作为一个查询函数,SUMMARIZE 执行三个操作:
- 它可以按表本身或相关表的任何列对表进行分组;
- 它可以创建新列,在行上下文和过滤上下文中计算表达式;
- 它可以产生不同级别的小计(subtotal)。
在 SUMMARIZE 的三个主要操作中,只有第一个是安全的。 另外两个操作——创建新列和计算小计——应该避免。 并不是说这些功能不起作用。 问题是 SUMMARIZE 的语义非常复杂,以至于结果可能出乎意料。 情况可能更糟:在第一次测试中结果可能看起来是正确的,但这可能只意味着 SUMMARIZE 正在静静地等着在背后捅你一刀,一旦部署到生产环境中,就会产生错误的结果,并且这个结果几乎是无法调试的 。
为了正确理解 SUMMARIZE,您必须了解集群的工作原理、行和过滤器上下文的存在有什么影响,以及扩展表在集群中的作用。 我们一次一步地介绍这些概念:首先是聚类,然后是扩展表在聚类中的作用,最后是同一公式中同时存在行和过滤器上下文的影响。
一,聚类(Clustering)
聚类是 SUMMARIZE 用来计算其结果的一种技术,我们使用只有七行的表来引入聚类。

SUMMARIZE (
Sales,
Sales[Color],
"Sales", SUM ( Sales[Amount] )
)

直觉上,我们可能会认为 SUMMARIZE 是从按 Sales[Color] 对 Sales 进行分组开始的; 然后它通过在颜色上创建过滤器上下文来计算具有相同颜色的所有行的 Amount 总和来迭代结果。 不幸的是,这将是 SUMMARIZE 执行的步骤的近似值。 它的作用更复杂。
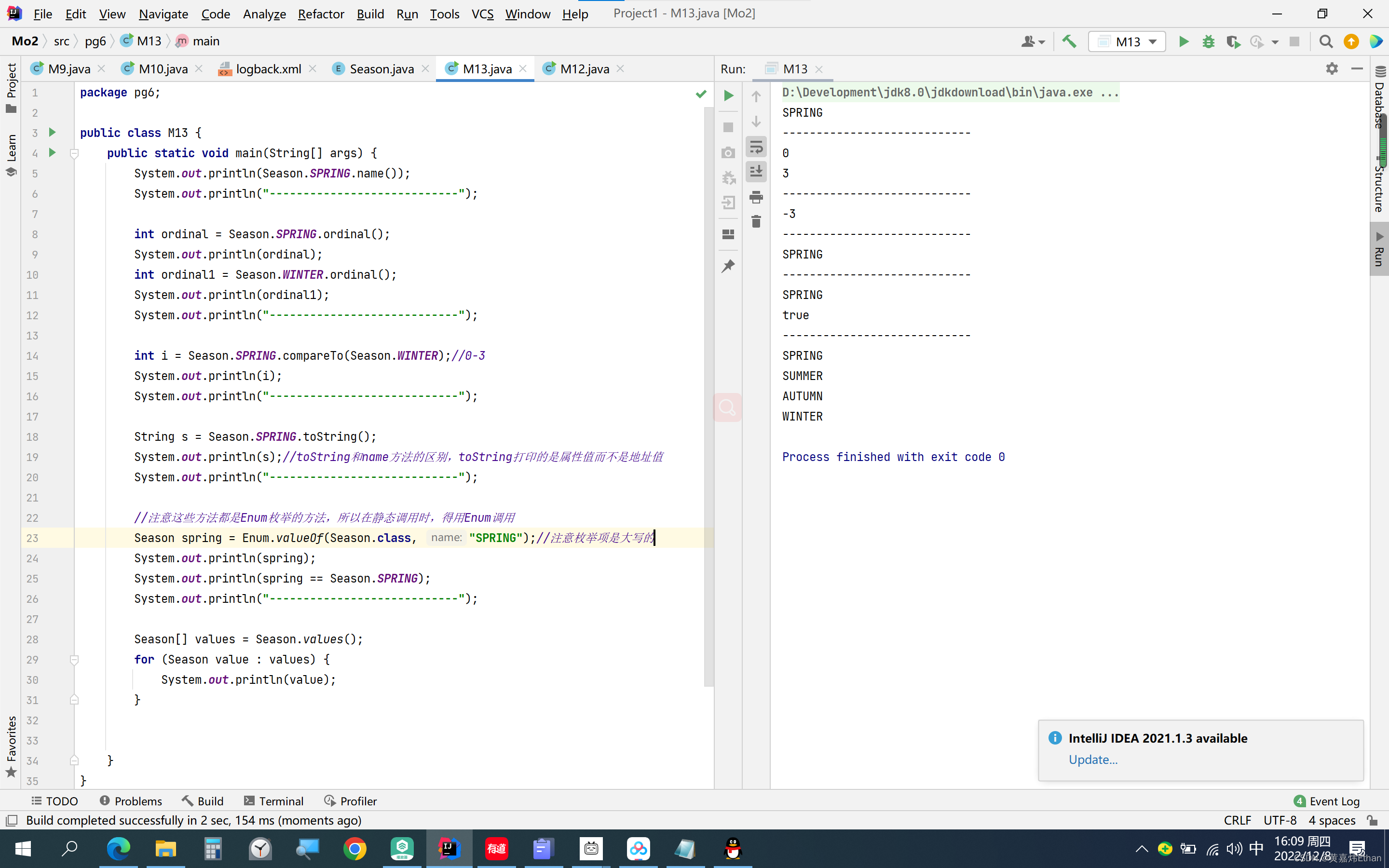
因为查询需要按颜色分组,所以 SUMMARIZE 将表拆分为分区——每种颜色一个。 此操作称为聚类。 聚类是基于用于分组的列创建分区。 SUMMARIZE 首先根据颜色对表进行聚类,然后通过创建将计算限制为迭代聚类的过滤上下文来计算每个聚类的表达式。 因为我们按 Sales[Color] 分组,SUMMARIZE 根据颜色将 Sales 表拆分为三个集群。

