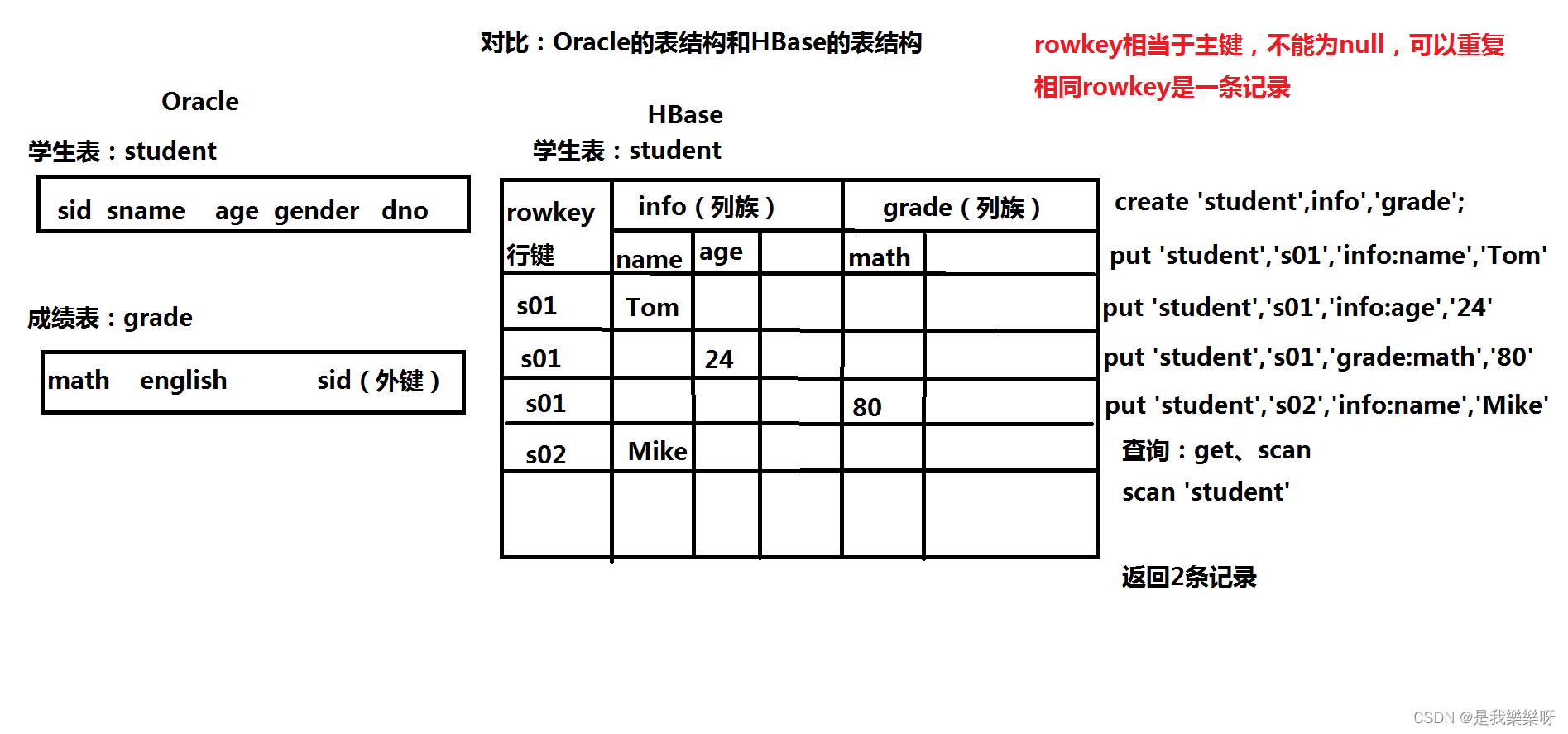
六、DDL数据库操作
1、MySQL的组成结构
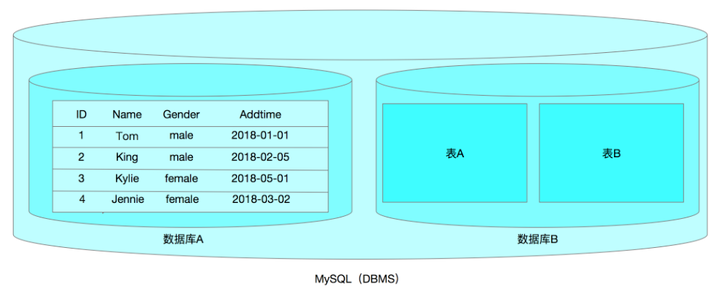
注:我们平常说的MySQL,其实主要指的是MySQL数据库管理软件。
一个MySQL DBMS可以同时存放多个数据库,理论上一个项目就对应一个数据库。如博客项目blzhujianog数据库、商城项目shop数据库、微信项目wechat数据库。
一个数据库中还可以同时包含多个数据表,而数据表才是真正用于存放数据的位置。(类似我们Office软件中的Excel表格),理论上一个功能就对应一个数据表。如博客系统中的用户管理功能,就需要一个user数据表、博客中的文章就需要一个article数据表、博客中的评论就需要一个message数据表。
一个数据表又可以拆分为多个字段,每个字段就是一个属性。
一个数据表除了字段以外,还有很多行,每一行都是一条完整的数据(记录)。
2、数据库的基本操作
① 创建数据库
普及英语小课堂:
创建 => create
数据库 => database
创建 + 数据库 = create database
数据库名称(字母+数字+下划线组成,以字母开头,不能出现中文以及特殊字符)
基本语法:
mysql> create database 数据库名称 [设置编码格式];
特别注意:在MySQL中,当一条SQL语句编写完毕后,一定要使用分号;进行结尾,否则系统认为这条语句还没有结束。
案例:创建数据库的相关案例
创建db_itheima库
create database db_itheima;
创建db1库并指定默认字符集
create database db_itheima default charset gbk;
如果存在不报错(if not exists)
create database if not exists db_itheima default character set utf8;
说明:不能创建相同名字的数据库!
扩展:编码格式,常见的gbk(中国的编码格式)与utf8(国际通用编码格式)
