目录
1.LCT介绍
2.LCT引入到yolov5
2.1 加入common.py中:
2.2 加入yolo.py中:
2.3 yolov5s_LCT.yaml
2.4 yolov5s_LCT1.yaml
3.YOLOv5/YOLOv7魔术师专栏介绍

1.LCT介绍

论文: https://arxiv.org/pdf/1909.03834v2.pdf
AAAI 2020
摘要:
在本研究中,我们首先重新审视了SE块,然后基于全局上下文和注意力分布之间的关系进行了详细的实证研究,基于此提出了一个简单而有效的模块,称为线性上下文变换(LCT)块。我们将所有通道分成不同的组,并在每个通道组内对全局聚合的上下文特征进行归一化,减少了来自无关通道的干扰。通过对归一化的上下文特征进行线性变换,我们独立地为每个通道建模全局上下文。LCT块非常轻量级,易于插入不同的主干模型,同时增加的参数和计算负担可以忽略不计。大量实验证明,在ImageNet图像分类任务和COCO数据集上的目标检测/分割任务中,LCT块在不同主干模型上的性能优于SE块。此外,LCT在现有最先进的检测架构上都能带来一致的性能提升,例如在COCO基准测试中,无论基线模型的容量如何,APbbox提升1.5∼1.7%,APmask提升1.0%∼1.2%。我们希望我们的简单而有效的方法能为基于注意力的模型的未来研究提供一些启示。
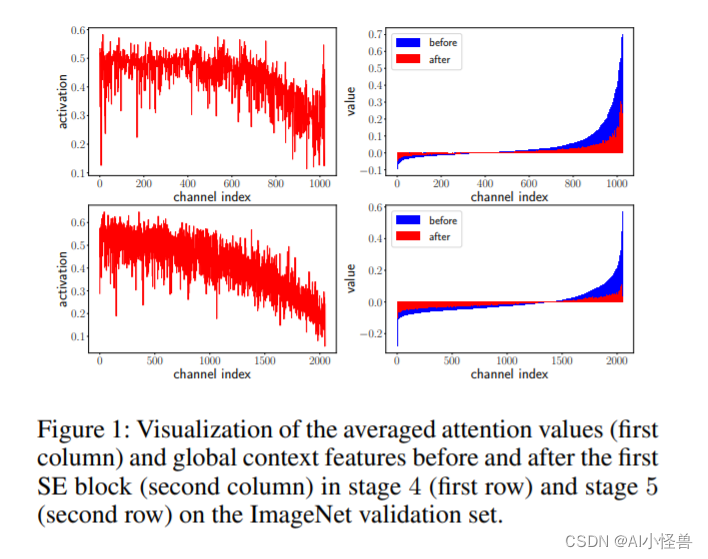
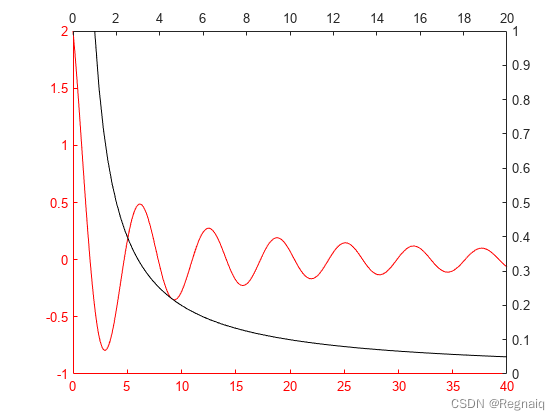
LCT结构图: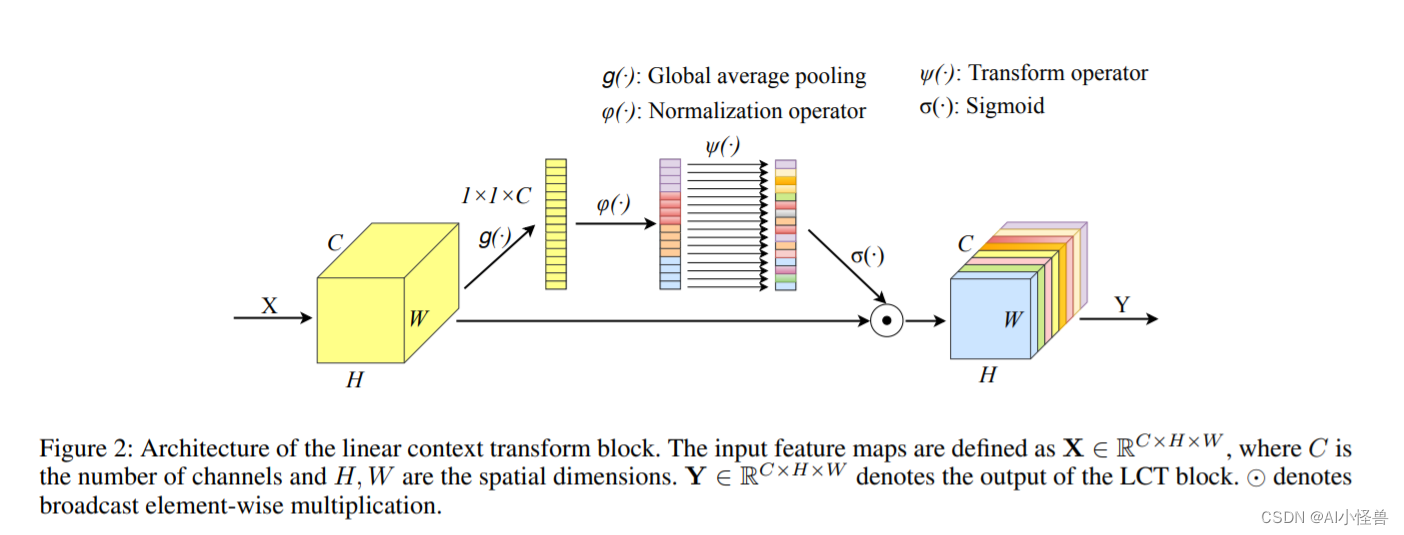
实验:
分类任务很重,LCT优于SE
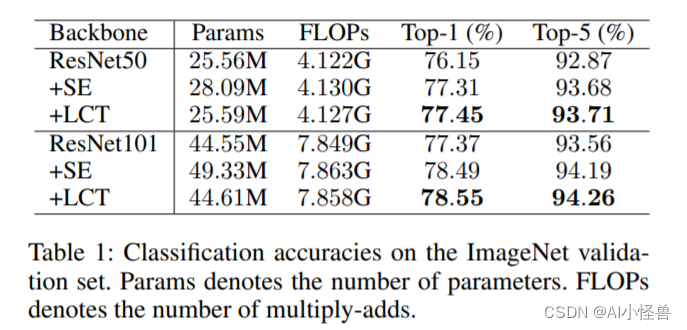
检测任务重,ap提升1.5∼1.7%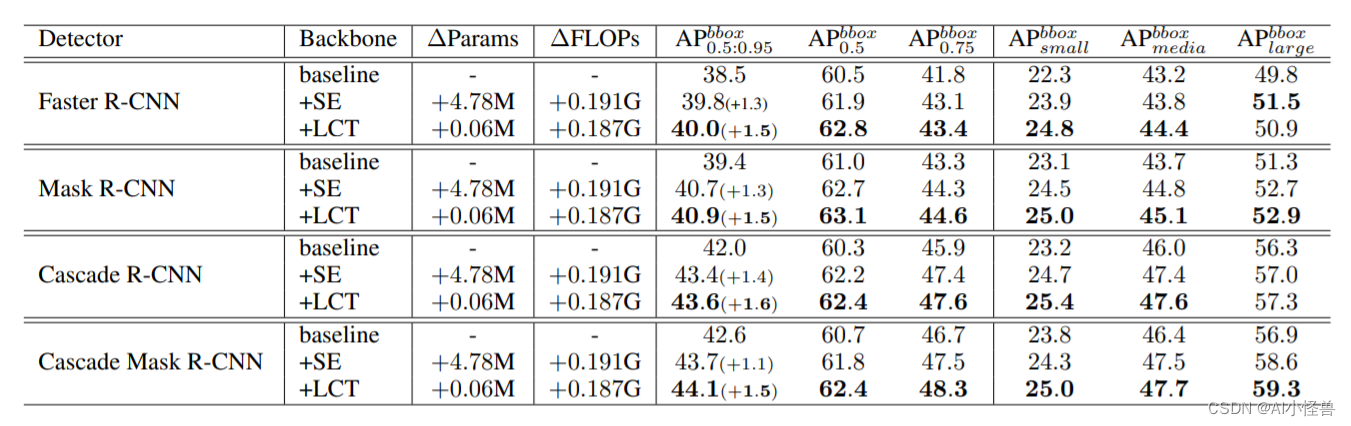
2.LCT引入到yolov5
2.1 加入common.py中:
###################### LCT attention #### start by AI&CV ###############################
"""
PyTorch implementation of Linear Context Transform Block
As described in https://arxiv.org/pdf/1909.03834v2
"""
