前言
最近接到一些改代码或者帮助debug的需求,大多数不是在本地而是autodl这种服务器上,有些人可能不太了解如何设置远程环境。通常在实验室一般都是在本地调好代码然后scp到服务器上去训练,不过这就需要本地有显卡能测试代码是否能跑通,或者直接在autodl这些提供的jupyter上去写代码(代码提示不算友好),一般复杂项目还是更倾向于在Pycharm,VsCode这种编辑器中开发。正好端午节回家,用家里的MacBook和服务器来演示一下整套流程以及介绍一下DDP相关的内容。
1. Pycharm远程设置
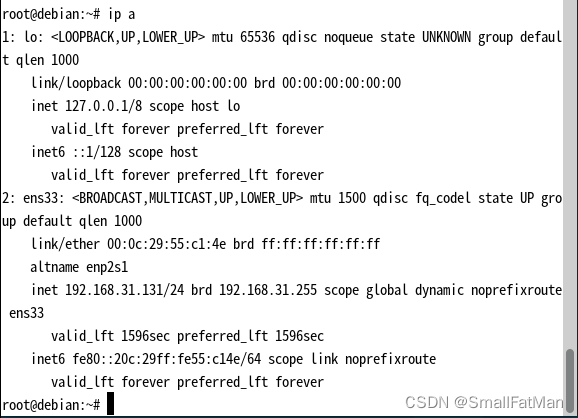
通常服务器会给一个公网ip允许你访问,而我这里因为服务器就放在阳台接的家里内网所以相当于局域网内访问原理是一样的。先连接远程进去看一下服务器ip,ifconfig 得到ip
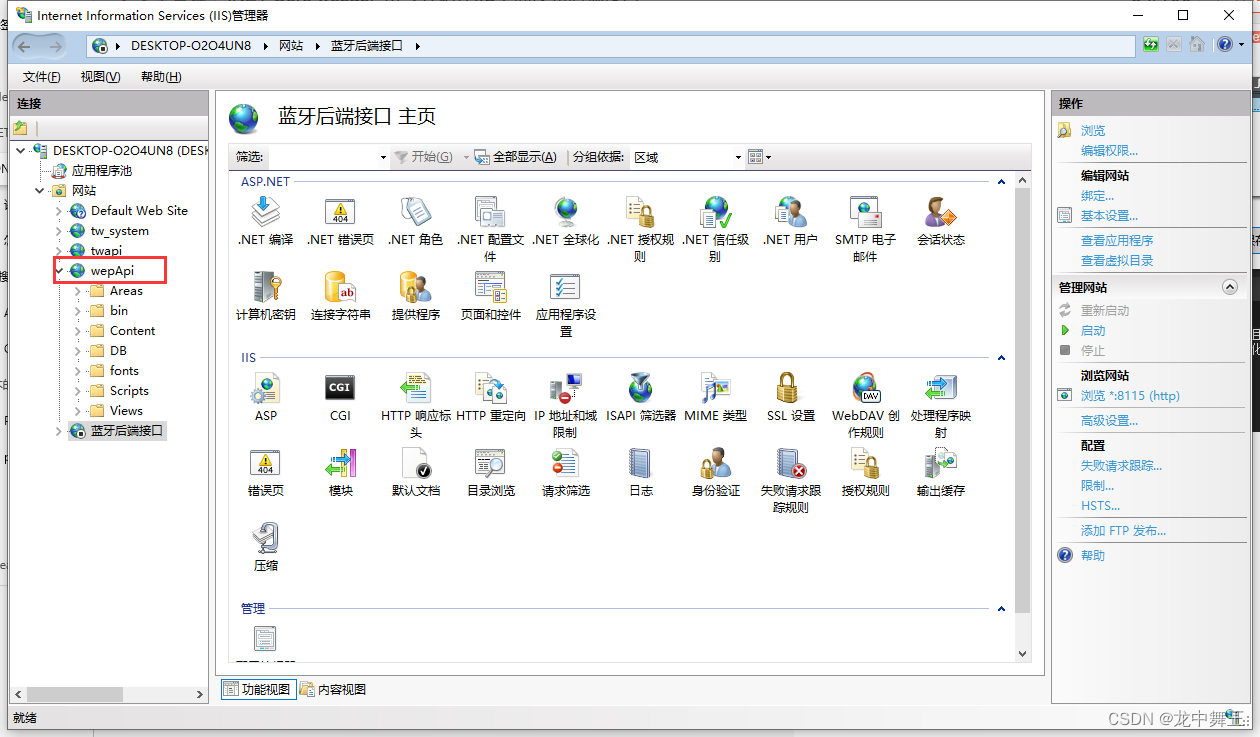
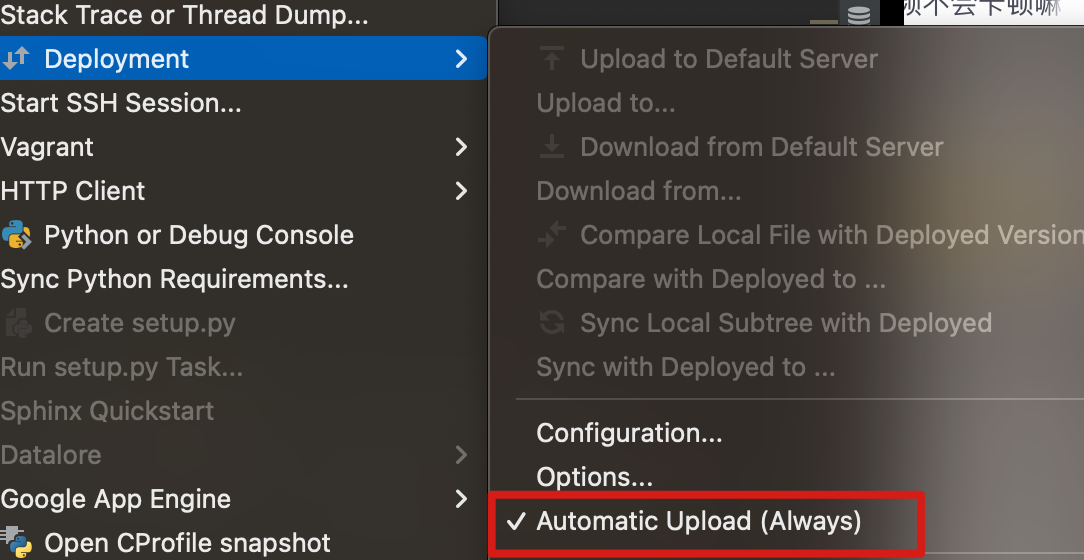
打开Pycharm,点击tools->Deployment->Configuration
