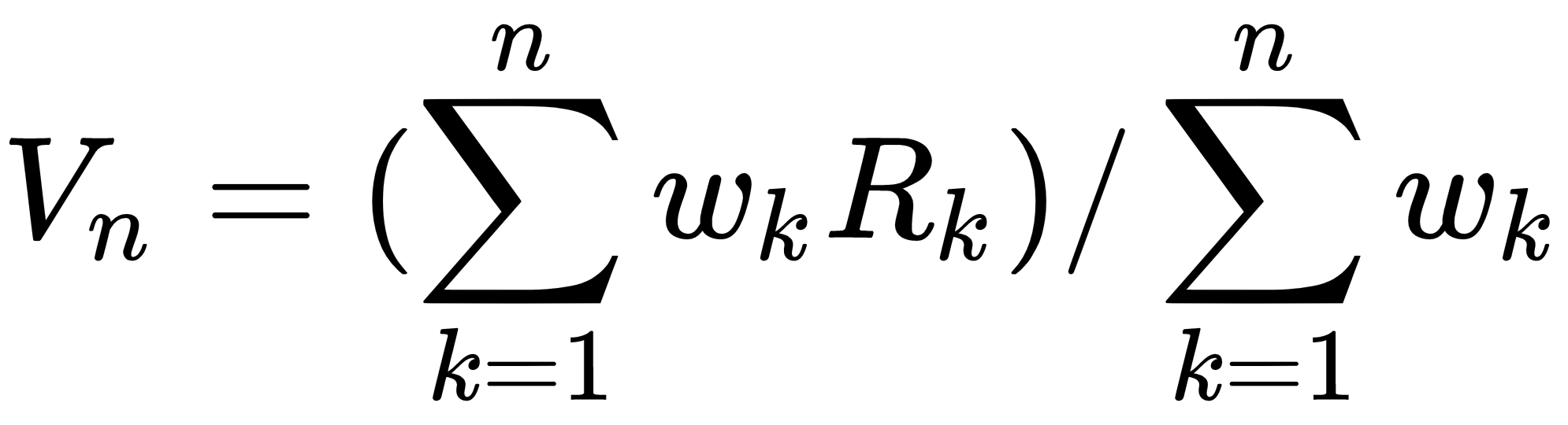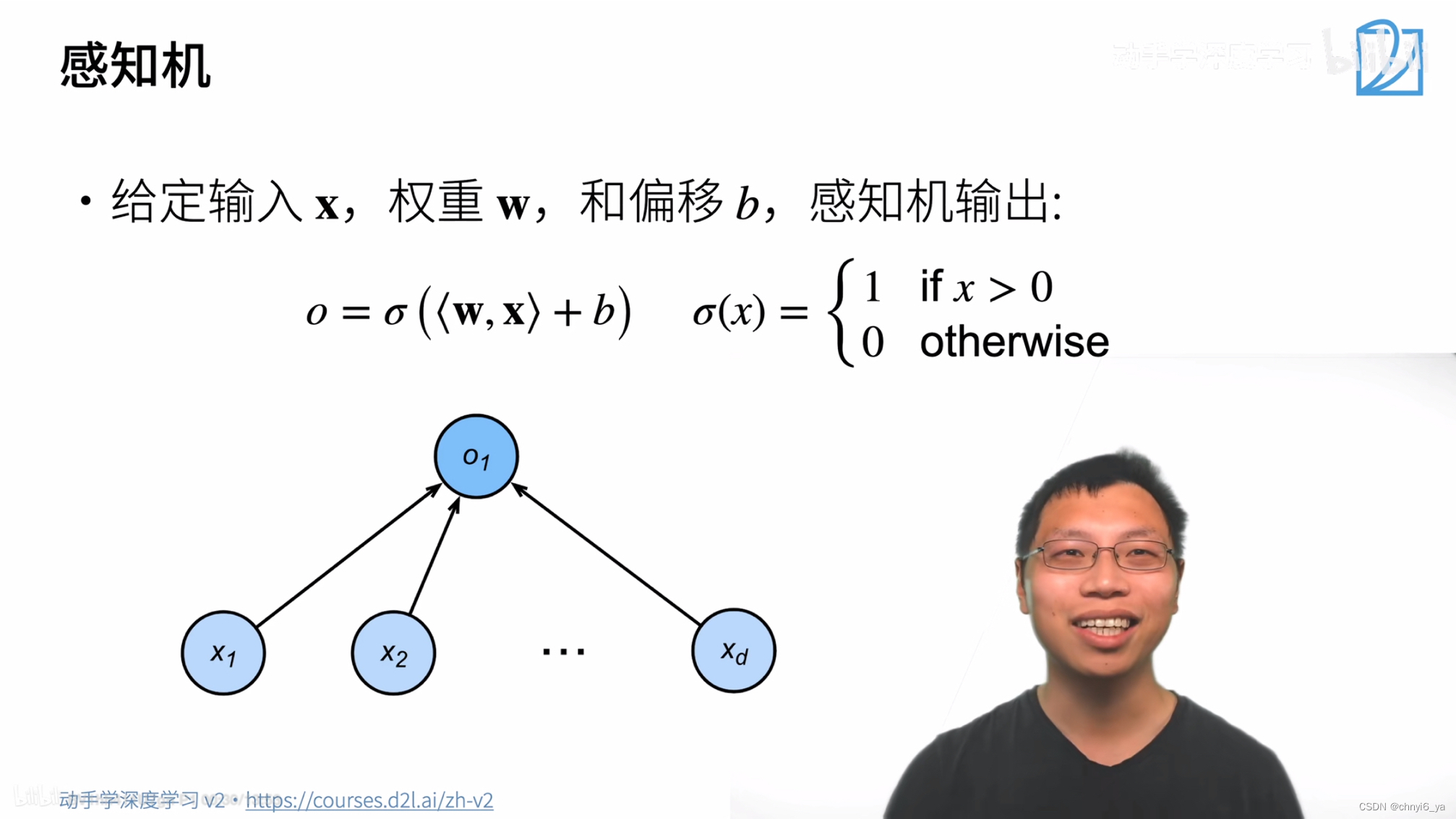
x和w都是向量,b是标量,感知机的输出是:w和x做内积之后+偏移b,最后加上一个函数(这个函数很多种选择)。

1. 训练感知机

