负责任地评估机器学习模型需要做的不仅仅是计算损失指标。在将模型投入实际应用之前,审核训练数据并评估偏见(Bias)对预测至关重要。本文内容着眼于解读训练数据中可能存在的不同类型的人类偏见,同时提供了识别它们并评估其影响的策略。
目录
1.偏见的类型(Types of Bias)
1.1 报告偏见
1.2 自动化偏见
1.3 选择偏见
1.4 群体归因偏见
1.5 隐性偏见
2.识别偏见(Identifying Bias)
2.1 缺少特征值
2.2 意外的特征值
2.3 数据偏见
3. 评估偏见(Evaluating for Bias)
3.1 额外的公平资源
4.参考文献
1.偏见的类型(Types of Bias)
机器学习模型本质上并不客观。工程师通过向模型提供训练示例数据集来训练模型,而人类参与这些数据的提供和管理可能会使模型的预测容易出现偏差。
构建模型时,了解数据中可能出现的常见人类偏见非常重要,这样我们就可以采取主动措施来减轻其影响。
警告:以下偏差清单仅提供了机器学习数据集中经常发现的一小部分偏差;此列表并非详尽无遗。维基百科的 认知偏见目录 列举了 100 多种可能影响我们判断的不同类型的人类偏见。在审核数据时,我们应该留意可能会影响模型预测的任何和所有潜在偏差来源。
1.1 报告偏见
当数据集中捕获的事件、属性和/或结果的频率不能准确反映其真实世界的频率时,就会出现报告偏见。之所以会出现这种偏见,是因为人们倾向于专注于记录不寻常或特别令人难忘的情况,认为普通情况可以“不言而喻”。
示例:训练情感分析模型,根据用户向热门网站提交的语料库来预测书评是正面还是负面。训练数据集中的大多数评论反映了极端的观点(喜欢或讨厌一本书的评论者),因为如果人们对一本书没有强烈的反应,他们就不太可能提交评论。因此,该模型不太能够正确预测使用更微妙的语言来描述书籍的评论的情绪。
1.2 自动化偏见
自动化偏见——是指倾向于选择自动化系统生成的结果而不是非自动化系统生成的结果,无论每个系统的错误率如何。
示例:为链轮制造商工作的软件工程师渴望部署他们训练的新的 “突破性” 模型来识别牙齿缺陷,直到工厂主管指出该模型的精确度和召回率均比人工检查员低 15%。
1.3 选择偏见
如果数据集示例的选择方式不反映其真实世界的分布,就会出现选择偏见。选择偏见可以有多种不同的形式:
- 覆盖偏见:数据不是以代表性的方式选择的。
示例:训练一个模型,根据对购买该产品的消费者样本进行的电话调查来预测新产品的未来销售情况。由于没有调查那些购买竞争产品的消费者,因此,这类人群(可以认为是 “负向”数据)没有出现在训练数据中。
- 无响应偏见(或参与偏见):由于数据收集过程中的参与差距,数据最终不具代表性。
示例:训练一个模型,根据对购买该产品的消费者样本和购买竞争产品的消费者样本进行的电话调查来预测新产品的未来销售情况。购买竞争产品的消费者拒绝完成调查的可能性高出 80%,而且他们的数据在样本中代表性不足。
- 抽样偏见:数据收集过程中未使用适当的随机化。
示例:训练一个模型,根据对购买该产品的消费者样本和购买竞争产品的消费者样本进行的电话调查来预测新产品的未来销售情况。调查人员没有随机定位消费者,而是选择了前 200 名回复电子邮件的消费者,他们可能比普通购买者对产品更热情。
1.4 群体归因偏见
群体归因偏见是一种将个人的真实情况概括到他们所属的整个群体的倾向。这种偏见的两个主要表现是:
- 群体内偏见:对你所属群体的成员或你也有共同特征的偏好。
示例:两位为软件开发人员训练简历筛选模型的工程师倾向于相信,与他们一起就读于同一所计算机科学学院的申请人更适合该职位。
- 外群体同质性偏见:一种对你不属于的群体中的个体成员形成刻板印象的倾向,或者认为他们的特征更加统一。
示例:两名工程师为软件开发人员训练简历筛选模型,他们倾向于认为所有未上过计算机科学学院的申请人不具备足够的专业知识来胜任该职位。
1.5 隐性偏见
当基于自己的心理模型和个人经历做出假设时,隐性偏见就会出现,而这些假设不一定适用于更普遍的情况。
示例:训练手势识别模型的工程师使用 摇头 作为特征来指示一个人正在传达 “不” 这个词。然而,在世界某些地区,摇头实际上表示“是”。
隐性偏差的一种常见形式是确认偏见,模型构建者无意识地以肯定预先存在的信念和假设的方式处理数据。在某些情况下,模型构建者实际上可能会继续训练模型,直到产生与其原始假设相符的结果;这就是所谓的 实验者偏见。
示例:一位工程师正在构建一个模型,根据各种特征(身高、体重、品种、环境)来预测狗的攻击性。这位工程师小时候曾与一只过度活跃的玩具贵宾犬有过一次不愉快的遭遇,从那时起,他就将该品种与攻击性联系在一起。当经过训练的模型预测大多数玩具贵宾犬相对温顺时,工程师又对模型进行了多次重新训练,直到得出的结果显示较小的贵宾犬更加暴力。
2.识别偏见(Identifying Bias)
当探我们索数据以确定如何在模型中最好地表示它时,还要注意:公平问题并主动审核潜在的偏见来源也很重要。偏见可能潜伏在哪里?以下是数据集中需要注意的三个危险信号。
2.1 缺少特征值
