Mysql专栏:@Mysql
本篇博客简介:介绍数据库的库操作
库的操作
- 创建数据库
- 创建数据库案例
- 字符集和校验规则
- 查看系统默认字符集和校验规则
- 查看数据库支持的字符集和校验规则
- 校验规则对于数据库的影响
- 操纵数据库
- 查看数据库
- 显示创建语句
- 修改数据库
- 数据库删除
- 查看连接情况
创建数据库
创建数据库的语法格式如下
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_nam
- 大写的表示关键字 (其实mysql中大小写并不严格 所以我们使用小写关键字也可以 )
- [] 是可选项
- CHARACTER SET: 指定数据库采用的字符集
- COLLATE: 指定数据库字符集的校验规则
什么是字符集和校验规则
我们简单理解下 字符集就是向计算机中存储数据的格式 校验规则就是从计算机中取出数据的格式
创建数据库案例
创建名为db1的数据库
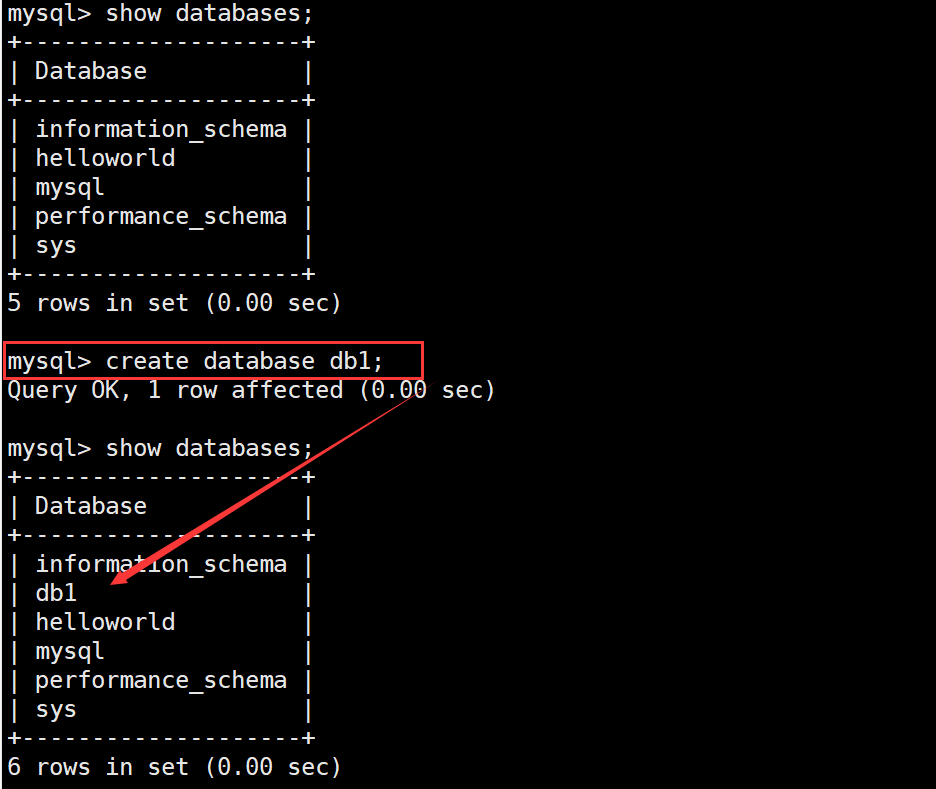
说明:当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则