latin1 256个字符
国内汉字无法通过256个字符进行描述,所以国内开发了自己的编码格式gb2312,升级gbk
中国台湾业开发了一套自己的编码格式big5
很多项目并不仅仅只在本地使用,也可能支持多国语言,标准化组织开发了一套通用编码utf8,后来5.6版本以后又进行了升级utf8mb4
编写SQL语句是一个比较细致工作,不建议大家直接在终端中输入SQL语句,可以先把你要写的SQL语句写入一个记事本中,然后拷贝执行。
② 查询数据库
英语小课堂:
显示 => show
数据库 => database
显示 + 所有数据库 = show databases;
基本语法:显示所有数据库
mysql> show databases;
③ 删除数据库
英语小课堂:
删除 => drop
数据库 => database
删除 + 数据库 = drop database
数据库名称; 基本语法:
mysql> drop database 数据库名称;
案例:删除db_itheima数据库
mysql> drop database db_itheima;
④ 选择数据库
从数据库列表中查找需要使用的数据库
格式:
mysql> use db_itheima;
查看正在使用的数据库(8.0以后版本需要基于select查询来获取当前数据库)
mysql> select database();
3、小结
创建数据库:CREATE DATABASE 数据库名;
查看数据库:SHOW DATABASES;
删除数据库:DROP DATABASE 数据库名; 使用数据库:USE 数据库名;
七、DDL数据表操作
特别注意:创建数据表必须有一个前提,首先要明确选择某一个数据库。
1、数据表的基本操作
☆ 数据表的创建
英语小课堂:
创建 => create
数据表 => table
创建 + 数据表 = create table 数据表名称
基本语法:
mysql> create table 数据表名称(
字段1 字段类型 [字段约束],
字段2 字段类型 [字段约束],
...
