线性回归
- 1、线性回归定义
- 2、线性回归题目示例
- 3、推导公式
- 4、误差
- 5、似然函数
- 6、线性回归评价指标
- 7、梯度下降
1、线性回归定义
-
经典统计学习技术中的线性回归和
softmax回归可以视为 线性神经⽹络。给定训练数据特征 X 和对应的已知标签 y ,线性回归的⽬标是找到⼀组权重向量 w 和偏置 b。当给定从X的同分布中取样的新样本特征时,找到的权重向量和偏置能够使得新样本预测标签的误差尽可能小。 -
线性回归是一个单层的神经网络,所以可以作为分类,检测等问题很多网络结构的最后的输出层。
-
机器学习模型中的关键要素是训练数据,损失函数,优化算法,还有模型本⾝。
-
⽮量化使数学表达上更简洁,同时运⾏的更快。
-
最小化⽬标函数和执⾏最⼤似然估计等价。
-
线性回归模型也是神经⽹络。
-
回归:就是预测值通过网络迭代逐渐逼近真实值的过程
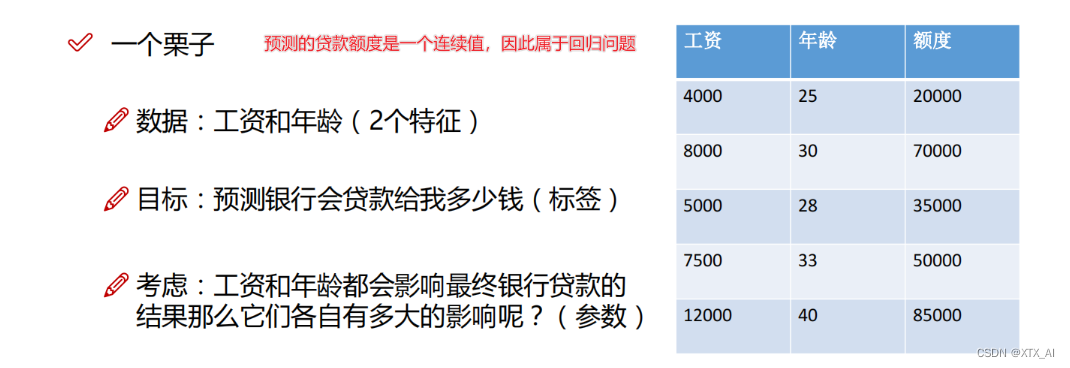
2、线性回归题目示例
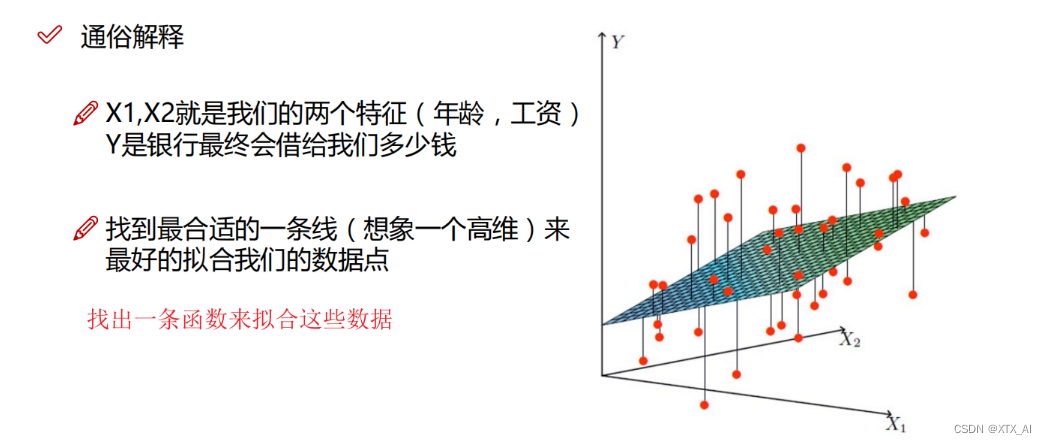
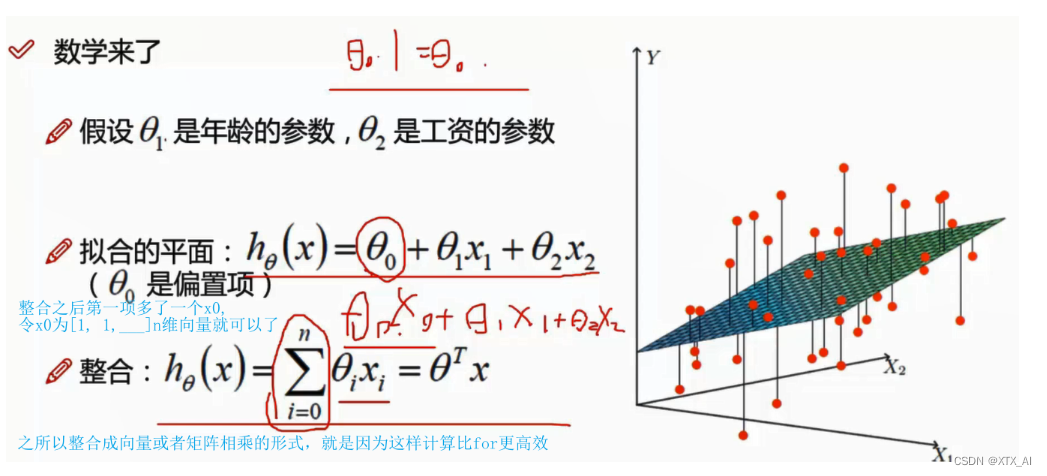
3、推导公式
其实x和参数看成是行向量和列向量都行,只要相乘后得到的预测值Y是一个列向量就行(一个样本就是一维列向量,多个样本集成在一块就是多维列向量,总之一个样本不管有多少元或者多少维 的参数或者特征,只对应一个预测值y, 且不同样本中参数的值是一样的,不同的只是特征的值不同)
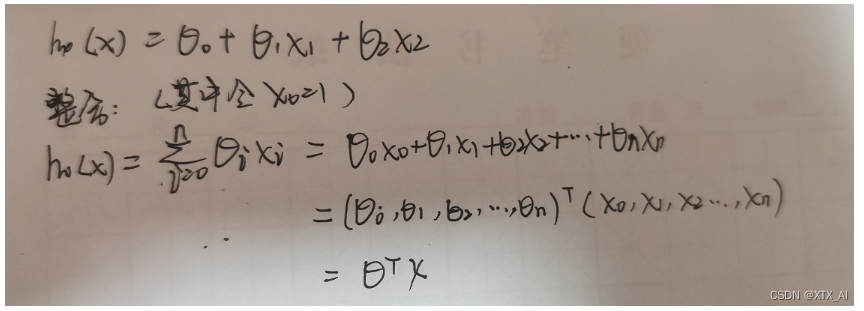
应该是这样的(其实 都行,保证输出正确就行):

