前言:
本文为记录自己在Nerf学习道路的一些笔记,包括对论文以及其代码的思考内容。公众号: AI知识物语 B站讲解:出门吃三碗饭
本篇文章主要针对其代码来学习其内容,关于代码的理解可能会有出入,欢迎批评指正!!!
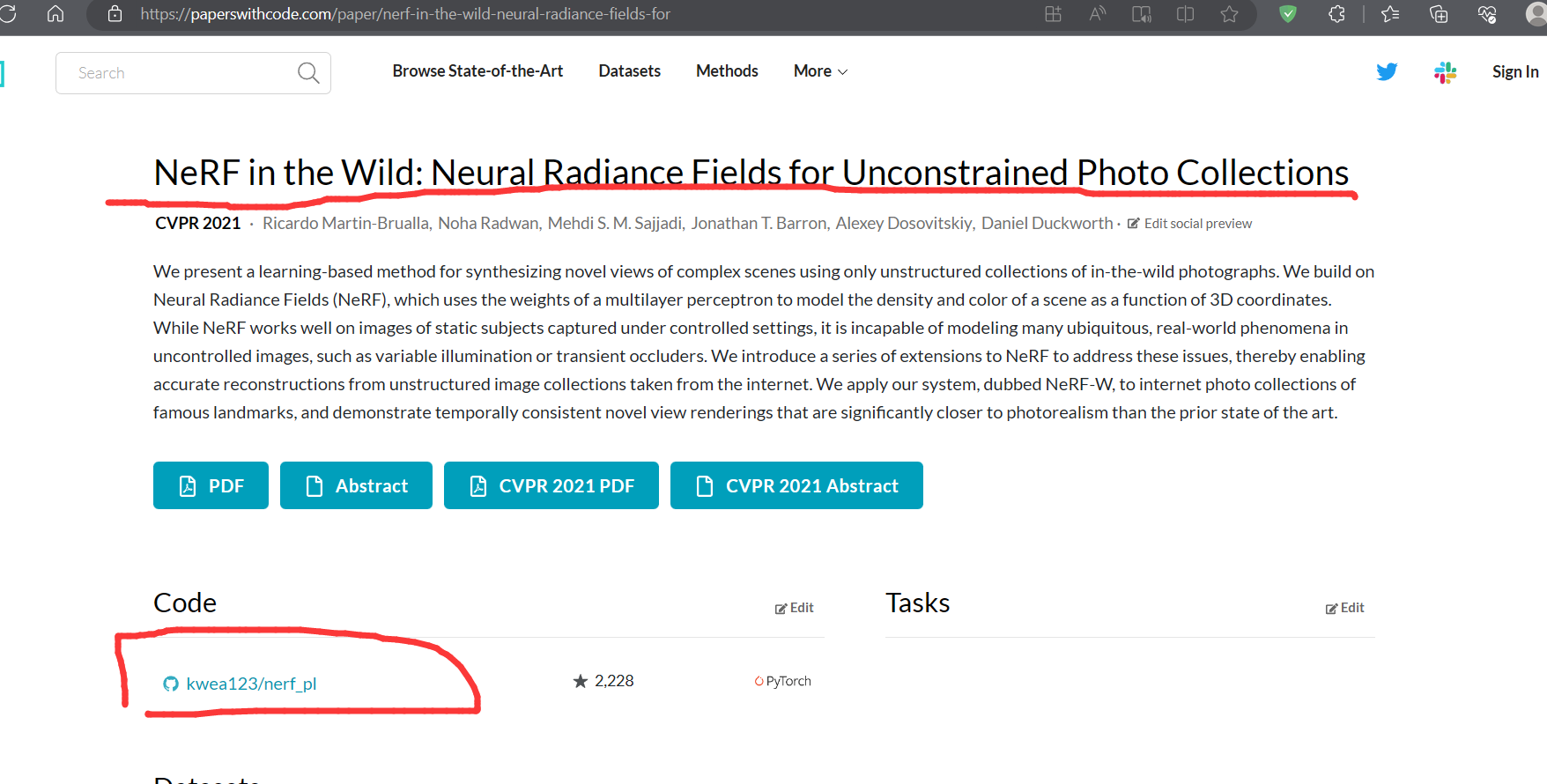
1:Paper with code 获取代码
(论文是论文:https://arxiv.org/abs/2003.08934)
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
代码地址,自取
Nerf 与unity结合

项目目录如下,这是nerf-wild的代码,不要clone错了
2:nerf.py
位置编码函数
有点类似这个函数(代码和下图公告不完全一致!)
注释里有解释其具体函数
(代码) x to (x, sin(2^k x), cos(2^k x), …)
(参考函数)
class PosEmbedding(nn.Module):
def __init__(self, max_logscale, N_freqs, logscale=True):
"""
Defines a function that embeds x to (x, sin(2^k x), cos(2^k x), ...)
