个人学习笔记(整理不易,有帮助点个赞)
笔记目录:学习笔记目录_pytest和unittest、airtest_weixin_42717928的博客-CSDN博客
目录
一:了解常用组件
二:创建测试计划
1)先新建一个测试计划
2)创建线程组
二:配置元件
1)HTTP请求默认值
2)HTTP消息头管理器
3)参数化配置元件(csv data set config)
4)创建用户定义的变量
三:监听器:如聚合报告,查看结果树
1)聚合报告
2)查看结果树
四:逻辑控制器
1)if控制器
2)仅一次控制器
3)吞吐量控制器
五:取样器
1)HTTP请求
六:定时器
1)固定吞吐量定时器
2)固定定时器
七:前置处理器
八:后置处理器
1)正则表达式提取器
2)BeanShell后置处理器
九:断言
1)响应断言
2)Size断言
3)BeanShell断言
一:了解常用组件

一个jmx测试脚本对应一个测试计划;一个测试计划至少包含一个线程组;
多个线程组之间可并行运行,也可串行运行
二:创建测试计划
1)先新建一个测试计划

任何类型的测试都要先创建线程组(任何内容都放在线程组中),一个线程组可看作一个虚拟用户组,其中的每个线程模拟为一个虚拟用户
2)创建线程组
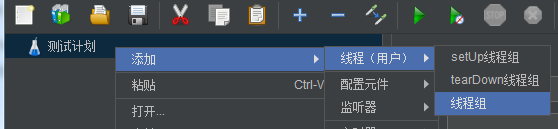
- setup线程组:用于执行预测试操作。这些线程的行为完全像一个正常的线程组元件;类似LR中的init
如:测试数据库,用于执行打开数据库连接操作
- teardown线程组:用于执行测试后动作。这些线程的行为完全像一个正常的线程组元件。类似LR中的end
如:测试数据库,用于执行关闭数据库连接操作
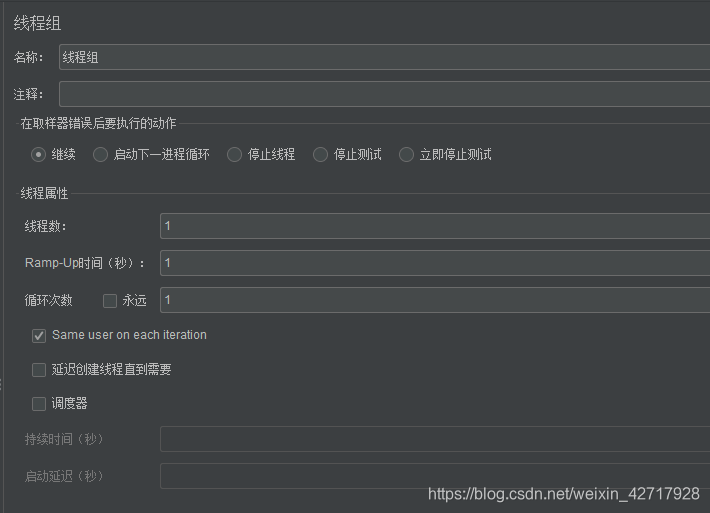
在取样器错误后要执行的动作:就是在错误之后要如何执行
- Contiune:继续。某一个请求遇到错误后,其他请求继续执行。在大量用户并发的时候,某个请求失败属正常现象
- Start Next Thread Loop:遇到错误后面的请求将不再执行,等下一轮再开始执行。例如线程组中包含登录和点赞2个请求,若登录请求失败,点赞请求将不再执行,等下一次重新迭代,从登录开始执行
- Stop Thread:遇到错误就停止线程再也不执行了。例如线程组中有50个线程,其中某一个线程的某个请求遇到错误即停止线程不再执行,剩下49个线程继续执行。若线程错误的比较多,剩余的线程就较少,此时负载数量就不足了,测试结果不满足测试要求,因此一般不会勾选此项。
- Stop Test:某个线程某个请求遇到错误,停止所有线程,也就是停止整个测试,但是线程中的余下的请求还是会执行完再停止。例如线程1中包含登录和点赞2个请求,其他线程遇到错误,现在要全部停下来,线程1点赞请求还是会执行,然后再停止测试。
- Stop Test Now:遇到错误立即停止所有线程,即整个测试。
- 线程数:一个线程代表一个虚拟用户
- Ramp-up Period (in Seconds):设置线程启动时长,单位s
假设线程数是50,启动时长是2s,则表示2s启动50个线程(50/2),那么平均每秒启动25个线程
- 循环次数(Loop Count):每个线程发送请求的次数
假设这个线程组有3个HTTP请求,循环是3,则表示一个线程会发送9个HTTP请求;如果选择永久(Infinite),所有线程无限循环发送请求;如果选择了永久且调度器设置中设置了持续时间,则会在持续时间到达后结束循环
- Delay Thread creation until needed:延迟线程的创建直到需要
此项一般与Ramp-up Period (in Seconds)一起使用
假设线程数为10,Ramp-up Period (in Seconds)是100,则不选择此项,测试会每隔10秒启动1个线程,那么100秒后会有1~10个线程运行
(为什么会出现1~9的情况?那是因为线程执行完成时间可能低于100秒,这样就导致设置的10个并发场景并未完全生效,当然线程执行时间大于100秒的话可不选)
如果选择此项,那么线程组会每隔10秒创建1个线程,但是不执行,等100秒后,10个线程全部创建完成,再同时执行
- 调度器
持续时间:表示线程组测试的持续时间。如果选择了永久(Infinite)且调度器设置中设置了持续时间,则会在持续时间到达后结束循环。这个时间不要小于Ramp-up Period
启动延迟:表示启动测试后多久开始创建线程组,常用于定时
ps:
1:线程组不使用可以禁用掉
2:时间和线程数的要求,一方面来自甲方要求;另一方面根据业务来定,假设一天有10000用户,最高峰期(性能测试一般看这个),10分钟内有1000用户,则1分钟100个用户,1秒大概1个用户,那在测试的时候可以提高这个值,比如1秒10用户
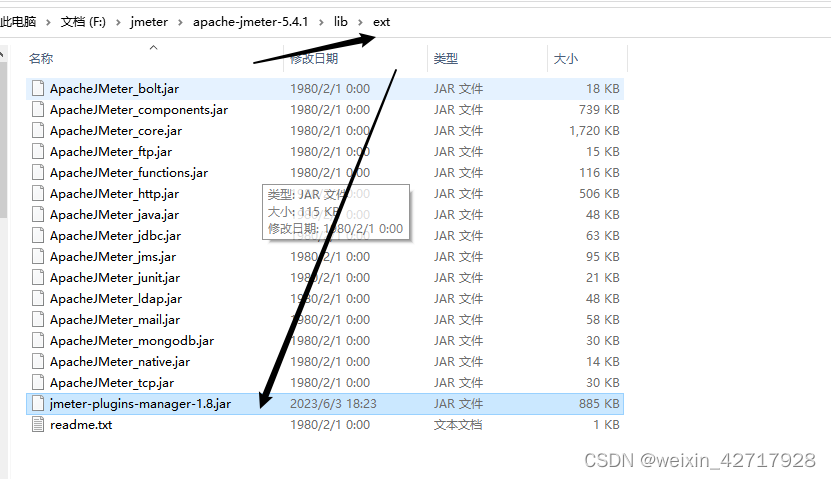
3:如果要测试阶段式压力的情况,即从某个值开始不断增加压力,直至到达某个指定值,然后持续运行一段时间,这个时候需要安装插件
下载地址:Install :: JMeter-Plugins.org
下载jmeter-plugins-manager-1.8.jar,丢到lib\ext下,重启即可