-
要注意的是这中间x1, x2……,是特征,整合后的x是一个包含所有特征的向量,应该是针对每一个样本(数据)都是这样 ,比如下图中根据工资和年龄这两个特征也预测贷款额度的第一行数据(也就是第一个样本)
-
而所说的高维是指的是高维度的特征,而不是很多样本

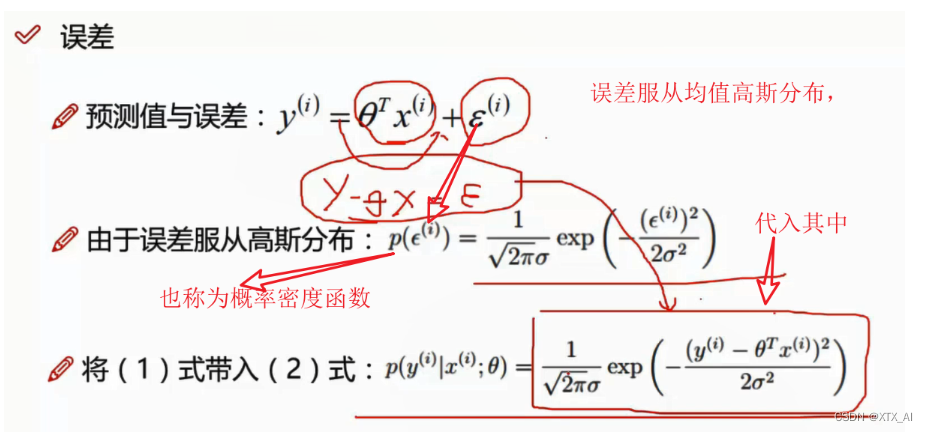
4、误差
预测值中就包含了偏置项,然后预测值不可能就恰好是真实值,也会存在着一个误差,且每个样本的误差都是不一样的
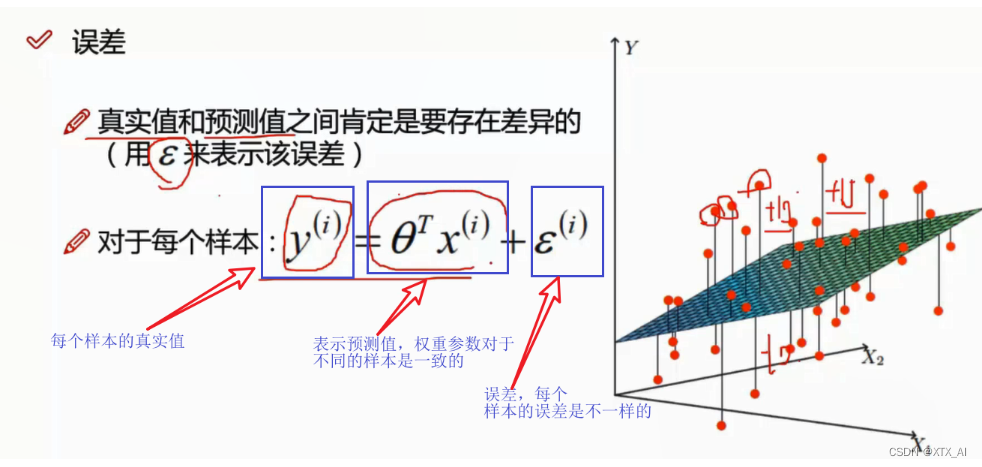
当数据不符合高斯分布时,我们需要进行转换使其符合高斯分布
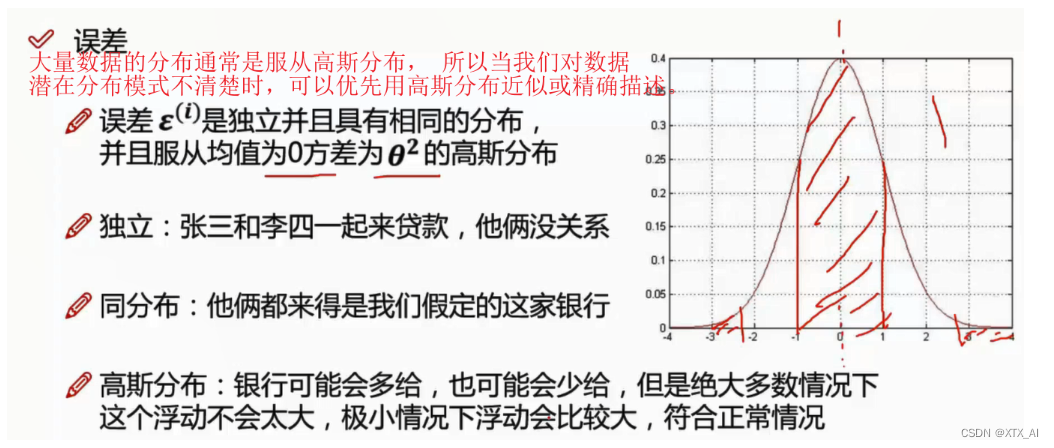
5、似然函数
最大似然函数 (maximum likelihood estimates,MLE)
似然函数是根据样本去估计参数值; 最大(极大)似然估计是一种确定模型参数值的方法。确定参数值的过程,是找到能最大化模型产生真实观察数据可能性的那一组参数。

