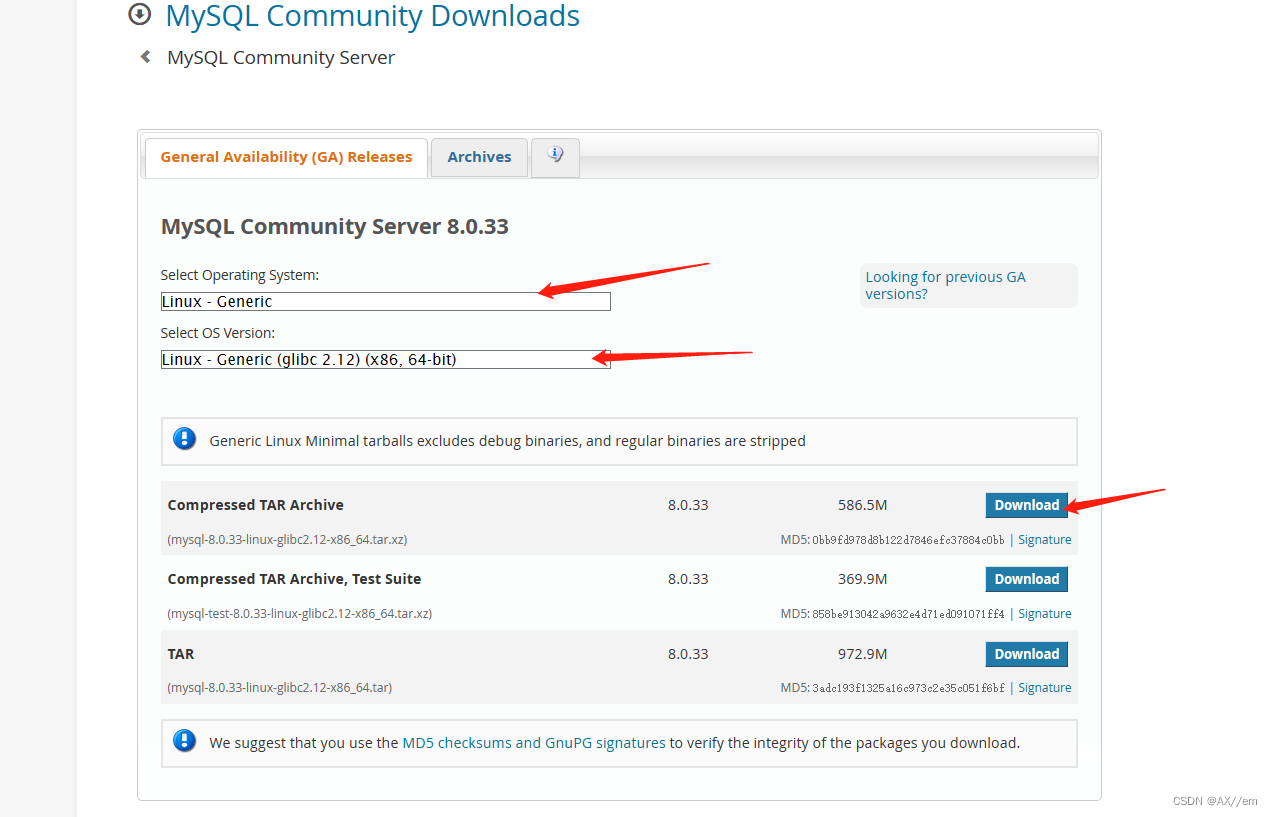
好久不见~让大家久等啦~
本期让我们来揭开vector的面纱,看看它底层是怎么实现的~
目录
一、STL定义vector的源码分析:
二、vector的模拟实现
2.1 vector框架的搭建(一些简单功能函数的实现)
2.2 迭代器失效问题
2.2.1 实现insert函数遇到的迭代器失效问题
2.2.2 实现erase函数遇到的迭代器失效问题
2.3 带模版的构造函数的实现
2.4 vector的深浅拷贝问题
三、vector实现全部代码
一、STL定义vector的源码分析:
我们先来看一看STL定义vector的源码:
template <class T, class Alloc = alloc>
class vector {
public:
typedef T value_type;
typedef value_type* pointer;
typedef const value_type* const_pointer;
typedef value_type* iterator;
typedef const value_type* const_iterator;
typedef value_type& reference;
typedef const value_type& const_reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
protected:
typedef simple_alloc<value_type, Alloc> data_allocator;
iterator start;
iterator finish;
iterator end_of_storage;
};
这三个成员变量(start,finish,end_of_storage),它们到底用来干嘛的?别急,我们先来看到它的无参构造函数:
vector() : start(0), finish(0), end_of_storage(0) {}
从中我们可以看出要想模拟实现vector必须得有start,finish,end_of_storage这三个成员,而且它们最初的类型是T*,只不过被重定义为了iterator。
现在我们来画一张图,解释一下start,finish,end_of_storage这三个指针类型的迭代器到底是干嘛的:
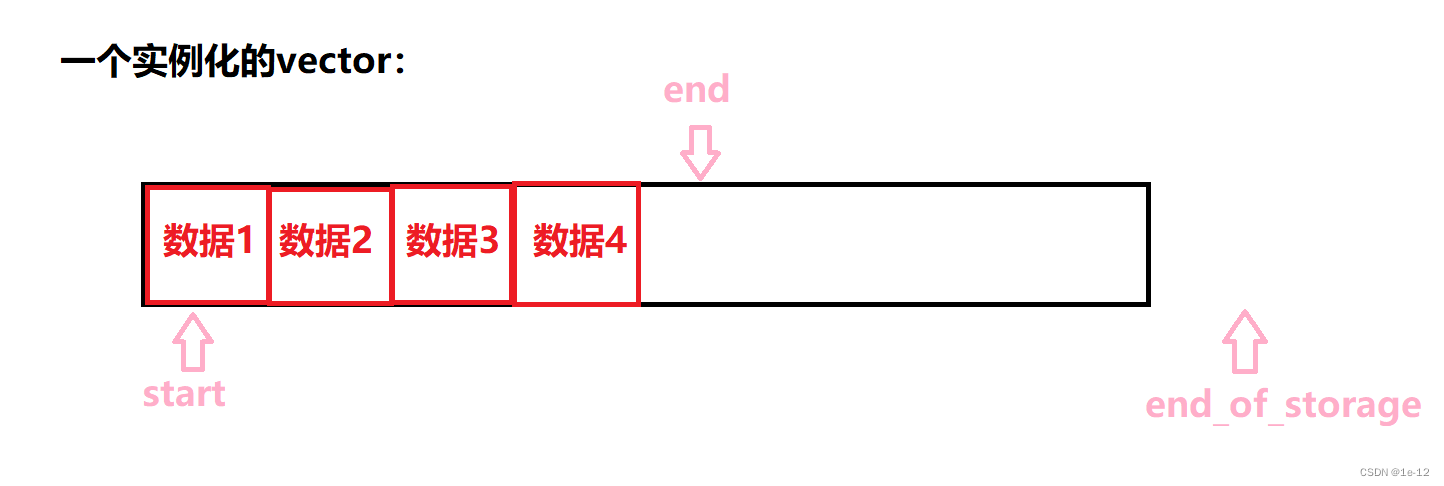
我们可以看到:
● start和finish用于确定vector中存储的元素的范围,即[start, finish)。
● end_of_storage用于确定vector分配的内存空间的范围,即[start, end_of_storage)。
● 当vector中的元素个数达到end_of_storage时,需要重新分配更大的内存空间,然后将原来的元素拷贝到新的内存空间中,同时更新start、finish和end_of_storage的值。
通过这三个指针类型的迭代器,我们可以方便地获取vector中的元素,并进行遍历和操作
明白了其底层原理后,我们就可以尝试模拟实现一下vector了
二、vector的模拟实现