是:utf8_ general_ ci
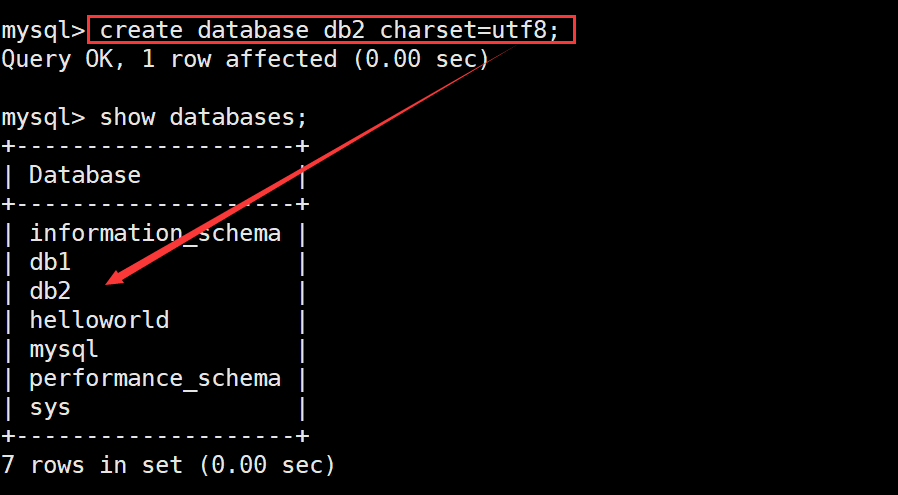
创建一个使用utf8字符集的 db2 数据库
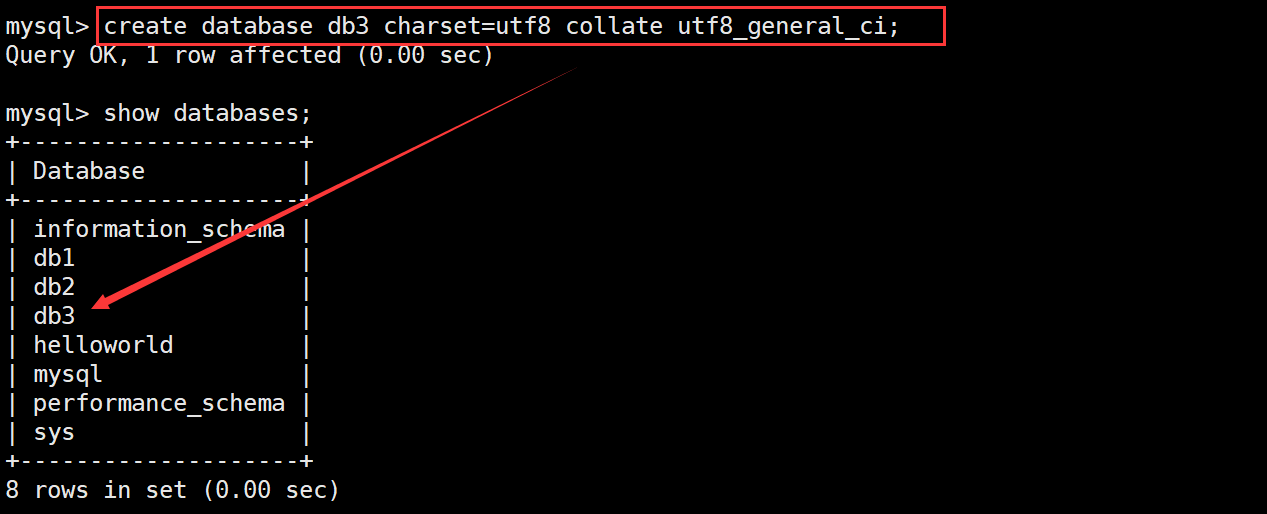
创建一个使用utf字符集 并带校对规则的 db3 数据库
字符集和校验规则
什么是字符集和校验规则
我们简单理解下 字符集就是向计算机中存储数据的格式 校验规则就是从计算机中取出数据的格式
一般来说字符集和校验规则是要配套的
查看系统默认字符集和校验规则
show variables like 'character_set_database';
show variables like 'collation_database';
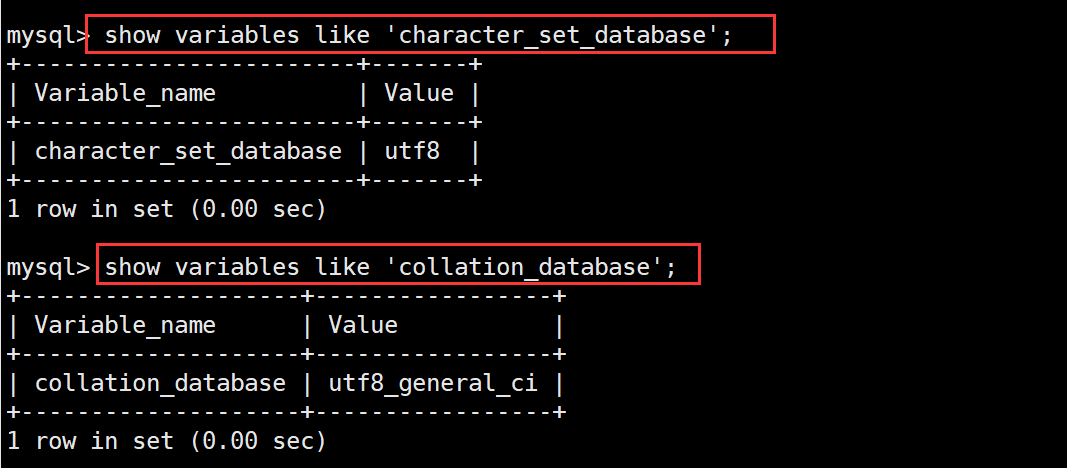
查看数据库支持的字符集和校验规则
show charset // 查看支持的字符集
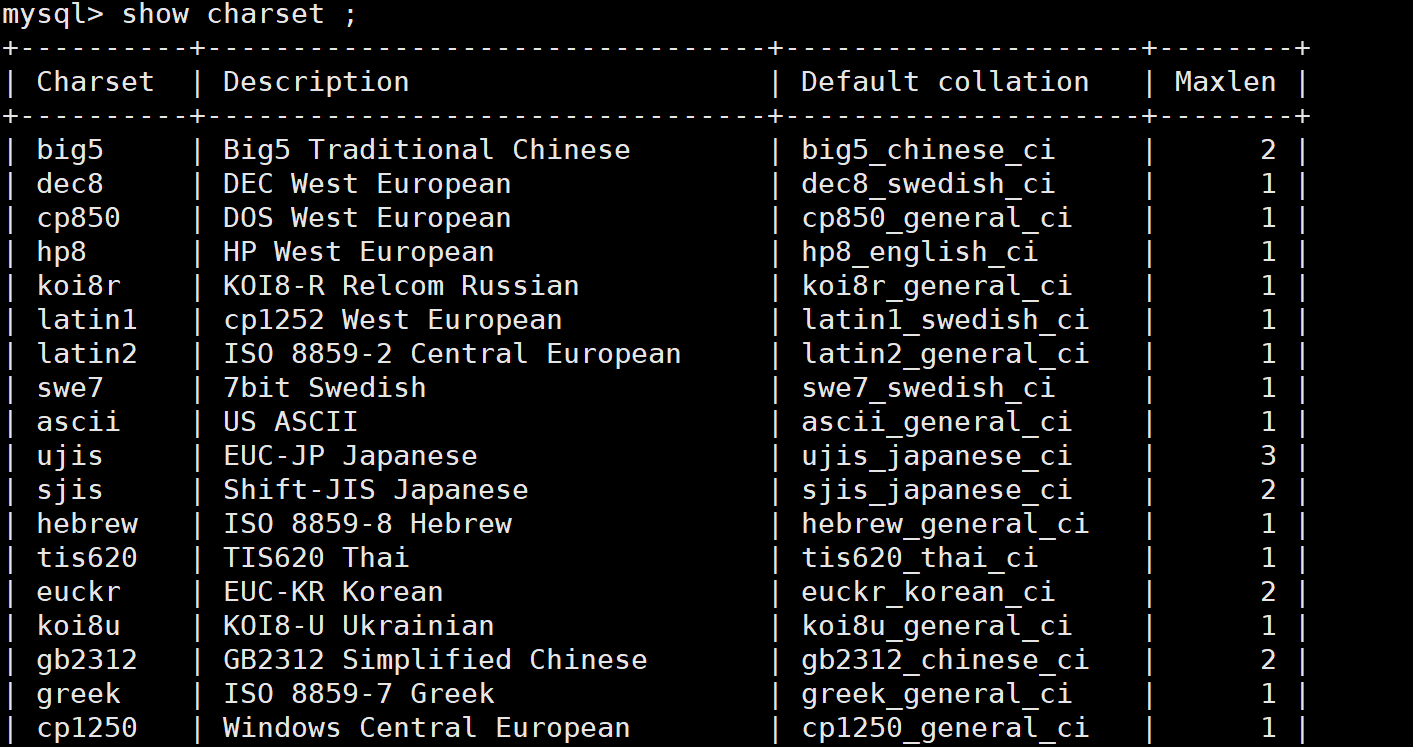
