测试
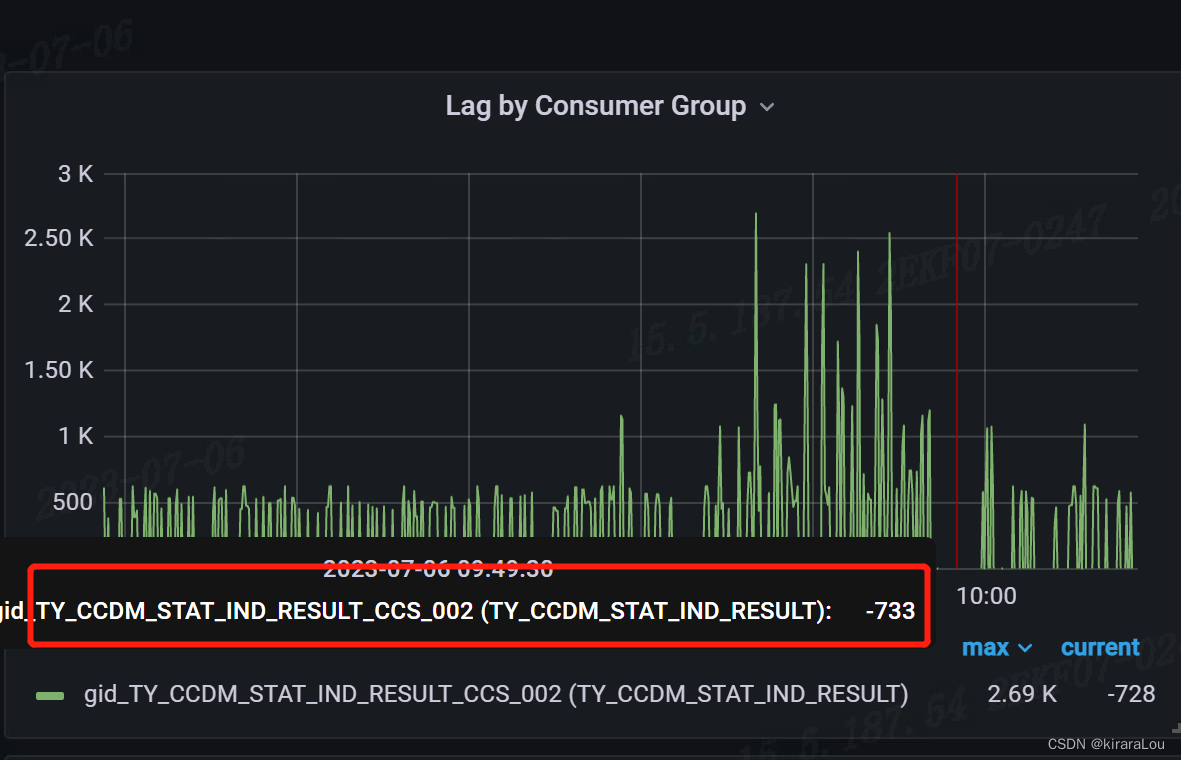
测试结果精度达到99%以上,如下图所示。
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。