2.1 vector框架的搭建(一些简单功能函数的实现)
我们先来搭建一个vector的框架,废话少说,我们运用数据结构的知识快速构建:
namespace lhs
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
//构造函数
vector()
:_start(nullptr),
_finish(nullptr),
_end_of_storage(nullptr)
{}
vector(size_t n, const T& val = T())
:_start(nullptr),
_finish(nullptr),
_end_of_storage(nullptr)
{
reserve(n);
for (int i = 0; i < n; ++i)
{
push_back(val);
}
}
//析构
~vector()
{
delete[] _start;
_start = nullptr;
_finish = nullptr;
_end_of_storage = nullptr;
}
size_t size()const//返回有效数据个数
{
return _finish - _start;
}
size_t capacity()const//返回容量大小
{
return _end_of_storage - _start;
}
bool empty()const//检查是否为空
{
return _start == _finish;
}
void reserve(size_t n)//扩容
{
if (n > capacity())//防止传入的n小于实际容量
{
T* temp = new T[n];
if (_start)//存有有效数据就进行拷贝
{
memcpy(temp, _start, sizeof(T) * size());
delete[] _start;
}
_finish = temp + size();//先更改_finish,避免_strat更改后影响size函数
_start = temp;
_end_of_storage = _start + n;
}
}
void resize(size_t n, T val = T())//改变size,并用val来填充扩充部分,注意这里的val默认是其默认构造的值
//因为T类型不确定,所以使用构造函数
{
assert(n >= 0);
if (n < size())//n<size就相当于删除数据
{
_finish = _start + n;
}
else
{
if (n > capacity())//检查是否需要扩容
{
reserve(n);
}
while (_finish != _start + n)
{
*_finish = val;
++_finish;
}
}
}
void push_back(const T& x)//尾插
{
if (_finish == _end_of_storage)//判断是否需要扩容
{
reserve(capacity() == 0 ? 4 : capacity() * 2);//扩容时要注意容量是否为0
}
*_finish = x;//插入新元素
++_finish;
}
void pop_back()//尾删
