推荐链接:
总结——》【Java】
总结——》【Mysql】
总结——》【Redis】
总结——》【Kafka】
总结——》【Spring】
总结——》【SpringBoot】
总结——》【MyBatis、MyBatis-Plus】
总结——》【Linux】
总结——》【MongoDB】
总结——》【Elasticsearch】
Mysql——》哈希索引
- 一、概念
- 二、示例
- 三、优点
- 四、缺点
- 五、哈希函数
- 六、如何解决hash碰撞/冲突
- 1、链表法
- 2、开放寻址
一、概念
AHI = Adaptive Hash Index = 自适应哈希索引
InnoDB存储引擎内部自己去监控索引表,如果监控到某个索引经常用,那么就认为是热数据,然后内部自己创建一个hash索引,称之为自适应哈希索引。创建以后,如果下次又查询到这个索引,那么直接通过hash算法推导出记录的地址,直接一次就能查到数据,比重复去B+tree索引中查询三四次节点的效率高了不少。
AHI是 InnoDB 存储引擎的一种索引优化技术,它可以根据访问模式实时地调整和优化哈希索引结构,提高查询速度和效率。AHI 运行时会动态调整它的大小,以便于它能够容纳正在访问的数据块的索引,并且自动调整索引的深度,以便于在存储数据块很多的情况下仍然能够保持高效的查询性能。
AHI 的分区个数是由 InnoDB 存储引擎内部计算和调整的,通常取决于数据库的访问热度、数据量、CPU 和内存等资源的使用情况。在大多数情况下,用户不需要手动地设定或调整 AHI 的分区个数,而是让 InnoDB 自行管理和优化。
-- 是否开启自适应哈希索引功能,默认值ON开启
show VARIABLES like 'innodb_adaptive_hash_index';
-- 开启
SET GLOBAL innodb_adaptive_hash_index = ON;
-- 关闭
SET GLOBAL innodb_adaptive_hash_index = OFF;
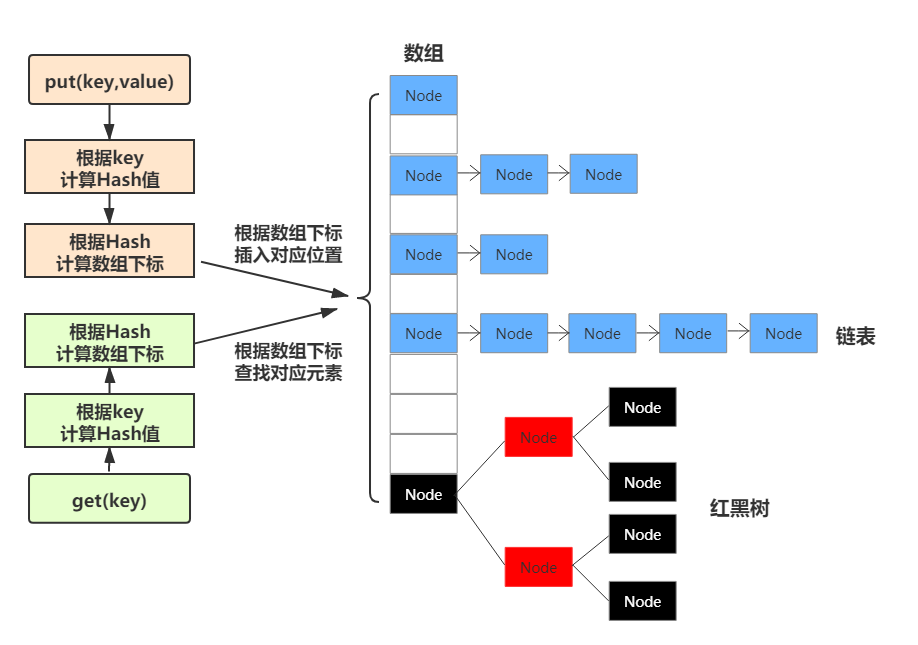
二、示例
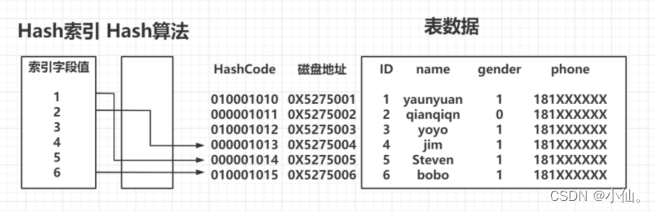
1、根据索引字段值,生成对应的HashCode
2、基于HashCode,映射对应的磁盘地址
三、优点
- 只支持等值查询(因为在查询数据的时候要根据键值计算哈希码)
- 时间复杂度是 O(1),查询速度比较快
四、缺点
- 不支持范围查询(> < >= <= between and)
- 不支持排序(数据不是按顺序存储)
- 不支持部分索引(联合索引将几个字段合并hash)
- 字段重复值很多的时候,会出现大量的哈希冲突(采用拉链法解决),效率会降低。
五、哈希函数
采用除法散列方式





![[MySQL]MySQL库的操作](https://img-blog.csdnimg.cn/img_convert/e13a733e474c1a58b67efcf73a26043e.png)