因为我们按颜色分组,所以每个集群都由一种颜色标识。 在我们的场景中,Sales[Color] 是集群标头。 簇头是 SUMMARIZE 的 groupby 部分中使用的一组列。 簇头可以包含多列,即使在第一种情况下我们只有一列。
集群准备就绪后,SUMMARIZE 计算三个集群的 SUM (Sales[Amount]) 值。 这是 SUMMARIZE 倾向于参与的许多恶作剧中的第一个:为了将计算限制在单个集群中,SUMMARIZE 不会创建仅包含集群标头的过滤器上下文。 相反,它使用集群中的所有列创建过滤上下文,过滤集群中存在的值。
对于蓝色集群,我们有三辆自行车,价格为 300.00 美元,四件衬衫,价格为 400.00 美元。 因此,为 Blue 集群计算的表达式如下所示:
CALCULATE (
SUM ( Sales[Amount] ),
FILTER (
ALL ( Sales ),
( Sales[Color], Sales[Product], Sales[Quantity], Sales[Amount] )
IN {
( "Blue", "Bike", 3, 300 ),
( "Blue", "Shirt", 4, 400 )
}
)
)
表达式过滤所有列,要求所有列的值都属于簇中的一行。 您可以通过运行以下查询来仔细检查此行为,作为测试:
SUMMARIZE (
Sales,
Sales[Color],
"Test", ISFILTERED ( Sales[Quantity] )
)
查询在 Test 中返回 TRUE。 这表明 Sales[Quantity] 正在被主动过滤,即使它没有出现在 groupby 列中的任何地方。 事实上,Sales[Quantity] 在由 SUMMARIZE 计算的表达式中被过滤,因为 Sales[Quantity] 是为按颜色切片而创建的集群的列之一。 虽然净效果看起来一样,但事实并非如此。 虽然每个簇确实只过滤一种颜色,但实际上簇过滤的不仅仅是颜色。
让我们看看为什么这是相关的。 在继续之前尝试猜测以下查询的结果:
SUMMARIZE (
Sales,
Sales[Color],
"Sales", SUM ( Sales[Amount] ),
"All Sales",
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( Sales[Color] )
)
)
如果我根据常识猜测,我会说 All Sales 返回所有产品的销售额。 相反,All Sales 的结果不是销售额的总计; 这是一个非常奇怪的数字,只有了解聚类才能理解。