{
assert(!empty());//vector不能为空
--_finish;
}
//迭代器
iterator begin()
{
return _start;
}
const_iterator begin()const
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator end()const
{
return _finish;
}
//运算符重载
T& operator[](size_t pos)
{
return *(_start + pos);
}
const T& operator[](size_t pos)const
{
return *(_start + pos);
}
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};
}这里要注意两个地方:
● reserve:在这个函数内先改变_finish的指向,防止_start改变_finish没变导致size()函数的返回值出错。
● resize:这个函数有个形参缺省用到了其默认构造函数,自定义类型是有构造函数的,那假如T是内置类型呢?内置类型也有构造函数吗?答案是没有的,但是C++为了匹配模版,对于内置类型编译器可以自动识别并赋值。
架子搭完我们继续深入
2.2 迭代器失效问题
2.2.1 实现insert函数遇到的迭代器失效问题
我们现在来实现一下insert函数的功能:
void insert(iterator pos, const T& val)//在pos位置插入val
{
assert(pos >= _start);
assert(pos < _finish);
if (_finish == _end_of_storage)//判断是否需要扩容
{
reserve(capacity() == 0 ? 4 : capacity() * 2);//扩容时要注意容量是否为0
}
//将pos位置之后的元素后移一位
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
//在pos位置插入val
*pos = val;
++_finish;
}
这函数乍一眼看没啥问题,下面我们来测试一下:
void Test4()
{
lhs::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.insert(v.begin(), 99);
for (auto x : v)
{
std::cout << x << ' ';
}
std::cout << std::endl;
}

没啥问题啊,我们再来试一下:
void Test4()
{
lhs::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
//v.push_back(5);
v.insert(v.begin(), 99);
for (auto x : v)
{
std::cout << x << ' ';
}
std::cout << std::endl;
}

咦?这是怎么回事?这次测试和上次测试唯一区别就是一个vector尾插了4个元素一个尾插了5个元素啊?
