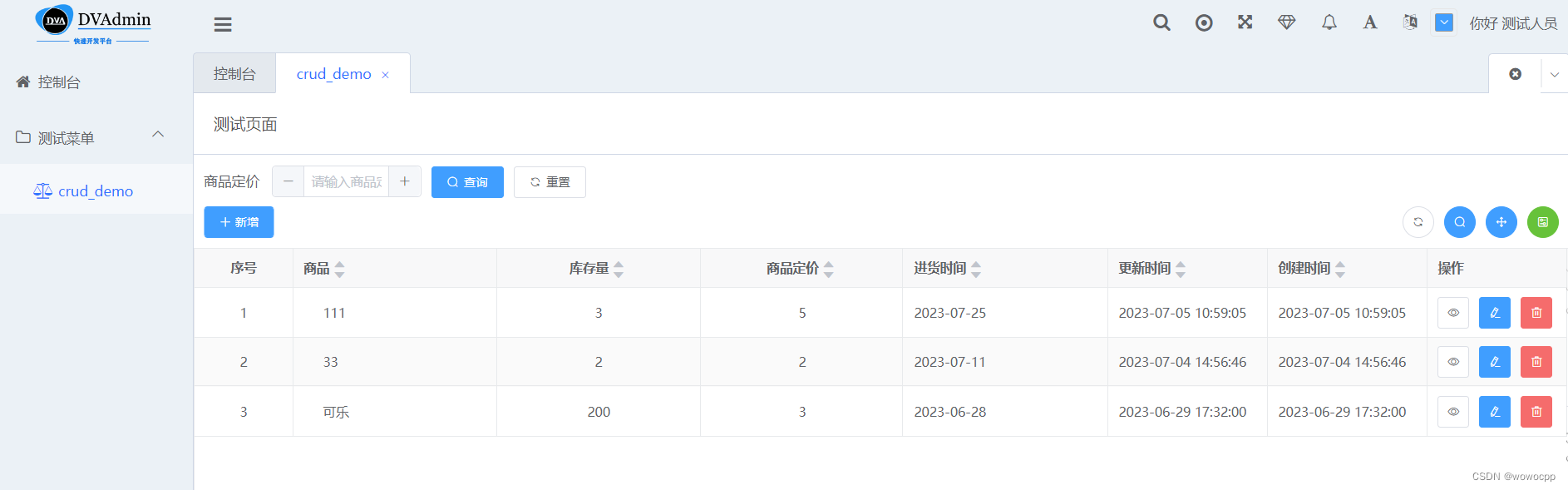
一、前言
本文将向您展示如何使用 R 对卫星图像执行非常基本的 kMeans 无监督分类。我们将在 Sentinel-2 图像的一小部分上执行此操作。
Sentinel-2 是由欧洲航天局发射的一颗卫星,其数据可在此处免费访问。
我要使用的图像显示了 Neusiedl 湖的北部(奥地利维也纳以东)。 该地区以销售、优质葡萄酒和美丽的自然风光(芦苇和受拉姆萨尔公约保护的湿地)而闻名。 我将使用波段 2 - 蓝色、波段 3 - 绿色、波段 4 - 红色和波段 8 - 近红外线进行分类。 图像的外观如下 - 在左侧您可以看到真彩色合成 (432),在右侧可以看到假彩色近红外合成 (843):

Sentinel-2 看到的 Neusiedl 湖。 湖泊周围环绕着芦苇带和密集的农业活动。 在图像的西北部可以看到一片落叶林。
请注意,您可以使用您选择的任何其他图像来执行分类。 代码将保持不变!
