一 Flink+Kafka做实时数仓的弊端
我们以前(包括现在)还有用Flink+Kafka做实时数仓,以及日志传输。Kafka本身的存储成本很高,并且数据保留时间有时效性,一旦消费积压,数据达到过期事件后,就会导致数据丢失并且没有消费到。

如果单纯的增加数据保留生命周期,会增大很大的费用。下图是Netflix公司在2021年Flink技术大会上分享的数据,如果都是保存30天的数据,使用Kafka会占用180PB的存储空间,而使用S3仅需要15PB的空间,前者是后者的12倍;在费用上Kafka是$183M,而S3仅仅是$3.8M,前者是后者的48倍。可见增长Kafka的存储时间会大幅增加费用。

1.1 Flink+Kafka+Hive方案优化
那么是否可以通过把离线的数据放到廉价的存储设备(S3或者HDFS)上。比如kafka保留最近3-7天的数据,历史数据存储在Hive上面,在需要统计全部数据时,将二者结合起来。这样是不是就能完美解决问题了呢?

选用Flink+Hive的准实时架构虽然支持了实时读写,但是这种架构带来的问题是随着表和分区增加,将会面临以下问题:
1.1.1 元数据过多
将Hive分区改为小时/分钟,虽然提高了数据的准实时性,但是metastore的压力也是显而易见的,元数据过多导致生成查询计划变慢,而且还会影响线上其他业务。
随着元数据增加,存储Hive元数据的数据库压力也会增加,一段时间后必须对该数据库进行扩容。
1.1.2 不支持ACID
不支持数据的Upsert场景,也不支持Row-level delete,数据的修正成本很高。同时也不能做增量数据读取,无法实现存储层面的流批统一。
1.1.3 Table Evolution
写入型 Schema,对 Schema 变更支持不好;Partition Spec 变更支持不友好。
二 Flink+Kafka+Iceberg可以完美解决上述痛点
那么Iceberg有什么本事呢,竟能解决Kafka+Hive的这些痛点,不会是吹牛吧。。。
这是有大前提的,可以将对实时业务要求不高的数据写入Iceberg(比如说能接受1-10分钟的数据延迟)。因为Iceberg0.11及以上版本也支持SQL准时实时提取,而且还能保存历史数据。这样既减轻了Kafka的压力,还能确保在数据不丢失的前提下也能实时读取数据。
2.1 Iceberg有哪些优点呢
说来说去,我们还是没看到Iceberg的优点,具体是什么呢?看你对知识渴望的小眼神,跟我有一拼。
2.1.1 通用化的表格设计
Apache Iceberg是一种用于分析大型数据集的开放表格格式,支持使用类似于SQL表的高性能格式进行分析处理。作为一个数据湖的数据存储中间层,完美的解耦计算引擎和存储设施,对外提供开放式的表格形式。
在计算引擎方面,Iceberg优秀的内核抽象能力使之不绑定特定的计算引擎,目前Iceberg支持Spark、Flink、Presto以及Hive等计算引擎,十分灵活。
数据依然存储在廉价的HDFS系统上面,Iceberg设计的初衷就是替换掉Hive,经过netflix、apple、linkedin、adobe这些公司的场景磨练,无缝替换hive上云应该是iceberg当前release的场景里面最核心的场景。
2.1.2 完善的Table语义 2.1.2.1 灵活的Partition策略
在查询性能和存储设计方面,Iceberg支持隐藏分区和分区进化,方便业务进行数据分区策略更新。
2.1.2.2 支持ACID语义
Iceberg提供ACID事务能力,上游数据写入即可见,不影响当前数据处理任务,使边读边写成为可能。ACID事务机制保证下游只能看到已Commit的SnapShot所包含的数据,而不用担心读到部分或者未Commit的数据。业务因此可以省去大量用于保证ACID事务和失败恢复的逻辑。
2.2 Iceberg术语
Iceberg内部的文件组织形式和读写流程是它性能优异的根本原因,以下是Iceberg关于底层数据结构的一些术语。
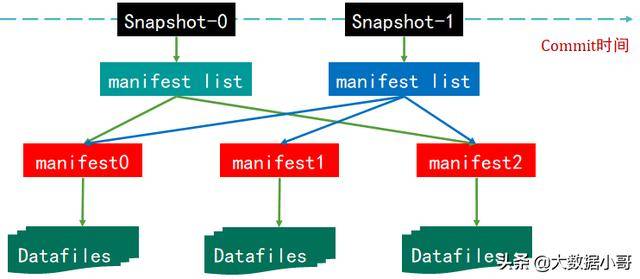
下图是一张Iceberg表在某个时刻的状态:

2.2.1 数据文件(Data Files)
Iceberg的数据文件通常存放在data目录下。一共有三种存储格式(Avro、Orc和Parquet),主要是看您选择哪种存储格式,后缀分别对应.avro、.orc或者.parquet。在一个目录,通常会产生多个数据文件。
2.2.2 清单文件(Manifest File)
所谓清单文件其实就是元数据文件,清单文件是以avro格式进行存储的,以avro后缀结尾,每次更新操作都会产生多个清单文件。清单文件里面列出了组成某个快照的数据文件列表。每行数据包括数据文件路径、状态、大小、分区信息、列级别的统计信息(例如空值数量、最大最小值等),以及文件里面的行数量等。
2.2.3 清单列表(Manifest List)
清单列表其实也是元数据文件,里面存储的是清单文件列表,每个清单文件占用一行数据。清单列表文件以snap开头,以avro后缀结尾,每次更新都产生一个清单列表文件。每行中存储了清单文件的路径、清单文件里面存储数据文件的分区范围、增加了几个数据文件、删除了几个数据文件等信息。
2.2.4 快照(SnapShot)
快照代表一张Iceberg表在某一时刻的状态。数据文件(Data Files)存储在不同的Manifest Files里面,Manifest Files存储在一个Manifest List文件里面,而一个Manifest List文件代表一个快照。
2.3 为什么Iceberg只能做准实时入湖?

如下图所示,虚线框(snapshot-1)表示正在进行写操作,但是还没有发生commit操作,这时候 snapshot-1 是不可读的,用户只能读取已经 commit 之后的 snapshot。同理, snapshot-2,snapshot-3表示已经可读。

可以支持并发读,例如可以同时读取S1、S2、S3的快照数据,同时,可以回溯到snapshot-2或者snapshot-3。在snapshot-4 commit完成之后,这时候snapshot-4已经变成实线,就可以读取数据了。
例如,现在current Snapshot 的指针移到S3,用户对一张表的读操作,都是读 current Snapshot 指针所指向的 Snapshot,但不会影响前面的 snapshot 的读操作。
当一切准备完毕之后,会以原子操作的方式Commit这个Metadata文件,这样一次Iceberg的数据写入就完成了。随着每次的写入,Iceberg就生成了下图这样的一个文件组织模式。

2.3.2 增量读取数据
Iceberg的每个snapshot都包含前一个snapshot的所有数据,每次都相当于全量读取数据,对于整个链路来说,读取数据的代价是非常高的。
如果我们只想读取当前时刻的增量数据,就可以根据Iceberg中Snapshot的回溯机制来实现,仅读取Snapshot1到Snapshot2的增量数据,也就是下图中的紫色数据部分。
同理,S3也可以只读取红色部分的增量数据,也可以读取S1-S3的增量数据。
Iceberg支持读写分离,也就是说可以支持并发读和增量读。

三 从Hive表迁移到Iceberg表的收益 3.1 Hive表能平滑迁移到Iceberg吗
目前Iceberg提供的Spark迁移工具,是完全可以不用挪动原来Hive表的ORC、Parquet文件,可以直接生成Iceberg的metadata,然后就可以拿到一个Iceberg表格。原来操作Hive表的Spark、Presto、Hive作业,切换到Iceberg表时,完全兼容,原来的SQL代码该怎么写还怎么写,只需要把表名改成Iceberg表名即可。Iceberg是不是有点来势汹汹,就是为了替换Hive呢?
3.2 从Hive表迁移到Iceberg有哪些收益呢? 3.2.1 准实时数据入湖(仓)
之前写入Hive数据表时,周期最短也是30分钟也如一次,现在写入Iceberg可以缩短到5分钟以内。本质上在于Iceberg把metadata存储在HDFS上,脱离了去中心化的hive-metastore依赖。
此外Iceberg提供了data文件和metadata文件的合并功能,数据可以按照5分钟的频次写入数据湖,上一个小时的data和metadata文件就可以合并了。这样就避免了过多小文件的影响,同学们是不是就不用担心数据分析受小文件过多的影响了。
最主要的是Iceberg提供了ACID功能。我们通常对Hive表都是每次写入一个新的Partition,在Query(查询、分析)的时候指定老的Partition范围。这套机制在天级别的离线系统里面,基本上没啥问题。一旦做到5分钟级别的数据实效性,我们怎么知道现在应该指定什么分区范围呢?有了iceberg的ACID隔离机制,就不存在这个问题,最近5分钟的数据通过txn commit了,查询就能看见,否则就看不见,不存在看一半数据的问题。

3.2.2 数据变更
Hive数据表本身就是为分析静态数据而设计的,而实际上数据变更是业务发展的常见需求。我们常见的场景有:
而上面这些问题,在Iceberg中都已经解决的非常好了。
四 Flink+Kafka+Iceberg数据湖的构建
我们已经知道Iceberg的性能要优于Hive,同时也只有Kafka才能真正的做到完全实时,但是Kafka的存储非常昂贵,通常的做法是把不常用的历史数据写入到Iceberg中,需要做全量数据分析时结合Kafka和Iceberg一起使用。