show collation; // 查看支持的字符集校验规则
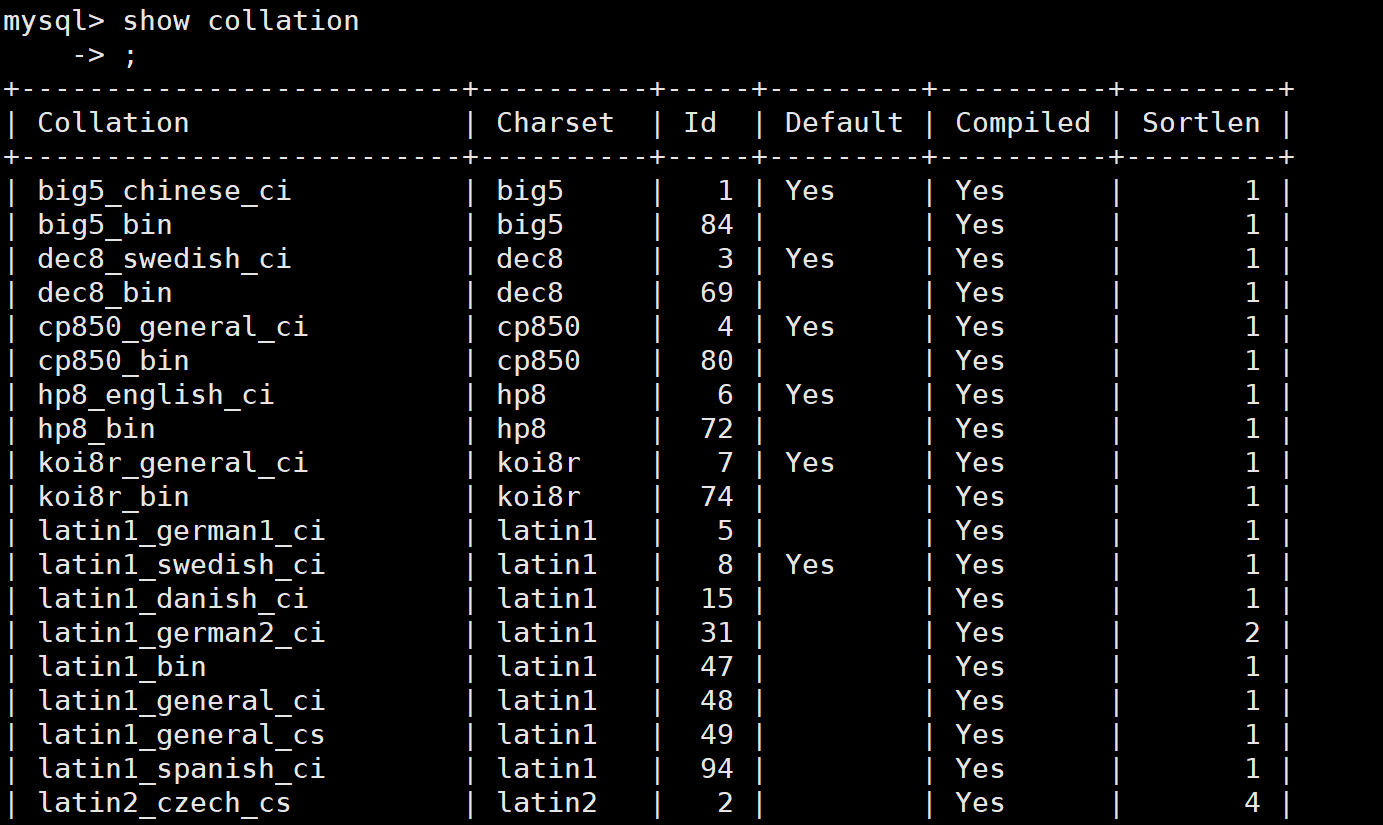
校验规则对于数据库的影响
创建一个数据库 校验规则使用utf8_ general_ ci[不区分大小写]
create database test1 collate utf8_general_ci
use test1;
create table person(name varchar(20));
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');
创建一个数据库 校验规则使用utf8_ bin[区分大小写]
create database test2 collate utf8_bin;
use test2
create table person(name varchar(20));
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');
表的字符集校验规则默认是数据库的字符集校验规则
之后我们分别对于这两个表进行查询和排序
查询
不区分大小写