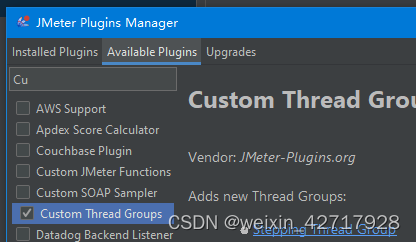
详情使用可参考:Jmeter-plugins-manager插件的安装与使用_晒不黑的黑煤球的博客-CSDN博客
二:配置元件
1)HTTP请求默认值

http:使用80端口;https:使用443端口
一般用作全局的配置,后面同样IP地址和端口的请求就不用重复填了
2)HTTP消息头管理器
如前端要给后端验证cookie/token之类的信息,就是将其添加到消息头里的
| Header | 解释 | 示例 |
|---|---|---|
| Accept | 客户端能接受的响应内容类型 | Accept: text/plain, text/html |
| Accept-Charset | 浏览器可以接受的字符编码集 | Accept-Charset: utf-8 |
| Accept-Encoding | 可接受的响应内容的编码方式 | Accept-Encoding: compress, gzip |
| Accept-Language | 可接受的响应内容的语言列表 | Accept-Language: en,zh |
| Accept-Ranges | 可以请求网页实体的一个或者多个子范围字段 | Accept-Ranges: bytes |
| Authorization | HTTP授权的授权证书 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Cache-Control | 指定请求和响应遵循的缓存机制 | Cache-Control: no-cache |
| Connection | 客户端/浏览器优先使用的连接类型(HTTP 1.1默认进行持久连接) | Connection: close Connection:keep-alive |
| Cookie | HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器 | Cookie: $Version=1; Skin=new; |
| Content-Length | 以八进制表示的请求体的长度 | Content-Length: 348 |
| Content-Type | 请求体的MIME类型 | Content-Type: application/x-www-form-urlencoded |
| Date | 请求发送的日期和时间 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| Expect | 客户端要求服务器做出的特定行为 | Expect: 100-continue |
| From | 发出请求的用户的Email | From: user@email.com |
| Host | 服务器的域名和端口号,如果端口号是80可省略 | Host: www.zcmhi.com |
| If-Match | 仅当客户端提供的实体与服务器对应的实体相匹配时,才能进行对应的操作。 主要用于像PUT这样的方法中,仅当从用户上次更新某个资源后,该资源未被修改的情况下,才更新该资源 | If-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Modified-Since | 如果请求的部分在指定时间之后被修改则请求成功,未被修改则返回304代码 | If-Modified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| If-None-Match | 如果内容未改变返回304代码,参数为服务器先前发送的Etag,与服务器回应的Etag比较判断是否改变 | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Range | 如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体。参数也为Etag | If-Range: “737060cd8c284d8af7ad3082f209582d” |
| If-Unmodified-Since | 只在实体在指定时间之后未被修改才请求成功 | If-Unmodified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| Max-Forwards | 限制信息通过代理和网关转发的次数 | Max-Forwards: 10 |
| Pragma | 用来包含实现特定的指令 | Pragma: no-cache |
| Proxy-Authorization | 连接到代理的授权证书 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Range | 只请求实体的一部分,指定范围 | Range: bytes=500-999 |
| Referer | 先前网页的地址,当前请求网页紧随其后,即来路 | Referer: http://www.zcmhi.com/archives/71.html |
| TE | 客户端愿意接受的传输编码,并通知服务器接受接受尾加头信息 | TE: trailers,deflate;q=0.5 |
| Upgrade | 要求服务器将协议升级到一个高版本(如果支持) | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent | 浏览器的身份标识字符串 | User-Agent: Mozilla/5.0 (Linux; X11) |
| Via | 通知中间网关或代理服务器地址,通信协议 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | 关于消息实体的警告信息 | Warn: 199 Miscellaneous warning |
注意:
1)Jmeter支持添加多个消息头管理器,会合并成一个消息头跟随请求提交,而且不同管理器内有名称相同的消息头条目存在时,顺序靠前的管理器的消息头条目会覆盖后面的
2)Jmeter中有cookie manager和cache manager,如果要模拟客户端无缓存场景,需要组件选择“每次反复清除cookies”和“clean cache each iteration”
3)参数化配置元件(csv data set config)
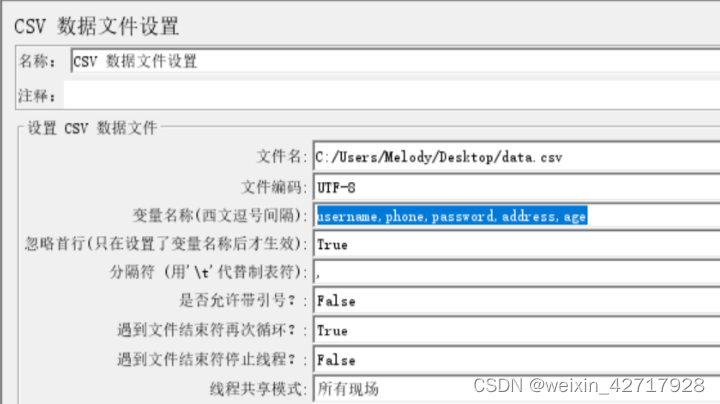
参数:
文件名(Filename) : 包含参数文件路径
1、这里要包括文件的路径,在4.0版本中可以点击右侧的浏览按钮选择文件,会自动带上文件的绝对路径
2、当csv文件在JMeter的bin目录或脚本目录时,只需文件名
3、使用相对路径时,JMeter默认先去bin目录下查找,然后去脚本目录下查找
文件编码:如utf-8
变量名称:csv文件中各列的参数名称,多个参数用逗号隔开
Ignore first line:忽略首行(只在变量名称不为空时才生效)
如果文件中第一行为参数名称,选择true
如果文件中第一行为参数值,选择false
此项只在设置了变量名称后才生效
Delimiter:分隔符,“\t”表示tab键
Allow quoted data?:是否允许带引号
当为False时,csv文件中有引号,但变量实际引用后会变成自动去掉引号
当为True时,csv文件中有引号,则变量引用后也带引号
Recycle on EOF?:遇到文件结束符是否再次循环
True—继续从文件第一行开始读取,False—不再循环;
此项与Stop thread on EOF为互斥关系,若Recycle on EOF设置为True,则Stop thread on EOF需要设置为False
Stop thread on EOF?:遇到文件结束符是否停止线程
True—停止,False—不停止;
注意:当Recycle on EOF设置为True时,此项设置无效
Sharing mode:线程共享模式
所有线程(All threads):测试计划中所有线程共享csv文件中的记录(所有线程按照顺序取文件中的记录)
当前线程组(Current thread group)::线程组中的所有线程共享csv文件中的记录(每个线程依次读取csv数据)
当前线程(Current thread):每个线程各自独立使用csv的记录
4)创建用户定义的变量
比如要用到的全局变量
三:监听器:如聚合报告,查看结果树
1)聚合报告