"""
super().__init__()
self.funcs = [torch.sin, torch.cos]
if logscale:
self.freqs = 2**torch.linspace(0, max_logscale, N_freqs)
else:
self.freqs = torch.linspace(1, 2**max_logscale, N_freqs)
def forward(self, x):
"""
Inputs:
x: (B, 3)
Outputs:
out: (B, 6*N_freqs+3)
"""
out = [x]
for freq in self.freqs:
for func in self.funcs:
out += [func(freq*x)]
return torch.cat(out, -1)
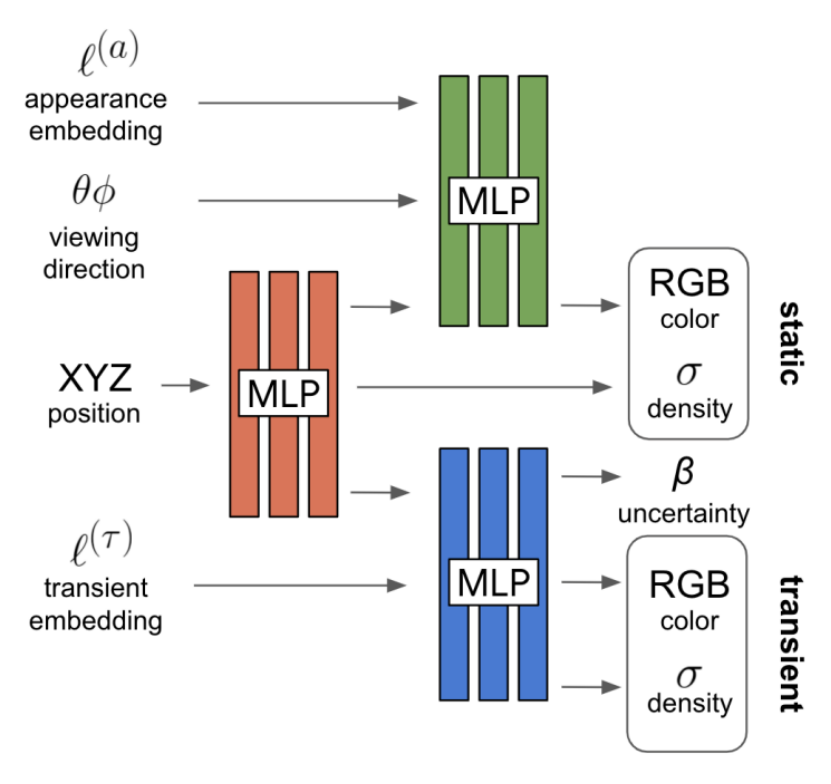
Nerf网络结构 (重点)
class NeRF(nn.Module):
def __init__(self, typ,
D=8, W=256, skips=[4],
in_channels_xyz=63, in_channels_dir=27,
encode_appearance=False, in_channels_a=48,
encode_transient=False, in_channels_t=16,
beta_min=0.03):
"""
---Parameters for the original NeRF---
D: number of layers for density (sigma) encoder
W: number of hidden units in each layer
skips: add skip connection in the Dth layer
in_channels_xyz: number of input channels for xyz (3+3*10*2=63 by default)
in_channels_dir: number of input channels for direction (3+3*4*2=27 by default)
in_channels_t: number of input channels for t
---Parameters for NeRF-W (used in fine model only as per section 4.3)---
---cf. Figure 3 of the paper---
encode_appearance: whether to add appearance encoding as input (NeRF-A)
in_channels_a: appearance embedding dimension. n^(a) in the paper
encode_transient: whether to add transient encoding as input (NeRF-U)
in_channels_t: transient embedding dimension. n^(tau) in the paper
beta_min: minimum pixel color variance
"""
super().__init__()
self.typ = typ
self.D = D
self.W = W
self.skips = skips
self.in_channels_xyz = in_channels_xyz
self.in_channels_dir = in_channels_dir
self.encode_appearance = False if typ=='coarse' else encode_appearance
self.in_channels_a = in_channels_a if encode_appearance else 0
self.encode_transient = False if typ=='coarse' else encode_transient
self.in_channels_t = in_channels_t
self.beta_min = beta_min
# xyz encoding layers
for i in range(D):
if i == 0:
layer = nn.Linear(in_channels_xyz, W)
elif i in skips:
layer = nn.Linear(W+in_channels_xyz, W)
else:
layer = nn.Linear(W, W)
layer = nn.Sequential(layer, nn.ReLU(True))
setattr(self, f"xyz_encoding_{i+1}", layer)
self.xyz_encoding_final = nn.Linear(W, W)
# direction encoding layers
self.dir_encoding = nn.Sequential(
nn.Linear(W+in_channels_dir+self.in_channels_a, W//2), nn.ReLU(True))
# static output layers
self.static_sigma = nn.Sequential(nn.Linear(W, 1), nn.Softplus())
self.static_rgb = nn.Sequential(nn.Linear(W//2, 3), nn.Sigmoid())
if self.encode_transient:
# transient encoding layers
self.transient_encoding = nn.Sequential(
nn.Linear(W+in_channels_t, W//2), nn.ReLU(True),
nn.Linear(W//2, W//2), nn.ReLU(True),
nn.Linear(W//2, W//2), nn.ReLU(True),
nn.Linear(W//2, W//2), nn.ReLU(True))
# transient output layers
self.transient_sigma = nn.Sequential(nn.Linear(W//2, 1), nn.Softplus())
self.transient_rgb = nn.Sequential(nn.Linear(W//2, 3), nn.Sigmoid())
self.transient_beta = nn.Sequential(nn.Linear(W//2, 1), nn.Softplus())
def forward(self, x, sigma_only=False, output_transient=True):
"""
Encodes input (xyz+dir) to rgb+sigma (not ready to render yet).
For rendering this ray, please see rendering.py
Inputs:
x: the embedded vector of position (+ direction + appearance + transient)
sigma_only: whether to infer sigma only.
has_transient: whether to infer the transient component.