二、代码实现
(1)将图像加载到 R 中
要执行无监督图像分类,我们首先需要将图像加载到 R 中。这就像这两行一样简单:
library(raster) #load raster package
image <- stack("path/To/YourImage/stack.tif)如果您没有安装光栅包,请先执行“install.packages(“raster”)”。
(2)分类
如果您以前从未对图像进行过分类或者您是机器学习的新手,那么 kMeans 无监督分类听起来可能会非常混乱和困难。 不用担心! 您实际上只需要大约 3-4 行代码就完成了 🙂 我们只需要“kMeans”函数。 我们需要指定我们想要在图像中“检测”的类的数量,该函数将处理其余部分。 它迭代地浏览图像并寻找所谓的集群(=构成土地覆盖类别的光谱相似区域)。 在我的例子中,我想检测六个类别,让我们看看无监督分类的表现如何:
#execute the kMeans function on the image values (indicated by the squared bracket)
#and search for 6 clusters (centers = 6)
kMeansResult <- kmeans(image[], centers=6)
#create a dummy raster using the first layer of our image
#and replace the values of the dummy raster with the clusters (classes) of the kMeans classification
result <- raster(image[[1]])
result <- setValues(result, kMeansResult$cluster)
#plot the result
plot(result)结果是这样的:

默认的可视化效果不是我见过的最好的,但是好吧……这是一个好的开始。 您可以看到六种不同的颜色,每种颜色对应一个光谱相似的区域。
无监督 kMeans 分类之后的第一步也是必要的一步是通过算法将类名分配给检测到的集群。 让我们看看我们的分类图像并将其与上面的卫星场景进行比较,这将帮助我们为检测到的集群/类分配名称:
- 1和2表示芦苇或森林
- 水被分类为3
- 农业大致由 4,5 和 6 描述。
让我们改变绘图的颜色,看看它看起来像什么:
plot(result, col=c("darkgreen", "darkgreen","blue",
"orange", "orange","orange"))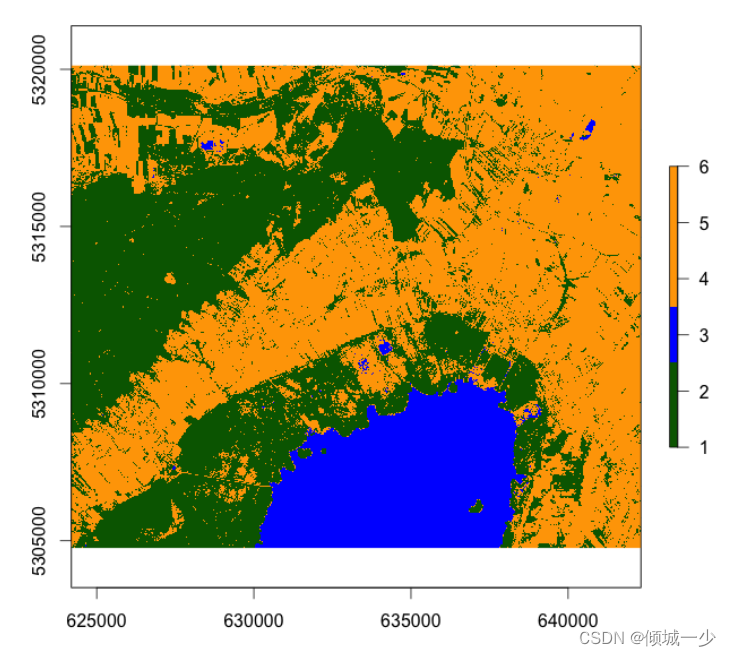
具有类别着色的无监督 kMeans 分类。 深绿色表示芦苇和森林,橙色表示农业,蓝色表水。
三、结论
我们可以看到,水被分类器很好地捕捉到了,农业也被很好地检测到了。 然而,芦苇(湖周围)和森林(湖西北部)似乎混合在一起,我们可以看到这两个类别之间存在很大的混淆。 无监督 kMeans 分类器是检测图像内部模式的一种快速简便的方法,通常用于进行第一个原始分类。 它因其良好的性能而广受欢迎,并且由于其应用不需要样本点(与监督分类相反)而被广泛使用。 然而,我的意图是检测六个不同的类别,而该算法只能大致区分三个。 通过增加“中心”参数,可能会检测到更多类别。