Label:每个JMeter的element的Name值,例如HTTP Request的Name
样本:发出请求数量;模拟10个用户,循环10次,所以显示了100
平均值(重点):平均响应时间(单位:ms);总运行时间/发送到服务器的请求数
默认是单个Request的平均响应时间,当使用了事务控制器(Transaction Controller)时,也可以以Transaction为单位显示平均响应时间
中位数:50%的用户响应时间小于这个值
95%百分位(重点):95%的用户响应时间小于这个值
99%百分位:99%的用户响应时间小于这个值
最小值:用户响应时间最小值
最大值:用户响应时间最大值
异常%:测试出现的错误请求数量百分比;请求的错误率 = 错误请求的数量/请求的总数;若出现错误就要看服务端的日志查找定位原因
吞吐量:Throughput简称TPS,吞吐量,默认情况下表示每秒处理的请求数,也就是指服务器处理能力,TPS越高说明服务器处理能力越好
KB/sec:每秒从服务器端接收到的数据量
2)查看结果树
用来调试脚本的时候观察请求和响应是否正确
ps:真正压测的时候禁用或者删除该组件,否则会影响性能

四:逻辑控制器
用于控制脚本的执行顺序,目前有2类共17种逻辑控制器
一类是控制测试计划中节点发送请求的逻辑顺序控制器,如if,switch,Loop,Random控制器等
一类是用于组织和控制节点的,如事务,吞吐量控制器等
1)if控制器
默认情况下,条件在初始输入时仅判断一次,但可以选择对控制器中包含的每个可执行请求进行判断
使用建议选择“Interpret C a V E”选项,即将条件解释为变量表达式。通常如果有无法使用变量表达式解释器执行的复杂条件,最好使用Groovy和JEXL解释器
2)仅一次控制器
在循环执行中执行一次仅一次控制器下的请求,然后在接下来的循环执行中将会跳过该控制器下的所有请求
通常用于登录的测试中,仅一次控制器相当于LR中的init初始化事务
3)吞吐量控制器
用于控制其下的子节点的执行次数与负载比例分配

- percent execution:按照百分比来执行
- total executions:按照次数来执行
- Per User(每用户执行次数):当选择total executions时,表示线程数;当选择percent execution,表示线程数*循环次数
1)线程2,循环次数2(样本4)----------------不使用吞吐量控制器的情况下
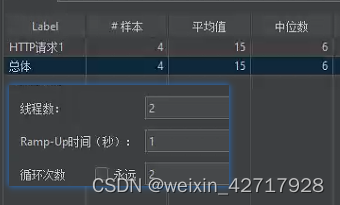
2)线程2,循环次数2;percent execution:25,不勾选Per user(样本1)
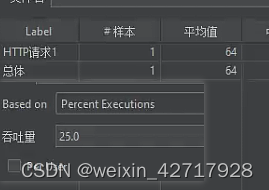
注意:如果还是上述条件,但勾选了per user,则不能生成数据(这样使用的实际意义没搞懂)
如果勾选了per user,但是不填写吞吐量,则样本数量是:线程数*循环次数=2*2=4

3)线程2,循环次数2;total executions:3,不勾选Per user(样本3)
注:吞吐量填写次数超过线程样本数,只会执行到最大值
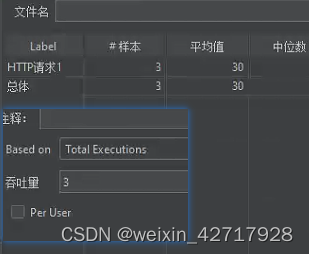
注意:还是上述条件,勾选Per user,结果样本4(这样使用的实际意义没搞懂)
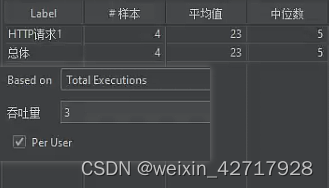
如果勾选了Per user,但是不填写吞吐量,则样本数量是2