如果当前是第i个样本,yi是真实标签值,<w,xi>+b得到的是预测值,如果二者相乘小于等于0,则表明分类错了,于是说明当前权重对分类是错误的,就对w和b都做一次更新。
解释一下,损失函数中,如果分类正确的话-y<w,x>是会小于0的,和0求max就是得到0,则梯度是一个常数,不会去做更新,对应上方的if、语句不成立。如果分类错误的话,第二项就会为正,会有梯度,进入到if语句里面。
损失函数求导,w的导数为yixi,b的导数为yi(损失函数中,把b写进了w和x向量里,b以增广矩阵的形式放到了w矩阵最后一列了)
感知机等价于用损失函数,使用批量大小为1做梯度下降。
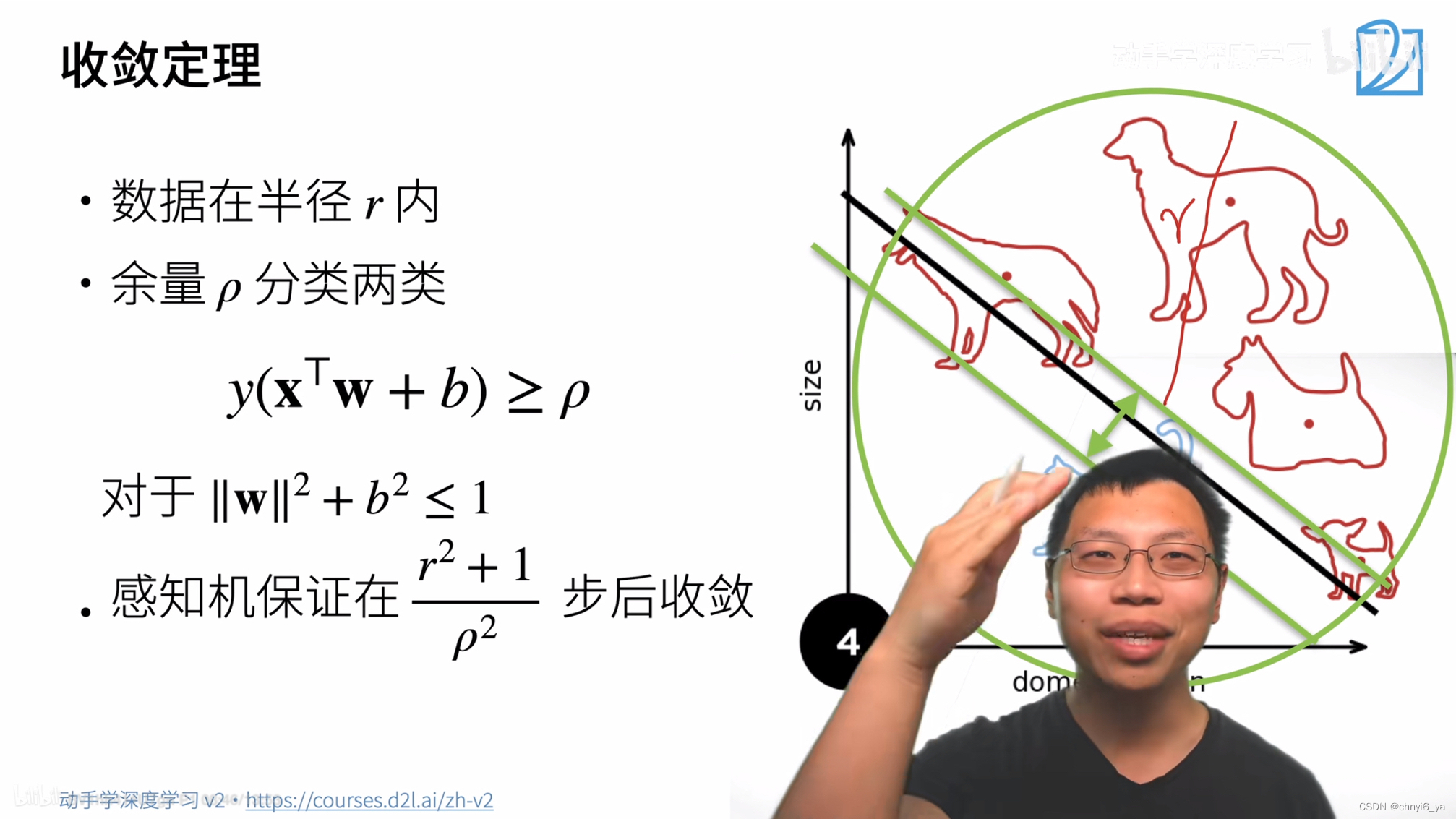
