一、概述
读写分离是常见的一种数据库架构,一般是由 1 主多从构成,特殊场景下也会存在多主多从的架构。
无论哪一种架构,对于应用程序来说都是多个数据源,增加了代码的复杂性。如果配合 mycat,则可以实现屏蔽数据库复杂性,面向应用程序提供统一入口的功能。
二、配置
mycat2 的配置逻辑架构大致如下:
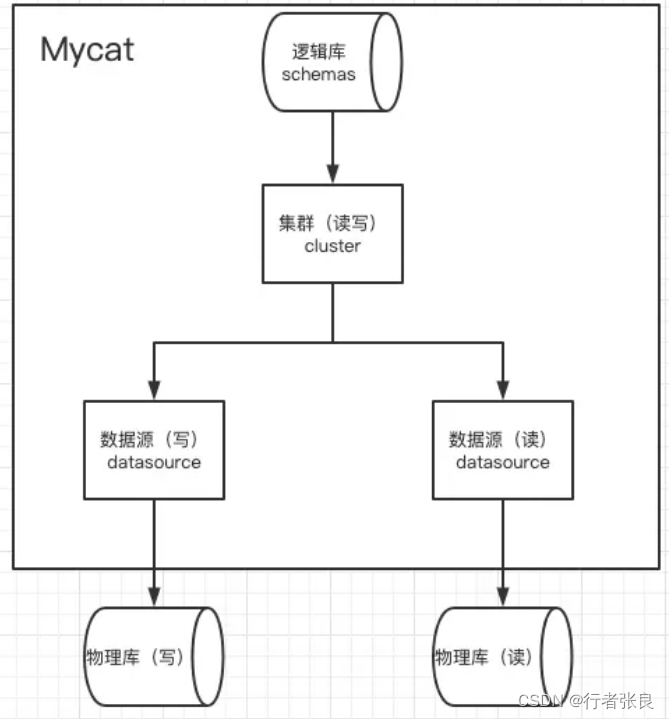
分别对应mycat的配置文件如下图:
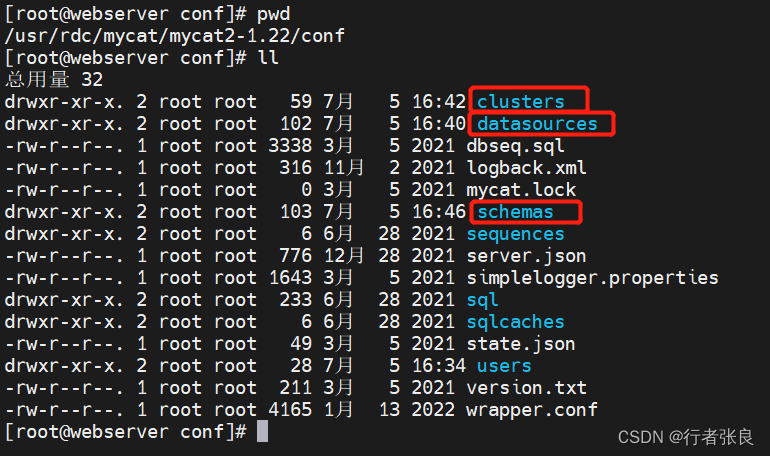
本文采用 mycat2 特有的注释进行相关配置读写分离。
前提:
1、已配置主从的两个 mysql 实例
2、mycat2 实例
步骤:
1、使用 Navicat 连接 mycat2
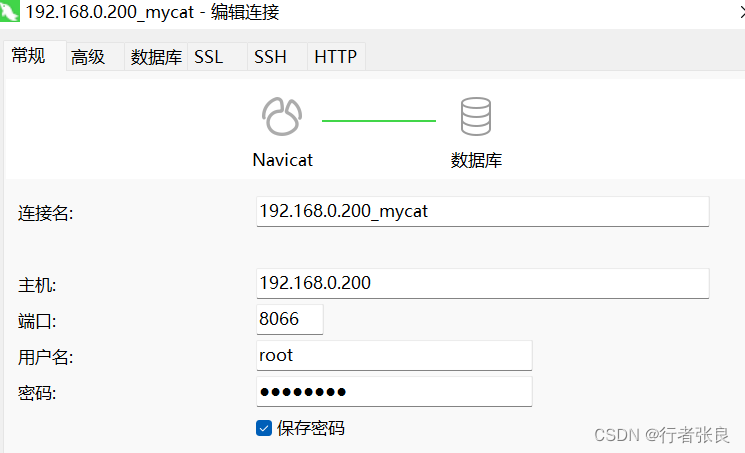
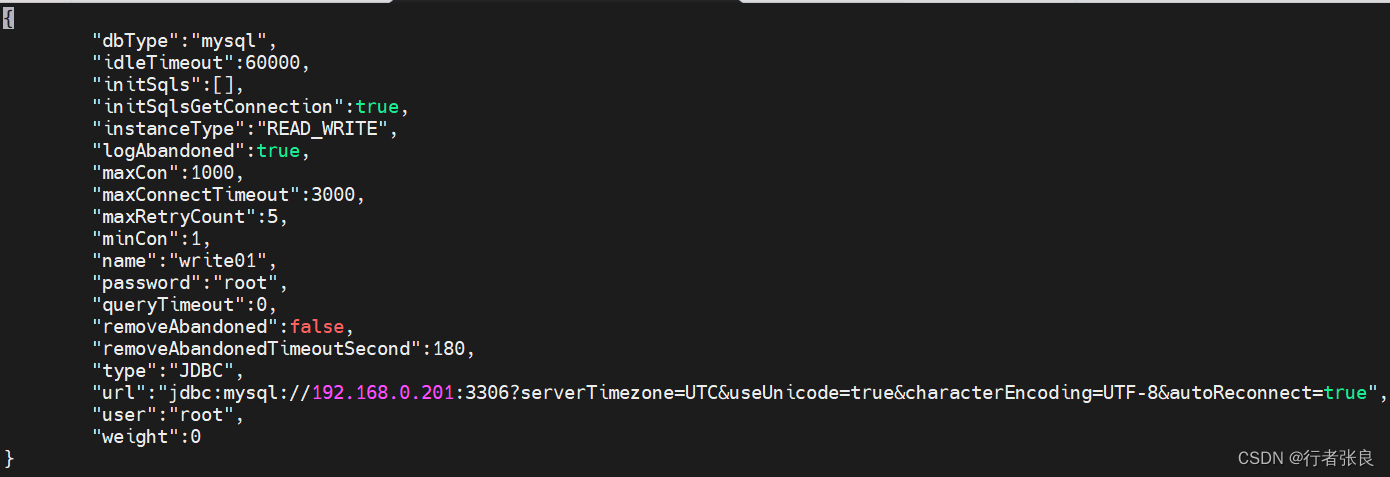
2、增加mysql读写库数据源
复制以下脚本在navicat查询器中执行:
/*+ mycat:createDataSource{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"master_write01",
"password":"root",
"type":"JDBC",
"url":"jdbc:mysql://192.168.0.201:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",
"weight":0
} */;