Per user勾选后对所有线程数都有效,不勾选仅对单个线程数生效,而且勾选Per user后,当选择T E时,表示线程数;当选择P E时,表示线程数*循环次数
五:取样器
取样器是用来模拟用户操作的,它可以向服务器发送请求以及接收服务器的响应数据
最常见的是HTTP请求和Java请求
1)HTTP请求
常见的有GET和POST
添加HTTP请求
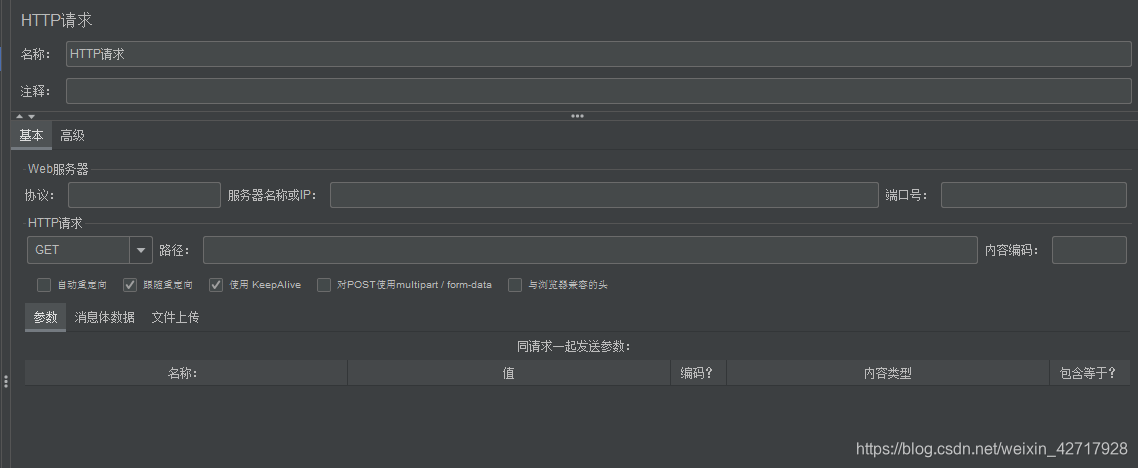
参数说明:
- 协议:如http/https,大小写不敏感,默认http
- 服务器名称或IP:http请求发送的目标服务器域名或者IP,比如http://www.baidu.com
- 端口号:目标服务器的端口号,默认值为80,可不填
- 请求方式:如GTE/POST(参考:HTTP学习(二)_weixin_42717928的博客-CSDN博客)
- 路径:目标的URL路径(不包括服务器地址和端口)
- Content encoding:内容的编码方式(Content-Type=application/json;charset=utf-8)
- 自动重定向:选中该项,发出的http请求得到响应是301/302,jmeter会重定向到新的界面,只能观察到重定向后的最终结果,不会记录重定向的请求和响应内容。此选项用于GET和HEAD请求,不能用于POST和PUT请求
- 跟随重定向:未启用“自动重定向”,该选项才生效。可以观察到整个重定向过程中的所有请求,无论重定向了多少次
- Use keep Alive:jmeter 和目标服务器之间使用 Keep-Alive方式进行HTTP通信(默认选中)
- Use multipart/from-data for HTTP POST :当发送HTTP POST 请求时,使用该项
- 与浏览器兼容的头:使用multipart/form-data时,设置的Content-Type和Content-Transfer-Encoding消息头将无效,仅发送Content-Disposition消息头
- Parameters:请求参数
- Body Data:请求参数,指的是实体参数,常见JSON格式
- Files Upload:从HTML文件获取所有内含的资源。该项被选中时,发出HTTP请求并获得响应的HTML文件内容后还对该HTML文件进行解析,并获取HTML中包含的所有资源

- URL编码:用于2个场景:一种是传递的参数中有特殊字符,如参数aa=bb=cc,不知道表达是“aa”=”bb=cc“”,还是“aa=bb”="cc",避免歧义需要勾选该项。另一种是中文

ps:
如果协议、IP、端口不填则使用HTTP请求默认值,如果填了则使用填好的请求
自动重定向只会跳到最终的页面(一般使用这个),跟随重定向会把中间每一个过程都记录下来
鉴权码一般通过接口获取,或者通过登录生成获取
常见重定向:
1)301:永久性重定向,表示请求的资源已经永久性分配了新的URI,以后使用新的URI。使用Location首部字段表示新的URI地址,浏览器会重新请求一次该URI
2)302:临时性重定向,表示希望用户本次使用新分配的URI
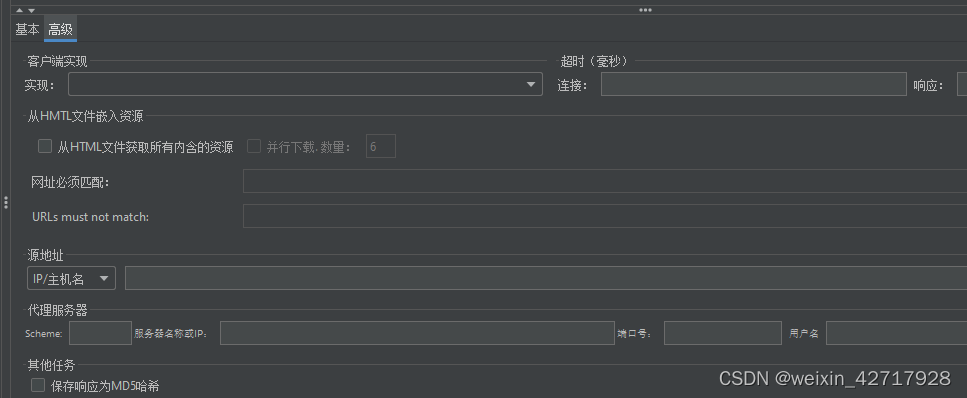
- 实现(Implementation):发送http请求的方式。可选项为Java和HttpClient4,默认为HttpClient4
- 连接(Connect):连接超时时间,单位为毫秒;超时则断言失败
- 响应(Response):响应等待超时时间,单位为毫秒;超时则断言失败
- Source address:用于启用IP欺骗
- 代理服务器:代理访问在此设置
- 保存响应为MD5哈希:保持响应为MD5,设置该项,则响应不会存储在样本结果中。否则将计算并存储数据的32个字符的MD5哈希编码
六:定时器
默认情况下,Jmeter线程在发送请求之间没有间歇,为了真实模拟用户请求情况,定时器用于在用户操作之间设置等待时间
定时器在每个取样器之前执行,无论定时器位置在之前还是之后
执行一个取样器之前,所有当前作用范围内的定时器都会执行,如果要对其中一个取样器生效,需要将定时器作为子节点加入
1)固定吞吐量定时器
用来设置QPS限制,控制给定的取样器发送请求的吞吐量,常用于混合压测过程中同时压测多个接口,这种场景下对每个接口的吞吐量设置一个上限