);
案例:创建一个admin管理员表,拥有3个字段(编号、用户名称、用户密码)
mysql> create database db_itheima;
mysql> use db_itheima;
use在MySQL中的含义代表选择,use 数据库名称相当于选择指定的数据库。而且use比较特殊,其选择结束后,其尾部可以不加分号;但是强烈建议所有的SQL语句都要加分号,养成一个好习惯。
mysql> create table tb_admin(
id tinyint,
username varchar(20),
password char(32)
) engine=innodb default charset=utf8;
tinyint :微整型,范围-128 ~ 127,无符号型,则表示0 ~ 255 表示字符串类型可以使用char与varchar,char代表固定长度的字段,varchar代表变化长度的字段。
案例:创建一个article文章表,拥有4个字段(编号、标题、作者、内容)
mysql> use db_itheima;
mysql> create table tb_article(
id int,
title varchar(50),
author varchar(20),
content text
) engine=innodb default charset=utf8;
text :文本类型,一般情况下,用varchar存储不了的字符串信息,都建议使用text文本进行处理。
varchar存储的最大长度,理论值65535个字符。但是实际上,有几个字符是用于存放内容的长度的,所以真正可以使用的不足65535个字符,另外varchar类型存储的字符长度还和编码格式有关。1个GBK格式的占用2个字节长度,1个UTF8格式的字符占用3个字节长度。GBK = 65532~65533/2,UTF8 = 65532~65533/3
☆ 查询已创建数据表
英语小课堂:
显示 => show
数据表 => table
显示所有数据表(当前数据库)
mysql> use 数据库名称;
mysql> show tables;
显示数据表的创建过程(编码格式、字段等信息)
mysql> desc 数据表名称;
☆ 修改数据表信息
① 数据表字段添加
英语小课堂:
修改 => alter
数据表 => table
基本语法:
mysql> alter table 数据表名称 add 新字段名称 字段类型 first|after 其他字段名称;
选项说明:
first:把新添加字段放在第一位
after 字段名称:把新添加字段放在指定字段的后面
案例:在tb_article文章表中添加一个addtime字段,类型为date(年-月-日)
mysql> alter table tb_article add addtime date after content;
mysql> desc tb_article;
② 修改字段名称或字段类型
修改字段名称与字段类型(也可以只修改名称)
mysql> alter table tb_admin change username user varchar(40);
mysql> desc tb_admin;
仅修改字段的类型
mysql> alter table tb_admin modify user varchar(20);
mysql> desc tb_admin;
③ 删除某个字段
mysql> alter table tb_article drop 字段名称;
mysql> desc tb_article;
④ 修改数据表名称
rename table 旧名称 to 新名称;
☆ 删除数据表
英语小课堂:
删除 => drop
数据表 => table
mysql> drop table 数据表名称;
2、字段类型详解
① 整数类型
| 分类 | 类型名称 | 说明 |
|---|---|---|
| tinyint | 很小的整数 | -128 ~ 127 |
| smallint | 小的整数 | -32768 ~ 32767 |
| mediumint | 中等大小的整数 | -8388608 ~ 8388607 |
| int(integer) | 普通大小的整数 | -2147483648 ~ 2147483647 |
② 浮点类型 浮点类型(精度失真情况)和定点类型(推荐使用定点类型)
| 分类 | 类型名称 |
|---|---|
| float | 单精度浮点数 |
| double | 双精度浮点数 |
| decimal(m,d) | 定点数,decimal(10,2) |
decimal(10,2) :代表这个数的总长度为10 = 整数长度 + 小数长度,2代表保留2位小数
③ 日期类型
| 份额里 | 类型名称 |
|---|---|
| year | YYYY 1901~2155 |
| time | HH:MM:SS -838:59:59~838:59:59 |
| date | YYYY-MM-DD 1000-01-01~9999-12-3 |
| datetime | YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00~ 9999-12-31 23:59:59 |
| timestamp | YYYY-MM-DD HH:MM:SS 19700101 00:00:01 UTC~2038-01-19 03:14:07UTC |
④ 文本
| 类型名称 | 说明 |
|---|---|
| char(m) | m为0~255之间的整数定长(固定长度) |