import torch
from torch import nn
class LCT(nn.Module):
def __init__(self, channels, groups, eps=1e-5):
super().__init__()
assert channels % groups == 0, "Number of channels should be evenly divisible by the number of groups"
self.groups = groups
self.channels = channels
self.eps = eps
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.w = nn.Parameter(torch.ones(channels))
self.b = nn.Parameter(torch.zeros(channels))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
batch_size = x.shape[0]
y = self.avgpool(x).view(batch_size, self.groups, -1)
mean = y.mean(dim=-1, keepdim=True)
mean_x2 = (y ** 2).mean(dim=-1, keepdim=True)
var = mean_x2 - mean ** 2
y_norm = (y - mean) / torch.sqrt(var + self.eps)
y_norm = y_norm.reshape(batch_size, self.channels, 1, 1)
y_norm = self.w.reshape(1, -1, 1, 1) * y_norm + self.b.reshape(1, -1, 1, 1)
y_norm = self.sigmoid(y_norm)
return x * y_norm.expand_as(x)
###################### LCT attention #### END by AI&CV ###############################2.2 加入yolo.py中:
def parse_model(d, ch): # model_dict, input_channels(3)
添加以下内容
if m in {Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF,DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, CNeB, nn.ConvTranspose2d, DWConvTranspose2d, C3x, C2f,LCT}:2.3 yolov5s_LCT.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, LCT, [1024]], # 24
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.4 yolov5s_LCT1.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, LCT, [256]], # 18
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, LCT, [512]], # 22
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 25 (P5/32-large)
[-1, 1, LCT, [1024]], # 26
[[18, 22, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
3.YOLOv5/YOLOv7魔术师专栏介绍
💡💡💡YOLOv5/YOLOv7魔术师,独家首发创新(原创),持续更新,最终完结篇数≥100+,适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络
💡💡💡重点:通过本专栏的阅读,后续你也可以自己魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
专栏介绍:
✨✨✨原创魔改网络、复现前沿论文,组合优化创新
🚀🚀🚀小目标、遮挡物、难样本性能提升
🍉🍉🍉持续更新中,定期更新不同数据集涨点情况
本专栏提供每一步改进步骤和源码,开箱即用,在你的数据集下轻松涨点
通过注意力机制、小目标检测、Backbone&Head优化、 IOU&Loss优化、优化器改进、卷积变体改进、轻量级网络结合yolo等方面进行展开点
专栏链接如下:
https://blog.csdn.net/m0_63774211/category_12240482.html