2. 收敛定理
3. XOR问题
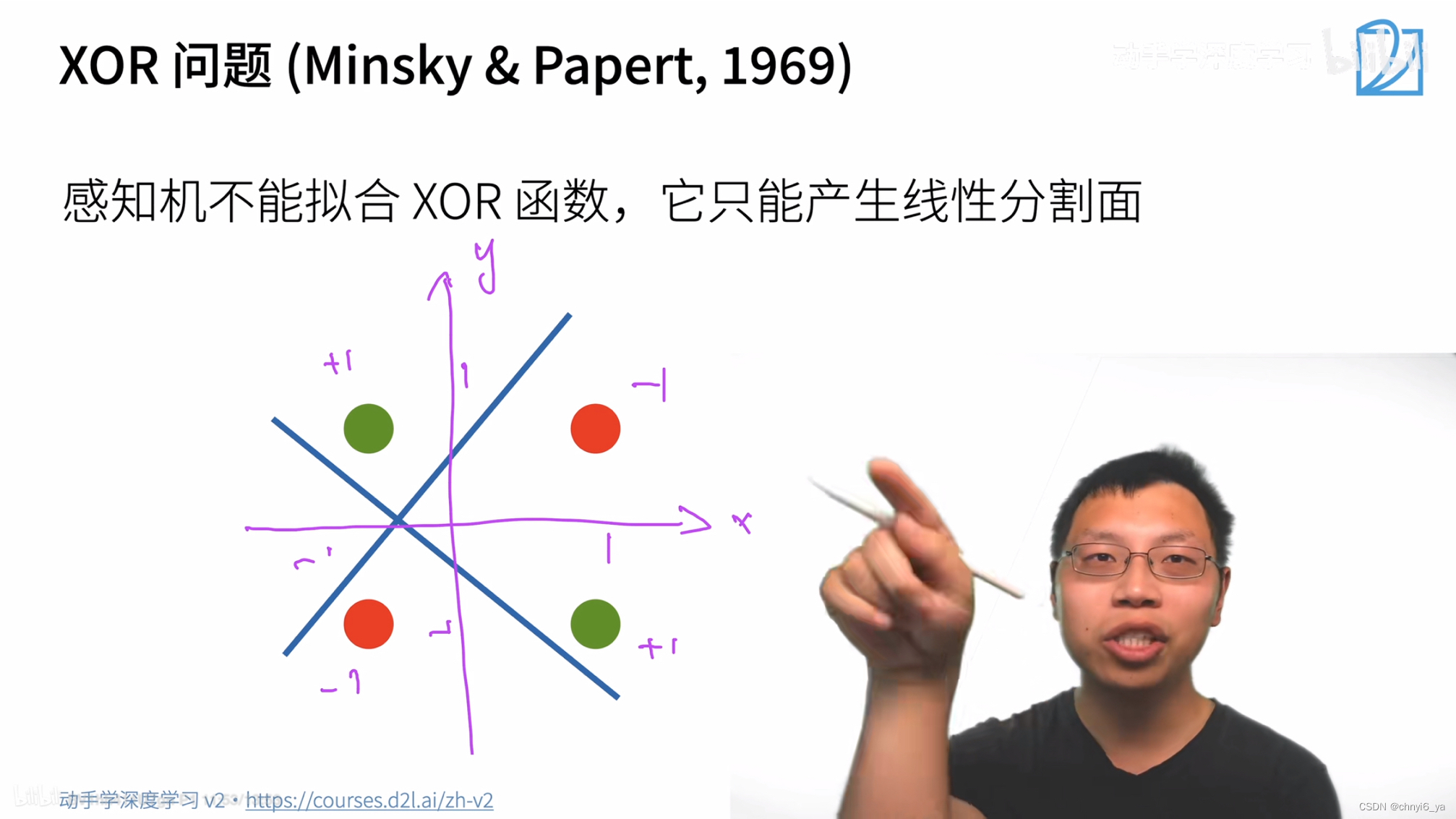
4. 对于感知机的总结
- 感知机是一个二分类模型,是最早的AI模型之一
- 它的求解算法等价于使用批量大小为1的梯度下降
- 它不能拟合XOR函数,导致第一AI寒冬