我们可以发现我们搭建的vector的扩容机制是超过了四个元素就会扩容一倍到八个元素的容量,很显然上一次测试我们的v本身有5个元素,在使用insert函数插入数据时不需要扩容,而在这一次测试中v本身只有4个元素,在使用insert函数插入数据时需要扩容。
难道是扩容出了问题?仔细想一想,扩容本身是没问题的,可是扩容时要进行空间的重新分配,重新分配完的空间的地址会发生变化啊!可是我们传入的pos迭代器所指向的位置没有改变,指向的还是原来旧空间的位置,这时pos迭代器不就失效了嘛~
那我们现在来解决这个问题,在扩容后要重新更新pos所指向的空间:
void insert(iterator pos, const T& val)//在pos位置插入val
{
assert(pos >= _start);
assert(pos < _finish);
if (_finish == _end_of_storage)//判断是否需要扩容
{
size_t len = pos - _start;//记录pos的相对于_start的相对位置
reserve(capacity() == 0 ? 4 : capacity() * 2);//扩容时要注意容量是否为0
pos = _start + len;//扩容完更新pos
}
//将pos位置之后的元素后移一位
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
//在pos位置插入val
*pos = val;
++_finish;
}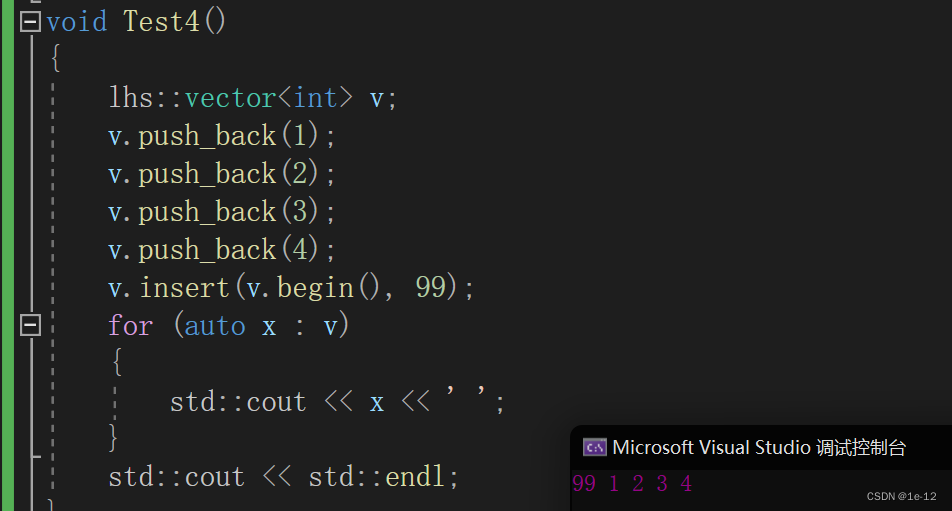
测试通过~
函数内部的迭代器失效问题是解决了,可是我们难免遇到这种情况:
void Test4()
{
lhs::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
lhs::vector<int>::iterator pos = v.begin() + 2;
v.insert(pos, 99);
for (auto x : v)
{
std::cout << x << ' ';
}
std::cout << std::endl;
++(*pos);
for (auto x : v)
{
std::cout << x << ' ';
}
std::cout << std::endl;
}在我们使用完pos迭代器进行insert之后,再将pos所指向的位置进行了++,而insert函数在内部更新pos形参是不会影响外部实参pos的,这样外部的pos就成了一个野指针:

我们可以发现运行结果是有问题的
为了解决这种情况,我们可以让insert函数返回更新之后pos的值:
iterator insert(iterator pos, const T& val)//在pos位置插入val
{
assert(pos >= _start);
assert(pos < _finish);
if (_finish == _end_of_storage)//判断是否需要扩容
{
size_t len = pos - _start;//记录pos的相对于_start的相对位置
reserve(capacity() == 0 ? 4 : capacity() * 2);//扩容时要注意容量是否为0
pos = _start + len;//扩容完更新pos
}
//将pos位置之后的元素后移一位
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
//在pos位置插入val
*pos = val;
++_finish;
//返回pos,避免更新后所带来的影响
return pos;
}下面,我们接受其返回值重新测试一下:
void Test4()
{
lhs::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
lhs::vector<int>::iterator pos = v.begin() + 2;
pos = v.insert(pos, 99);
for (auto x : v)
{
std::cout << x << ' ';
}
std::cout << std::endl;
++(*pos);
for (auto x : v)
{
std::cout << x << ' ';
}
std::cout << std::endl;
}
这就对了嘛~
从这里我们可以从根本上理解STL库中的迭代器失效的问题了,在我们使用完迭代器之后一定要注意!