如果您依赖直观的行为,您会假设 REMOVEFILTERS (Sales[Color]) 从 Sales[Color] 列中删除过滤器,从而使 Sales 的所有行都可见。 实际上,REMOVEFILTERS 会从 Sales[Color] 中删除筛选器,但不会从集群中的所有其他列中删除筛选器。 因此,对 Blue 集群的 All Sales 的评估如下:
CALCULATE (
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( Sales[Color] )
),
FILTER (
ALL ( Sales ),
( Sales[Color], Sales[Product], Sales[Quantity], Sales[Amount] )
IN {
( "Blue", "Bike", 3, 300 ),
( "Blue", "Shirt", 4, 400 )
}
)
)
内部 CALCULATE 删除 Sales[Color] 上的过滤器,但它不会修改 Sales[Product]、Sales[Quantity] 和 Sales[Amount] 上的所有剩余过滤器。 如果删除 Sales[Color] 上的过滤器并保留其他列上的过滤器,则组合 (Green, Bike, 3, 300) 是在过滤器上下文中变得可见的唯一附加行。

每个集群中存在的列取决于您用作 SUMMARIZE 起点的表。事实上,尽管我们通常在模型中对表进行 SUMMARIZE,但 SUMMARIZE 实际上可以对任何表表达式进行分组。 您对此有完全的控制权。 例如,我们可以稍微改变查询以获得变体。 我们不汇总销售额,而是汇总所有(销售额[颜色]、销售额[数量]):
SUMMARIZE (
ALL ( Sales[Color], Sales[Quantity] ),
Sales[Color],
"Sales", SUM ( Sales[Amount] ),
"All Sales",
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( Sales[Color] )
)
)
尽管看起来不寻常,但这个查询运行得很好。 它创建了包含两列的集群——Sales[Color] 和 Sales[Quantity])——然后它产生了这个结果。

让我们再次关注蓝色集群。 1300从哪里来? 为了理解它,我们首先构建集群,注意到集群中现在只有两列:Sales[Color] 和 Sales[Quantity]。 通过删除 Sales[Color] 上的过滤器,唯一剩下的过滤器是 Sales[Quantity] 上过滤两个值的过滤器:3 和 4。因此,结果是具有数量的所有列的 Sales[Amount] 的总和 三个或四个:
CALCULATE (
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( Sales[Color] )
),
FILTER (
ALL ( Sales[Color], Sales[Quantity] ),
( Sales[Color], Sales[Quantity] )
IN {
( "Blue", 3 ),
( "Blue", 4 )
}
)
)
查看后面的代码,重要的是 FILTER - 引入以限制集群 - 现在仅适用于 Sales[Color] 和 Sales[Quantity]。 如果错误地编写了筛选整个表的代码,则不会生成 SUMMARIZE 的结果。 相反,以下查询返回 1,000:
CALCULATE (
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( Sales[Color] )
),
FILTER (
ALL ( Sales ),
( Sales[Color], Sales[Quantity] )
IN {
( "Blue", 3 ),
( "Blue", 4 )
}
)
)
实际上,在最后一个表达式中,外部 CALCULATE 的 Sales 过滤器在表的所有列上重新引入了过滤器上下文,再次产生 1,000 而不是 1,300。 请记住,这段代码对于理解 SUMMARIZE 的作用很有用:我们需要正确地编写它以产生与 SUMMARIZE 相同的输出。
二,为什么SUMMARIZE使用聚类
此时,一个逻辑问题是:在SUMMARIZE 可以只使用簇头来过滤表的情况下,为什么 SUMMARIZE 会产生如此复杂的流程? 原因是 SUMMARIZE 比我们通常使用它的功能更强大。 SUMMARIZE 可以按源表中的任何列进行分组,甚至可以按计算添加的扩展列进行分组。
例如,看看这个查询:
SUMMARIZE (
ADDCOLUMNS (
Sales,
"@Large Sale", IF ( Sales[Quantity] > 2, "Large", "Small" )
),
[@Large Sale],
"Amt", SUM ( Sales[Amount] )
)
该查询有效,它按新引入的列对 Amt 计算值进行切片。