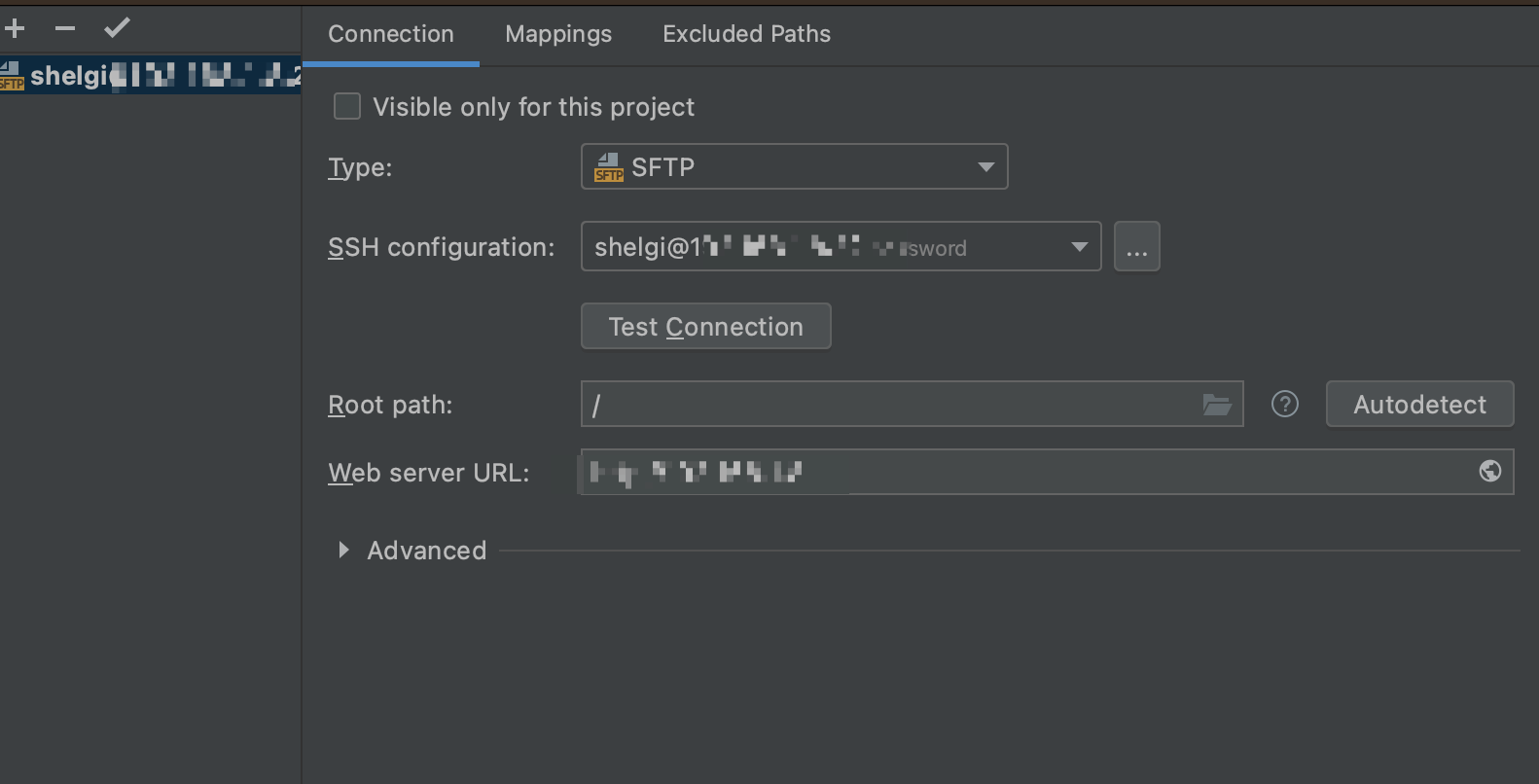
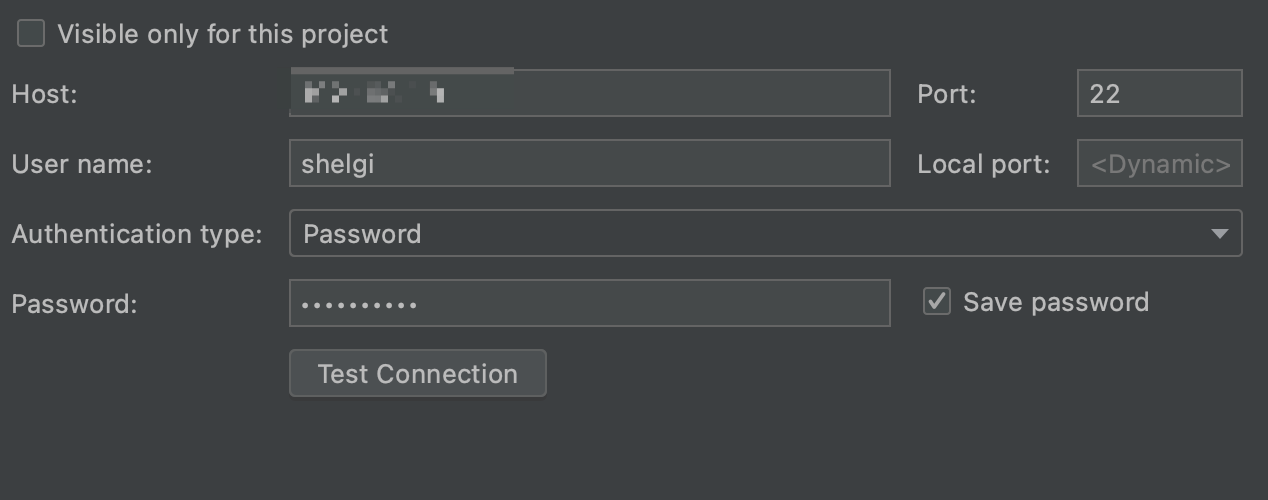
这里就是基本的ssh连接设置,将服务器的ip,用户名和密码设置好,然后点击测试,如果能顺利连接就进行下一步操作。

顺利创建连接之后,设置一下文件路径映射。在Deployment中将自动上传给选上,保证本地的文件修改能顺利在服务器中同步。
2. DDP 相关
通常为了加速训练,我们要尽量使用服务器的所有显卡资源。最常见的环境就是单机多卡(多机多卡后期抽空把实验室的服务器全整上来单独出一期),所以今天主要还是将单机多卡场景。
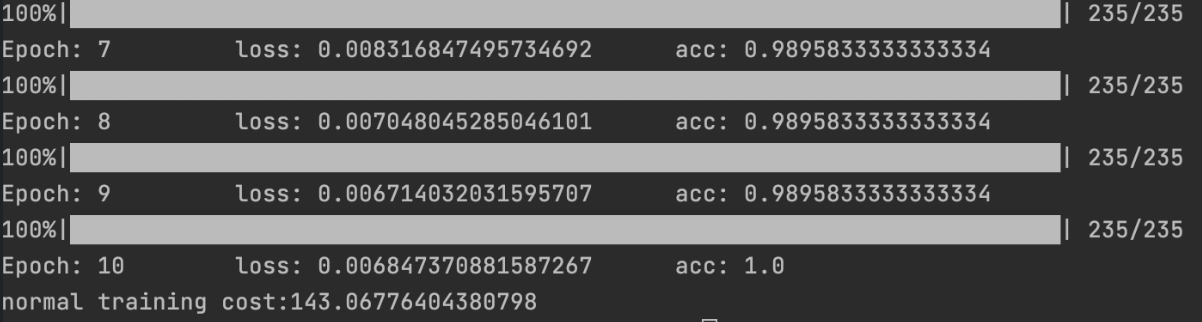
在单机多卡之前,还是上一版最简单的单卡的demo作为比较
def get_dataloader():
transform = transforms.Compose([
transforms.ToTensor(),
])
dataset = torchvision.datasets.MNIST("./", train=True, transform=transform, download=True)
dataloader = DataLoader(dataset, batch_size=256, shuffle=True, num_workers=12, pin_memory=True)
return dataloader
def train(epochs=10, ckpt_save_path='./best.pt'):
model = Model(10).cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
dataloader = get_dataloader()
best_acc = -torch.inf
start = time.time()
for epoch in range(epochs):
labels_list = []
prediction_list = []
loss_list = []
model.train()
for _, (images, labels) in tqdm(enumerate(dataloader), total=len(dataloader), leave=True):
images, labels = images.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss_list.append(loss)
outputs = torch.max(outputs, dim=1)[1]
prediction_list.extend(outputs)
labels_list.extend(labels)
loss.backward()
optimizer.step()
acc = accuracy_score(labels.cpu().detach().numpy(), outputs.cpu().detach().numpy())
print(f'Epoch: {epoch + 1} \t loss: {sum(loss_list) / len(loss_list)} \t acc: {acc}')
if acc > best_acc:
best_acc = acc
print(f"best acc:{best_acc} model save!")
