今天看到一个比较热门的项目就是来自于北大研究团队刚刚开源的chatLaw法律领域数据开发构建的大模型,官方项目地址在这里,如下所示:

目前已经收货2.1k的star量还是很不错的了。
官方提供的学术报告文章地址在这里,如下所示:



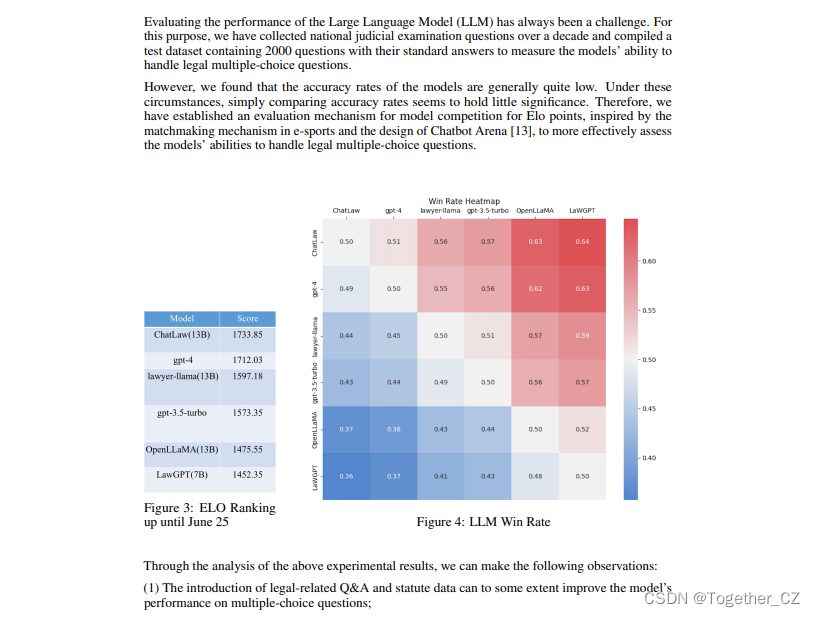
感兴趣的话可以仔细看下。
官方同时也给提供了可以在线体验使用的Demo网站,地址在这里,如下所示:

使用实例如下所示:
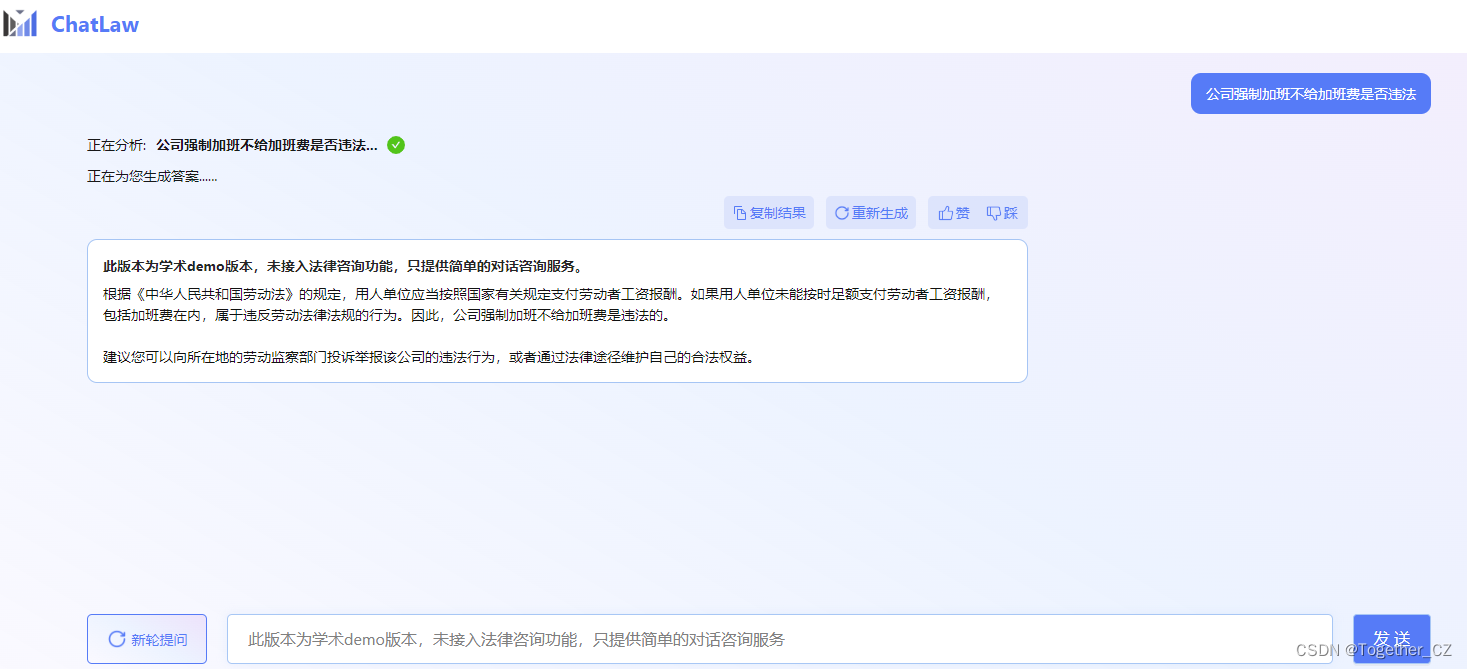
简单地使用了一下还好,感兴趣的胡也可以体验一下。
官方使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型ChatLaw-Text2Vec,可将用户提问信息和对应的法条相匹配,地址在这里,如下所示:

数据实例如下所示:
| sentence1 | sentence2 | score |
|---|---|---|
| 股权转让合同的双方就转让对价未达成合意,导致已签订的股权转让协议不具有可履行性的,应认定该转让协议不成立。 | 有限责任公司的股东会决议确认了有关股东之间股权转让的相关事宜,但对转让价款规定不明确,当事人不能达成补充协议的,讼争股东之间的股权转让合同是否成立? | 1 |
| 租赁房屋消防要求不达标,能否导致合同目的不能实现,合同是否当然无效的问题。 | 原审认为,二被告作为承租人租赁的是一般房屋,双方对租赁物了解,标的物是符合合同要求的。租赁房屋存在与相邻建筑防火间距不足,疏散通道的宽度不够的问题。该标的物的相邻建筑防火间距和疏散通道宽度均达不到国家标准。承租人取得租赁房屋后从事宾馆经营,提升了消防要求,但阻隔合同目的实现不是必然的,不支持合同无效。 再审认为,该租赁房屋在建成后,一直作为服务性经营场所,本案提及的消防问题,程度不一的存在。但未发现以前有行政管理部门禁止其经营的记录。本次公安消防的通知是整改,并不是禁止经营。公安部2012年颁布的《建设工程消防监督管理规定》强制消防要求达标的范围,是指在50米以下的建筑物。也就是该房屋作为租赁物建立合同关系,不违反国家的强制性规定。参照最高人民法院[2003]民一他字第11号函复《关于未经消防验收合格而订立的房屋租赁合同如何认定其效力》的相关意见,认定双方签订的租赁合同成立并有效。 | 1 |
数据实例如下所示:
Examples
请问夫妻之间共同财产如何定义?
- 最高人民法院关于适用《婚姻法》若干问题的解释(三)(2011-08-09): 第五条 夫妻一方个人财产在婚后产生的收益,除孳息和自然增值外,应认定为夫妻共同财产。
- 最高人民法院关于适用《婚姻法》若干问题的解释(二)的补充规定(2017-02-28): 第十九条 由一方婚前承租、婚后用共同财产购买的房屋,房屋权属证书登记在一方名下的,应当认定为夫妻共同财产。
- 最高人民法院关于适用《婚姻法》若干问题的解释(二)的补充规定(2017-02-28): 第二十二条 当事人结婚前,父母为双方购置房屋出资的,该出资应当认定为对自己子女的个人赠与,但父母明确表示赠与双方的除外。当事人结婚后,父母为双方购置房屋出资的,该出资应当认定为对夫妻双方的赠与,但父母明确表示赠与一方的除外。
请问民间借贷的利息有什么限制
- 合同法(1999-03-15): 第二百零六条 借款人应当按照约定的期限返还借款。对借款期限没有约定或者约定不明确,依照本法第六十一条的规定仍不能确定的,借款人可以随时返还;贷款人可以催告借款人在合理期限内返还。
- 合同法(1999-03-15): 第二百零五条 借款人应当按照约定的期限支付利息。对支付利息的期限没有约定或者约定不明确,依照本法第六十一条的规定仍不能确定,借款期间不满一年的,应当在返还借款时一并支付;借款期间一年以上的,应当在每届满一年时支付,剩余期间不满一年的,应当在返还借款时一并支付。
- 最高人民法院关于审理民间借贷案件适用法律若干问题的规定(2020-08-19): 第二十六条 出借人请求借款人按照合同约定利率支付利息的,人民法院应予支持,但是双方约定的利率超过合同成立时一年期贷款市场报价利率四倍的除外。前款所称“一年期贷款市场报价利率”,是指中国人民银行授权全国银行间同业拆借中心自2019年8月20日起每月发布的一年期贷款市场报价利率。
代码实现如下所示:
from sentence_transformers import SentenceTransformer, LoggingHandler, losses, models, util
from sentence_transformers.util import cos_sim
model_path = "your_model_path"
model = SentenceTransformer(model_path).cuda()
sentence1 = "合同法(1999-03-15): 第二百零六条 借款人应当按照约定的期限返还借款。对借款期限没有约定或者约定不明确,依照本法第六十一条的规定仍不能确定的,借款人可以随时返还;贷款人可以催告借款人在合理期限内返还。"
sentence2 = "请问如果借款没还怎么办。"
encoded_sentence1 = model.encode(sentence1)
encoded_sentence2 = model.encode(sentence2)
print(cos_sim(encoded_sentence1, encoded_sentence2))
# tensor([[0.9960]])
模型权重文件如下所示:

官方一共开发构建了ChatLaw-13B和ChatLaw-33B两款模型。
其中:
ChatLaw-13B,此版本为学术demo版,基于姜子牙Ziya-LLaMA-13B-v1训练而来,中文各项表现很好,但是逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决。
Ziya-LLaMA-13B-v1项目地址在这里,如下所示:

可以看到:有不同参数量级的开源。可以根据自己的实际需要自行选择下载即可。
ChatLaw-33B,此版本为学术demo版,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据。
Anima官方项目地址在这里,如下所示:

第一个开源的基于QLoRA的33B中文大语言模型 the First QLoRA based 33B fully open-source Chinese LLM
为什么33B模型很重要?QLoRA是个Game Changer?
之前大部分开源可finetune的模型大都是比较小的模型7B或者13B,虽然可以在一些简单的chatbot评测集上,通过finetune训练有不错的表现。但是由于这些模型规模还是有限,LLM核心的reasoning的能力还是相对比较弱。这就是为什么很多这种小规模的模型在实际应用的场景表现像是个玩具。如这个工作中的论述:chatbot评测集比较简单,真正比较考验模型能力的复杂逻辑推理及数学问题上小模型和大模型差距还是很明显的。
因此我们认为QLoRA 的工作很重要,重要到可能是个Game Changer。通过QLoRA的优化方法,第一次让33B规模的模型可以比较民主化的,比较低成本的finetune训练,并且普及使用。我们认为33B模型既可以发挥大规模模型的比较强的reasoning能力,又可以针对私有业务领域数据进行灵活的finetune训练提升对于LLM的控制力。
官方readme也给了详细的使用介绍,如下所示:
Backbone模型选择
Anima模型基于QLoRA开源的33B guanaco训练了10000 steps。训练使用一个H100 GPU。
思考逻辑:本工作主要为了验证QLoRA训练方法的有效性,因此选择了基于QLoRA的Guanaco 33B finetune训练,这个训练更多的是增强模型的中文能力。Assume模型的基础logical reasoning和Knowledge能力已经足够。
训练数据选择
使用Chinese-Vicuna项目开放的训练数据集guanaco_belle_merge_v1.0进行finetune训练。
思考逻辑:按照QLoRA Appendix B.4和Table 9中的Grid Search的结论:对于QLoRA finetune,training sample量不一定越大越好。10000个steps是一个ROI比较优的size。因此我们希望选择一个不小于10000个steps的数据集。Belle 10M数据集似乎太大了,不确定数据质量如何。时间有限,先选择guanaco_belle_merge_v1.0。后边会进一步更系统性的测试更多的数据集和数据质量筛选的效果。
感谢:Chinese-Vicuna项目、Belle项目、GuanacoDataset的贡献。
超参选择
基于成本ROI平衡的考虑,没有做太多的grid search,基本的思路是follow QLoRA paper 的结论,因为QLoRA做了相对比较详尽的超参Grid Search实验:
Batch size: 16 (QLoRA Appendix B.4和Table 9)
Max steps: 10000 (QLoRA Appendix B.4和Table 9),更多的steps和更大的数据集的训练在进一步实验中,后续会持续更新。