mysql> use test1;
mysql> select * from person where name='a';
+------+
| name |
+------+
| a |
| A |
+------+
2 rows in set (0.01 sec)
区分大小写
mysql> use test2;
mysql> select * from person where name='a';
+------+
| name |
+------+
| a |
+------+
2 rows in set (0.01 sec)
结果排序
不区分大小写
mysql> use test1;
mysql> select * from person order by name;
+------+
| name |
+------+
| a |
| A |
| b |
| B |
+------+
区分大小写
mysql> use test2;
mysql> select * from person order by name;
+------+
| name |
+------+
| A |
| B |
| a |
| b |
+------+
通过上面的两组对比我们可以很明显的发现字符集的校验规则能够影响到数据的查询和排序
操纵数据库
查看数据库
语法:
show databases;
显示创建语句
语法:
show create database test1;
它的作用是显示创建数据库的语句
比如说我们使用gbk字符集创建test1数据库 之后使用显示创建语句
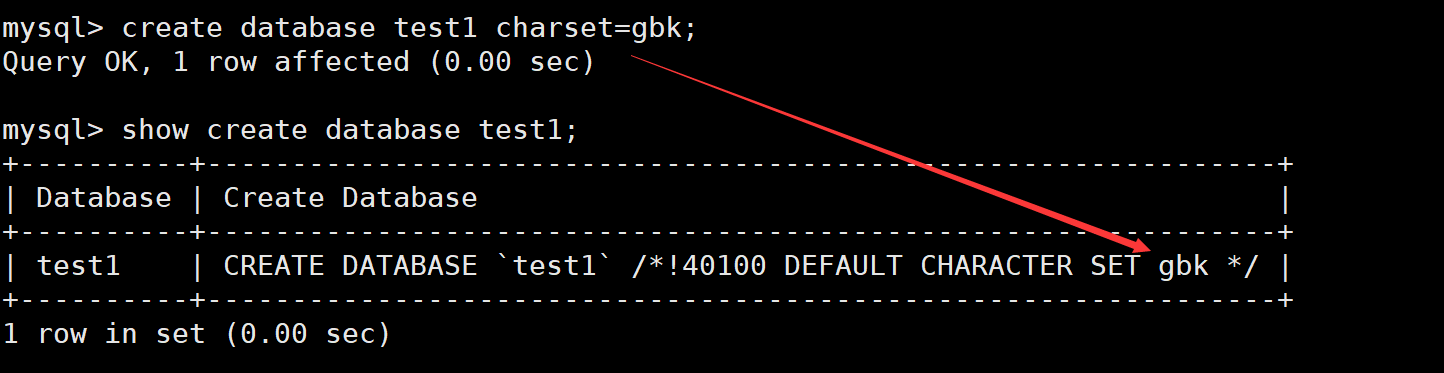
我们可以发现在下面的记录中展示了test1数据库的字符集
需要注意的是
- 数据库名字的反引号``,是为了防止使用的数据库名刚好是关键字
- /*!40100 default… */ 这个不是注释 表示当前mysql版本大于4.01版本 就执行这句话
修改数据库
一般来说我们修改数据库就是修改数据库的字符集还有校验规则
修改数据库名字和属性都是很危险的事情 很可能会导致一系列的问题
语法如下
ALTER DATABASE db_name
[alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
