一、基本语法结构
列表推导式的基本语法结构为:
[ expression for item in iterable if condition ]
其中,expression表示参与列表生成的表达式,可包含变量、函数调用等操作;item表示生成列表中的元素;iterable表示可迭代的对象,例如列表、元组、集合等;if condition表示对条件的筛选,可以省略。
expression表示要对每个item进行操作的表达式,item是可迭代对象中的每个元素,if condition是可选的筛选条件。在执行完毕后,将得到一个新的列表new_list。
"""
生成1-9的整数列表
"""
myList = [x for x in range(1,10)]
# [1,2,3,4,5,6,7,8,9]
print(myList)
"""
生成1~9之间的整数的平方列表
"""
square_list = [i**2 for i in range(1,11)]
# [1, 4, 9, 16, 25, 36, 49, 64, 81]
print(square_list)
"""
从一个字符串列表中筛选出长度超过3的字符串
"""
str_list = ['hello', 'world', 'python', 'list', 'comprehension', 'study']
new_list = [s for s in str_list if len(s) > 3]
#
print(new_list)
多重循环
my_list = [n*m for n in range(1,3) for m in range(1,3) ]
# 此处通过两层循环实现了乘法操作,即n和m分别取1、2时,它们的乘积构成了列表中的元素
# [1,2,2,4]
print(my_list)
嵌套列表推导式
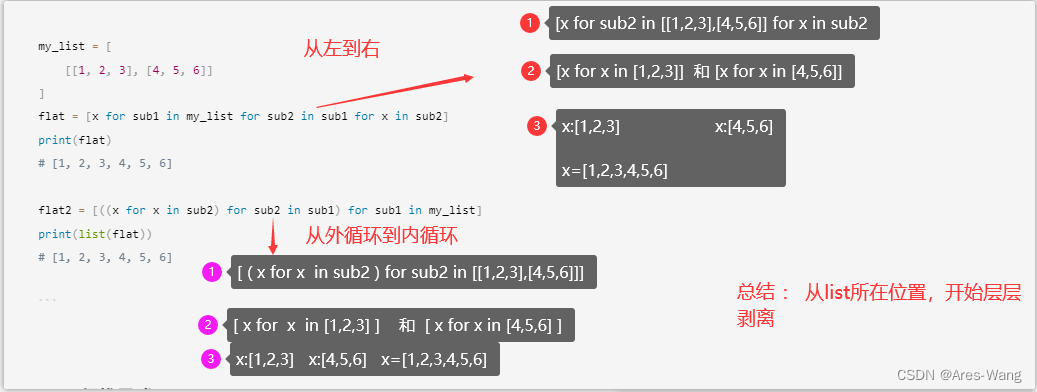
有时候需要在生成一个列表时,对其中的元素进行更加复杂的操作,此时就可以使用嵌套列表推导式。嵌套列表推导式即在列表推导式的基础上再次嵌套列表推导式,其语法结构为:
[ expression for item in iterable if condition for sub_item in sub_iterable if sub_condition ]
其中,expression、item、iterable和condition的含义与上述基本语法结构中一致;sub_item表示在item遍历的基础上再次遍历的元素;sub_iterable表示sub_item的迭代对象;sub_condition表示对sub_item的筛选条件。
matrix = [[i*j for j in range(1,4)] for i in range(1,4)]
for row in matrix:
print(row)
"""
[1, 2, 3]
[2, 4, 6]
[3, 6, 9]
"""
my_list = [
[[1, 2, 3], [4, 5, 6]]
]
flat = [x for sub1 in my_list for sub2 in sub1 for x in sub2]
print(flat)
# [1, 2, 3, 4, 5, 6]
flat2 = [((x for x in sub2) for sub2 in sub1) for sub1 in my_list]
print(list(flat))
# [1, 2, 3, 4, 5, 6]
元组推导式
元组推导式类似于列表推导式,只是将中括号换为了小括号。
元组推导式和列表推导式不一样,其生成的是一个对象, 一个生成器对象,并不直接是一个元组;如果想要得到一个元组或列表的话,那么就需要通过tuple()或list()来进行转化。
import random
randomnumber = (random.randint(10, 100) for i in range(10))
print(randomnumber)
>>>
<generator object <genexpr> at 0x00000165F97CE5C8>
我们发现并没有生成元组,而只是得到了一个生成器,我们还需要转换一下:
import random
randomnumber = (random.randint(10, 100) for i in range(10))
print(tuple(randomnumber))
>>>
(68, 39, 49, 22, 34, 39, 12, 53, 19, 29)