Outputs (concatenated):
if sigma_ony:
static_sigma
elif output_transient:
static_rgb, static_sigma, transient_rgb, transient_sigma, transient_beta
else:
static_rgb, static_sigma
"""
if sigma_only:
input_xyz = x
elif output_transient:
input_xyz, input_dir_a, input_t = \
torch.split(x, [self.in_channels_xyz,
self.in_channels_dir+self.in_channels_a,
self.in_channels_t], dim=-1)
else:
input_xyz, input_dir_a = \
torch.split(x, [self.in_channels_xyz,
self.in_channels_dir+self.in_channels_a], dim=-1)
xyz_ = input_xyz
for i in range(self.D):
if i in self.skips:
xyz_ = torch.cat([input_xyz, xyz_], 1)
xyz_ = getattr(self, f"xyz_encoding_{i+1}")(xyz_)
static_sigma = self.static_sigma(xyz_) # (B, 1)
if sigma_only:
return static_sigma
xyz_encoding_final = self.xyz_encoding_final(xyz_)
dir_encoding_input = torch.cat([xyz_encoding_final, input_dir_a], 1)
dir_encoding = self.dir_encoding(dir_encoding_input)
static_rgb = self.static_rgb(dir_encoding) # (B, 3)
static = torch.cat([static_rgb, static_sigma], 1) # (B, 4)
if not output_transient:
return static
transient_encoding_input = torch.cat([xyz_encoding_final, input_t], 1)
transient_encoding = self.transient_encoding(transient_encoding_input)
transient_sigma = self.transient_sigma(transient_encoding) # (B, 1)
transient_rgb = self.transient_rgb(transient_encoding) # (B, 3)
transient_beta = self.transient_beta(transient_encoding) # (B, 1)
transient = torch.cat([transient_rgb, transient_sigma,
transient_beta], 1) # (B, 5)
return torch.cat([static, transient], 1) # (B, 9)
这段代码定义了一个名为NeRF的模块类,用于将输入x编码为RGB颜色和密度(sigma)的输出。具体的功能如下:
初始化函数__init__接受以下参数:
typ:模型类型,可以是coarse或fine
D:密度(sigma)编码器的层数 (默认8层)
W:每层中的隐藏单元数 (默认256个单元)
skips:在第D层中添加跳跃连接的层数列表 (默认第4层跳转)
in_channels_xyz:坐标(xyz)的输入通道数,默认为63(63为经过PosEmbedding后的一个通道数)
in_channels_dir:方向的输入通道数,默认为27 (同理)
encode_appearance:是否添加外观编码作为输入,默认为False
in_channels_a:外观嵌入的维度,默认为48 ( appearance embedding)
encode_transient:是否添加瞬变编码作为输入,默认为False
in_channels_t:瞬变嵌入的维度,默认为16 ( transient embedding)
beta_min:像素颜色方差的最小值,默认为0.03
在初始化函数中,根据模型类型typ和是否编码外观encode_appearance、是否编码瞬变encode_transient进行设置。
初始化xyz编码器层。使用nn.Linear和nn.ReLU构建了多层全连接网络,并使用setattr动态地给模块设置属性,属性名为xyz_encoding_{i+1},其中i为层的索引。
for i in range(D):
if i == 0:
layer = nn.Linear(in_channels_xyz, W)
elif i in skips:
layer = nn.Linear(W+in_channels_xyz, W)
else:
layer = nn.Linear(W, W)
layer = nn.Sequential(layer, nn.ReLU(True))
setattr(self, f"xyz_encoding_{i+1}", layer)
self.xyz_encoding_final = nn.Linear(W, W)
初始化方向编码器层。使用nn.Linear和nn.ReLU构建了一个全连接网络。
self.dir_encoding = nn.Sequential(
nn.Linear(W+in_channels_dir+self.in_channels_a, W//2), nn.ReLU(True))
初始化静态输出层。使用nn.Linear和nn.Softplus构建了两个全连接网络,分别用于预测密度(sigma)和RGB颜色。
self.static_sigma = nn.Sequential(nn.Linear(W, 1), nn.Softplus())
self.static_rgb = nn.Sequential(nn.Linear(W//2, 3), nn.Sigmoid())
如果模型需要编码瞬变,则初始化瞬变编码器层和瞬变输出层。使用nn.Linear和nn.ReLU构建了多层全连接网络,并使用nn.Softplus和nn.Sigmoid构建了多个全连接网络,分别用于预测瞬变的密度(sigma)、RGB颜色和像素颜色方差。
if self.encode_transient:
# transient encoding layers
self.transient_encoding = nn.Sequential(
nn.Linear(W+in_channels_t, W//2), nn.ReLU(True),
nn.Linear(W//2, W//2), nn.ReLU(True),
nn.Linear(W//2, W//2), nn.ReLU(True),
nn.Linear(W//2, W//2), nn.ReLU(True))
# transient output layers
self.transient_sigma = nn.Sequential(nn.Linear(W//2, 1), nn.Softplus())