Learning rate: 1e-4 (QLoRA Appendix B.4和Table 9)
LoRA r=64, alpha=16 (QLoRA Appendix B.2)
source_max_len=512, target_max_len=512,需要保证大部分的training sample没有truncate,能完整的把信息训练到模型中,根据脚本中的估计,512大概可以覆盖大部分的样本长度。
如何训练
重现Anima的模型训练过程:使用以下步骤可以重现Anima 33B模型(单卡80GB H100或双卡 40GB A100均测试过可运行):
# 1. install dependencies
pip install -r requirements.txt
# 2.
cd training
./run_Amina_training.sh
基于Anima finetune训练其他model:
# 1. install dependencies
pip install -r requirements.txt
# 2.
cd training
./run_finetune_raining_based_on_Anima.sh
注:可以修改run_finetune_raining_based_on_Anima.sh中的--dataset和--dataset_format参数使用其他训练数据dataset。
多卡训练
由于使用Hugging Face Accelerate,天然支持多卡训练。 我们测试过双卡40GB的A100,可以直接运行。使用代码如下所示:
# imports
from peft import PeftModel
from transformers import GenerationConfig, LlamaForCausalLM, LlamaTokenizer
import torch
# create tokenizer
base_model = "timdettmers/guanaco-33b-merged"
tokenizer = LlamaTokenizer.from_pretrained(base_model)
# base model
model = LlamaForCausalLM.from_pretrained(
base_model,
torch_dtype=torch.float16,
device_map="auto",
)
# LORA PEFT adapters
adapter_model = "lyogavin/Anima33B"
model = PeftModel.from_pretrained(
model,
adapter_model,
#torch_dtype=torch.float16,
)
model.eval()
# prompt
prompt = "中国的首都是哪里?"
inputs = tokenizer(prompt, return_tensors="pt")
# Generate
generate_ids = model.generate(**inputs, max_new_tokens=30)
print(tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0])
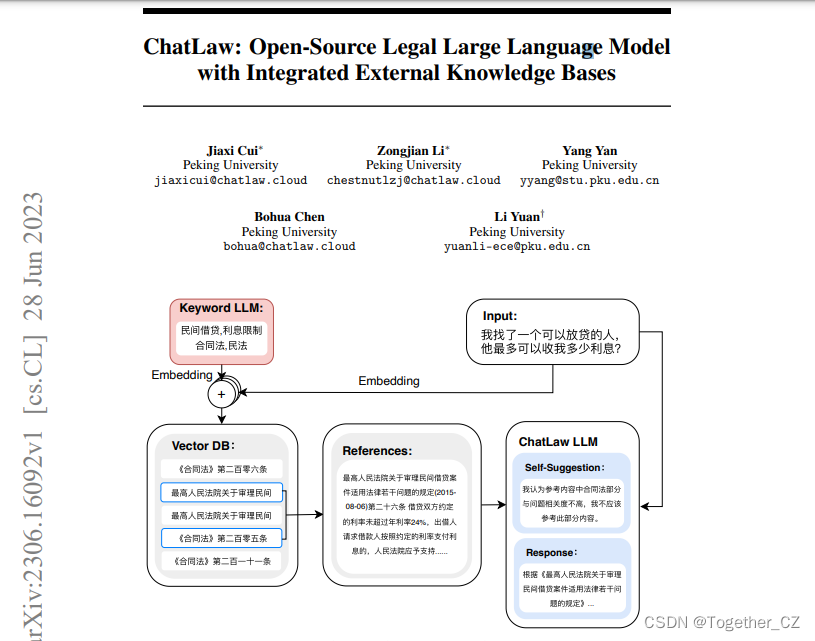
# output: '中国的首都是哪里?\n中国的首都是北京。\n北京位于中国北部,是中国历史悠'chatLaw整体流程如下所示:
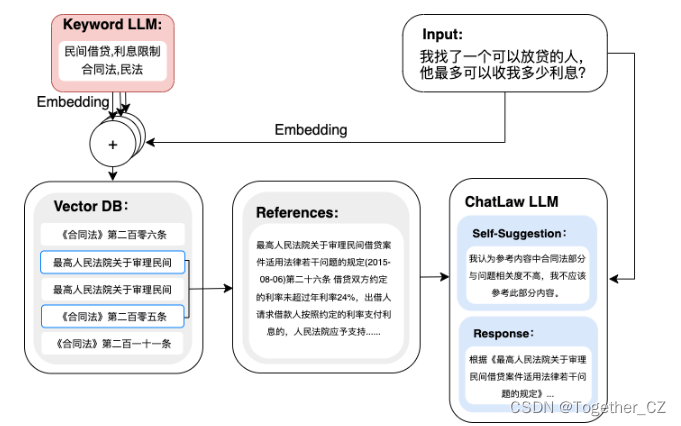
作者发现增加了训练数据,做成了ChatLaw-33B,逻辑推理能力大幅提升。说明大模型的突破点还是在于增加模型的参数量才是最关键的。
后面有时间再继续仔细研究下。