2.2.2 实现erase函数遇到的迭代器失效问题
下面我们来实现一下erase函数的功能:
void erase(iterator pos)//删除pos位置的数据
{
assert(pos >= _start);
assert(pos < _finish);
//将pos位置之后的元素前移一位
iterator begin = pos + 1;
while (begin < _finish)
{
*(begin - 1) = *begin;
++begin;
}
--_finish;
}测试一下:
void Test5()
{
lhs::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
for (auto x : v)
{
std::cout << x << ' ';
}
std::cout << std::endl;
lhs::vector<int>::iterator pos = v.begin() + 4;
v.erase(pos);
for (auto x : v)
{
std::cout << x << ' ';
}
std::cout << std::endl;
}

结果是正确的
但是我们用完erase后再对pos进行访问呢?
void Test5()
{
lhs::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
for (auto x : v)
{
std::cout << x << ' ';
}
std::cout << std::endl;
lhs::vector<int>::iterator pos = v.begin() + 4;
v.erase(pos);
for (auto x : v)
{
std::cout << x << ' ';
}
std::cout << std::endl;
std::cout << ++(*pos);//越界访问
}

我们可以看到,当我们删除第五个元素后,pos还指向一个非法的空间,这时我们再对pos进行访问就越界了,这是不合理的,也就是说在使用完erase后pos这个迭代器失效了
那当我们可以像insert函数一样,让erase函数返回传入pos位置的后一个元素的位置:
iterator erase(iterator pos)//删除pos位置的数据
{
assert(pos >= _start);
assert(pos < _finish);
//将pos位置之后的元素前移一位
iterator begin = pos + 1;
while (begin < _finish)
{
*(begin - 1) = *begin;
++begin;
}
--_finish;
//返回pos
if (pos != _finish)
return pos;
else
return nullptr;
}
2.3 带模版的构造函数的实现
我们现在来写一个构造函数,这个构造函数可以接受任意类型的迭代器,并将迭代器区间的数据储存在我们自己的vector里面:
template<class InputIterato>