比如说我们修改test1数据库的字符集为utf8
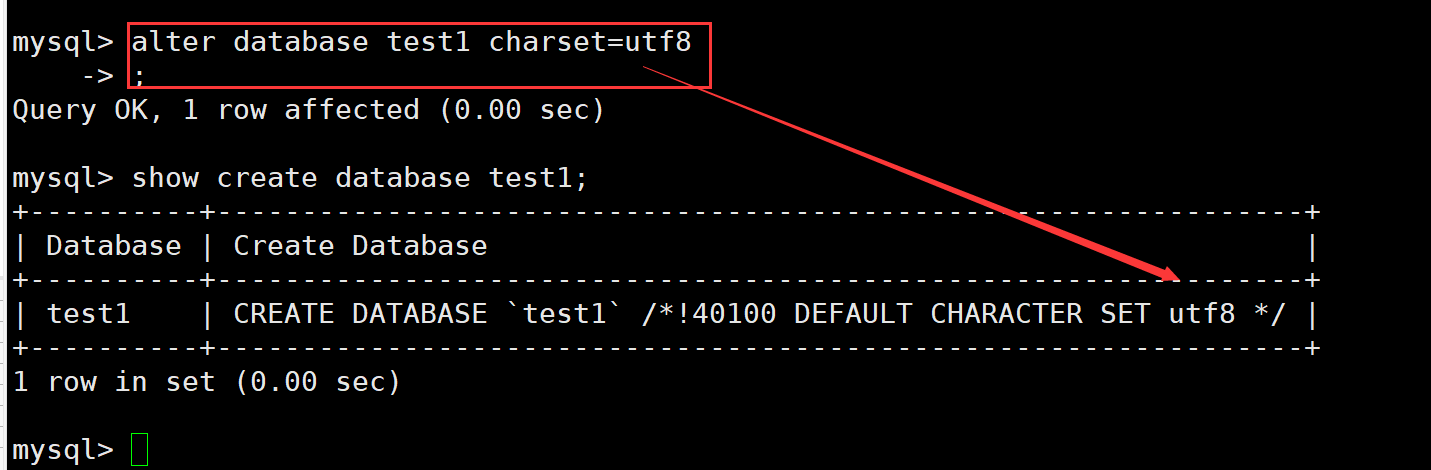
我们可以看到字符集成功被修改为utf8了
数据库删除
语法:
DROP DATABASE [IF EXISTS] db_ name;
比如说我们要删除test1数据库
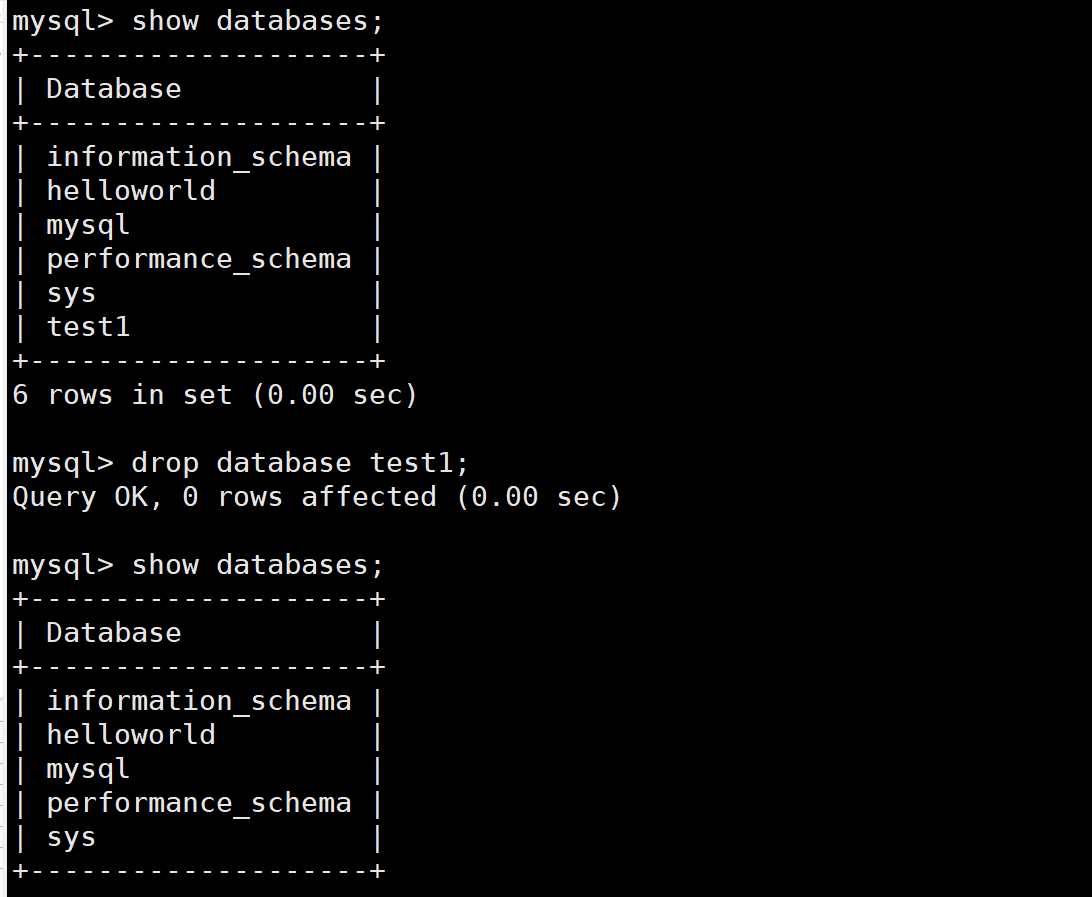
此外还有一种方法可以删除数据库
我们可以使用Linux的管理员权限进入保存数据库数据的目录下 直接删除对应目录即可
查看连接情况
语法:
show processlist

从左到右介绍下第一列的含义
- id : mysql中对于用户的一个标识
- user:当前用户
- host :主机
- db:正在访问的数据库
- command:显示当前连接执行的命令
- time:显示线程执行当前状态的时间
- state:当前连接sql语句的状态
- info:线程执行的语句
当我们发现自己的数据库运行速度较慢的时候 可以通过该指令来查询访问数据库的用户 如果查出哪个用户不是正常登录的 那么很可能是你的数据库被黑入了