| varchar(m) | m为0~65535之间的整数变长(变化长度) |
| text | 允许长度0~65535字节 |
| mediumtext | 允许长度0~167772150字节 |
| longtext | 允许长度0~4294967295字节 |
八、DML数据操作语言
1、DML包括哪些SQL语句
insert插入、update更新、delete删除
2、数据的增删改(重点)
英语小课堂: 增加:insert 删除:delete 修改:update
☆ 数据的增加操作
基本语法:
mysql> insert into 数据表名称([字段1,字段2,字段3...]) values (字段1的值,字段2的值,字段3的值...);
特别注意:在SQL语句中,除了数字,其他类型的值,都需要使用引号引起来,否则插入时会报错。
第一步:准备一个数据表
mysql> use db_itheima;
mysql> create table tb_user(
id int,
username varchar(20),
age tinyint unsigned,
gender enum('男','女','保密'),
address varchar(255)
) engine=innodb default charset=utf8;
unsigned代表无符号型,只有0到正数。tinyint unsigned无符号型,范围0 ~ 255 enum枚举类型,多选一。只能从给定的值中选择一个
第二步:使用insert语句插入数据
mysql> insert into tb_user values (1,'刘备',34,'男','广州市天河区');
mysql> insert into tb_user(id,username,age) values (2,'关羽',33);
第三步:批量插入多条数据
mysql> insert into tb_user values (3,'大乔',19,'女','上海市浦东新区'),(4,'小乔',18,'女','上海市浦东新区'),(5,'马超',26,'男','北京市昌平区');
☆ 数据的修改操作
基本语法:
mysql> update 数据表名称 set 字段1=更新后的值,字段2=更新后的值,... where 更新条件;
特别说明:如果在更新数据时,不指定更新条件,则其会把这个数据表的所有记录全部更新一遍。
案例:修改username='马鹏'这条记录,将其性别更新为男,家庭住址更新为广东省深圳市
mysql> update tb_user set gender='男',address='广东省深圳市' where username='马鹏';
案例:今年是2020年,假设到了2021年,现在存储的学员年龄都差1岁,整体进行一次更新
mysql> update tb_user set age=age+1;
☆ 数据的删除操作
基本语法:
mysql> delete from 数据表名称 [where 删除条件];
案例:删除tb_user表中,id=1的用户信息
mysql> delete from tb_user where id=1;
delete from与truncate清空数据表操作
mysql> delete from 数据表;
或
mysql> truncate 数据表;
delete from与truncate区别在哪里?
-
delete:删除数据记录
-
数据操作语言(DML)
-
删除大量记录速度慢,只删除数据,主键自增序列不清零,100 => 新插入 => 101
-
可以带条件删除
-
truncate:删除所有数据记录
-
数据定义语言(DDL)
-
清里大量数据速度快,主键自增序列清零, 100 => 新插入 => 1
-
不能带条件删除
九、SQL约束
1、主键约束
1、PRIMARY KEY 约束唯一标识数据库表中的每条记录。
2、主键必须包含唯一的值。
3、主键列不能包含 NULL 值。
4、每个表都应该有一个主键,并且每个表只能有一个主键。 主键约束:要求主键这一列必须是唯一的、非空,另外一定要特别注意:一个表可以没有主键,但是如果有主键只能有且仅有一个主键。
遵循原则:
1)主键应当是对用户没有意义的(没创建一个数据表默认都应该拥有一个id字段)
2)永远也不要更新主键。
3)主键不应包含动态变化的数据,如时间戳、创建时间列、修改时间列等。(1-无穷大)
4) 主键应当由计算机自动生成。 创建主键约束:创建表时,在字段描述处,声明指定字段为主键
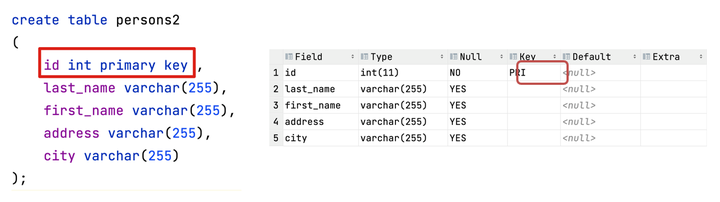
删除主键约束:如需撤销 PRIMARY KEY 约束,请使用下面的 SQL
alter table persons2 drop primary key;

补充:自动增长 => auto_increment,从1开始,依次递增
我们通常希望在每次插入新记录时,数据库自动生成字段的值。 我们可以在表中使用 auto_increment(自动增长列)关键字,自动增长列类型必须是整型,自动增长列必须为键(一般是主键)。
下列 SQL 语句把 "Persons" 表中的 "Id" 列定义为 auto_increment 主键
create table persons3(
id int auto_increment primary key,
first_name varchar(255),
last_name varchar(255),
address varchar(255),
city varchar(255)
) default charset=utf8;
