Generalized Category Discovery
- 摘要
- 1.导言
- 2.相关工作
- 3.广义类发现
- 3.1 我们的方法
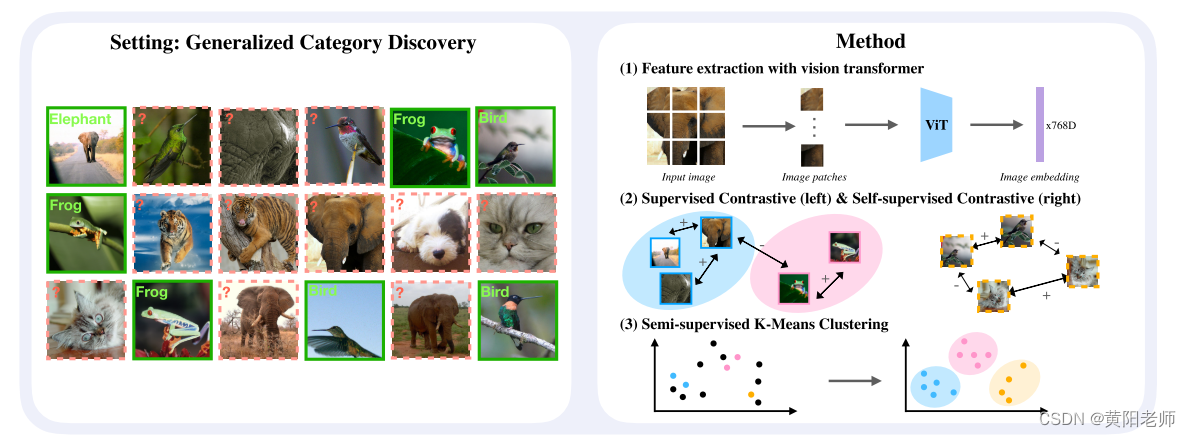
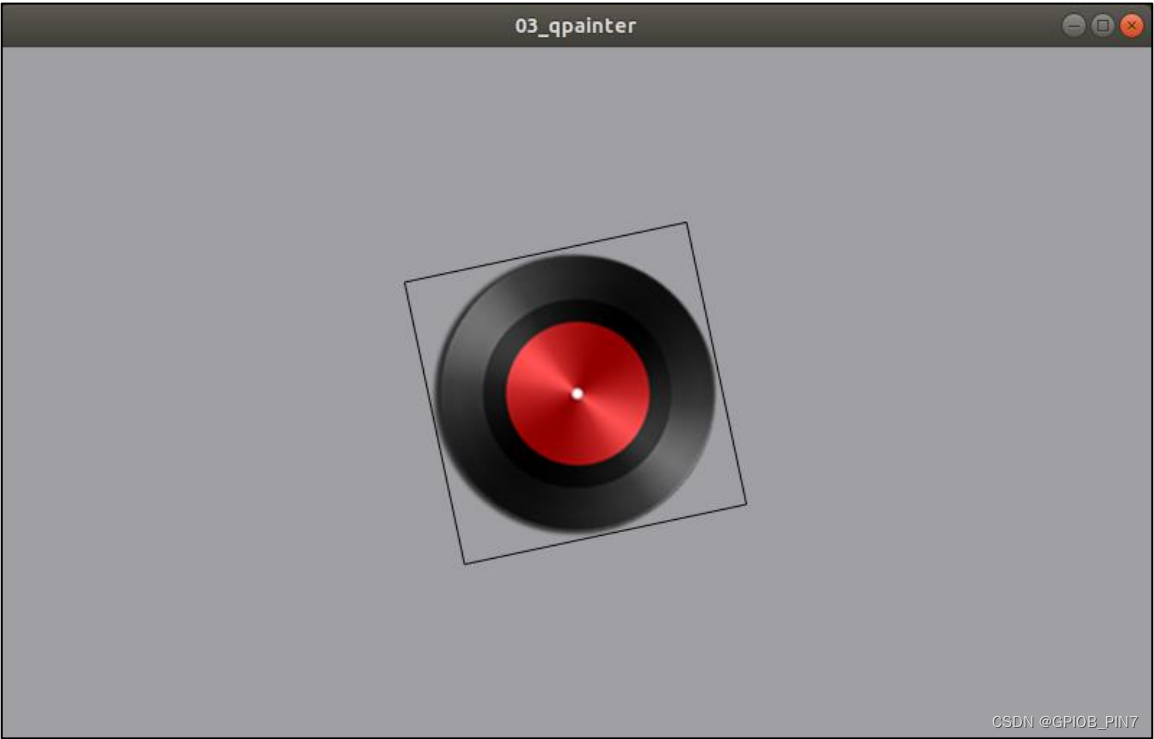
图1.我们提出一个新的设置:“广义类别发现”及其解决方法。我们的设置可以简洁地描述为:给定一个子集具有类标签的数据集,对数据集中所有未标记的图像进行分类。未标记的图像可以来自标记的或新的类别。我们的方法利用对比训练的视觉变换器直接通过聚类来分配标签。
摘要
在本文中,我们考虑了一个非常通用的图像识别场景,其中给定了一个带标签和无标签的图像集,任务是对所有无标签集中的图像进行分类。在这里,无标签图像可能来自带标签的类别,也可能来自新类别。现有的识别方法无法处理这种情况,因为它们做出了一些限制性的假设,比如无标签实例只来自已知的或未知的类别,并且未知类别的数量是先验已知的。我们处理更加不受约束的设置,将其称为“广义类别发现”,并挑战了所有这些假设。我们首先通过采用最新类别发现的最先进算法,并针对这个任务进行了调整,建立了强大的基准线。接下来,我们提出在这个开放世界的环境中使用具有对比度表示学习的视觉变换器。然后,我们引入了一种简单而有效的半监督K均值方法,将无标签数据自动聚类为已见和未见类别,大大优于基准线。最后,我们还提出了一种估计无标签数据中类别数量的新方法。我们在公共数据集上对我们的方法进行了全面评估,包括通用物体分类数据集和精细化数据集,利用了最近提出的语义变化基准套件。代码可在以下网址找到:https://www.robots.ox.ac.uk/∼vgg/research/gcd
1.导言
考虑一个坐在汽车里观察世界的婴儿。物体实例将经过汽车,对于其中的一些实例,婴儿可能已经被告知它们的类别(“那是一只狗”,“那是一辆车”),并能够识别它们。还会有一些婴儿以前没有见过的实例(猫和自行车),通过观察这些实例,我们可能期望婴儿的视觉识别系统将它们聚类成新的类别。
这是我们在这项工作中考虑的问题:给定一个图像数据集,其中只有一部分图像被标记了它们的类别,我们需要为剩下的图像分配一个类别标签,可能会使用在标记集中没有观察到的新类别。我们将这个问题称为广义类别发现(Generalized Category Discovery,GCD),并且认为这是许多机器视觉应用的一个现实使用案例:无论是在超市中识别产品,医学图像中的病理,还是自动驾驶中的车辆。在这些和其他现实的视觉场景中,往往无法确定新的图像来自已标记的类别还是新的类别。
相比之下,让我们来考虑现有图像识别设置的局限性。在图像分类中,这是其中一个被广泛研究的问题,所有的训练图像都有类别标签。此外,测试时的所有图像都来自于与训练集相同的类别。半监督学习(Semi-supervised Learning,SSL)[7]引入了从未标记数据中学习的问题,但仍假设所有未标记的图像来自于与标记图像相同的类别集合。最近,开放集识别(Open-Set Recognition,OSR)[38]和新类别发现(Novel-Category Discovery,NCD)[19]的任务针对的是开放世界的设置,测试时的图像可能属于新的类别。然而,OSR的目标仅仅是检测测试时的图像是否属于已标记集合中的类别之一,但不需要对这些检测到的图像进行进一步的分类。与此同时,NCD是与本工作所处理的问题最接近的设置,方法从已标记和未标记的图像中进行学习,旨在发现未标记集合中的新类别。然而,NCD仍然假设所有未标记的图像来自于新的类别,这通常是不现实的。