5. 学习XOR

一次分类不出,就先学一个简单的函数,再学一个简单函数,再用另一个简单函数组合之前学的两个函数。
6. 单隐藏层

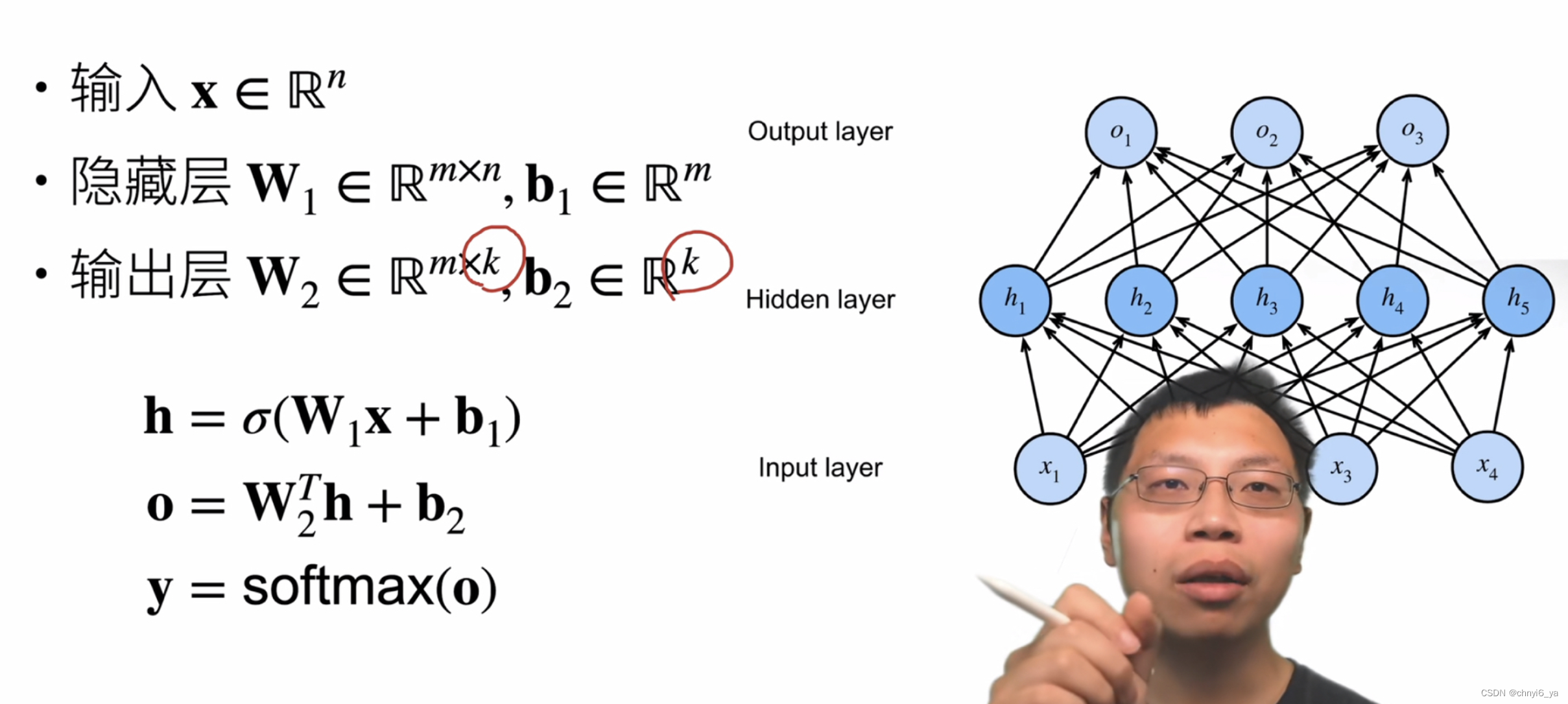
隐藏层的大小是一个超参数,输入的大小是不能改变的,输出的大小看输入数据分为几类,而隐藏层有多大是能设计的。