向persons添加数据时,可以不为Id字段设置值,也可以设置成null,数据库将自动维护主键值:
insert into persons3(first_name,last_name) values('Bill','Gates');
insert into persons3(id,first_name,last_name) values(null,'Bill','Gates');
运行效果:

特别说明:如果某个列设置为自动增长,则这一列必须设置为主键,否则系统会报错。
2、非空约束
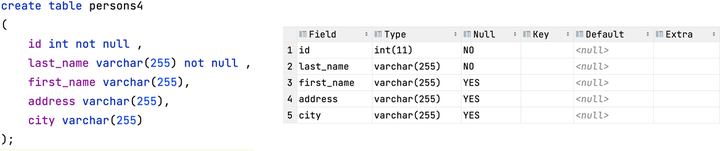
NOT NULL 约束强制列不接受 NULL 值。
NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录。 下面的 SQL 语句强制 "id" 列和 "last_name" 列不接受 NULL 值:
3、唯一约束
UNIQUE 约束唯一标识数据库表中的每条记录。
UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
PRIMARY KEY 拥有自动定义的 UNIQUE 约束。
注:虽然唯一约束与主键约束在描述上功能类似,但是其实还是很多区别的。
相同点:都可以表示唯一性,唯一标识数据表中的每一条记录(一行)
不同点:
① 插入数据的来源不同 主键大多数都是自动编号结合primary key 唯一大多数都是手工设置(不一定都是数字类型,如身份证号也可以表示唯一)
② 主键必须非空字段,但是唯一约束不要求列必须是非空的,这一列也可以出现null空值
③ 一个数据表中如果有主键,有且仅有1个主键。但是在一个数据表中可以拥有多个唯一约束 所以数据库考察中,经常会问:主键约束与唯一约束区别
主键一定满足唯一约束,但是唯一约束不一定是主键。
请注意:
每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。

4、默认值约束
default 默认值
5、外键约束(了解)
外键约束(多表关联使用)
比如:有两张数据表,这两个数据表之间有联系,通过了某个字段可以建立连接,这个字段在其中一个表中是主键,在另外一张表中,我们就把其称之为外键。
6、小结
① 主键约束:唯一标示,不能重复,不能为空。
1)主键应当是对用户没有意义的,一般都叫id
2)永远也不要更新主键,自动编号
3)主键不应包含动态变化的数据,如时间戳、创建时间列、修改时间列等。
4)主键应当由计算机自动生成,一般配合auto_increment自动增长
自动增长:
我们可以在表中使用 auto_increment(自动增长列)关键字,自动增长列类型必须是整型,自动增长列必须为键(一般是主键)。
② 非空约束:
NOT NULL 约束强制列不接受 NULL 值。
③ 唯一约束:
UNIQUE 约束唯一标识数据库表中的每条记录。
UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
PRIMARY KEY 拥有自动定义的 UNIQUE 约束。
④ 默认值约束 default 默认值
⑤ 外键约束: 多表关联字段、在一个表中是主键,在另外一个表中是非主键(则这个字段一般就称之外键)
十、DQL数据查询语言
1、数据集准备
CREATE TABLE product
(
pid INT PRIMARY KEY,
pname VARCHAR(20),
price DOUBLE,
category_id VARCHAR(32)
) DEFAULT CHARSET=utf8;
插入数据:
INSERT INTO product VALUES (1,'联想',5000,'c001');
INSERT INTO product VALUES (2,'海尔',3000,'c001');
INSERT INTO product VALUES (3,'雷神',5000,'c001');
INSERT INTO product VALUES (4,'杰克琼斯',800,'c002');
INSERT INTO product VALUES (5,'真维斯',200,'c002');
INSERT INTO product VALUES (6,'花花公子',440,'c002');
INSERT INTO product VALUES (7,'劲霸',2000,'c002');
INSERT INTO product VALUES (8,'香奈儿',800,'c003');
INSERT INTO product VALUES (9,'相宜本草',200,'c003');
INSERT INTO product VALUES (10,'面霸',5,'c003');
INSERT INTO product VALUES (11,'好想你枣',56,'c004');
INSERT INTO product VALUES (12,'香飘飘奶茶',1,'c005');
INSERT INTO product VALUES (13,'海澜之家',1,'c002');
DataGrip软件关键字替换,可以使用Ctrl + R快捷键
2、select查询
# 根据某些条件从某个表中查询指定字段的内容
格式:select [distinct]*| 列名,列名 from 表where 条件
3、简单查询
# 1.查询所有的商品.
select * from product;
# 2.查询商品名和商品价格.
select pname,price from product;