如果你的数据集的一个或多个特征在大量示例中缺少值,则可能表明你的数据集的某些关键特征代表性不足。
举个例子,下表显示了 加州住房数据 集中的部分要素的关键统计数据摘要,这些数据存储在 pandas 中 DataFrame 并通过生成 DataFrame.describe。从数据中可以发现——所有特征的总数都是 17000,说明所有示例都没有缺失特征。
| 经度 | 纬度 | 总房间数 | 人口 | 家庭 | 收入中位数 | 房屋价值中位数 | |
|---|---|---|---|---|---|---|---|
| 总数(count) | 17000.0 | 17000.0 | 17000.0 | 17000.0 | 17000.0 | 17000.0 | 17000.0 |
| 平均值(mean) | -119.6 | 35.6 | 2643.7 | 1429.6 | 501.2 | 3.9 | 207.3 |
| 标准(std) | 2.0 | 2.1 | 2179.9 | 1147.9 | 384.5 | 1.9 | 116.0 |
| 最小值(min) | -124.3 | 32.5 | 2.0 | 3.0 | 1.0 | 0.5 | 15.0 |
| 25% | -121.8 | 33.9 | 1462.0 | 790.0 | 282.0 | 2.6 | 119.4 |
| 50% | -118.5 | 34.2 | 2127.0 | 1167.0 | 409.0 | 3.5 | 180.4 |
| 75% | -118.0 | 37.7 | 3151.2 | 1721.0 | 605.2 | 4.8 | 265.0 |
| 最大值(max) | -114.3 | 42.0 | 37937.0 | 35682.0 | 6082.0 | 15.0 | 500.0 |
假设三个特征(population-人口、households-房间数量 和 median_income-收入中位数)的计数仅为 3000——换句话说,每个特征有 14,000 个缺失值:
| 经度 | 纬度 | 总房间数 | 人口 | 家庭 | 收入中位数 | 房屋价值中位数 | |
|---|---|---|---|---|---|---|---|
| 总数(count) | 17000.0 | 17000.0 | 17000.0 | 3000.0 | 3000.0 | 3000.0 | 17000.0 |
| 平均值(mean) | -119.6 | 35.6 | 2643.7 | 1429.6 | 501.2 | 3.9 | 207.3 |
| 标准(std) | 2.0 | 2.1 | 2179.9 | 1147.9 | 384.5 | 1.9 | 116.0 |
| 最小值(min) | -124.3 | 32.5 | 2.0 | 3.0 | 1.0 | 0.5 | 15.0 |
| 25% | -121.8 | 33.9 | 1462.0 | 790.0 | 282.0 | 2.6 | 119.4 |
| 50% | -118.5 | 34.2 | 2127.0 | 1167.0 | 409.0 | 3.5 | 180.4 |
| 75% | -118.0 | 37.7 | 3151.2 | 1721.0 | 605.2 | 4.8 | 265.0 |
| 最大值(max) | -114.3 | 42.0 | 37937.0 | 35682.0 | 6082.0 | 15.0 | 500.0 |
由于示例数据缺失了 14,000 个特征值,在训练模型时,将难以准确地将【家庭收入中位数】与【房价中位数】关联起来。鉴于此,在利用这些数据训练模型之前,应谨慎检查这些缺失值的原因,以确保不存在导致收入和人口数据缺失的潜在偏差。
2.2 意外的特征值
在检查数据时,我们还应该寻找包含特别不典型或不寻常的特征值的示例。这些意外的特征值可能表明数据收集过程中发生的问题或可能引入偏见的其他不准确之处。例如,看一下以下来自加州住房数据集的摘录示例:
| 经度 | 纬度 | 总房间数 | 人口 | 家庭 | 收入中位数 | 房屋价值中位数 | |
|---|---|---|---|---|---|---|---|
| 1 | -121.7 | 38.0 | 7105.0 | 3523.0 | 1088.0 | 5.0 | 0.2 |
| 2 | -122.4 | 37.8 | 2479.0 | 1816.0 | 496.0 | 3.1 | 0.3 |
| 3 | -122.0 | 37.0 | 2813.0 | 1337.0 | 477.0 | 3.7 | 0.3 |
| 4 | -103.5 | 43.8 | 2212.0 | 803.0 | 144.0 | 5.3 | 0.2 |
| 5 | -117.1 | 32.8 | 2963.0 | 1162.0 | 556.0 | 3.6 | 0.2 |
| 6 | -118.0 | 33.7 | 3396.0 | 1542.0 | 472.0 | 7.4 | 0.4 |
你能指出任何意外的特征值吗?