我们需要使用极大似然估计来找到能最大化模型产生真实观察数据可能性的那一组参数 (如果数据服从高斯分布,因此要求求解的参数就是均值和标准差,注意这里是每个每个样本对应的误差服从正太分发布,要求的参数不是标准差),而似然估计概率(L),也就是联合概率是越大越好;使用对数似然求解,化简如下:

疑问:这里的目标函数就是CNN中常用的损失吗?
还需要掌握矩阵求导,完全推导出求偏导的步骤


这样是直接通过求偏导来求出参数的值,线性回归是个特例,可以直接求出参数,但目标函数并不总能求解,所以需要借助梯度下降方法来求解,当然线性回归我们也可以用梯度下降法来求解参数,应该更为简单
6、线性回归评价指标

此外, RMSE(Root Mean Square Error)均方根误差 ; MSE(Mean Square Error)均方误差 ;F-statistic(F统计或者F检验)也可以用来评价一个线性回归模型;
F statistic, F统计也称F检验,它是检验因变量与所有自变量之间的线性关系是否显着, 多元线性回归中当我们想要测定多元自变量是否整体与y因变量线性相关时,就需要F检验
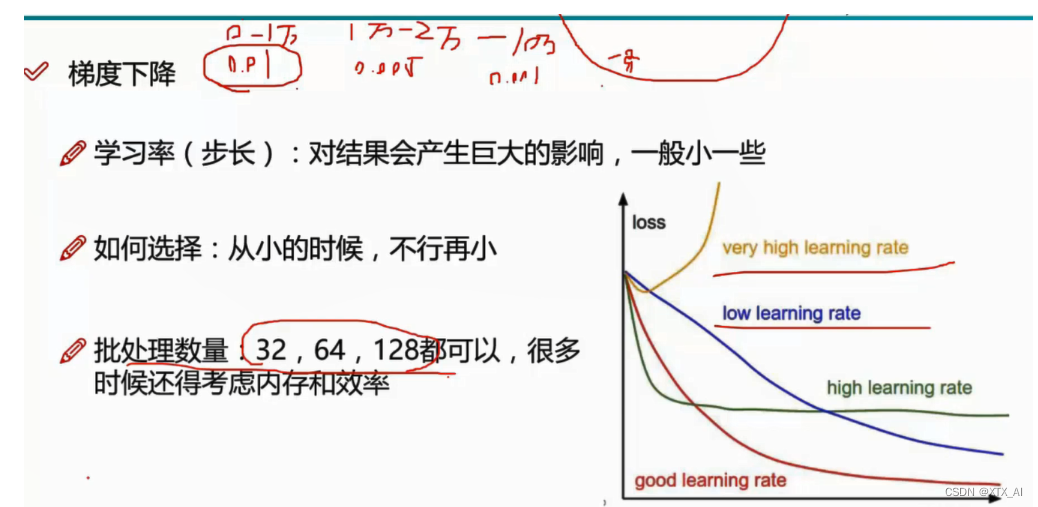
7、梯度下降
在线性回归中,可以通过求偏导直接计算出参数解, 但目标函数并不总是好求解或者能求解(通过求偏导来求解),因此需要通过梯度下降法来计算出参数,下面是使用梯度下降法通过迭代来更新参数,最终得到参数解。
θ 中的 θ1, θ2……是各自求偏导优化,而不是整体去优化

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uC6IsxP1-1666598578897)(md_images_save/images_save_add/1662887082967.png)]](https://img-blog.csdnimg.cn/fc8aca3645ac42d1932a47927d7ef69e.png)
该实例目标函数中θ0, θ1,在进行梯度下降时会赋予一个初始值,也就是参数初始化
梯度前加一个负号,就意味着朝着梯度相反的方向前进!我们在前文提到,梯度的方向实际就是函数在此点上升最快的方向!而我们需要朝着下降最快的方向走,自然就是负的梯度的方向,所以此处需要加上负号;那么如果时上坡,也就是梯度上升算法,当然就不需要添加负号了。

学习率先稍微大一点,后在减少一些,学习率太大 ,容易错过最低点,太小迭代速度太慢