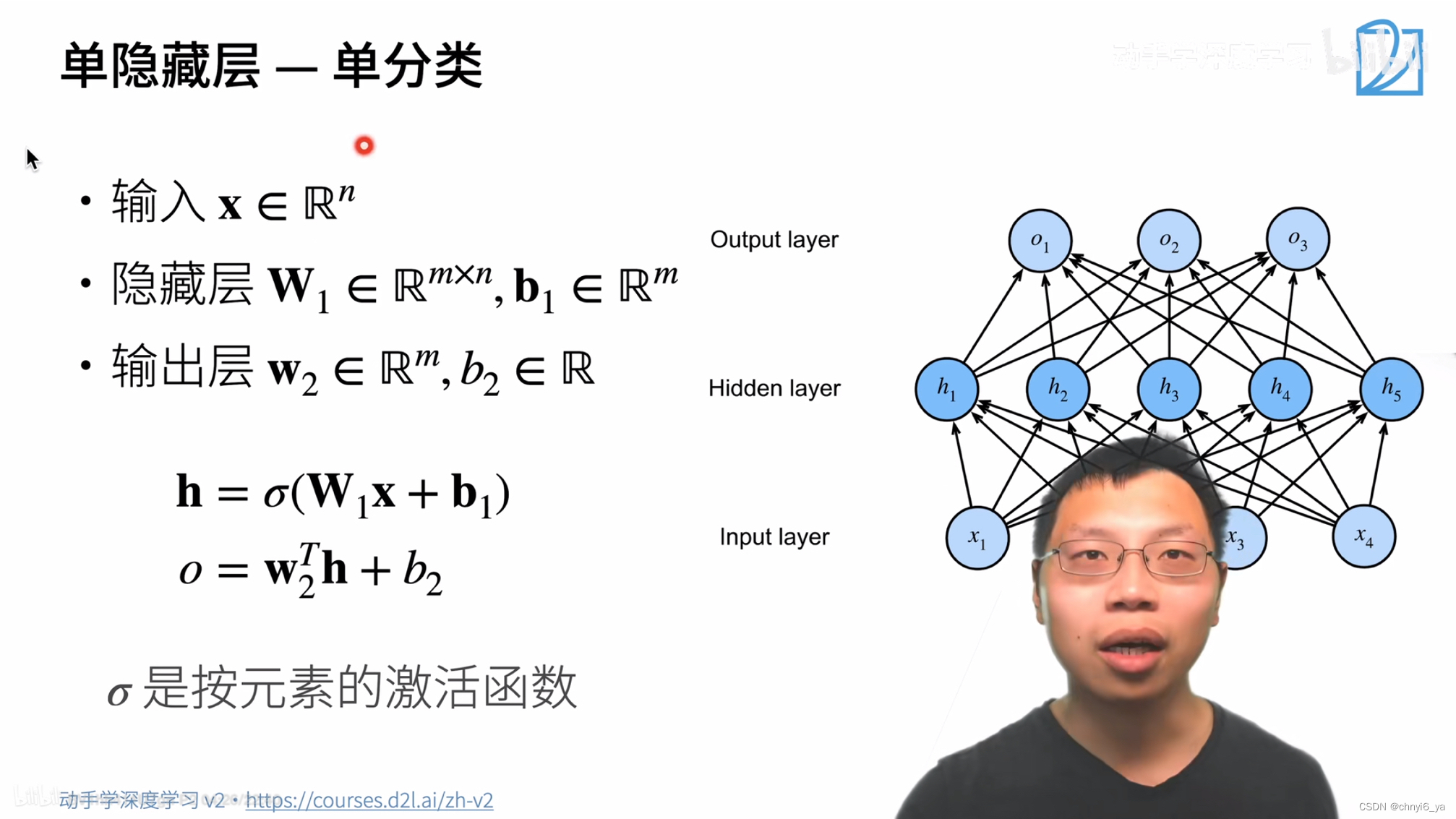
注意,这里是解释单分类,而右边图片明显分类数为3,因此不要对应起来,具体解释如下:

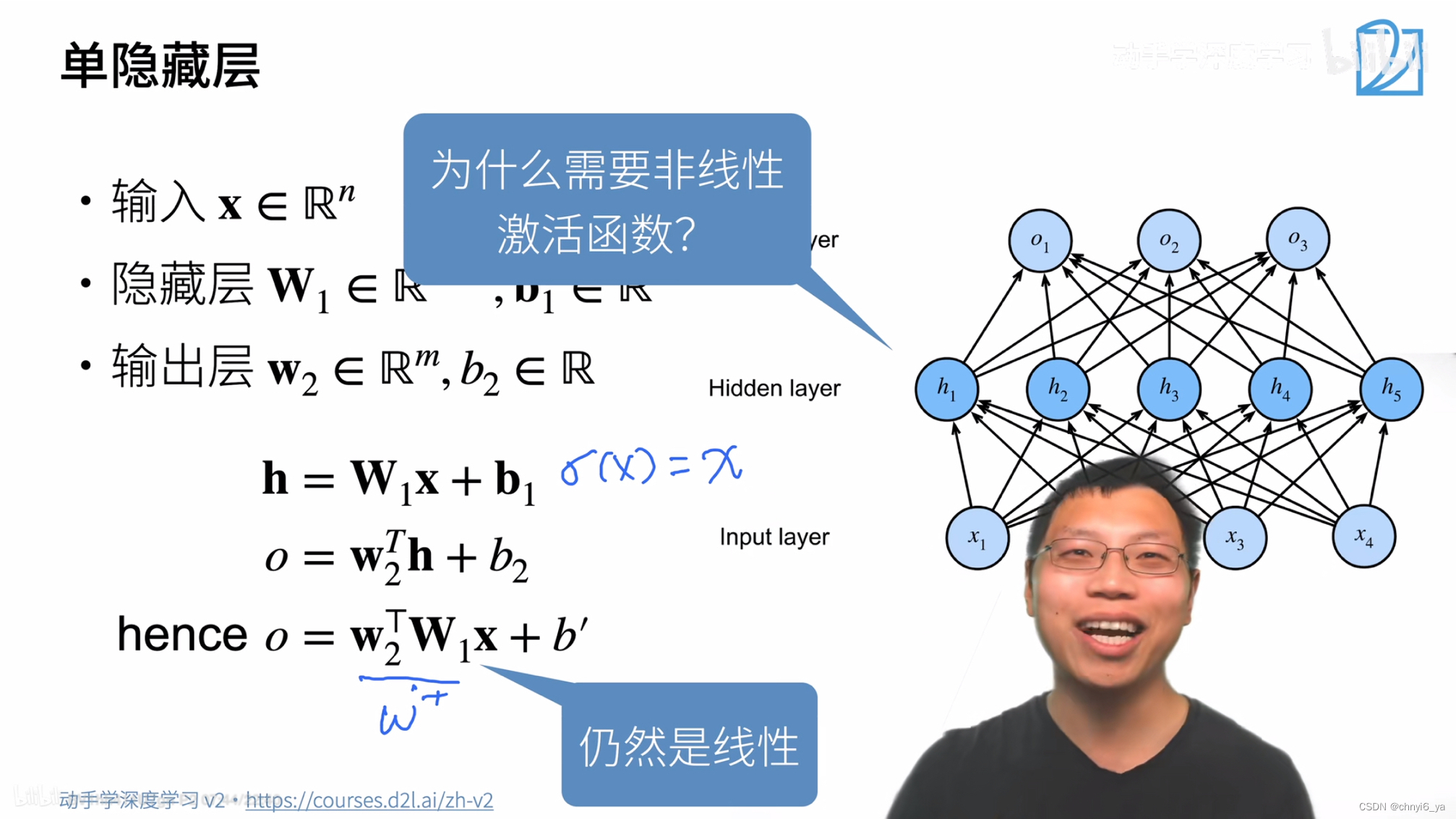
Q:为什么需要非线性的激活函数?