self.transient_rgb = nn.Sequential(nn.Linear(W//2, 3), nn.Sigmoid())
self.transient_beta = nn.Sequential(nn.Linear(W//2, 1), nn.Softplus())
前向传播函数forward接受输入x,以及是否只输出密度(sigma)、是否输出瞬变组件的标志。
如果只输出密度(sigma),则将输入x作为xyz的编码输入,并通过静态密度(sigma)网络得到输出。
如果需要输出瞬变组件,则将输入x分割为xyz的编码输入、方向和外观的输入以及瞬变的输入,并分别经过对应的编码器层得到输出。
将xyz的编码输出和方向/外观的编码输入连接起来,并通过方向编码器层得到输出。然后,通过静态RGB网络得到静态RGB颜色输出。
如果不需要输出瞬变组件,则将静态RGB颜色和静态密度(sigma)连接起来作为输出。
如果需要输出瞬变组件,则将xyz的编码输出和瞬变的输入连接起来,并通过瞬变编码器层得到输出。然后,通过瞬变的RGB、密度(sigma)和像素颜色方差网络得到瞬变组件的输出。
最终,将静态组件和瞬变组件连接起来作为输出。输出形状为(B, 9),其中B为批量大小。
简略网络图参考
下面是我简单测试后输出的网络层
NeRF(
(xyz_encoding_1): Sequential(
(0): Linear(in_features=63, out_features=256, bias=True)
(1): ReLU(inplace=True)
)
(xyz_encoding_2): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU(inplace=True)
)
(xyz_encoding_3): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU(inplace=True)
)
(xyz_encoding_4): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU(inplace=True)
)
(xyz_encoding_5): Sequential(
(0): Linear(in_features=319, out_features=256, bias=True)
(1): ReLU(inplace=True)
)
(xyz_encoding_6): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU(inplace=True)
)
(xyz_encoding_7): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU(inplace=True)
)
(xyz_encoding_8): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU(inplace=True)
)
(xyz_encoding_final): Linear(in_features=256, out_features=256, bias=True)
(dir_encoding): Sequential(
(0): Linear(in_features=283, out_features=128, bias=True)
(1): ReLU(inplace=True)
)
(static_sigma): Sequential(
(0): Linear(in_features=256, out_features=1, bias=True)
(1): Softplus(beta=1, threshold=20)
)
(static_rgb): Sequential(
(0): Linear(in_features=128, out_features=3, bias=True)
(1): Sigmoid()
)
)
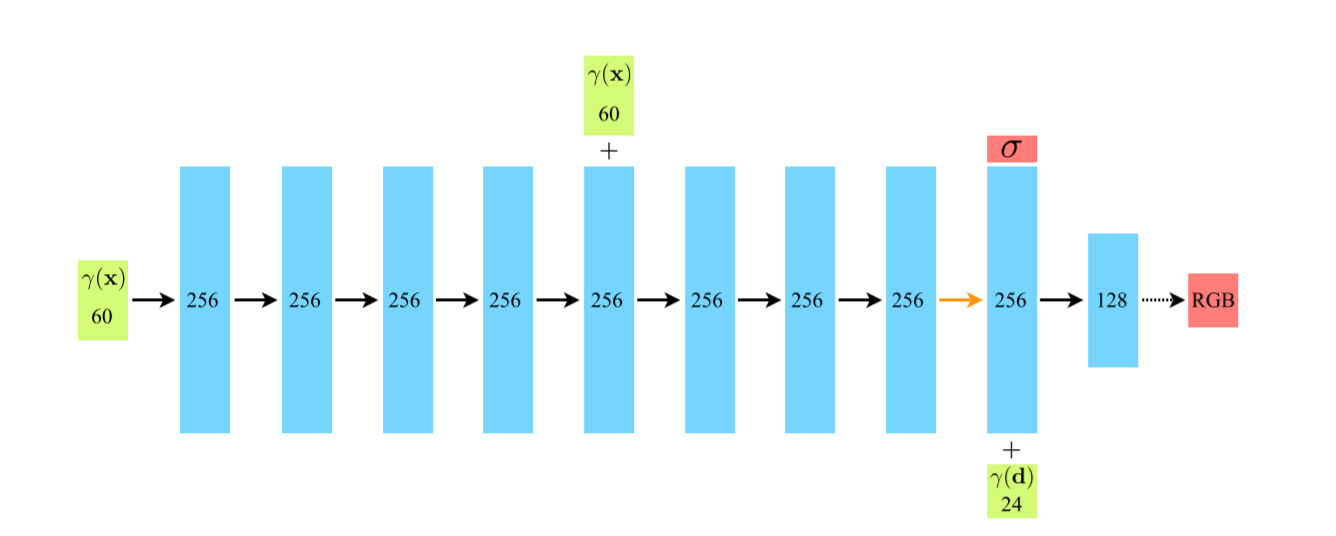
下面这个图是论文NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 的网络图,其前半部分大致是相同的,全连接层以及对应的relu, skip操作等等
,
3:损失函数
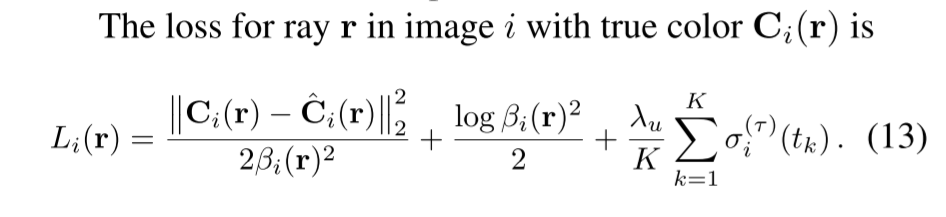
这段代码定义了两个损失函数类:
3.1ColorLoss
ColorLoss类用于计算颜色损失,初始化函数__init__接受一个参数coef,用于调节损失的权重。在初始化函数中,定义了一个均方误差损失函数nn.MSELoss,并将其赋值给属性self.loss。
在前向传播中,计算了粗采样的颜色coarse-color输出与目标值之间的均方误差损失c_l。如果inputs中还包含了细采样fine-color颜色输出rgb_fine,则计算细化颜色输出与目标值之间的均方误差损失f_l。最后,将粗采样颜色损失和细采样颜色损失加权求和,并乘以权重coef作为最终的损失输出。
3.2NerfWLoss
NerfWLoss类用于计算NeRF-W论文中的损失函数,初始化函数__init__接受两个参数coef和lambda_u(默认0.01),分别表示损失的权重和论文中的lambda_u超参数。
在前向传播中,计算了粗采样颜色输出与目标值之间的均方误差损失c_l。如果inputs中还包含了细化颜色输出rgb_fine,则根据是否包含了瞬变组件计算不同的细采样颜色损失。(同理)
如果没有瞬变组件(transient head),使用均方误差损失函数计算细化颜色输出与目标值之间的损失f_l。
如果包含了瞬变组件(transient head),使用公式13中的第一项计算细采样颜色损失f_l,其中分子部分为细采样颜色输出与目标值之间的平方差,分母部分为输入inputs中的beta值的平方乘以2,再取均值。
同时,计算了输入inputs中的beta值的对数的平均值,并加上3以保证其为正数,作为公式13中的第二项beta损失b_l。
ret['b_l'] = 3 + torch.log(inputs['beta']).mean() # +3 to make it positive
最后,计算了输入inputs中的瞬变组件(transient head)密度(sigma)的平均值乘以lambda_u超参数,作为公式13中的第三项sigma损失s_l。
(补充:这里我看其他大佬有写解释的一种说法是,为了避免beta值过大,导致第1项为0,设了第2项,可以让其稍微偏离0)
最后,将粗糙颜色损失、细化颜色损失、beta损失和sigma损失分别乘以权重coef作为最终的损失输出。
其他内容具体可以参考代码
class ColorLoss(nn.Module):
def __init__(self, coef=1):
super().__init__()
self.coef = coef
self.loss = nn.MSELoss(reduction='mean')
def forward(self, inputs, targets):
loss = self.loss(inputs['rgb_coarse'], targets)
if 'rgb_fine' in inputs:
loss += self.loss(inputs['rgb_fine'], targets)
return self.coef * loss
class NerfWLoss(nn.Module):
"""
Equation 13 in the NeRF-W paper.
