目录标题
- 前言
- 环境使用:
- 模块使用:
- 代码展示
- 尾语 💝
前言
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章

环境使用:
-
Python 3.8
-
Pycharm
模块使用:
第三方模块 需要安装的
-
requests >>> pip install requests
-
parsel >>> pip install parsel
-
csv
第三方模块安装:
win + R 输入cmd 输入安装命令 pip install 模块名
(如果你觉得安装速度比较慢, 你可以切换国内镜像源)
完整源码、教程 点击此处跳转文末名片获取 ,我都放在这里了。
代码展示
# 导入数据请求模块
import requests
# 导入数据解析模块
import parsel
# 导入csv
import csv
"""
1. 创建文件对象 f
"""
f = open('data.csv', mode='w', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'品牌',
'信息',
'年份',
'里程',
'城市',
'售价',
'标签',
'详情页',
])
csv_writer.writeheader()
"""
发送请求: 模拟浏览器对于url地址发送请求
- 模拟浏览器
headers 请求头模拟伪装
字典数据类型, 构建完整键值对
如果你要采集其他网站, 替换链接地址/请求头参数/请求方式
多页的数据采集 --> 分析请求链接变化规律
"""
# 模拟浏览器
headers = {
# User-Agent 用户代理, 表示浏览器基本身份信息
源码、解答、资料加V:qian97378免费领
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
for page in range(1, 51):
# 请求链接
url = f'*****/all/?page={page}'
# 发送请求 <Response [200]> 响应对象 状态码200 表示请求成功
response = requests.get(url=url, headers=headers)
"""
获取数据: 获取服务器返回响应数据 <网页源代码>
response.text 获取响应文本数据
解析数据: 提取我们想要的数据内容
解析方法: 选择那种解析方法, 根据返回数据来
re正则表达式 -> 对于字符串数据直接解析
css选择器 -> 根据标签属性提取数据
xpath节点提取 -> 根据标签节点提取数据
css选择器 -> 根据标签属性提取数据
1. 找到数据对应标签位置
"""
# 把获取到网页源代码 response.text, 转成可解析对象
selector = parsel.Selector(response.text) # <Selector xpath=None data='<html lang="en">\n<head>\n <meta cha...'>
# 第一次提取, 获取所有车辆信息所在li标签 获取多个基本返回列表
lis = selector.css('.Content_left .gongge_ul li')
# for循环遍历
for li in lis:
"""
.title::attr(title)
定位class类型为title的标签里面title属性
get 获取第一个标签
getall 获取所有标签
i::text 获取i标签里面文本
"""
# 标题
title = li.css('.title::attr(title)').get()
info = li.css('.gongge_main p i::text').getall()
price = li.css('.gongge_main .price .Total::text').get()
tag = li.css('.qgg_tag::text').get().strip()
href = li.css('.title::attr(href)').get()
"""
split() 字符串分割
replace() 字符串替换
str.join() 列表合并成字符串
strip() 去除字符串左右两端空格
[0] [1] [2] 列表索引位置取值
[2:] 切片
"""
dit = {
'品牌': title.split(' ')[0],
'信息': ' '.join(title.split(' ')[2:]),
'年份': info[0].replace('年', ''),
'里程': info[1].replace('万公里', ''),
'城市': info[2].strip(),
'售价': price,
'标签': tag,
'详情页': href,
}
csv_writer.writerow(dit)
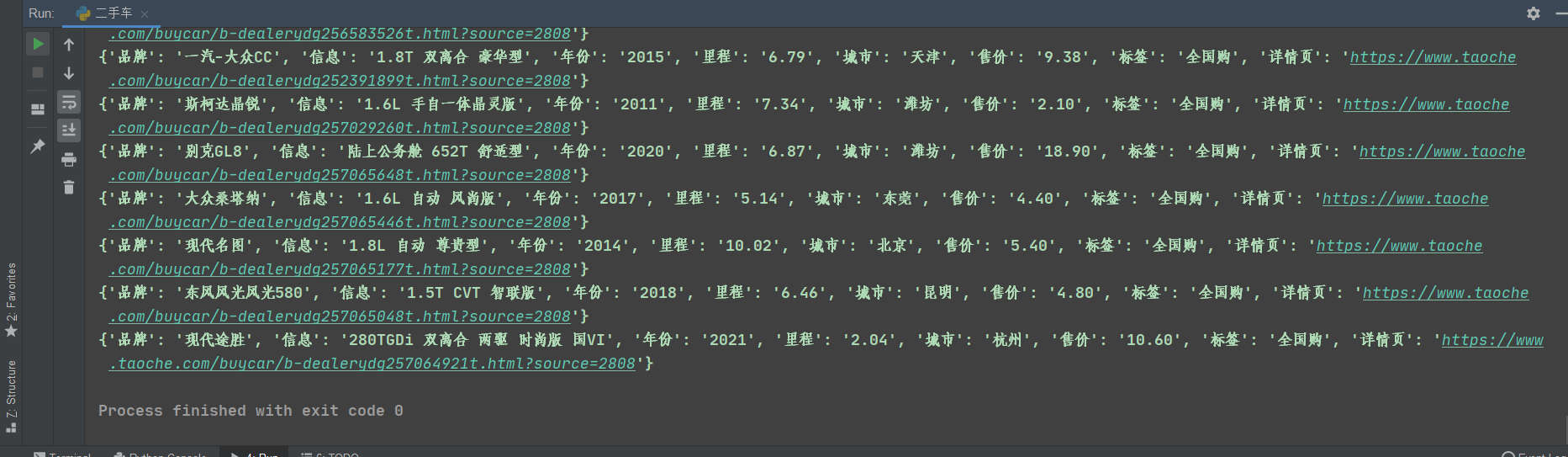
print(dit)
尾语 💝
好了,今天的分享就差不多到这里了!
完整代码、更多资源、疑惑解答直接点击下方名片自取即可。
对下一篇大家想看什么,可在评论区留言哦!看到我会更新哒(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!