答:假设激活函数为f(x)=x,也输出就是输入的话,则h = W1x+b1,再把h带入到第二个式子:o = W2Th+b2,则o = w2TW1x+b‘ ,并且w2TW1是一个向量,若把它记为W’ ,那么最后的输出是 o = w‘x+b’,仍然是一个线性模型,就无法解决XOR问题,也就等价于单层感知机。
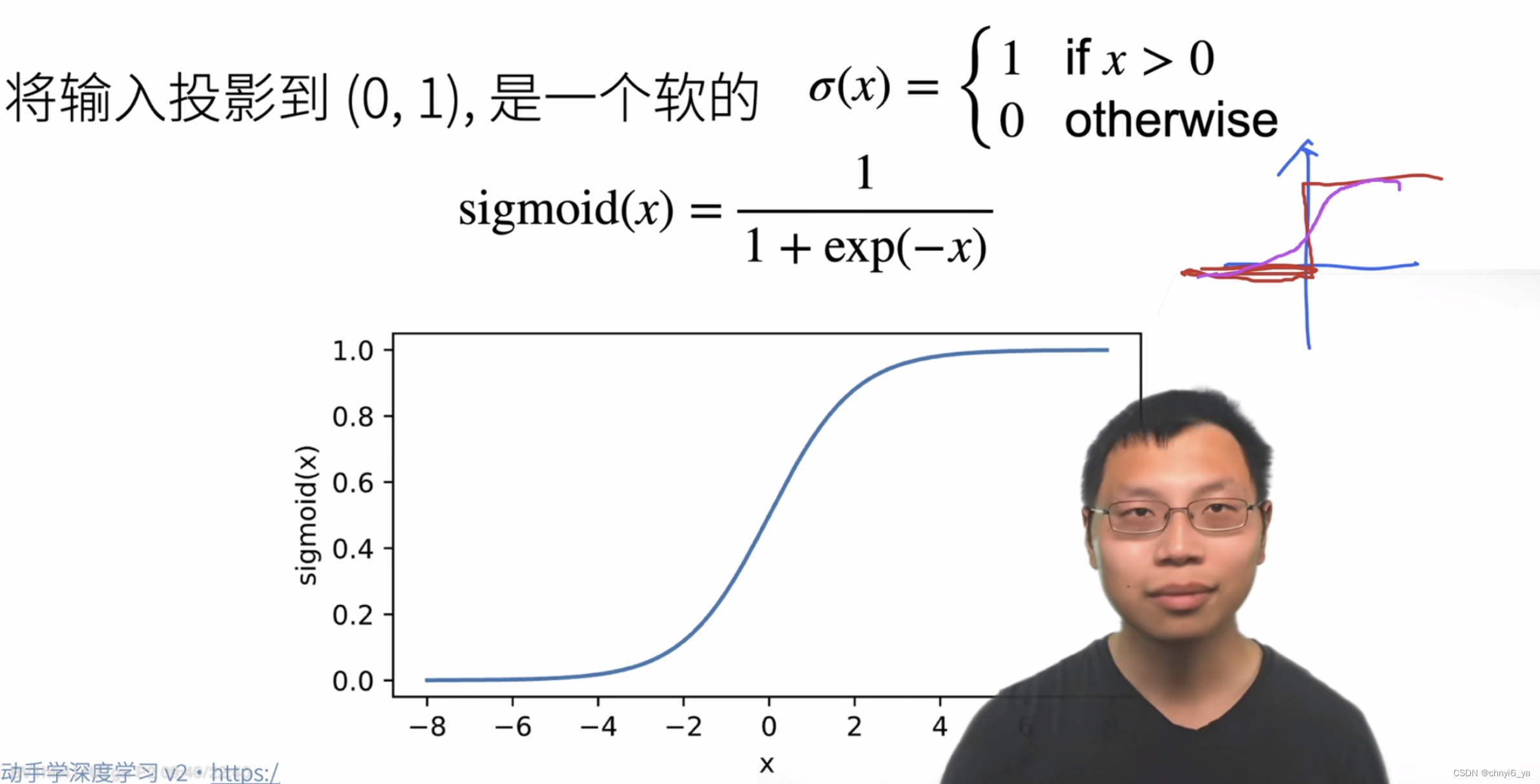
7.几种激活函数
1. sigmoid激活函数
2. Tanh激活函数

蓝色曲线是红色曲线的soft版本,更平滑。
3. ReLU激活函数(常用)