Name abbreviations:
c_l: coarse color loss
f_l: fine color loss (1st term in equation 13)
b_l: beta loss (2nd term in equation 13)
s_l: sigma loss (3rd term in equation 13)
"""
def __init__(self, coef=1, lambda_u=0.01):
"""
lambda_u: in equation 13
"""
super().__init__()
self.coef = coef
self.lambda_u = lambda_u
def forward(self, inputs, targets):
ret = {}
ret['c_l'] = 0.5 * ((inputs['rgb_coarse']-targets)**2).mean()
if 'rgb_fine' in inputs:
if 'beta' not in inputs: # no transient head, normal MSE loss
ret['f_l'] = 0.5 * ((inputs['rgb_fine']-targets)**2).mean()
else:
ret['f_l'] = \
((inputs['rgb_fine']-targets)**2/(2*inputs['beta'].unsqueeze(1)**2)).mean()
ret['b_l'] = 3 + torch.log(inputs['beta']).mean() # +3 to make it positive
ret['s_l'] = self.lambda_u * inputs['transient_sigmas'].mean()
for k, v in ret.items():
ret[k] = self.coef * v
return ret
loss_dict = {'color': ColorLoss,
'nerfw': NerfWLoss}
train.py
这部分比较简单,主要是对上述工作的一些调用
定义了一个名为NeRFSystem的类,它是一个继承自LightningModule的模型。NeRFSystem用于实现基于NeRF(Neural Radiance Fields)的渲染系统。
在__init__方法中,模型初始化了一些参数和组件。创建了一些位置编码器(PosEmbedding)用于对位置信息进行嵌入。模型还定义了一个粗糙(coarse)NeRF模型(self.nerf_coarse)和一个细化(fine)NeRF模型(self.nerf_fine),并将它们存储在self.models字典中。
forward方法实现了批量推断。它根据输入的光线和时间戳,调用render_rays函数对光线进行渲染。渲染使用了定义的NeRF模型和嵌入器,以及其他一些参数,例如采样数量、是否使用视差、扰动等。最后,将渲染结果返回。
总体来说,NeRFSystem的作用是实现了一个NeRF渲染系统,可以对输入的光线进行渲染,并返回渲染结果。
class NeRFSystem(LightningModule):
def __init__(self, hparams):
super().__init__()
self.hparams = hparams
self.loss = loss_dict['nerfw'](coef=1)
self.models_to_train = []
self.embedding_xyz = PosEmbedding(hparams.N_emb_xyz-1, hparams.N_emb_xyz)
self.embedding_dir = PosEmbedding(hparams.N_emb_dir-1, hparams.N_emb_dir)
self.embeddings = {'xyz': self.embedding_xyz,
'dir': self.embedding_dir}
if hparams.encode_a:
self.embedding_a = torch.nn.Embedding(hparams.N_vocab, hparams.N_a)
self.embeddings['a'] = self.embedding_a
self.models_to_train += [self.embedding_a]
if hparams.encode_t:
self.embedding_t = torch.nn.Embedding(hparams.N_vocab, hparams.N_tau)
self.embeddings['t'] = self.embedding_t
self.models_to_train += [self.embedding_t]
self.nerf_coarse = NeRF('coarse',
in_channels_xyz=6*hparams.N_emb_xyz+3,
in_channels_dir=6*hparams.N_emb_dir+3)
self.models = {'coarse': self.nerf_coarse}
if hparams.N_importance > 0:
self.nerf_fine = NeRF('fine',
in_channels_xyz=6*hparams.N_emb_xyz+3,
in_channels_dir=6*hparams.N_emb_dir+3,
encode_appearance=hparams.encode_a,
in_channels_a=hparams.N_a,
encode_transient=hparams.encode_t,
in_channels_t=hparams.N_tau,
beta_min=hparams.beta_min)
self.models['fine'] = self.nerf_fine
self.models_to_train += [self.models]
def get_progress_bar_dict(self):
items = super().get_progress_bar_dict()
items.pop("v_num", None)
return items
def forward(self, rays, ts):
"""Do batched inference on rays using chunk."""