# 3.查询结果是表达式(运算查询):将所有商品的价格+10元进行显示.
select pname,price+10 from product;
4、条件查询(where子句)
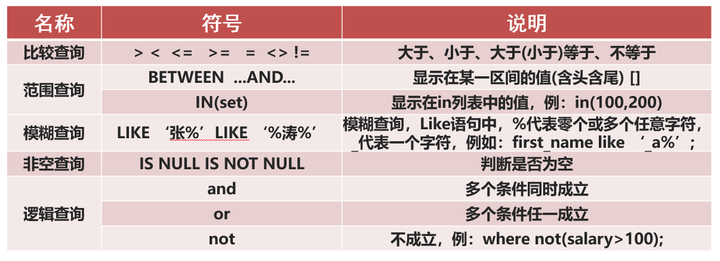
☆ 比较查询
# 查询商品名称为“花花公子”的商品所有信息:
SELECT * FROM product WHERE pname = '花花公子';
# 查询价格为800商品
SELECT * FROM product WHERE price = 800;
# 查询价格不是800的所有商品
SELECT * FROM product WHERE price != 800;
SELECT * FROM product WHERE price <> 800;
# 查询商品价格大于60元的所有商品信息
SELECT * FROM product WHERE price > 60;
# 查询商品价格小于等于800元的所有商品信息
SELECT * FROM product WHERE price <= 800;
☆ 范围查询
# 查询商品价格在200到1000之间所有商品
SELECT * FROM product WHERE price BETWEEN 200 AND 1000;
# 查询商品价格是200或800的所有商品
SELECT * FROM product WHERE price IN (200,800);
☆ 逻辑查询
# 查询商品价格在200到1000之间所有商品
SELECT * FROM product WHERE price >= 200 AND price <=1000;
# 查询商品价格是200或800的所有商品
SELECT * FROM product WHERE price = 200 OR price = 800;
# 查询价格不是800的所有商品
SELECT * FROM product WHERE NOT(price = 800);
☆ 模糊查询
# 查询以'香'开头的所有商品
SELECT * FROM product WHERE pname LIKE '香%';
# 查询第二个字为'想'的所有商品
SELECT * FROM product WHERE pname LIKE '_想%';
☆ 非空查询
# 查询没有分类的商品
SELECT * FROM product WHERE category_id IS NULL;
# 查询有分类的商品
SELECT * FROM product WHERE category_id IS NOT NULL;
5、排序查询(order by子句)
# 通过order by语句,可以将查询出的结果进行排序。暂时放置在select语句的最后。
格式:SELECT * FROM 表名 ORDER BY 排序字段 ASC|DESC;
ASC 升序 (默认)
DESC 降序
# 1.使用价格排序(降序)
SELECT * FROM product ORDER BY price DESC;
# 2.在价格排序(降序)的基础上,以分类排序(降序)
SELECT * FROM product ORDER BY price DESC,category_id DESC;
6、聚合查询
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个单一的值;另外聚合函数会忽略空值。 今天我们学习如下五个聚合函数:
| 聚合函数 | 作用 |
|---|---|
| count() | 统计指定列不为NULL的记录行数; |
| sum() | 计算指定列的数值和,如果指定列类型不是数值类型,则计算结果为0 |
| max() | 计算指定列的最大值,如果指定列是字符串类型,使用字符串排序运算; |
| min() | 计算指定列的最小值,如果指定列是字符串类型,使用字符串排序运算; |
| avg() | 计算指定列的平均值,如果指定列类型不是数值类型,则计算结果为0 |
案例演示:
# 1、查询商品的总条数
SELECT COUNT(*) FROM product;
# 2、查询价格大于200商品的总条数
SELECT COUNT(*) FROM product WHERE price > 200;
# 3、查询分类为'c001'的所有商品的总和
SELECT SUM(price) FROM product WHERE category_id = 'c001';
# 4、查询分类为'c002'所有商品的平均价格
SELECT AVG(price) FROM product WHERE categ ory_id = 'c002';
# 5、查询商品的最大价格和最小价格
SELECT MAX(price),MIN(price) FROM product;
7、分组查询与having子句
☆ 分组查询介绍
分组查询就是将查询结果按照指定字段进行分组,字段中数据相等的分为一组。
分组查询基本的语法格式如下:
GROUP BY 列名 [HAVING 条件表达式] [WITH ROLLUP]
说明:
-
列名: 是指按照指定字段的值进行分组。
-
HAVING 条件表达式: 用来过滤分组后的数据。