target Throughput :目标吞吐量
- This thread only:控制每个线程的吞吐量。选择这种模式时,总的吞吐量=设置的目标吞吐量 * 线程的数量
- All active threads:设置的目标吞吐量将分配在每个活跃线程上。每个活跃线程在上一次运行结束后等待合理的时间后再次运行。活跃线程指同一时刻同时运行的线程
- All avtive threads(shared):与All active threads的选项基本相同。唯一区别是,每个活跃线程都会在所有活跃线程上一次运行结束后等待合理的时间后再次运行
- All active threads in current thread group:设置的目标吞吐量将分配在当前线程组的每一个活跃线程上。当测试计划中只有一个线程组时,该选项和All active threads 选项的效果完全相同
- All active threads in current thread group(shared):与All active threads in current thread group 基本相同,唯一的区别是,每个活跃线程都会在所有活跃线程的上一次运行结束后等待合理的时间后再次运行
ps:
该定时器只有在线程组中的线程产生足够多请求的情况下才有意义。因此,即时设置了固定吞吐量定时器的值,也可能由于线程组中的线程数量不够,或者定时器设置不合理等原因,导致总体的QPS不能达到预期目标
如果要将定时器应用于单个定时器,则要将定时器添加为取样器的子元素。在执行取样器之前将应用定时器。如果要在取样器之后应用定时器,则要将定时器添加到下一个取样器
2)固定定时器
使用该项,可以让每个线程在两次请求之间暂停相同的时间
七:前置处理器
用于请求发送之前对请求进行处理,如参数化,加密请求,替换请求等
- 重置解析器:是否重新初始化
- 参数:BeanShell脚本中的变量初始化时可以在这指定值,这里接受变量和字符串数组,如果是字符串数组有两个元素,则元素直接用空格隔开
- 文件名:指定执行的BeanShell脚本
- Script:编写BeanShell脚本,通过BeanShell脚本可访问ctx、vars、props、prev、sampler、log
ctx:访问Jmeter运行时状态,如线程数和线程状态
vars:访问定义的变量
props:访问运行时设置
prev:访问前一个取样器结果
sampler:访问当前取样器
log:写日志
如接口性能测试,需要每次api请求的入参都是变化的
比如有些接口请求参数有时间戳
比如要保证接口请求的安全性,需要请求携带sign入参,且sign是通过加密算法得到
也就是说,这样的接口基本每次请求前需要构建不同的入参数据。因此需要参数化请求入参,BeanShell Preprocessor(BeanShell预处理程序)这样的前置处理器就可以很方便构建参数化入参。
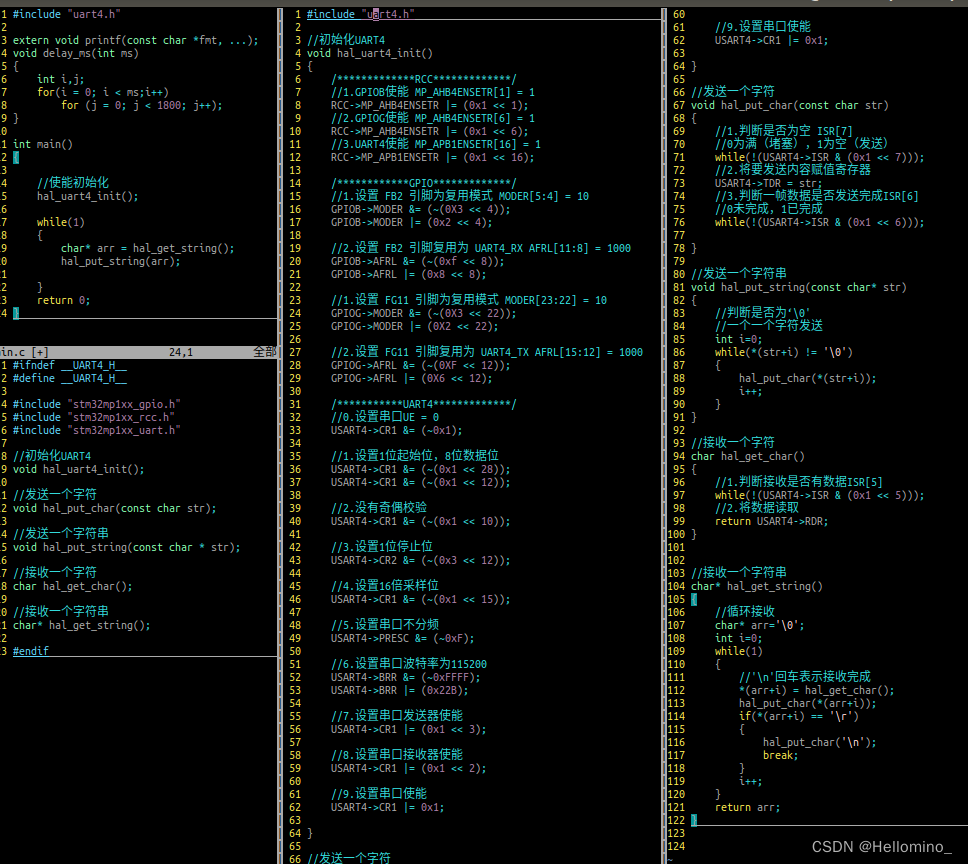
实例:参数化时间戳、参数化sign签名
// 导入MD5加密需要用到的jar包。
import org.apache.commons.codec.digest.DigestUtils;
// 声明你需要拼接的字符串
//String requestTime = "1680089472000"; //生成时间戳
String requestTime = "${__time(,)}"; //生成时间戳
log.info("=====请求时间戳:=====>>"+requestTime);
String yan = "N[8HXx!57Ivy%)#R";
//拼接需要加密的字符串
String str = yan + requestTime;
// 加密已拼接的字符串
String sign = DigestUtils.md5Hex(str);
log.info("=====sign签名:=====>>"+sign);
vars.put("sign",sign); //设置变量,将md5加密后的值传递给变量sign
vars.put("requestTime", requestTime); //将时间传递给变量requestTime如BeanShell脚本中,定义了两个字符串:requestTime 和sign,设置了它们的取值
其中requestTime的值是${__time(,)},该函数可以按当前时间生成时间戳
sign的值是进行了md5加密后生成了一个32位小写的字符串
并将值传给变量requestTime 和sign用于后续接口请求参数化
将脚本中的requestTime 和sign参数引入接口请求中
![]()
八:后置处理器
用于请求发送之后得到服务器响应进行处理
1)正则表达式提取器
接口关联
简单的说就是用前一个请求的数据作为后一个请求的参数的值,比如:
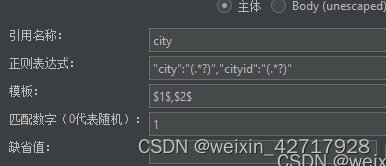
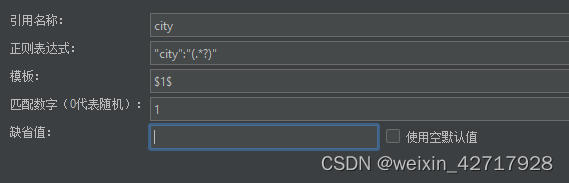
引用名称:其他地方引用提取值的变量名称
模板:表示使用提取到的第几个值。如果前面的正则表达式提取了不止一个参数(多个括号括起来),那么这里需要指定参数的组别,格式为$n$,比如$1$,$2$等,表示解析到的第几个值给引用名称变量。正则表达式的提取模式,值是从1开始,值为0则对应的是整个匹配的表达式
匹配数字:0代表随机取值,-1是全部取值,其余正整数代表在已提取的内容中,匹配第几个内容
默认值:如果正则表达式没有查到值,则使用默认值
方法一:使用正则表达式实现接口关联(可以作用于任意值)
新建一个请求:http://www.weather.com.cn/data/sk/101010100.html