B = rays.shape[0]
results = defaultdict(list)
for i in range(0, B, self.hparams.chunk):
rendered_ray_chunks = \
render_rays(self.models,
self.embeddings,
rays[i:i+self.hparams.chunk],
ts[i:i+self.hparams.chunk],
self.hparams.N_samples,
self.hparams.use_disp,
self.hparams.perturb,
self.hparams.noise_std,
self.hparams.N_importance,
self.hparams.chunk, # chunk size is effective in val mode
self.train_dataset.white_back)
for k, v in rendered_ray_chunks.items():
results[k] += [v]
for k, v in results.items():
results[k] = torch.cat(v, 0)
return results
def setup(self, stage):
dataset = dataset_dict[self.hparams.dataset_name]
kwargs = {'root_dir': self.hparams.root_dir}
if self.hparams.dataset_name == 'phototourism':
kwargs['img_downscale'] = self.hparams.img_downscale
kwargs['val_num'] = self.hparams.num_gpus
kwargs['use_cache'] = self.hparams.use_cache
elif self.hparams.dataset_name == 'blender':
kwargs['img_wh'] = tuple(self.hparams.img_wh)
kwargs['perturbation'] = self.hparams.data_perturb
self.train_dataset = dataset(split='train', **kwargs)
self.val_dataset = dataset(split='val', **kwargs)
def configure_optimizers(self):
self.optimizer = get_optimizer(self.hparams, self.models_to_train)
scheduler = get_scheduler(self.hparams, self.optimizer)
return [self.optimizer], [scheduler]
def train_dataloader(self):
return DataLoader(self.train_dataset,
shuffle=True,
num_workers=4,
batch_size=self.hparams.batch_size,
pin_memory=True)
def val_dataloader(self):
return DataLoader(self.val_dataset,
shuffle=False,
num_workers=4,
batch_size=1, # validate one image (H*W rays) at a time
pin_memory=True)
def training_step(self, batch, batch_nb):
rays, rgbs, ts = batch['rays'], batch['rgbs'], batch['ts']
results = self(rays, ts)
loss_d = self.loss(results, rgbs)
loss = sum(l for l in loss_d.values())
with torch.no_grad():
typ = 'fine' if 'rgb_fine' in results else 'coarse'
psnr_ = psnr(results[f'rgb_{typ}'], rgbs)
self.log('lr', get_learning_rate(self.optimizer))
self.log('train/loss', loss)
for k, v in loss_d.items():
self.log(f'train/{k}', v, prog_bar=True)
self.log('train/psnr', psnr_, prog_bar=True)
return loss
def validation_step(self, batch, batch_nb):
rays, rgbs, ts = batch['rays'], batch['rgbs'], batch['ts']
rays = rays.squeeze() # (H*W, 3)
rgbs = rgbs.squeeze() # (H*W, 3)
ts = ts.squeeze() # (H*W)
results = self(rays, ts)
loss_d = self.loss(results, rgbs)
loss = sum(l for l in loss_d.values())
log = {'val_loss': loss}
typ = 'fine' if 'rgb_fine' in results else 'coarse'
if batch_nb == 0:
if self.hparams.dataset_name == 'phototourism':
WH = batch['img_wh']
W, H = WH[0, 0].item(), WH[0, 1].item()
else:
W, H = self.hparams.img_wh
img = results[f'rgb_{typ}'].view(H, W, 3).permute(2, 0, 1).cpu() # (3, H, W)
img_gt = rgbs.view(H, W, 3).permute(2, 0, 1).cpu() # (3, H, W)
depth = visualize_depth(results[f'depth_{typ}'].view(H, W)) # (3, H, W)
stack = torch.stack([img_gt, img, depth]) # (3, 3, H, W)
self.logger.experiment.add_images('val/GT_pred_depth',
stack, self.global_step)
psnr_ = psnr(results[f'rgb_{typ}'], rgbs)
log['val_psnr'] = psnr_
return log
def validation_epoch_end(self, outputs):
mean_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
mean_psnr = torch.stack([x['val_psnr'] for x in outputs]).mean()
self.log('val/loss', mean_loss)
self.log('val/psnr', mean_psnr, prog_bar=True)
__init __.py
这个文件里面主要优化optimizer方面的代码
(可以对比下2份代码的优化器,差别不大,不过多介绍就提一下)
代码中给出了四种可能的优化器选择:SGD、Adam、RAdam和Ranger。根据所选的优化器,函数使用给定的超参数(如学习率、动量、权重衰减等)来初始化优化器对象。
最后,函数返回初始化的优化器对象。
因此,这段代码的作用是根据超参数和模型选择合适的优化器,并返回初始化后的优化器对象。
Nerf----------Wild
import torch
# optimizer
from torch.optim import SGD, Adam
import torch_optimizer as optim
# scheduler
from torch.optim.lr_scheduler import CosineAnnealingLR, MultiStepLR
from .warmup_scheduler import GradualWarmupScheduler
from .visualization import *
def get_parameters(models):
"""Get all model parameters recursively."""
parameters = []
if isinstance(models, list):
for model in models:
parameters += get_parameters(model)
elif isinstance(models, dict):
for model in models.values():
parameters += get_parameters(model)
else: # models is actually a single pytorch model
parameters += list(models.parameters())
return parameters
# 在这里是选择优化器
def get_optimizer(hparams, models):
eps = 1e-8
parameters = get_parameters(models)
if hparams.optimizer == 'sgd':
optimizer = SGD(parameters, lr=hparams.lr,
momentum=hparams.momentum, weight_decay=hparams.weight_decay)
elif hparams.optimizer == 'adam':
optimizer = Adam(parameters, lr=hparams.lr, eps=eps,
weight_decay=hparams.weight_decay)
elif hparams.optimizer == 'radam':
optimizer = optim.RAdam(parameters, lr=hparams.lr, eps=eps,
weight_decay=hparams.weight_decay)
elif hparams.optimizer == 'ranger':
optimizer = optim.Ranger(parameters, lr=hparams.lr, eps=eps,
weight_decay=hparams.weight_decay)
else:
raise ValueError('optimizer not recognized!')
return optimizer
def get_scheduler(hparams, optimizer):
eps = 1e-8
if hparams.lr_scheduler == 'steplr':
scheduler = MultiStepLR(optimizer, milestones=hparams.decay_step,
gamma=hparams.decay_gamma)
elif hparams.lr_scheduler == 'cosine':
scheduler = CosineAnnealingLR(optimizer, T_max=hparams.num_epochs, eta_min=eps)
elif hparams.lr_scheduler == 'poly':
scheduler = LambdaLR(optimizer,
lambda epoch: (1-epoch/hparams.num_epochs)**hparams.poly_exp)
else:
raise ValueError('scheduler not recognized!')