/*+ mycat:createDataSource{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"slave_read01",
"password":"root",
"type":"JDBC",
"url":"jdbc:mysql://192.168.0.202:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",
"weight":0
} */;
可在查询器中通过执行以下语句查询已创建的数据源
/*+ mycat:showDataSources {} */
也可以通过配置文件夹查看到新创建的数据源配置文件

后续配置变更可以直接修改此配置文件
vi read01.datasource.json
vi write01.datasource.json
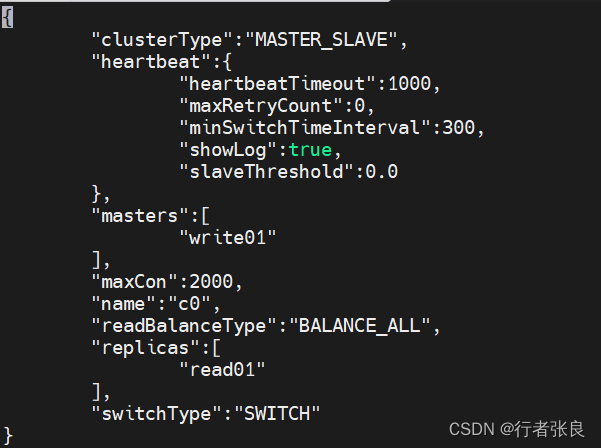
3、创建读写集群
复制以下语句到查询器中执行:
/*! mycat:createCluster{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
},
"masters":[
"master_write01" // 可以配置多个主节点,在主挂的时候会选一个检测存活的数据源作为主节点
],
"maxCon":2000,
"name":"c0", // 集群的名字
"readBalanceType":"BALANCE_ALL", // 读数据的负责均衡策略:BALANCE_ALL -- 获取集群中所有数据源,BALANCE_ALL_READ -- 获取集群中允许读的数据源, BALANCE_READ_WRITE -- 获取集群中允许读写的数据源,但允许读的数据源优先, BALANCE_NONE -- 获取集群中允许写数据源,即主节点中选择