综上,我们使用元组推导式时,得到的并不是一个元组,而是一个生成器,如果我们希望输出元组,我们还需要使用tuple() 函数转换一下。
另外,我们还可以直接遍历生成器:
import random
randomnumber = (random.randint(10, 100) for i in range(10))
##print(tuple(randomnumber))
for i in randomnumber:print(i, end = " ")
>>>
75 88 76 77 65 13 82 31 71 35
import random
print(tuple(random.randint(10,1000) for i in range(10)))
print(list(random.randint(10,1000) for i in range(10)))
输出为:
(930, 139, 668, 598, 493, 936, 742, 763, 339, 205)
[437, 689, 372, 171, 876, 451, 336, 903, 513, 727]
元组推导式得到的结果是一个生成器对象,并不是一个元组。
如果我们不想转换成元组或列表,但还想输出生成器中的内容,那就要使用for循环来遍历它了。
import random
yz=(random.randint(10,1000) for i in range(10))
for i in yz:
# 输出的是单个数,并不是元组;如果用默认的换行的话,输出的数更是每个一行(所以输出没有外面的括号);
print(i,end=' ') #不换行,用空格分割
输出为:
725 10 513 74 42 683 143 997 315 795
魔法方法
对于生成器对象除了可以使用for循环来遍历它,还可以使用__next__来遍历它
import random #导入随机数模块
yz=(random.randint(10,1000) for i in range(10))
print(yz.__next__())#输出生成器中的第一个元素
print(yz.__next__())#输出生成器中的第二个元素
print(yz.__next__())#输出生成器中的第三个元素
420
709
760
可看到,当for循环输出生成器对象中的10个元素;再次转换成元组输出,但此时生成器的内容为空了,
因为:当我们对生成器对象当中的内容进行访问后,这个生成器对象已经不存在了,
所以再对它进行转换后,它就是一个空的元组了;
如果希望再使用这个生成器对象,则必须重新生成。
import random #导入随机数模块
yz=(random.randint(10,1000) for i in range(10))
for i in yz:
print(i,end=' ')
print(tuple(yz))
输出为:
935 51 628 73 392 442 145 694 369 173 ()
字典推导式
语法1
new_dictionary = {key_exp:value_exp for key, value in dict.items() if condition}
字典推导式说明:
key:dict.items()字典中的key
value:dict.items()字典中的value
dict.items():序列
condition:if条件表达式 : 可以用key,也可以用value
key_exp:在for循环中,如果if条件表达式condition成立(即条件表达式成立),返回对应的**key,value当作key_exp,value_exp**处理
value_exp:在for循环中,如果if条件表达式condition成立(即条件表达式成立),返回对应的**key,value当作key_exp,value_exp**处理
这样就返回一个新的字典。
dictionary_1 = {'a': '1234', 'B': 'FFFF', 'c': ' 23432', 'D': '124fgr', 'e': 'eeeee', 'F': 'QQQQQ'}
# 案例一:获取字典中key值是小写字母的键值对
new_dict_1 = {key: value for key, value in dictionary_1.items() if key.islower()}
new_dict_2 = {g: h for g, h in dictionary_1.items() if g.islower()}
# g, h只是一个变量,使用任意字母都行,但是一定要前后保持一致。
print(new_dict_1)