在本文中,我们采用多种方法来解决广义类别发现问题。首先,我们通过选择NCD中的代表性方法并将其应用到这个任务中,建立了强有力的基线模型。为此,我们调整它们的训练和推断机制以适应我们更一般的设置,并使用更强大的骨干网络架构进行重新训练。我们表明,在这个广义的设置中,现有的NCD方法容易对已标记的类别过拟合。
接下来,观察到NCD方法过拟合其分类头部到已标记类别的潜在问题,我们提出了一种简单而有效的聚类识别方法。我们的关键洞察是利用视觉变换器的强大的“最近邻”分类属性以及对比学习。我们提出了使用对比训练和半监督K均值聚类算法来识别没有参数化分类器的图像。我们表明,这些提出的方法在通用对象识别数据集以及更具挑战性的细粒度基准测试上明显优于已建立的基线方法。对于后一种评估,我们利用最近提出的语义漂移基准套件[45],该套件旨在识别语义新颖性。
最后,我们提出了一个在图像识别中具有挑战性且未经充分研究的问题的解决方案:估计未标记数据中的类别数目。几乎所有方法,包括纯无监督方法,都假设了对类别数目的了解,这在现实世界中是一个非常不现实的假设。我们提出了一种算法,利用已标记的数据集来解决这个问题。
我们的贡献可以总结如下:
(i) 将广义类别发现(GCD)形式化为图像识别中的一个新而现实的设置;
(ii) 通过将标准的新类别发现技术应用于该任务,建立了强大的基准线;
(iii) 提出了一种简单而有效的GCD方法,利用对比表示学习和聚类直接提供类别标签,并显著优于基准线;
(iv) 提出了一种估计未标记数据中类别数目的新方法,这是一个很少研究的问题;
(v) 在标准图像识别数据集以及最近的语义漂移基准套件[45]上进行了严格的评估。
2.相关工作
我们的工作与半监督学习、开放集识别和新类别发现的先前工作相关,下面我们简要回顾一下这些工作。
半监督学习:已经提出了许多方法来解决半监督学习(SSL)的问题[7, 33, 37, 40, 49]。SSL假设有标记和未标记的实例来自同一组类别。其目标是在训练过程中利用标记和未标记数据来学习一个鲁棒的分类模型。在现有的方法中,基于一致性的方法似乎很受欢迎且有效,例如LadderNet [36]、PI模型 [29]和Mean-teacher [43]。最近,随着自监督学习的成功,还提出了通过添加自监督目标来改进SSL的方法[37, 49]。
开放集识别:开放集识别(OSR)的问题在文献[38]中得到了形式化,其目标是对来自与标记数据相同语义类别的未标记实例进行分类,同时检测来自未知类别的测试实例。OpenMax [3]是第一个使用极值理论来解决这个问题的深度学习方法。通常使用生成对抗网络(GANs)来生成对抗样本以训练开放集分类器,例如[14, 25, 32]。已经提出了几种方法来训练模型,使得具有较大重构误差的图像被视为开放集样本[34, 41, 48]。还有一些方法通过与原型之间的距离来学习标记类别的原型,并通过与原型的距离来识别未知类别的图像[8, 9, 39]。最近,[8, 9]提出了学习描述与标记类别相对的"其他性"的互补点。[50]同时训练了基于流的密度估计器和基于分类的编码器来进行OSR。最后,Vaze等人[45]研究了封闭集和开放集性能之间的相关性,表明通过提高标准交叉熵基线的封闭集准确性可以获得最先进的OSR结果。
新类发现:
新类发现(NCD)的问题在DTC [19]中得到了形式化。可以应用于该问题的早期方法包括KCL [21]和MCL [22],它们分别维护用于通用任务转移学习的带标记数据和未标记数据的两个模型。AutoNovel(又名Rankstats)[17, 18]通过三个阶段的方法解决NCD问题。首先,模型通过自监督在所有数据上进行低层表示学习的训练。然后,它进一步通过带标记数据的完全监督训练来捕捉更高层次的语义信息。最后,进行联合学习阶段,利用排序统计信息将知识从标记数据传递到未标记数据。Zhao和Han [51]提出了一个模型,其中包含两个分支,一个用于全局特征学习,另一个用于局部特征学习,以便使用这两个分支进行双重排序统计和相互学习,以实现更好的表示学习和新类别发现。OpenMix [53]混合了标记和未标记数据,以避免模型在NCD中过拟合。NCL [52]使用对比学习提取和聚合未标记数据的成对伪标签,并通过在特征空间中混合标记和未标记数据生成困难负例来进行NCD。贾等人[23]提出了一种用于单模态和多模态数据的端到端NCD方法,该方法使用对比学习和取胜取样哈希。UNO [13]引入了统一的交叉熵损失,允许模型联合训练标记和未标记数据,通过交换标记和未标记分类头中的伪标签来实现。
最后,我们强调Girish等人的工作[15],他们解决了与GCD类似的任务,但是针对的是GAN归属问题,而不是图像识别。此外,Cao等人的同时工作[4]解决了一个类似的图像识别问题,称为开放世界半监督学习。与我们的设置不同,它们没有利用大规模预训练,并且没有在语义漂移基准测试中展示性能,这更好地隔离了检测语义新颖性的问题。
3.广义类发现
我们首先正式定义了广义类别发现(Generalized Category Discovery,GCD)的任务。简而言之,我们考虑的问题是对数据集中的图像进行分类,其中一部分图像具有已知的类别标签。任务是为所有其余的图像分配类别标签,使用的类别可能在已标记的图像中有出现,也可能没有出现(参见图1,左侧)。
正式地,我们如下定义广义类别发现(Generalized Category Discovery,GCD)。我们考虑一个数据集 D,包含两个部分:DL = {(xi, yi)}N
i=1 ∈ X × YL 和 DU = {(xi, yi)}M
i=1 ∈ X × YU,其中 YL ⊂ YU。在训练过程中,模型无法访问 DU 中的标签,并且在测试时需要预测它们。此外,我们假设有一个验证集 DV = {(xi, yi)}N‘
i=1 ∈ X × YL,它与训练集不相交,并且包含与已标记集中的类别相同的图像。这个形式化定义使我们能够清楚地看到与新类别发现设置的区别。新类别发现(Novel Category Discovery,NCD)假设 YL ∩ YU = ∅,并且现有方法在训练过程中依赖于这个先验知识。
在本节中,我们将介绍我们提出的解决GCD问题的方法。首先,我们描述了我们的方法。利用自监督表示学习的最新进展,我们提出了一种简单而有效的方法,基于对比学习,使用半监督k-means算法进行分类。接下来,我们开发了一种估计未标记数据中类别数量的方法,这是一个在文献中研究较少的具有挑战性的任务。最后,我们通过修改最先进的NCD方法RankStats [18]和UNO [13]来适应我们的设置,构建了两个强基线用于GCD。
总的来说,我们的方法利用自监督学习、对比学习和半监督聚类来应对GCD的挑战,并为具有未知或新类别的图像分类提供有效的解决方案。