vector(InputIterato begin, InputIterato end)
:_start(nullptr),
_finish(nullptr),
_end_of_storage(nullptr)
{
while (begin != end)
{
push_back(*begin);
++begin;
}
}测试一下:
void Test7()
{
std::string str("Hello");
lhs::vector<char> v1(str.begin(), str.end());
for (auto x : v1)
{
std::cout << x << ' ';
}
std::cout << std::endl;
int arr[] = { 10,50,89,55 };
lhs::vector<int> v2(arr, arr + 4);
for (auto x : v2)
{
std::cout << x << ' ';
}
std::cout << std::endl;
}

我们可以看到我们实现的vector可以接收如何类型的迭代器了,甚至是数组(数组传参本身就是地址)
2.4 vector的深浅拷贝问题
最后我们从实现其拷贝构造函数入手,分析一下vector的深浅拷贝问题:
vector(const vector<T>& val)
{
_start = new T[val.capacity()];
memcpy(_start, val._start, sizeof(T) * val.size());
_finish = _start + val.size();
_end_of_storage = _start + val.capacity();
}
我们先来用上面写的拷贝构造函数来测试一下:
void Test8()
{
int arr[] = { 10,50,89,55 };
lhs::vector<int> v1(arr, arr + 4);
lhs::vector<int> v2(v1);
for (auto x : v2)
{
std::cout << x << ' ';
}
std::cout << std::endl;
}
很好,结果令人满意~
再来试试高级一点的:
void Test8()
{
int arr[] = { 10,50,89,55 };
lhs::vector<int> v1(arr, arr + 4);
lhs::vector<int> v2(v1);
for (auto x : v2)
{
std::cout << x << ' ';
}
std::cout << std::endl;
std::string str("Hello");
lhs::vector<std::string> v3(3, str);
lhs::vector<std::string> v4(v3);
for (auto x : v3)
{
std::cout << x << ' ';
}
std::cout << std::endl;
}
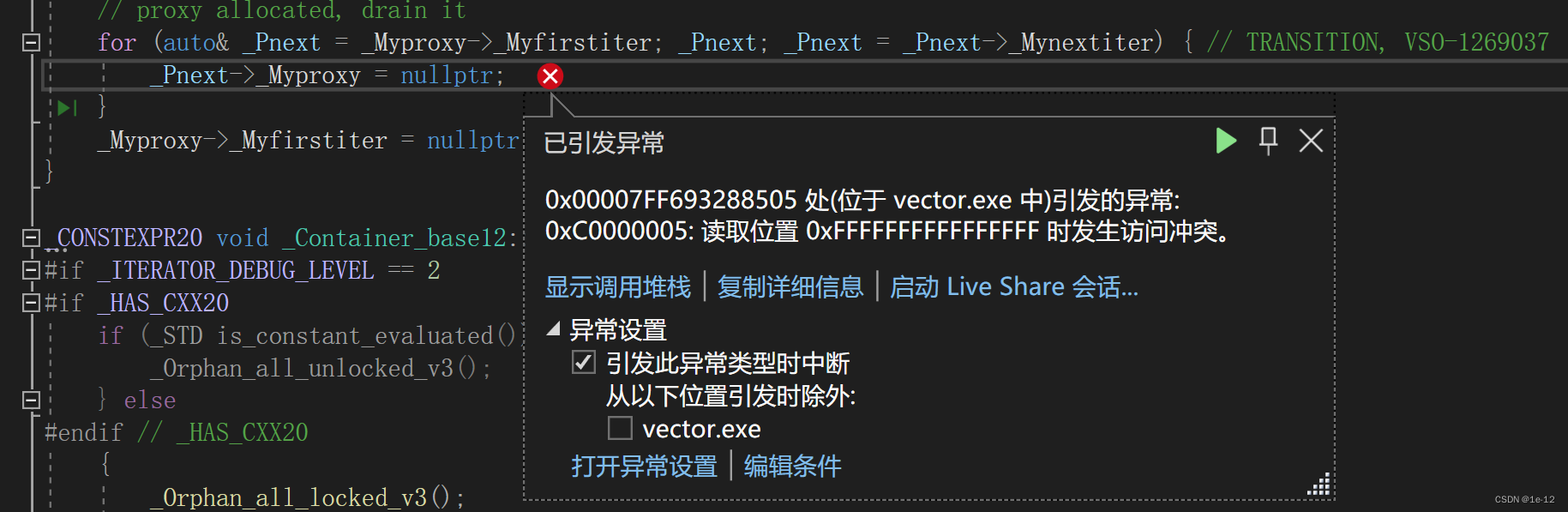
咦?报错了?怎么拷贝构造vector<string>类型的数据就出错了呢?