运行能看到结果

如果出现乱码,可以添加一个BeanShell后置处理程序,加上代码:prev.setDataEncoding("utf-8");

在查看结果树这里可以查看结果,也可以进行一些测试,比如正则表达式的测试:
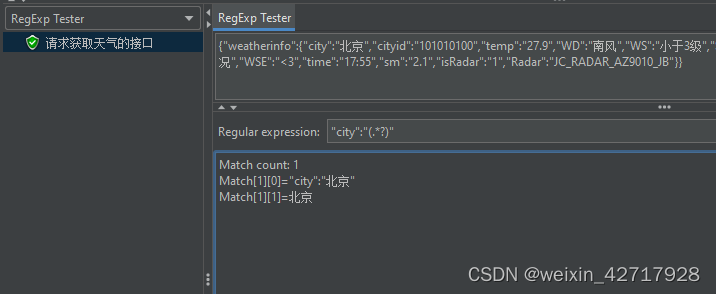
其中:
():封装了待返回的字符串.:匹配任意一个字符(除了回车键)*:限定符,匹配(*之前的符号)0次或多次,默认是贪婪模式+:限定符,匹配(+之前的符号)1次或多次,默认是贪婪模式?:限定符,匹配0次或1次,在找到第一个匹配项后停止.*:匹配连续0个/多个字符.+:匹配连续1个/多个字符\ :转义,\.表示匹配字符.本身
^:边界限定,字符串的开始位置
$:边界限定,字符串的结束位置
| :模式限定符,从中任选一个匹配
PS: 这个怎么理解,.是提取一个,但是使用了*或者+,那就会一直提取到最后一个字符串,?表示第一个匹配到第一个项就停止(也就是北京,然后有“,就停止了),所以如果不加?,则一直匹配到B为止
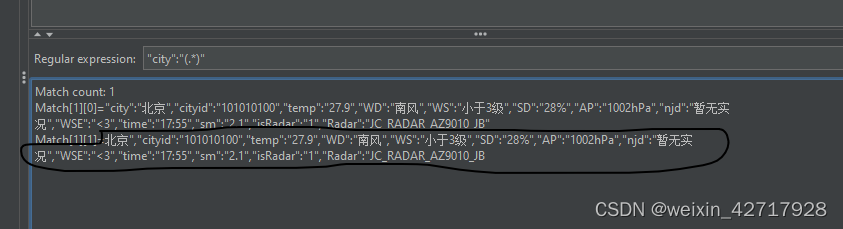
添加一个后置处理器:正则表达式提取器
提取器作用的范围:
- Main samples and sub-samples:匹配范围包括当前父取样器并覆盖至子取样器。
- Main samples only:只匹配当前父取样器(一般使用这个)
- Sub-samples only:仅匹配子取样器
- Jmeter Variable Name to use:支持对Jemter变量值进行匹配
提取器取值的范围:
- Body:响应数据的主体部分
- Body(unescaped):针对替换了的响应码部分
- Body as a doucment:返回内容作为一个文档进行匹配
- Response Headers:响应头部分
- Request Headers:请求头部分
- URL:URL链接
- Response Code:响应码。如HTTP返回码200代表成功。
- Resopnse Message:响应信息。比如处理成功返回“成功”字样,或者“OK”字样
其中:
$1$表示解析到的第1个值,$$是固定写法
匹配数字:0代表随机取值,1表示匹配返回数组的第一个元素内容
缺省值:如果参数没有取得到值,那默认给一个值让它取
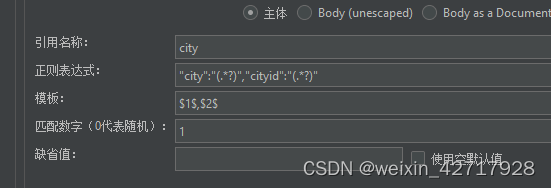
如果是取2个值就这样
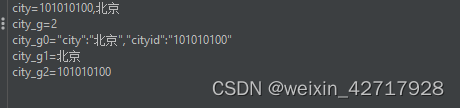
增加一个调试取样器,用于查看结果有没有取值到