[@Large Sale] 列不属于该模型。 它是由查询中的 ADDCOLUMNS 计算的计算列。 作为计算列,它没有模型沿袭。 因此,无法根据[@Large Sale]筛选模型。 SUMMARIZE 不依赖于 [@Large Sale] 上的过滤器。 相反,它将 [@Large Sale] 视为集群标头。 [@Large Sale] 的每个值都与同一集群中行的 Sales 的所有其他列中的值集相关联。 SUMMARIZE 在集群中为 [@Large Sale] 生成给定值的所有列上使用过滤器来计算 Amt 的值。 换句话说,为了按 [@Large Sale] 分组,SUMMARIZE 生成一个筛选器,筛选 Sales 中的所有列。 例如,Small 的过滤器是使用属于标头为 Small 的集群的 Sales 的所有行和列的值创建的。
我们可以通过创建一个仅包含 [@Large Sale] 列的表来仔细检查此行为。 我们通过使用 SELECTCOLUMNS 来做到这一点:
SUMMARIZE (
SELECTCOLUMNS (
ADDCOLUMNS (
Sales,
"@Large Sale", IF ( Sales[Quantity] > 2, "Large", "Small" )
),
"@Large Sale", [@Large Sale]
),
[@Large Sale],
"Amt", SUM ( Sales[Amount] )
)
在此查询中,簇仅包含一个没有任何沿袭的列。 因此,SUMMARIZE 生成的过滤器上下文对 Sales 无效,而 Sales 又会在每一行上产生相同的总计结果。

在大多数情况下,如果您的计算遵循规则,SUMMARIZE 使您有机会根据并非源自模型的列执行分组。
虽然非常强大,但很少使用这种行为。 原因是,正如我们正在学习的那样,实现按扩展列分组的机制相当复杂。 它是如此复杂,我们通常避免使用它并且我们依赖于不同的分组技术。 例如,GROUPBY 函数通过使用 CURRENTGROUP 函数使聚类更加明显。 尽管功能不那么强大,但它更受欢迎,因为它更直观。
三,集群和扩展表
既然介绍了集群的概念,我们就可以更进一步,讨论扩表对集群的影响。 SUMMARIZE 可以将您用作第一个参数的扩展表的任何列用作簇头。 到目前为止,我们经常给出一个简化的描述,即 SUMMARIZE 可以按任何相关列进行分组。 正确的描述是SUMMARIZE可以按展开表的任意列进行聚类。 因为表扩展从多边到单边的常规关系,它自然地遵循 SUMMARIZE 可以按关联表的任何列分组,这些表与基表具有常规关系的多对一连接。
因此,SUMMARIZE 不适用于有限关系,包括多对多交叉过滤器关系和跨岛关系。
此外,还有另一个重要结果:集群包含扩展表的所有列,而不仅仅是基表中的列。 建议明智地选择基表,以最大限度地提高获得所需结果的机会。 让我们用不同的模型详细说明这一点。
让我们处理一个稍微不同的模型:我们添加一个 Product 表并将 Sales 中的产品列替换为 Product Code 列。

有了我们目前获得的知识,现在很容易理解为什么以下查询会产生意外结果:
SUMMARIZE (
Sales,
'Product'[Color],
"Sales", SUM ( Sales[Amount] ),
"All Sales",
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( 'Product'[Color] )
)
)
簇标题包含 Product[Color],但簇过滤器包含展开表 Sales 中的所有列。 这包括 Product Code、Year、Quantity 和 Amount from Sales,以及 Product 的所有列。 因此,尽管通过 REMOVEFILTERS 从 Product[Color] 中删除了筛选器,但 Sales 和 All Sales 计算都会产生相同的结果。