4.1 实时CDC数据读写
对Flink来说,一般常用的有两种场景,第一种场景是上游的Binlog能够很快速的写到Iceberg中,然后供不同的分析引擎做分析使用; 第二种场景是使用Flink做一些聚合操作,输出的流是upsert类型的数据流,也需要能够实时的写到数据湖或者是下游系统中去做分析。
4.1.2 Flink CDC2.0
Flink CDC Connectors内部封装了Debezium特性,可以使用Flink CDC的方式替代canal+kafka的方式,直接通过sql的方式来实现对mysql数据的同步。

Flink在1.11版本开始引入Flink CDC功能,并且同时支持Table和SQL两种形式,Flink SQL CDC基于Debezium实现的,能够对CDC数据进行实时解析同步。当启动MySQL CDC源时,它将获取一个全局读取锁(FLUSH TABLES WITH READ LOCK),该锁将阻止其他数据库的写入,然后读取当前binlog位置以及数据库和表的schema,之后将释放全局读取锁。然后它扫描数据库表并从先前记录的位置读取binlog,Flink将定期执行checkpoints以记录binlog位置。如果发生故障,作业将重新启动并从checkpoint完成的binlog位置恢复,因此它保证了仅一次的语义。

Dynamic Table是Flink内部定义的表,它和流式可以相互转化的。可以简单的理解为:每张MySQL表对应一个Binlog日志,Binlog日志随着MySQL表的变化而变化,Dynamic Table相当于Binlog日志流在某一时刻的物化结果。在Flink中,数据从一个算子流向另外一个算子的时候,都是以Changelog Stream的格式发送到下游,在下游我们可以将其翻译成一张表或者一条流进行操作。
4.1.2 准实时操作CDC数据
Iceberg 是统一的数据湖存储,支持多样化的计算模型,也支持各种引擎(包括 Spark、Presto、hive)来进行分析;产生的 file 都是纯列存的,对于后面的分析是非常快的;Iceberg 作为数据湖基于 snapshot 的设计,支持增量读取;Iceberg 架构足够简洁,没有在线服务节点,纯 table format 的,这给了上游平台方足够的能力来定制自己的逻辑和服务化。
将数据连同 CDC flag 直接 append 到 Iceberg 当中,在 merge 的时候,把这些增量的数据按照一定的组织格式、一定高效的计算方式与全量的上一次数据进行一次 merge。这样的好处是支持近实时的导入和实时数据读取;这套计算方案的 Flink SQL 原生支持 CDC 的摄入,不需要额外的业务字段设计。

4.2 准实时数据仓库分析系统
我们知道Iceberg支持读写分离,又支持并发读、增量读、合并小文件,而且还能做到秒级/分钟级的数据延迟。我们基于Iceberg这些优势,采用Flink+Iceberg的方式构建了流批一体化的实时数据仓库。

在数据仓库处理层,可以用 presto 进行一些简单的查询,因为 Iceberg 支持 Streaming read,所以在系统的中间层也可以直接接入 Flink,直接在中间层用 Flink 做一些批处理或者流式计算的任务,把中间结果做进一步计算后输出到下游。
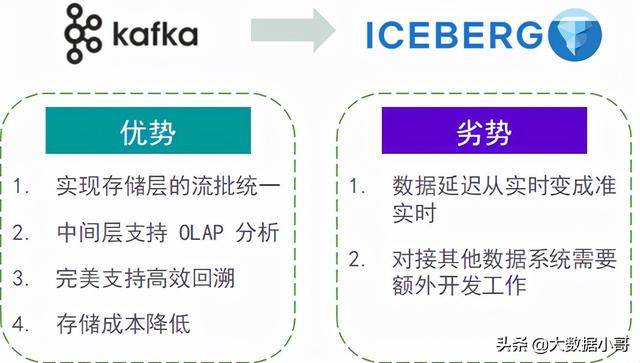
五 采用Iceberg替代Kafka实时数仓的优劣势
六 总结
随着数据量的持续增大,和业务对时效性的严苛要求,基于 Apache Flink 和Apache Iceberg 构建准实时数仓愈发重要和迫切,作为实时数仓的两大核心组件,可以缩短数据导入、方便数据行级变更、支持数据流式读取等。
作为大数据工程师,我们要灵活选用大数据组件,不要拘泥一种,让这些组件物尽其用才是根本,没有谁优谁劣,我们只看重结果,不是吗?哈哈哈哈,最后一句有没有领导的语气,欢迎大家转发评论。
![[附源码]JAVA毕业设计文件发布系统(系统+LW)](https://img-blog.csdnimg.cn/3d20e6b5c8f6436ca0043d0b60df7f4c.png)