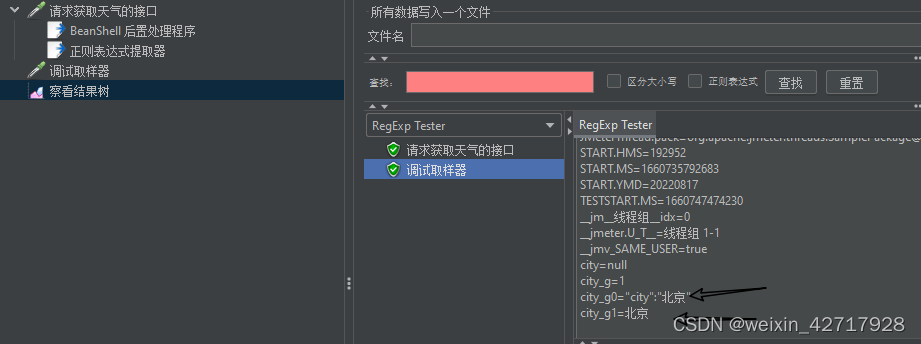
这里我遇到一个问题,我把后置处理器放在正则提取器的后面,得到的结果是???,放在提取器前面就好了,我理解是请求后的数据,要先处理乱码,再提取,才是正确的
方法二:使用Jsonpath表达式实现接口关联(只能作用于返回值是Json的)
1)从根目录开始找(绝对路径):$.weatherinfo.temp
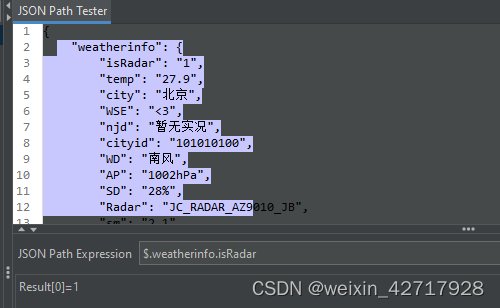
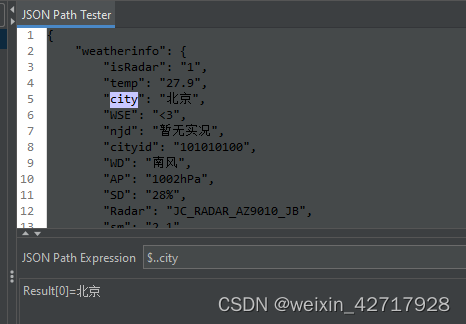
2)从任意目录开始找(相对路径):$..city
创建一个Json提取器,填写的内容和正则表达式类似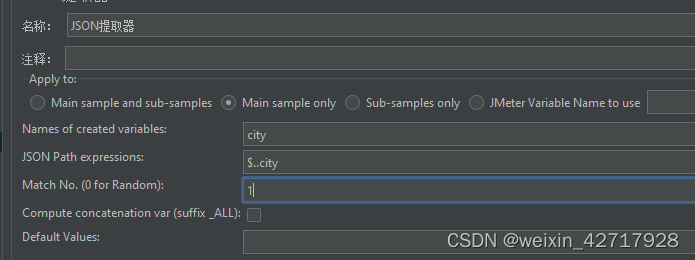
ps:如果需要宣线程组之间引用变量值,那么在正则表达式提取后,还要添加一个后置处理器
通过设置属性的方式,${_setProperty(globalToken,${token},)}
另一个线程组中可以引用属性值globalToken
2)BeanShell后置处理器
如果数据量小,建议使用正则表达式。如果数据量大或者对取值有特殊要求,可以考虑使用BeanShell后置处理器
针对数据比较大且返回有多个列表,需要人工判断需要取的值是否存在并且在什么位置,导致效率低而且容易出错,则可以使用BeanShell后置处理器,分别提取每个列表的值
可以将前一个接口的响应结果的某个字段用于下一个接口的参数

