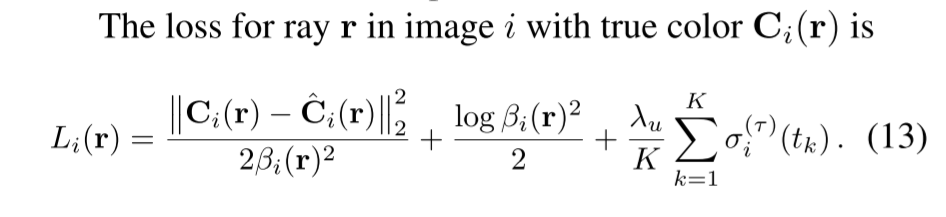注1:本文系“简要介绍”系列之一,仅从概念上对元学习(Meta-Learning)进行非常简要的介绍,不适合用于深入和详细的了解。
元学习:学会学习的新途径
BLOG | Samsung Research
1 背景介绍
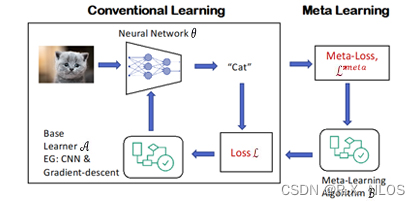
元学习(Meta-Learning),又称为学习的学习,是指让机器学习模型具备在多个任务上快速学习和适应的能力。它试图解决传统机器学习模型需要大量训练数据和计算资源的问题。元学习的目标是在少量数据上训练一个模型,使其能够在新任务上快速适应。
2 原理介绍和推导
2.1 模型无关的元学习(MAML)
模型无关的元学习(Model-Agnostic Meta-Learning,简称MAML)是一种广泛使用的元学习算法。MAML的关键思想是:在元学习阶段学习一个初始化参数,使得在新任务上仅需少量梯度更新步骤就可以获得较好的性能。
MAML的优化目标如下:
min θ ∑ i = 1 N L T i ( θ − α ∇ θ L T i ( θ ) ) \min_{\theta} \sum_{i=1}^N \mathcal{L}_{T_i}(\theta - \alpha \nabla_\theta \mathcal{L}_{T_i}(\theta)) θmini=1∑NLTi(θ−α∇θLTi(θ))
其中, θ \theta θ是模型的参数, α \alpha α是学习率, N N N是任务数, L T i \mathcal{L}_{T_i} LTi是在任务 i i i上的损失函数。
2.2 记忆增强神经网络(MANN)
记忆增强神经网络(Memory-Augmented Neural Networks,简称MANN)是另一种元学习方法,其主要思想是将神经网络与可微分的外部记忆结构相结合。这使得模型可以在新任务上快速适应,同时还能记住之前学到的知识。
一个典型的MANN模型是神经图灵机(Neural Turing Machine,简称NTM),其结构如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Aux6z8kL-1688559988925)(https://miro.medium.com/max/700/1*Uq3fzrNsLloVv4l4rQ6eWw.png)]
3 研究现状
元学习近年来取得了显著的进展,应用领域包括:自然语言处理(NLP)、计算机视觉(CV)和强化学习(RL)等。
-
在自然语言处理领域,BERT等预训练模型在迁移学习任务中表现出色,部分原因是它们具备了一定的元学习能力。
-