原因都是memcpy惹的祸,memcpy只能继续浅拷贝,对于string类型的数据只是将其内部成员_str的地址简单的进行了赋值,实际并没有另开空间去存储,所以导致v3和v4所存储的srting元素指向的同一块空间,释放空间时会重复释放导致报错:
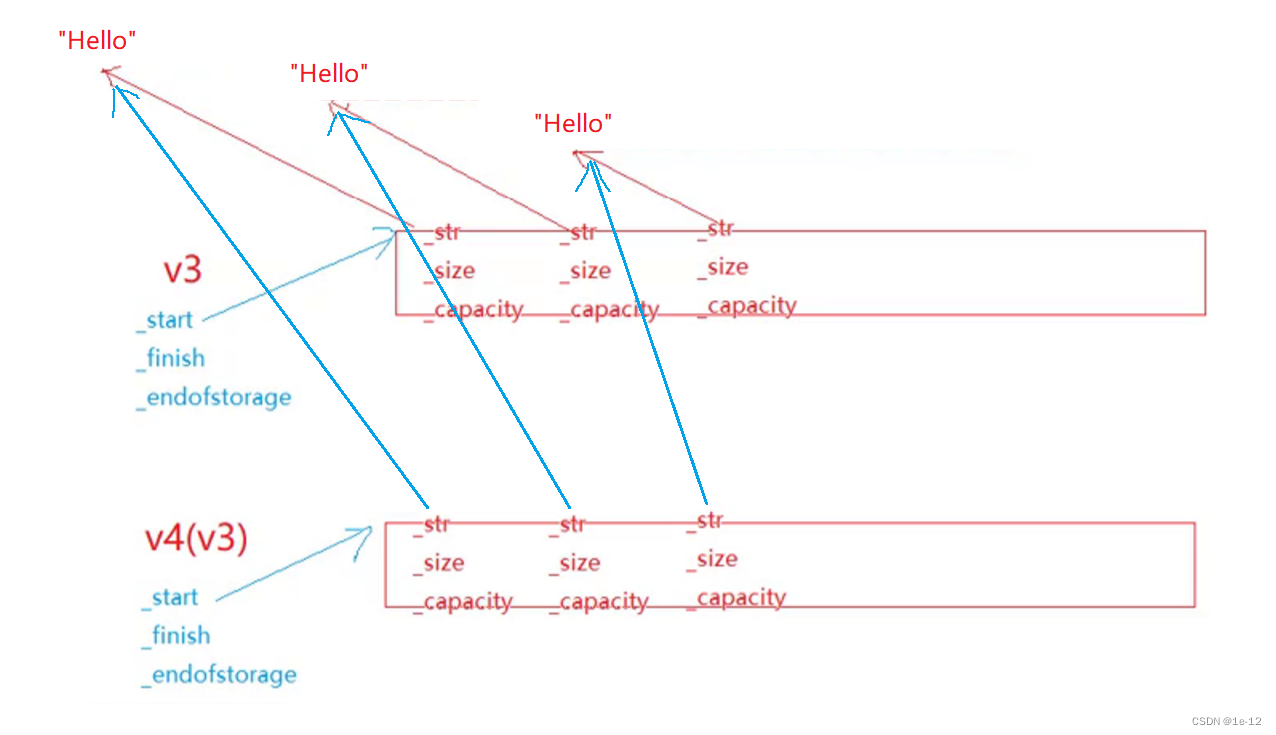
这样子我们自己手动来进行深拷贝:
vector(const vector<T>& val)
{
_start = new T[val.capacity()];
for (size_t i = 0; i < val.size(); ++i)//深度拷贝
{
_start[i] = val._start[i];
}
_finish = _start + val.size();
_end_of_storage = _start + val.capacity();
}
上面将_start一一赋值,如果_start是自定义类型的话就会调用相对应的拷贝构造函数进行深拷贝了~
测试一下:

成功运行~
那这样子说,我们之前实现的reserve函数里面用的是memcpy进行的浅拷贝,这样子也会出错的,下面我们来改进一下:
void reserve(size_t n)//扩容
{
if (n > capacity())//防止传入的n小于实际容量
{
T* temp = new T[n];
if (_start)//存有有效数据就进行拷贝
{
for (size_t i = 0; i < size(); ++i)//深拷贝
{
temp[i] = _start[i];
}
delete[] _start;
}
_finish = temp + size();//先更改_finish,避免_strat更改后影响size函数
_start = temp;
_end_of_storage = _start + n;
}
}
三、vector实现全部代码
#include <iostream>
#include <assert.h>
namespace lhs
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
//构造函数
vector()
:_start(nullptr),
_finish(nullptr),
_end_of_storage(nullptr)
{}
vector(size_t n, const T& val = T())
:_start(nullptr),
_finish(nullptr),
_end_of_storage(nullptr)
{
reserve(n);
for (int i = 0; i < n; ++i)
{
push_back(val);
}
}
vector(int n, const T& val = T())
:_start(nullptr),
_finish(nullptr),
_end_of_storage(nullptr)
{
reserve(n);
for (int i = 0; i < n; ++i)
{
push_back(val);
}
}
template<class InputIterato>
vector(InputIterato begin, InputIterato end)
:_start(nullptr),
_finish(nullptr),
_end_of_storage(nullptr)
{
while (begin != end)
{
push_back(*begin);
++begin;
}
}
//拷贝构造
vector(const vector<T>& val)
{
_start = new T[val.capacity()];
for (size_t i = 0; i < val.size(); ++i)//深度拷贝
{
_start[i] = val._start[i];
}
_finish = _start + val.size();
_end_of_storage = _start + val.capacity();
}
//析构
~vector()
{
delete[] _start;
_start = nullptr;
_finish = nullptr;
_end_of_storage = nullptr;
}
size_t size()const//返回有效数据个数
{
return _finish - _start;
}
size_t capacity()const//返回容量大小
{
return _end_of_storage - _start;