示例 4 中的经度和纬度坐标(分别为 -103.5 和 43.8)不属于美国加利福尼亚州。事实上,它们是 南达科他州拉什莫尔山国家纪念碑的大致坐标。这是我们插入到数据集中的一个虚假示例。
2.3 数据偏见
数据中的任何形式的偏见(例如:某些群体或特征相对于现实世界的患病率可能代表性不足或过高)都可能会给我们的模型带来偏见。
在【机器学习1~21】中的编程练习中,我们将加州住房数据集分割为【训练集】和【验证集】之前都会对其进行随机化,其目标就是减少数据偏见。图 1 可视化了从完整数据集中提取的数据子集,专门代表加利福尼亚州西北部地区。
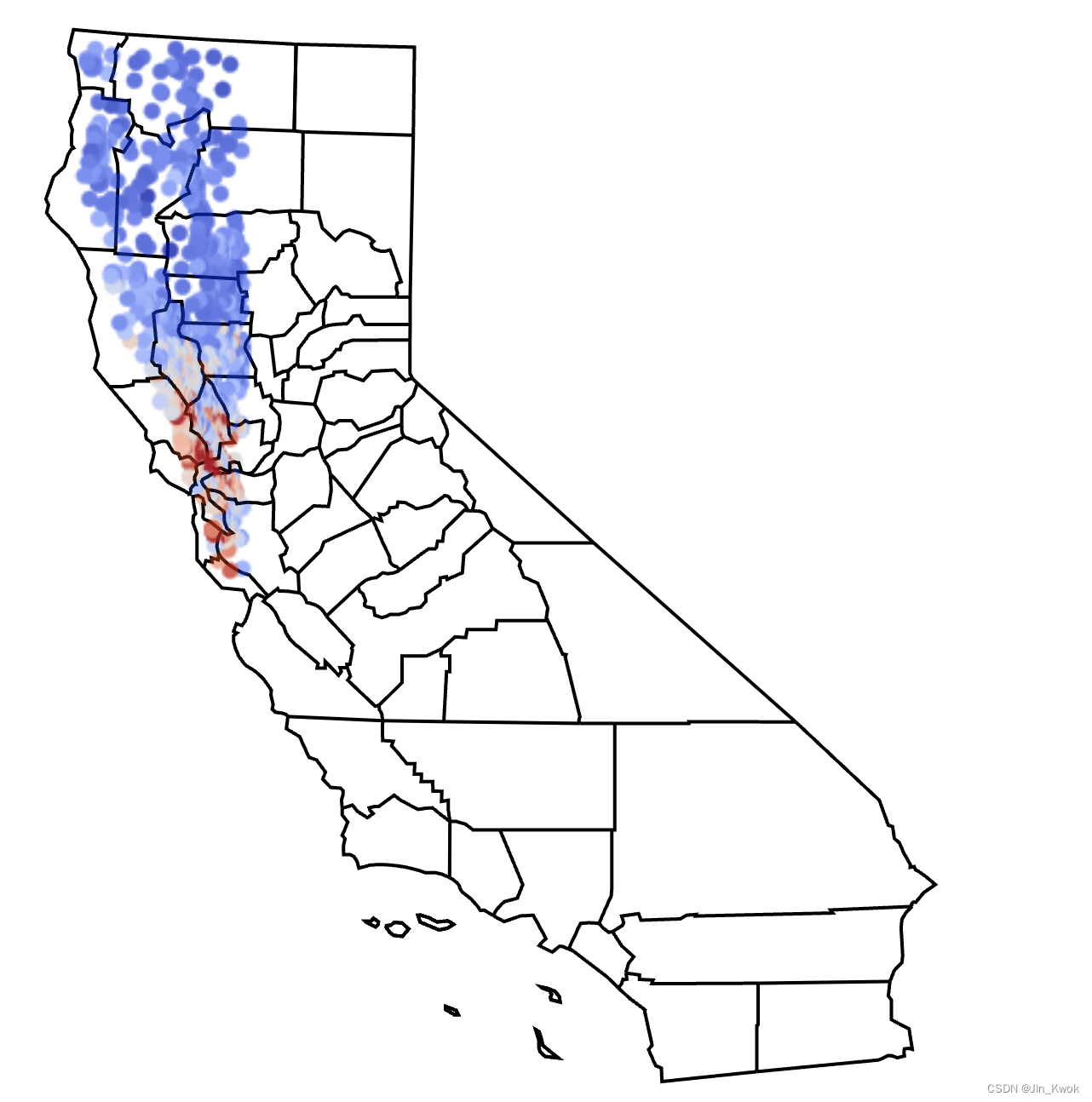
图 1. 加利福尼亚州地图与加利福尼亚州住房数据集的数据重叠。每个点代表一个住宅区,颜色从蓝色到红色分别对应房价中值从低到高的变化。
如果使用上述不具有代表性的样本来训练模型来预测加州全州的房价,那么缺乏加州南部地区的住房数据将会出现问题。模型中编码的地理偏见可能会对无人代表的社区的购房者产生不利影响。
3. 评估偏见(Evaluating for Bias)
评估模型时,根据整个测试集或验证集计算的指标并不总是能够准确地描述模型的公平程度。举个例子,开发一个用于预测肿瘤存在的新模型,该模型根据 1,000 名患者医疗记录的验证集进行评估。500 条记录来自女性患者,500 条记录来自男性患者。以下 混淆矩阵 总结了所有 1,000 个示例的结果:
| 真阳性 (TP):16 | 误报 (FP):4 |
| 漏报 (FN):6 | 真阴性 (TN):974 |
|
| |
|
| |
这些结果看起来很有希望:精确度为 80%,召回率为 72.7%。但如果我们分别计算每组患者的结果会怎样?让我们将结果分解为两个独立的混淆矩阵:一个用于女性患者,一个用于男性患者。
女性患者结果
