paste('abc', 'def', 'gh', sep = '') #粘贴字符串
substr('abcdefg', 2, 3) # 取特定字符串
gsub('abc', '', c('abc', 'abcc', 'abcbc')) # 将字符串中abc替换为空
strsplit('a;b;c', ';', fixed = T) # 按照;切分字符串
strsplit('a222b2.2c', '2.2', fixed = F) # 按照正则表达式分隔,这里的.是通配符
strsplit('a222b2.2c', '2.2', fixed = T) # 按照2.2分隔,这里的.只是.
# 排序
#sort
v <- c('a','d','z','c')
sort.result <- sort(v) #升序
sort.result
v <- c('a','d','z','c')
sort.result <- sort(v, decreasing = T) #降序
sort.result
#order
v <- c('a','d','z','c')
order.result <- order(v) # 输出的是每个字符按照排序后的顺序展示其在原来字符串中的索引/升序
order.result
v <- c('a','d','z','c')
order.result <- order(v, decreasing = T) # 输出的是每个字符按照排序后的顺序展示其在原来字符串中的索引/升序
order.result
# 排序练习
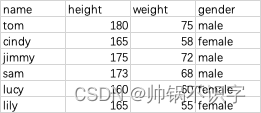
test <- read.table('/Users/zhangzhishuai/Downloads/13 lesson13 R数据框(一)/dataframe/test.txt', header = T,sep = '\t', row.names = 1)
test
sort(test$height)
order(test$height)
test[order(test$height),]
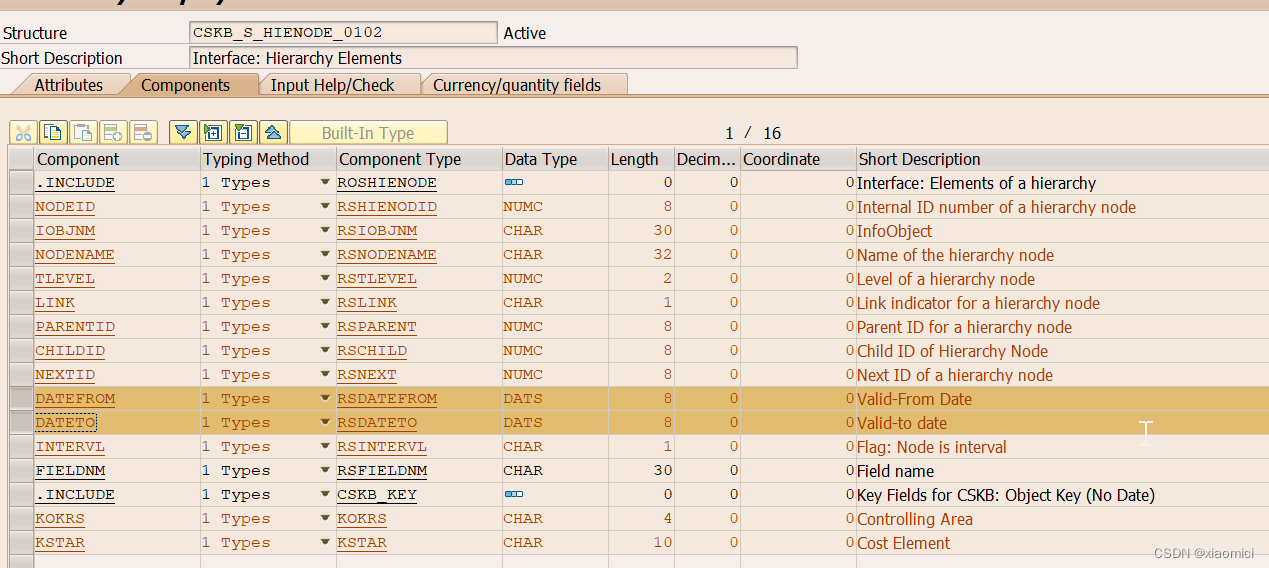
示例数据:

![BUU [ZJCTF 2019]NiZhuanSiWei](https://img-blog.csdnimg.cn/img_convert/7ae1a327c454ce25745b70e431e07d3e.png)