如果您展开 REMOVEFILTERS 以从 Product 表中删除任何过滤器,您仍然会获得相同的结果:
SUMMARIZE (
Sales,
'Product'[Color],
"Sales", SUM ( Sales[Amount] ),
"All Sales",
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( 'Product' )
)
)
原因是集群包含 Sales 中的所有列,包括 Sales[Product Code]。 无论您从簇标题中删除了多少筛选器,真正的筛选器都来自 Sales 中的其他列。 此外,我们使用的模型只有两个表。 当模型包含数十个表时(大多数现实世界的数据模型都是这种情况),Sales 表的扩展版本可能包含大量列。
这不仅会影响语义:越来越难弄清楚过滤器的应用位置。 它还对性能有很大的影响。 实际上,仅通过使用 SUMMARIZE,您就可以处理大量列上的巨大过滤器。 这通常会导致非常大的具体化,从而导致性能不佳。
DAX 新手的一个常见问题是在 Sales 表或 Product 表上使用 SUMMARIZE 有什么区别。 有多种差异。
首先,集群的大小非常不同。 展开的 Sales 表比展开的 Product 表大得多,后者大多只展开到自身。
此外,通过对 Sales 使用 SUMMARIZE,集群仅包含 Sales 中存在的值的现有组合。 从未销售过的产品不会出现,因为在 Sales 中没有对应的交易记录。 结果,它被从结果中过滤掉了。
第一点很重要。 通过使用尽可能小的表来创建集群,您不仅可以获得更好的性能 – 您还可以获得更容易理解的结果,因为集群的宽度较小。
尽管如此,对集群使用更窄的集合并不能自动解决 SUMMARIZE 的所有问题。 作为练习,您自己找出下一个查询产生其结果的原因。 一、查询:
SUMMARIZE (
Product,
'Product'[Color],
"Sales", SUM ( Sales[Amount] ),
"All Colors",
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( 'Product'[Color] )
),
"All Sales",
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( 'Product' )
)
)

All Colors 从 Product[Color] 中删除筛选器,但不会从 Product 中的所有其他列中删除筛选器。 因此,它将筛选器保留在 Product[Product Code] 列中,该列唯一标识产品。 因此,红色集群仍然只包含红色产品,即使我们已经移除了 Product[Color] 上的过滤器。
All Sales 从 Product 中删除所有过滤器:这样,我们从集群中的列中删除所有过滤器,从而获得预期的结果。
三,理解SUMMARIZE
一步一步,我们正在弄清楚 SUMMARIZE 是如何工作的。 到目前为止,您应该熟悉集群的概念。 一旦理解了聚类的概念,您可能就能更好地理解为什么我们认为 SUMMARIZE 是一个危险的函数。 这并不是说您不能使用 SUMMARIZE,或者它不起作用。 它有效,但它所做的并不是你认为它应该做的。
降低 SUMMARIZE 复杂性的最简单方法是减少簇中的列数,使其仅包含簇标题列。 您可以通过多种方式实现此结果。 一种方法——有点违反直觉——是嵌套多个 SUMMARIZE 函数。 查看以下查询,其中外部 SUMMARIZE 使用内部 SUMMARIZE 作为基表:
SUMMARIZE (
SUMMARIZE ( Sales, 'Product'[Color] ),
'Product'[Color],
"Sales", SUM ( Sales[Amount] ),
"All Colors",
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( 'Product'[Color] )
),
"All Sales",
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( 'Product' )
)
)

原因很简单:内部 SUMMARIZE 生成的表仅包含 Product[Color] 列。 因此,集群仅包含 Product[Color] 列,当我们从 Product[Color] 中删除过滤器时,我们实际上是在修改直观的过滤器上下文。
最后的考虑导致我们建议作为最佳实践的代码:不要使用 SUMMARIZE 生成新列,仅使用它来执行分组。 事实上,在我们的最后一个查询中,我们可以轻松地将外部 SUMMARIZE 替换为更直观的 ADDCOLUMNS,其语义更简单。 我们只需要在第一个扩展列中添加 CALCULATE,因为 ADDCOLUMNS 不会生成筛选上下文; 它只依赖于行上下文:
ADDCOLUMNS (
SUMMARIZE ( Sales, 'Product'[Color] ),
"Sales", CALCULATE ( SUM ( Sales[Amount] ) ),
"All Colors",
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( 'Product'[Color] )
),
"All Sales",
CALCULATE (
SUM ( Sales[Amount] ),
REMOVEFILTERS ( 'Product' )
)
)
四,行上下文和过滤器上下文
SUMMARIZE 的另一个方面是它是 DAX 中唯一同时创建行上下文和筛选器上下文的函数。 在评估新列期间,SUMMARIZE 对集群进行迭代并生成:
包含簇头的行上下文;
一个过滤器上下文,包含集群中的所有列,包括集群标题。
这种独特的行为给本来就很复杂的函数增加了一些混乱。 实际上,以下查询会生成一个颜色列表,在所有列中复制相同的颜色名称:
SUMMARIZE (
Sales,
'Product'[Color],
"Color 1", Product[Color],
"Color 2", SELECTEDVALUE ( Product[Color] ),
"Color 3", VALUES ( Product[Color] )
)