主要的好处:算起来很快,不用像之前的函数做指数运算。

8. 多类分类

多类分类和softmax没有本质区别是因为,相对于softmax回归,唯一不同是加了隐藏层,加上隐藏层就变成了多层感知机,没有加就是softmax回归。
做多类分类的感知机如下:
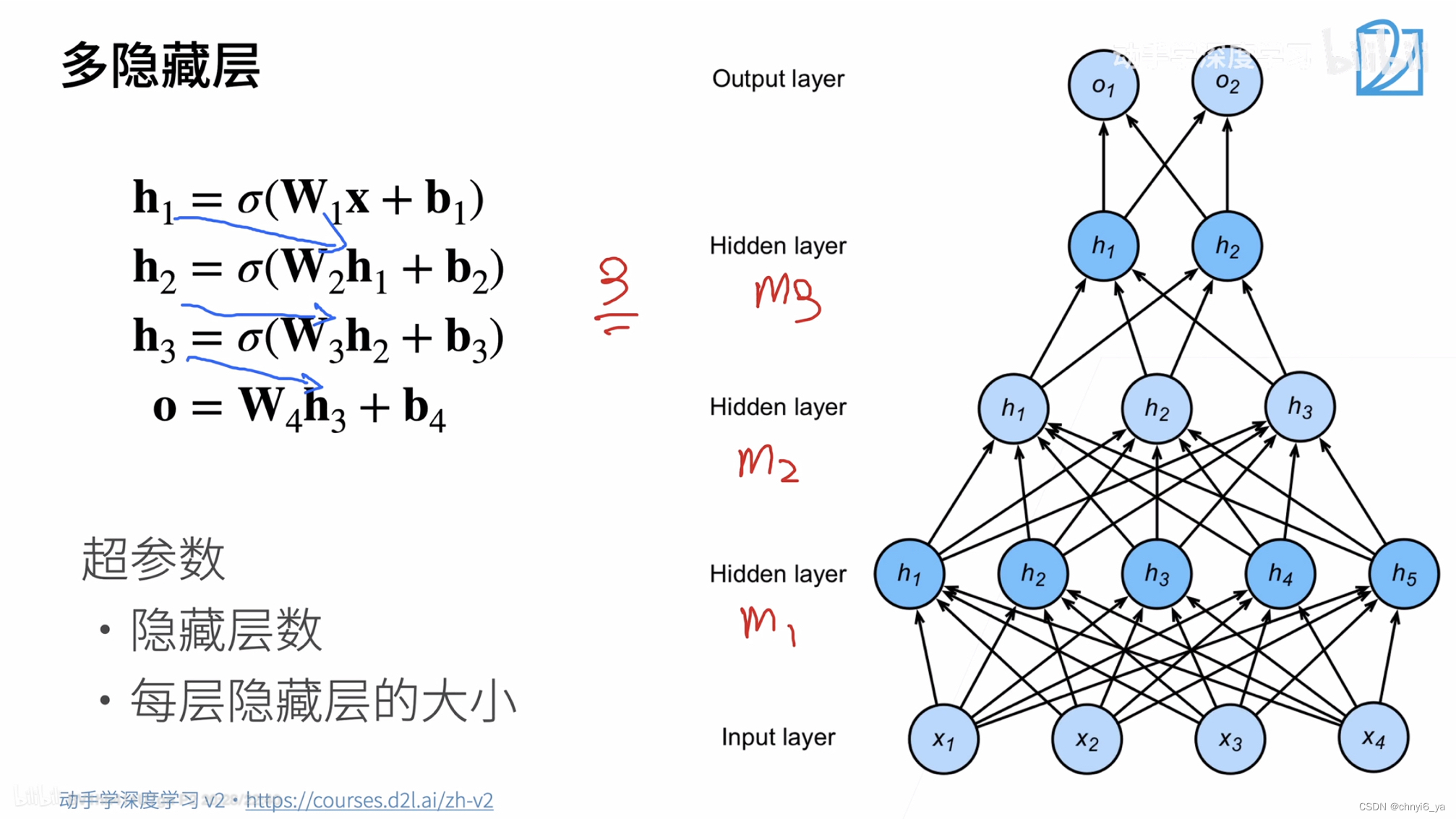
9.多隐藏层:
每一个隐藏层都有自己的W和b。
总结
- 多层感知机使用隐藏层和激活函数来得到非线性模型
- 常用的激活函数是sigmoid,tanh,ReLU
- 使用softmax来处理多类分类
- 超参数为隐藏层数和各个隐藏层大小