}
bool empty()const//检查是否为空
{
return _start == _finish;
}
void reserve(size_t n)//扩容
{
if (n > capacity())//防止传入的n小于实际容量
{
T* temp = new T[n];
if (_start)//存有有效数据就进行拷贝
{
for (size_t i = 0; i < size(); ++i)//深拷贝
{
temp[i] = _start[i];
}
delete[] _start;
}
_finish = temp + size();//先更改_finish,避免_strat更改后影响size函数
_start = temp;
_end_of_storage = _start + n;
}
}
void resize(size_t n, T val = T())//改变size,并用val来填充扩充部分,注意这里的val默认是其默认构造的值
//因为T类型不确定,所以使用构造函数
{
assert(n >= 0);
if (n < size())//n<size就相当于删除数据
{
_finish = _start + n;
}
else
{
if (n > capacity())//检查是否需要扩容
{
reserve(n);
}
while (_finish != _start + n)
{
*_finish = val;
++_finish;
}
}
}
void push_back(const T& x)//尾插
{
if (_finish == _end_of_storage)//判断是否需要扩容
{
reserve(capacity() == 0 ? 4 : capacity() * 2);//扩容时要注意容量是否为0
}
*_finish = x;//插入新元素
++_finish;
}
void pop_back()//尾删
{
assert(!empty());//vector不能为空
--_finish;
}
iterator insert(iterator pos, const T& val)//在pos位置插入val
{
assert(pos >= _start);
assert(pos < _finish);
if (_finish == _end_of_storage)//判断是否需要扩容
{
size_t len = pos - _start;//记录pos的相对于_start的相对位置
reserve(capacity() == 0 ? 4 : capacity() * 2);//扩容时要注意容量是否为0
pos = _start + len;//扩容完更新pos
}
//将pos位置之后的元素后移一位
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
//在pos位置插入val
*pos = val;
++_finish;
//返回pos,避免更新后所带来的影响
return pos;
}
iterator erase(iterator pos)//删除pos位置的数据
{
assert(pos >= _start);
assert(pos < _finish);
//将pos位置之后的元素前移一位
iterator begin = pos + 1;
while (begin < _finish)
{
*(begin - 1) = *begin;
++begin;
}
--_finish;
//返回pos
if (pos != _finish)
return pos;
else
return nullptr;
}
//迭代器
iterator begin()
{
return _start;
}
const_iterator begin()const
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator end()const
{
return _finish;
}
//运算符重载
T& operator[](size_t pos)
{
return *(_start + pos);
}
const T& operator[](size_t pos)const
{
return *(_start + pos);
}
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};
}到这里本期博客就结束了,后期博主会加快更新,正式进入到快车道,冲冲冲~
本期代码量比较大,如有不足还请大佬们指出~