| 真阳性 (TP):10 | 误报 (FP):1 |
| 漏报 (FN):1 | 真阴性 (TN):488 |
|
| |
|
| |
男性患者结果
| 真阳性 (TP):6 | 误报 (FP):3 |
| 漏报 (FN):5 | 真阴性 (TN):486 |
|
| |
|
| |
当我们分别计算女性和男性患者的指标时,我们发现每组的模型性能存在明显差异。
女性患者:
-
在 11 名实际患有肿瘤的女性患者中,模型正确预测了 10 名患者呈阳性(召回率:90.9%)。换句话说,该模型漏掉了 9.1% 的女性病例的肿瘤诊断。
-
同样,当模型在女性患者中返回肿瘤阳性时,11 例中有 10 例是正确的(精确率:90.9%);换句话说,该模型错误地预测了 9.1% 的女性病例的肿瘤。
男性患者:
-
然而,在 11 名实际患有肿瘤的男性患者中,模型仅正确预测 6 名患者呈阳性(召回率:54.5%)。这意味着该模型漏掉了 45.5% 的男性病例的肿瘤诊断。
-
当模型在男性患者中返回肿瘤阳性时,9 例中只有 6 例是正确的(精确率:66.7%);换句话说,该模型错误地预测了 33.3% 的男性病例的肿瘤。
基于上面的内容,相信读者对模型预测中固有的偏见已经有了更好的理解。同时,我们应该认识到,如果存在偏见的模型被用于关键领域(如医疗),那么,产生的风险将是巨大的。
3.1 额外的公平资源
公平性是机器学习学科中一个相对较新的子领域。要详细了解致力于开发新工具和技术以识别和减轻机器学习模型中的偏见的研究和计划,可查看 资料(链接-https://ai.google/responsibility/responsible-ai-practices/ )了解更多内容。
4.参考文献
链接-https://developers.google.cn/machine-learning/crash-course/fairness/types-of-bias