"replicas":[
"slave_read01" // 可以配置多个从节点
],
"switchType":"SWITCH"
} */;
可在查询器中通过执行以下语句查询已创建的查看集群
/*+ mycat:showClusters {} */
也可以通过配置文件夹查看到新创建的mycat集群配置文件

后续参数变更可以直接修改此文件
vi co.cluster.json
4、创建逻辑库
/*+ mycat:createSchema{
"customTables":{},
"globalTables":{},
"normalTables":{},
"schemaName":"pmonitor-cloud", // 与物理库中的数据库名保持一致
"shardingTables":{},
"targetName":"c0" // 注意 targetName 指的是集群的名字
} */;
可在查询器中通过执行以下语句查询已创建的逻辑库
/*+ mycat:showSchemas {} */
也可以通过配置文件夹查看到新创建的mycat集群配置文件

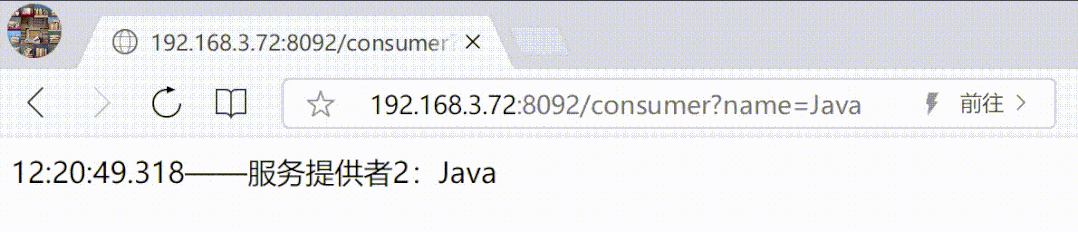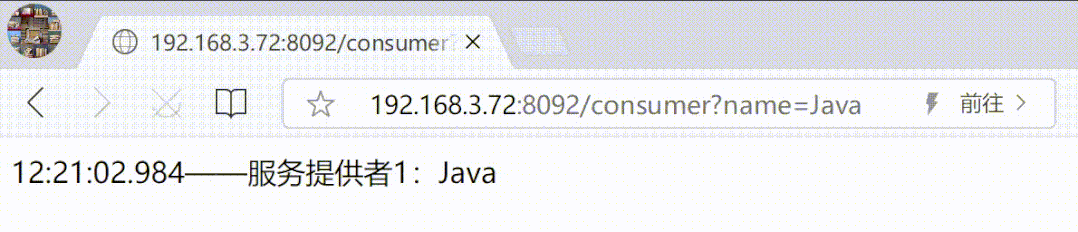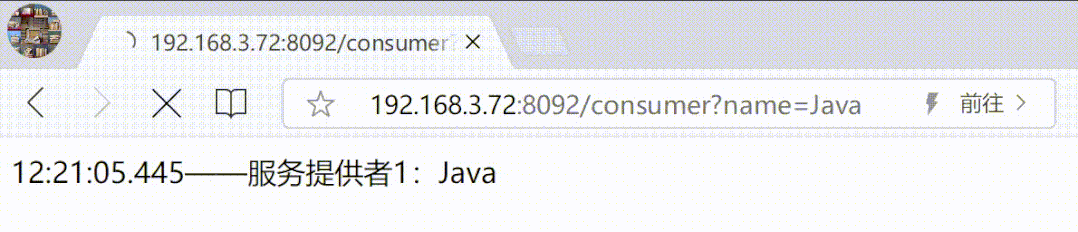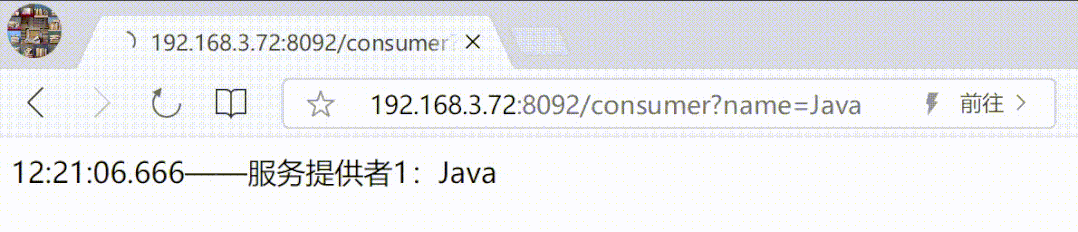
5、连接测试
以上执行成功后,重新连接 mycat 即可看到逻辑库,打击打开可以看到库内所有表(不用单独再创建每一张物理表的逻辑表,自动映射)。