颜色 1 基于行上下文,其中仅包含簇标题。 颜色 2 和颜色 3 依赖于过滤器上下文。
就其本身而言,这种行为并不坏。 它只会造成一些混乱,因为当您在 SUMMARIZE 中使用 CALCULATE 时,您不仅会更改过滤器上下文,还会对簇标题中的所有列调用上下文转换。
SUMMARIZE 需要遍历集群,让开发人员在由该 SUMMARIZE 计算的列的代码中使用 ALLSELECTED。 请记住,ALLSELECTED 依赖于影子过滤器上下文的存在才能正常工作。 如果您不熟悉 ALLSELECTED 和影子过滤器上下文,您可以在此处找到更多信息:ALLSELECTED 权威指南 – SQLBI。
正如我们所说,需要 SUMMARIZE 的双重性质,既作为簇头的迭代器,又作为簇内容的过滤器上下文的生成器,以获得您对 ALLSELECTED 的期望。 实际上,通过遍历簇头,SUMMARIZE 在簇头上生成影子过滤器上下文。 这样,在 SUMMARIZE 中调用 ALLSELECTED 可以恢复簇头上的过滤器上下文,从而获得您想要的结果。
使用 ADDCOLUMNS 而不是 SUMMARIZE 不会更改此行为。 ADDCOLUMNS 在 SUMMARIZE 返回的表上进行迭代,它还会生成影子过滤器上下文。 使用 ADDCOLUMNS 而不是 SUMMARIZE 添加列的优点是我们更习惯于迭代器创建的影子过滤器上下文——当我们考虑 SUMMARIZE 时,我们不会想到迭代器。 事实上,SUMMARIZE 是一个迭代器:它迭代集群。
五,ADDCOLUMNS 和 SUMMARIZE的组合
先说结论,建议不要使用SUMMARIZE函数来增加扩展列,而使用ADDCOLUMNS 和 SUMMARIZE的组合。不推荐使用的原因是:新增列的计算同时处于行上下文(row context)和过滤上下文(filter context)中,这会使得结果很复杂。如果对新增列进行计算,SUMMARIZE函数不保持计算列的数据沿袭。
虽然SUMMARIZE 函数被标记为弃用,但是有时使用起来真的非常方便。
ADDCOLUMNS(
SUMMARIZE( <table>, <group by column> ),
<column_name>, CALCULATE( <expression> )
)
注意,当<expression>包含聚合函数时,CALCULATE函数是必须的。这是因为ADDCOLUMNS函数根据SUMMARIZE的结果产生一个行上下文(row context),这个行上下文不会自动转换为过滤器上下文(filter context),而CALCULATE(<expression>) 会把行上下文转换为等价的过滤器上下文。
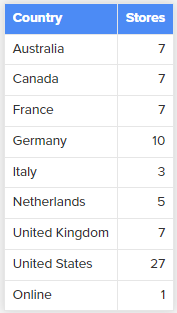
举个例子,使用以下的代码,来统计每个Country的函数,由于行上下文无法自动转换为filter context,迭代函数返回的是总行数:
ADDCOLUMNS (
SUMMARIZE (
Store,
Store[Country]
),
"Stores", COUNTROWS ( Store )
)

当添加CALCULATE函数后,CALCULATE函数把行上下文自动转换为filter context,统计的是每一个Coutnry对应的行数:
SUMMARIZE (
Store,
Store[Country],
"Stores", CALCULATE(COUNTROWS( Store ))
)
参考文档:
All the secrets of SUMMARIZE
Best practices using SUMMARIZE and ADDCOLUMNS

![[附源码]JAVA毕业设计文件发布系统(系统+LW)](https://img-blog.csdnimg.cn/3d20e6b5c8f6436ca0043d0b60df7f4c.png)