在计算机视觉领域,元学习被广泛应用于少样本学习(Few-Shot Learning),如MAML和Prototypical Networks等。
-
在强化学习领域,元学习用于提高模型适应新环境的速度,如Reptile和Meta-World等。
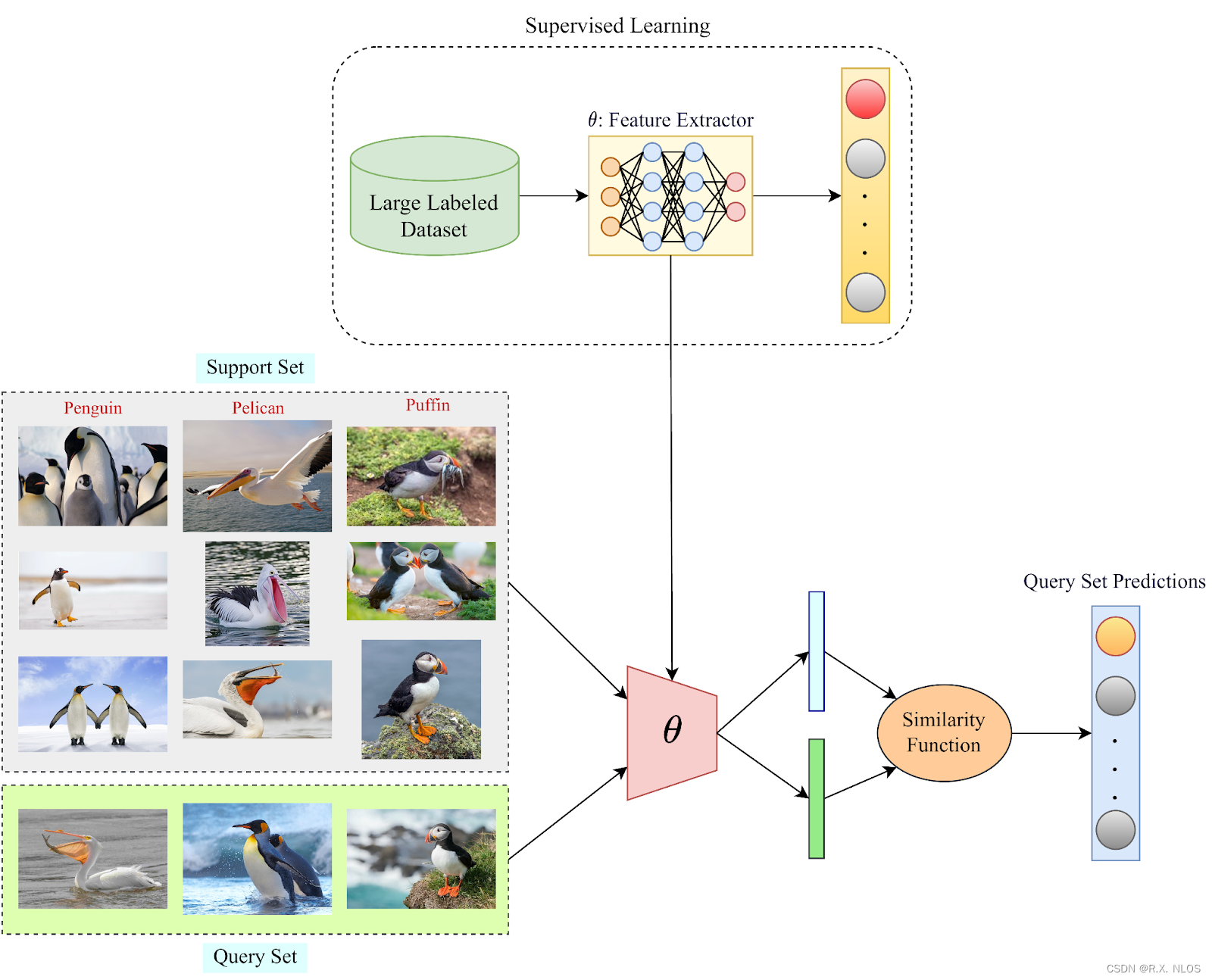
Everything you need to know about Few-Shot Learning
4 挑战
尽管元学习在多个领域取得了一定的成功,但仍然面临着诸多挑战:
-
泛化能力:元学习模型在新任务上的泛化能力仍有待提高,尤其是在任务具有较大差异的情况下。
-
计算复杂性:许多元学习算法的计算复杂性很高,需要大量的计算资源。
-
可解释性:元学习模型的可解释性往往较差,尤其是在使用复杂神经网络结构时。
5 未来展望
未来,元学习研究可能朝以下方向发展:
-
提高泛化能力:研究新的元学习算法和框架,以提高模型在新任务上的泛化能力。
-
降低计算复杂性:优化现有算法,降低计算复杂性,使元学习能够在资源受限的环境中运行。
-
提高可解释性:研究新的可解释性方法,使元学习模型更容易被理解和分析。
-
跨领域研究:结合其他学科,如认知科学、心理学等,研究元学习的理论基础。
6 代码示例
以下是一个使用PyTorch实现的简单MAML算法示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.layer = nn.Linear(1, 1)
def forward(self, x):
return self.layer(x)
# 生成训练数据
def generate_data():
x = torch.randn(10, 1)
y = 2 * x + 1
return x, y
# MAML算法
def maml(model, tasks, meta_lr=1e-3, inner_lr=1e-2, num_inner_updates=5):
meta_optimizer = optim.Adam(model.parameters(), lr=meta_lr)
for task in tasks:
x, y = generate_data()
task_model = Model() # 创建一个新模型用于任务训练
task_model.load_state_dict(model.state_dict()) # 从元模型复制参数
task_optimizer = optim.SGD(task_model.parameters(), lr=inner_lr)
# 在任务数据上进行梯度更新
for _ in range(num_inner_updates):
loss = nn.MSELoss()(task_model(x), y)