if hparams.warmup_epochs > 0 and hparams.optimizer not in ['radam', 'ranger']:
scheduler = GradualWarmupScheduler(optimizer, multiplier=hparams.warmup_multiplier,
total_epoch=hparams.warmup_epochs, after_scheduler=scheduler)
return scheduler
# 选择超参数 学习率
def get_learning_rate(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def extract_model_state_dict(ckpt_path, model_name='model', prefixes_to_ignore=[]):
checkpoint = torch.load(ckpt_path, map_location=torch.device('cpu'))
checkpoint_ = {}
if 'state_dict' in checkpoint: # if it's a pytorch-lightning checkpoint
checkpoint = checkpoint['state_dict']
for k, v in checkpoint.items():
if not k.startswith(model_name):
continue
k = k[len(model_name)+1:]
for prefix in prefixes_to_ignore:
if k.startswith(prefix):
print('ignore', k)
break
else:
checkpoint_[k] = v
return checkpoint_
def load_ckpt(model, ckpt_path, model_name='model', prefixes_to_ignore=[]):
model_dict = model.state_dict()
checkpoint_ = extract_model_state_dict(ckpt_path, model_name, prefixes_to_ignore)
model_dict.update(checkpoint_)
model.load_state_dict(model_dict)
Nerf ---------optimizer
import math
import torch
from torch.optim.optimizer import Optimizer, required
import itertools as it
class RAdam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, degenerated_to_sgd=True):
if not 0.0 <= lr:
raise ValueError("Invalid learning rate: {}".format(lr))
if not 0.0 <= eps:
raise ValueError("Invalid epsilon value: {}".format(eps))
if not 0.0 <= betas[0] < 1.0:
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
self.degenerated_to_sgd = degenerated_to_sgd
if isinstance(params, (list, tuple)) and len(params) > 0 and isinstance(params[0], dict):
for param in params:
if 'betas' in param and (param['betas'][0] != betas[0] or param['betas'][1] != betas[1]):
param['buffer'] = [[None, None, None] for _ in range(10)]
defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay, buffer=[[None, None, None] for _ in range(10)])
super(RAdam, self).__init__(params, defaults)
def __setstate__(self, state):
super(RAdam, self).__setstate__(state)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError('RAdam does not support sparse gradients')
p_data_fp32 = p.data.float()
state = self.state[p]
if len(state) == 0:
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
exp_avg.mul_(beta1).add_(1 - beta1, grad)
state['step'] += 1
buffered = group['buffer'][int(state['step'] % 10)]
if state['step'] == buffered[0]:
N_sma, step_size = buffered[1], buffered[2]
else:
buffered[0] = state['step']
beta2_t = beta2 ** state['step']
N_sma_max = 2 / (1 - beta2) - 1
N_sma = N_sma_max - 2 * state['step'] * beta2_t / (1 - beta2_t)
buffered[1] = N_sma
# more conservative since it's an approximated value
if N_sma >= 5:
step_size = math.sqrt((1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2)) / (1 - beta1 ** state['step'])
elif self.degenerated_to_sgd:
step_size = 1.0 / (1 - beta1 ** state['step'])
else:
step_size = -1
buffered[2] = step_size
# more conservative since it's an approximated value
if N_sma >= 5:
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
denom = exp_avg_sq.sqrt().add_(group['eps'])
p_data_fp32.addcdiv_(-step_size * group['lr'], exp_avg, denom)
p.data.copy_(p_data_fp32)
elif step_size > 0:
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
p_data_fp32.add_(-step_size * group['lr'], exp_avg)
p.data.copy_(p_data_fp32)
return loss
class PlainRAdam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, degenerated_to_sgd=True):
if not 0.0 <= lr:
raise ValueError("Invalid learning rate: {}".format(lr))
if not 0.0 <= eps:
raise ValueError("Invalid epsilon value: {}".format(eps))
if not 0.0 <= betas[0] < 1.0:
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
self.degenerated_to_sgd = degenerated_to_sgd
defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay)
super(PlainRAdam, self).__init__(params, defaults)
def __setstate__(self, state):
super(PlainRAdam, self).__setstate__(state)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError('RAdam does not support sparse gradients')
p_data_fp32 = p.data.float()
state = self.state[p]
if len(state) == 0:
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
exp_avg.mul_(beta1).add_(1 - beta1, grad)
state['step'] += 1
beta2_t = beta2 ** state['step']
N_sma_max = 2 / (1 - beta2) - 1
N_sma = N_sma_max - 2 * state['step'] * beta2_t / (1 - beta2_t)
# more conservative since it's an approximated value
if N_sma >= 5:
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
step_size = group['lr'] * math.sqrt((1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2)) / (1 - beta1 ** state['step'])
denom = exp_avg_sq.sqrt().add_(group['eps'])
p_data_fp32.addcdiv_(-step_size, exp_avg, denom)
p.data.copy_(p_data_fp32)
elif self.degenerated_to_sgd:
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
step_size = group['lr'] / (1 - beta1 ** state['step'])
p_data_fp32.add_(-step_size, exp_avg)
p.data.copy_(p_data_fp32)
return loss
class AdamW(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, warmup = 0):
if not 0.0 <= lr:
raise ValueError("Invalid learning rate: {}".format(lr))
if not 0.0 <= eps:
raise ValueError("Invalid epsilon value: {}".format(eps))
if not 0.0 <= betas[0] < 1.0:
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
defaults = dict(lr=lr, betas=betas, eps=eps,
weight_decay=weight_decay, warmup = warmup)
super(AdamW, self).__init__(params, defaults)
def __setstate__(self, state):
super(AdamW, self).__setstate__(state)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError('Adam does not support sparse gradients, please consider SparseAdam instead')
p_data_fp32 = p.data.float()
state = self.state[p]
if len(state) == 0:
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
state['step'] += 1
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
exp_avg.mul_(beta1).add_(1 - beta1, grad)
denom = exp_avg_sq.sqrt().add_(group['eps'])
bias_correction1 = 1 - beta1 ** state['step']
bias_correction2 = 1 - beta2 ** state['step']
if group['warmup'] > state['step']:
scheduled_lr = 1e-8 + state['step'] * group['lr'] / group['warmup']
else:
scheduled_lr = group['lr']
step_size = scheduled_lr * math.sqrt(bias_correction2) / bias_correction1
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * scheduled_lr, p_data_fp32)
p_data_fp32.addcdiv_(-step_size, exp_avg, denom)
p.data.copy_(p_data_fp32)
return loss
#Ranger deep learning optimizer - RAdam + Lookahead combined.