-
WITH ROLLUP:在所有记录的最后加上一条记录,显示select查询时聚合函数的统计和计算结果
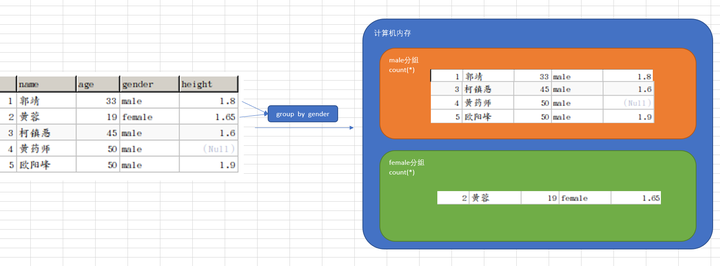
☆ group by的使用
group by可用于单个字段分组,也可用于多个字段分组
-- 根据gender字段来分组
select gender from students group by gender;
-- 根据name和gender字段进行分组
select name, gender from students group by name, gender;
① group by可以实现去重操作
② group by的作用是为了实现分组统计(group by + 聚合函数)
☆ group by + 聚合函数的使用
-- 统计不同性别的人的平均年龄
select gender,avg(age) from students group by gender;
-- 统计不同性别的人的个数
select gender,count(*) from students group by gender;
☆ group_concat()函数
group_concat()是MySQL中自带的一个函数,这个函数主要用于分组查询中。其主要功能可以某个分组中的数据中的某列(字段)值进行concat拼接操作。 案例:统计男分组中,一共有哪些人,字段值与字段值之间使用逗号隔开。
select gender,group_concat(name) from tb_student group by gender;
☆ with rollup回溯统计
with rollup主要应用于group by分组中,代表对所有分组数据进行回溯统计。
select gender,count(*) from tb_student group by gender;
但是我们希望在以上分组的基础上,在添加一行,没有分组,只有一个具体的值。这个值是以上两个分组的总记录数。
select gender,count(*) from tb_student group by gender with rollup;
8、having的使用
having作用和where类似都是过滤数据的,但是两者之间的执行顺序不同
① where子句 ② group by子句 ③ having子句
第一种情况:如果只是简单的查询操作(没有group by的情况),大部分时间having是可以直接替代where子句
select * from product where price > 800;
以上语句等价于
select * from product having price > 800;
第二种情况:
-- 根据gender字段进行分组,统计分组条数大于2的
select gender,count(*) from students group by gender having count(*)>2;
案例演示:
#1 统计各个分类商品的个数
SELECT category_id ,COUNT(*) FROM product GROUP BY category_id ;
#2 统计各个分类商品的个数,且只显示个数大于1的信息
SELECT category_id ,COUNT(*) FROM product GROUP BY category_id HAVING COUNT(*) > 1;
9、limit子句的使用
应用场景:限制查询与分页查询
限制查询:主要限制数据查询的数量(获取数据表中的前3条数据)
select * from 数据表 limit 查询数量;
分页查询:实际特别接近,因为只要有分页的地方,底层100%都是使用limit子句实现的
分页查询在项目开发中常见,由于数据量很大,显示屏长度有限,因此对数据需要采取分页显示方式。例如数据共有30条,每页显示5条,第一页显示1-5条,第二页显示6-10条。
格式:
SELECT 字段1,字段2... FROM 表名 LIMIT M,N
M: 整数,表示从第几条索引开始,计算方式 (当前页-1)*每页显示条数
N: 整数,表示查询多少条数据
SELECT 字段1,字段2... FROM 表明 LIMIT 0,5
SELECT 字段1,字段2... FROM 表明 LIMIT 5,5
10、小结
条件查询:select *|字段名 form 表名 where 条件;
排序查询:SELECT * FROM 表名 ORDER BY 排序字段 ASC|DESC;
聚合查询函数:count(),sum(),max(),min(),avg()。
分组查询:SELECT 字段1,字段2… FROM 表名 GROUP BY 分组字段 HAVING 分组条件;
分页查询:
SELECT 字段1,字段2... FROM 表名 LIMIT M,N
M: 整数,表示从第几条索引开始,计算方式 (当前页-1)*每页显示条数
N: 整数,表示查询多少条数据

![[MySQL]MySQL库的操作](https://img-blog.csdnimg.cn/img_convert/e13a733e474c1a58b67efcf73a26043e.png)