可以获得登录接口的 token ,并保存到本地
FileWriter fs= new FileWriter("E:\\token.csv",true);
BufferedWriter out = new BufferedWriter(fs);
//phone 是 login 接口的入参,这里一并写入文件
out.write(vars.get("phone")+',');
out.write(vars.get("token")+'\n');
out.close();
fs.close();一些使用代码也可以参考:武汉茑萝:Jmeter之BeanShell详解 - 知乎
九:断言
用于自动化验证取样器请求,或对应的响应数据是否返回了期望的结果
1)响应断言
响应断言提供对取样器的响应文本、响应代码、响应信息、响应头、请求头、URL样本、文档、请求数据等内容进行包括,匹配,相等,否,或等判断,可以将多个断言附加到任何控制器以提高灵活性
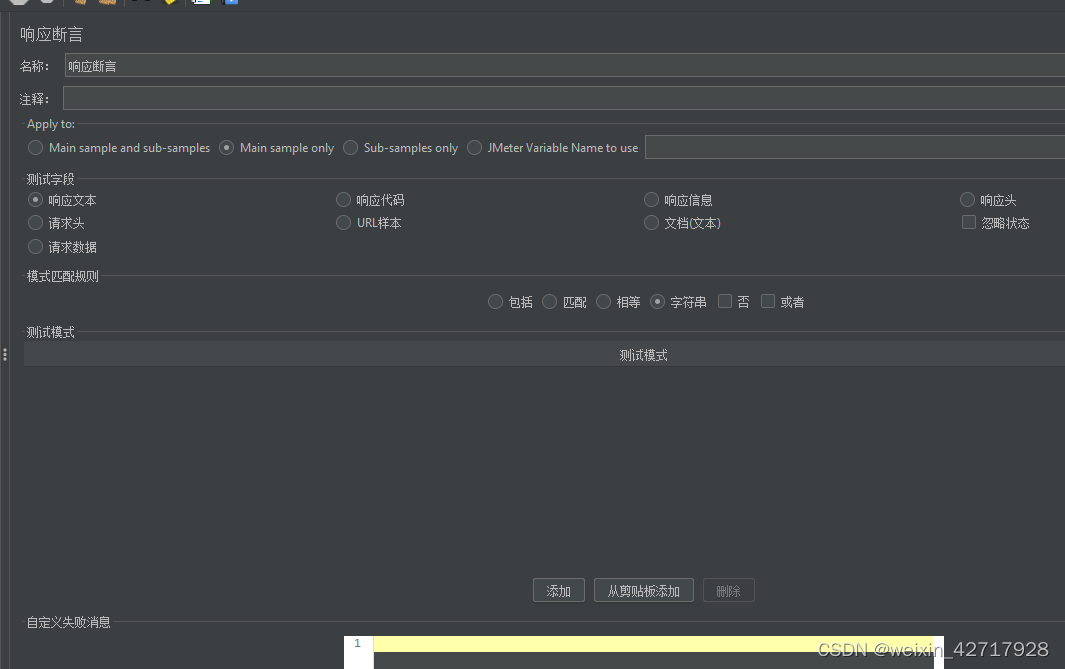
(1)Apply to:响应断言的应用范围
- Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
- Main sample only:仅作用于父节点的取样器。(选默认的main sample only就行了)
- Sub-samples only:仅作用于子节点的取样器
- JMeter Variable Name to use:作用于JMeter变量(输入框内可写入正则提取的响应值),从指定变量中提取需要的值
(2)要测试的响应字段
- 响应文本:请求的响应文本信息,不包含响应头信息,最常用的断言字段
- 响应代码:HTTP请求返回的响应码。如果要验证404,501等HTTP响应代码时,需要选择Ignore Status选项,因为当HTTP响应代码为400,500时,Jmeter默认这个请求是失败的
- 响应信息:响应信息中匹配数据(Response message),比如"OK"
- Response Headers:从响应头信息中提取数据
- Request Headers:从请求头信息中提取数据
- URL样本:从请求URL中提取数据,如果有重定向包含重定向URL
- Document (text):文档(文本),通过Apache Tika从各种类型的文档中,提取文本进行验证,包括响应文本,pdf、word等等各种格式文本
- 忽略状态(Ignore Status):一个请求进行多项响应断言时,忽略某一项断言的响应结果,而继续下一项断言
- Request Data:从请求体包含的信息中提取数据
(3)模式匹配
- 包括(Contains):返回结果包括指定的内容代表响应成功,支持正则匹配
- 匹配(Matches):响应内容完全匹配代表响应成功,大小写不敏感,支持正则表达式
- 相等(Equals):响应内容完全匹配代表响应成功,大小写敏感,需要匹配的内容是字符串非正则表达式
- 字符串(Substring):响应内容包含指定内容代表响应成功,大小写敏感,需要匹配的内容是字符串非正则表达式
- 否(Not):相当于取反。 如果断言结果为True,勾选“否”后,最终断言结果为False。反之亦然
- 或者(Or):若测试模式中有一个成功,则整个断言成功
(4)测试模式
要测试的模式。在这里输入结果期望值,注意空格要去掉,可以设置多个期望值,如果其中一个执行失败,则不再继续检查
(5)自定义失败消息
断言失败时,打印的消息
ps:如果返回报文是这种情况
{resultcode:200,message:XXX},如果配置检查点resultcode:200,可能会存在漏判,比如
{resultcode:200,message:null},这样检查点虽然成功,但事务是失败的(如后端调用超时或者失败,通信层面是成功的,但消息没成功返回),因此需要额外的关键字作为检查点
2)Size断言
用来判断返回内容字节大小,以及响应结果是否包含正确数量的字节
比如大报文返回场景:
{resultcode:200,list:[..................................123...............................................],}
如果断言为123做内容检查就会出现问题。假设list返回10条,实际上只返回1条,虽然检查通过了,但实际事务失败。所以需要Size断言做额外判断
3)BeanShell断言
如果断言不能直接进行判断,需要进行一定的转换处理,就需要BeanShell断言。
它可以通过BeanShell脚本来执行断言检查
假如有以下响应数据
{
2 "message": "XXX",
3 "Code": 200
4 }(1)使用JSONObject对象来获取json数据,要下载org.json的jar包,在测试计划中导入该jar包,在jmeter的lib目录下放入该jar包
验证Code的值是否等于200,验证message的值是否符合预期
// 获取上一个请求的返回值
String jsonString = prev.getResponseDataAsString();
// 将【返回值】转换为JSON格式
JSONObject responseJson = new JSONObject(jsonString);
if (responseJson.getInt("Code") != 200){
Failure = true;
FailureMessage = "statusCode的返回值错误";
}
String message1 = responseJson.getString("message");
log.info(message1);
if (!message1.equals("XXX")){
Failure = true;
FailureMessage = "message与实际值不一致";
}(2)如果有以下数据,要解析数组中data的值
{
"Code": 200,
"data": [
{
"i": "1234",
"n": "XXX",
"v": "2.0",
"iconUrl": "",
},
{
"i": "4567",
"n": "YYY",
"v": "3.0",
"iconUrl": "",
}
] String jsonContent = prev.getResponseDataAsString();
JSONObject response = new JSONObject(jsonContent);
JSONArray groups = response.getJSONArray("data");
String strData= groups.toString();
log.info(strData)(3)如果有更复杂的结构,要解析groups的数据
{
2 "priorityGroups": {
3 "proId": 1234,
5 "groups": [
6 {
7 "id": "345677",
8 "items": [
9 {
10 "proId": 1111,
11 "n": "PC端",
12 "index": 1
13 },
14 {
15 "proId": 2222,
16 "n": "iOS端",
17 "index": 2
18 }
24 ]
25 }
26 ]
27 },
28 "promotion": {
29 "proId": 1234,
38 "createTime": 1111111111111
39 }
40 }import org.json.JSONArray;
import org.json.JSONException;
import org.json.JSONObject;
String jsonContent = prev.getResponseDataAsString();
JSONObject response = new JSONObject(jsonContent);
JSONArray groups = response.getJSONObject("priorityGroups").getJSONArray("groups");
String strGroups = groups.toString();(4)响应头解析
// 4. 响应头解析
import java.util.HashMap;
import java.util.Map;
//将字符串用换行符 截取为abc数组
String [] headersList = ResponseHeaders.split("\n");
Map headersMap = new HashMap(); // 创建HashMap来重新组装headers
for (int i=1; i<headersList.length; i++){
String [] itemsList = headersList[i].split(": "); // 按照冒号分割
headersMap.put(itemsList[0], itemsList[1]); // 键值对放入HashMap
}
String contentType = headersMap.get("Content-Type"); //提取请求头
log.info("响应Content-Type:" + contentType )