#https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
#Ranger has now been used to capture 12 records on the FastAI leaderboard.
#This version = 9.3.19
#Credits:
#RAdam --> https://github.com/LiyuanLucasLiu/RAdam
#Lookahead --> rewritten by lessw2020, but big thanks to Github @LonePatient and @RWightman for ideas from their code.
#Lookahead paper --> MZhang,G Hinton https://arxiv.org/abs/1907.08610
#summary of changes:
#full code integration with all updates at param level instead of group, moves slow weights into state dict (from generic weights),
#supports group learning rates (thanks @SHolderbach), fixes sporadic load from saved model issues.
#changes 8/31/19 - fix references to *self*.N_sma_threshold;
#changed eps to 1e-5 as better default than 1e-8.
class Ranger(Optimizer):
def __init__(self, params, lr=1e-3, alpha=0.5, k=6, N_sma_threshhold=5, betas=(.95, 0.999), eps=1e-5, weight_decay=0):
#parameter checks
if not 0.0 <= alpha <= 1.0:
raise ValueError(f'Invalid slow update rate: {alpha}')
if not 1 <= k:
raise ValueError(f'Invalid lookahead steps: {k}')
if not lr > 0:
raise ValueError(f'Invalid Learning Rate: {lr}')
if not eps > 0:
raise ValueError(f'Invalid eps: {eps}')
#parameter comments:
# beta1 (momentum) of .95 seems to work better than .90...
#N_sma_threshold of 5 seems better in testing than 4.
#In both cases, worth testing on your dataset (.90 vs .95, 4 vs 5) to make sure which works best for you.
#prep defaults and init torch.optim base
defaults = dict(lr=lr, alpha=alpha, k=k, step_counter=0, betas=betas, N_sma_threshhold=N_sma_threshhold, eps=eps, weight_decay=weight_decay)
super().__init__(params,defaults)
#adjustable threshold
self.N_sma_threshhold = N_sma_threshhold
#now we can get to work...
#removed as we now use step from RAdam...no need for duplicate step counting
#for group in self.param_groups:
# group["step_counter"] = 0
#print("group step counter init")
#look ahead params
self.alpha = alpha
self.k = k
#radam buffer for state
self.radam_buffer = [[None,None,None] for ind in range(10)]
#self.first_run_check=0
#lookahead weights
#9/2/19 - lookahead param tensors have been moved to state storage.
#This should resolve issues with load/save where weights were left in GPU memory from first load, slowing down future runs.
#self.slow_weights = [[p.clone().detach() for p in group['params']]
# for group in self.param_groups]
#don't use grad for lookahead weights
#for w in it.chain(*self.slow_weights):
# w.requires_grad = False
def __setstate__(self, state):
print("set state called")
super(Ranger, self).__setstate__(state)
def step(self, closure=None):
loss = None
#note - below is commented out b/c I have other work that passes back the loss as a float, and thus not a callable closure.
#Uncomment if you need to use the actual closure...
#if closure is not None:
#loss = closure()
#Evaluate averages and grad, update param tensors
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError('Ranger optimizer does not support sparse gradients')
p_data_fp32 = p.data.float()
state = self.state[p] #get state dict for this param
if len(state) == 0: #if first time to run...init dictionary with our desired entries
#if self.first_run_check==0:
#self.first_run_check=1
#print("Initializing slow buffer...should not see this at load from saved model!")
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
#look ahead weight storage now in state dict
state['slow_buffer'] = torch.empty_like(p.data)
state['slow_buffer'].copy_(p.data)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
#begin computations
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
#compute variance mov avg
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
#compute mean moving avg
exp_avg.mul_(beta1).add_(1 - beta1, grad)
state['step'] += 1
buffered = self.radam_buffer[int(state['step'] % 10)]
if state['step'] == buffered[0]:
N_sma, step_size = buffered[1], buffered[2]
else:
buffered[0] = state['step']
beta2_t = beta2 ** state['step']
N_sma_max = 2 / (1 - beta2) - 1
N_sma = N_sma_max - 2 * state['step'] * beta2_t / (1 - beta2_t)
buffered[1] = N_sma
if N_sma > self.N_sma_threshhold:
step_size = math.sqrt((1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2)) / (1 - beta1 ** state['step'])
else:
step_size = 1.0 / (1 - beta1 ** state['step'])
buffered[2] = step_size
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
if N_sma > self.N_sma_threshhold:
denom = exp_avg_sq.sqrt().add_(group['eps'])
p_data_fp32.addcdiv_(-step_size * group['lr'], exp_avg, denom)
else:
p_data_fp32.add_(-step_size * group['lr'], exp_avg)
p.data.copy_(p_data_fp32)
#integrated look ahead...
#we do it at the param level instead of group level
if state['step'] % group['k'] == 0:
slow_p = state['slow_buffer'] #get access to slow param tensor
slow_p.add_(self.alpha, p.data - slow_p) #(fast weights - slow weights) * alpha
p.data.copy_(slow_p) #copy interpolated weights to RAdam param tensor
return loss