print(new_dict_2)
# 案例二:将字典中的所有key设置为小写
# 字典推导式 key:可以是变量,也可以是表达式,函数等
new_dict_3 = {key.lower(): value for key, value in dictionary_1.items()}
# 将字典中的所有key设置为小写,value值设置为大写
new_dict_4 = {key.lower(): value.upper() for key, value in dictionary_1.items()}
print(new_dict_3)
print(new_dict_4)
三元表达式又称三元运算符,是软件编程中的一个固定格式,语法是“条件表达式?表达式1:表达式2”。常用于根据条件为变量赋值。
Python中也有三元表达式,不过Python的三元运算符和C语言以及Java等语言有所区别,语法格式为:
表达式1 if 条件表达式 else 表达式2
当表达式返回True时,返回结果表达式1,否则返回结果表达式2
语法2
{key_exp:value_exp1 if condition else value_exp2 for key, value in dict.items()}
字典推导式说明:
key:dict.items()字典中的key
value:dict.items()字典中的value
dict.items():序列
condition:if条件表达式的判断内容
value_exp1:在for循环中,如果条件表达式condition成立(即条件表达式成立),返回对应的key,value并作key_exp,value_exp1处理
value_exp2:在for循环中,如果条件表达式condition不成立(即条件表达式不成立),返回对应的key,value并作key_exp,value_exp2处理

# 在爬虫中,我们需要获取cookies并以字典的形式传参,如果cookies是字符串则需要转换为字典,经典代码案例如下:
# 原来的cookies很长,这里截取一部分做演示:
cookies = "anonymid=jy0ui55o-u6f6zd; depovince=GW; _r01_=1; JSESSIONID=abcMktGLRGjLtdhBk7OVw; ick_login=a9b557b8-8138-4e9d-8601-de7b2a633f80"
# 字典推导式,将长的字符串转化为字典。
new_dict_1 = {cookie.split("=")[0]: cookie.split("=")[1] for cookie in cookies.split(";")}
print(new_dict_1)
"""
代码分析:
在字符串cookies中’=’前面是key,’=’后面是value,每一个’;’构成一个键值对;多个键值对构成一个字典;
1.根据’;’将字符串拆分为列表;
2.根据第一步获取的列表,遍历时将每一个字符串根据’=’再次拆分;
3.根据第二步拆分的结果,列表第一个元素作为key,列表第二个元素作为value;
"""
new_dict_2 = {key: value for t in cookies.split(";") for key, value in (t.split("="),)}
# 先将字符串通过';'分解成短的带有等号的字符串,然后将这个短的字符串转化为元组,最后再通过'='分解成俩个值分别赋给key、value。
print(new_dict_2)
"""
# 下面是分解的演示:
for t in cookies.split(';'):
print(type(t))
print((t.split('='),))
print(type((t.split('='),)))
print(cookies.split(';'))
"""
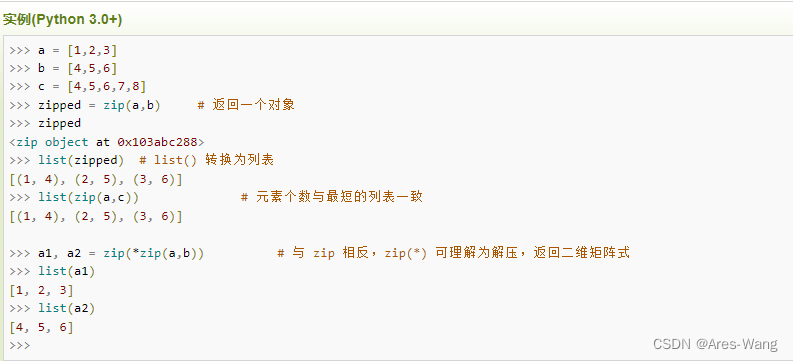
三元表达式又称三元运算符,是软件编程中的一个固定格式,语法是“条件表达式?表达式1:表达式2”。常用于根据条件为变量赋值。
Python中也有三元表达式,不过Python的三元运算符和C语言以及Java等语言有所区别,语法格式为:
表达式1 if 条件表达式 else 表达式2
当表达式返回True时,返回结果表达式1,否则返回结果表达式2
断言
assert expression [, arguments]
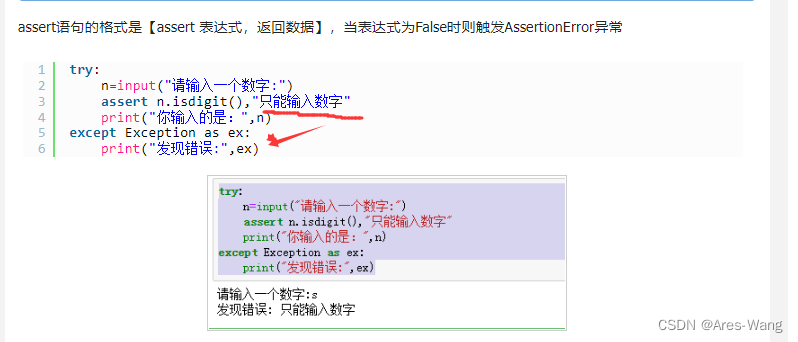
result = assert a, b 效果 类似 C# ??