torch.save(model.state_dict(), ckpt_save_path)
return time.time() - start
然后再来看看单机多卡版本
def setup():
dist.init_process_group('nccl')
rank = dist.get_rank()
torch.cuda.set_device(rank)
device_id = rank % torch.cuda.device_count()
return device_id
def cleanup():
dist.destroy_process_group()
def get_distributed_dataloader():
transform = transforms.Compose([
transforms.ToTensor(),
])
dataset = torchvision.datasets.MNIST("./", train=True, transform=transform, download=True)
data_sampler = DistributedSampler(dataset)
dataloader = DataLoader(dataset, batch_size=256, num_workers=12, sampler=data_sampler, pin_memory=True)
return dataloader
def train_ddp(epochs=10, ckpt_save_path='./best_ddp.pt'):
setup()
model = Model(num_classes=10).cuda()
model = DDP(model)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
dataloader = get_distributed_dataloader()
best_acc = -torch.inf
start = time.time()
for epoch in range(epochs):
labels_list = []
prediction_list = []
loss_list = []
model.train()
for _, (images, labels) in tqdm(enumerate(dataloader), total=len(dataloader), leave=True):
images, labels = images.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss_list.append(loss)
outputs = torch.max(outputs, dim=1)[1]
prediction_list.extend(outputs)
labels_list.extend(labels)
loss.backward()
optimizer.step()
acc = accuracy_score(labels.cpu().detach().numpy(), outputs.cpu().detach().numpy())
if dist.get_rank() == 0:
print(f'Epoch: {epoch + 1} \t loss: {sum(loss_list) / len(loss_list)} \t acc: {acc}')
if acc > best_acc:
best_acc = acc
print(f"best acc:{best_acc} model save!")
torch.save(model.state_dict(), ckpt_save_path)
return time.time() - start
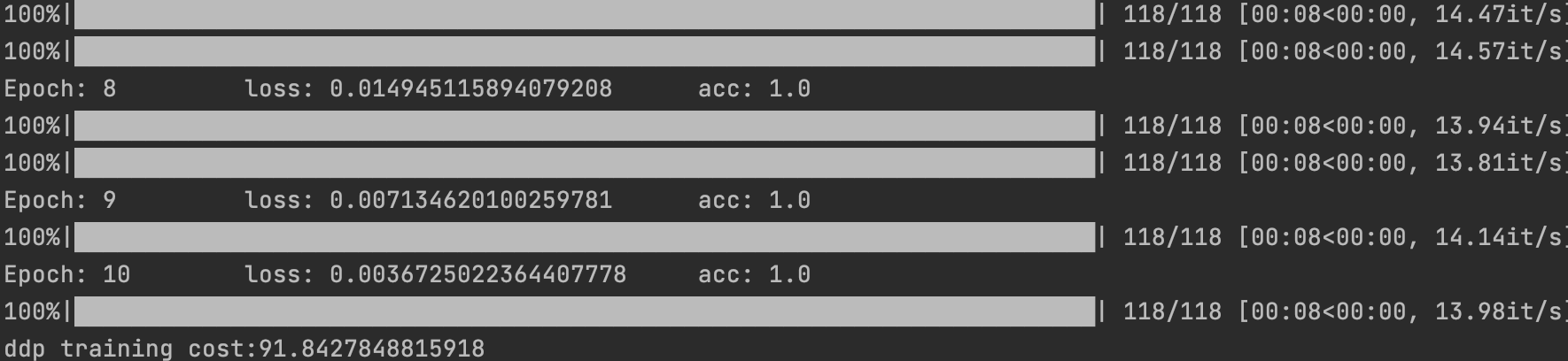
得益于pytorch封装,相比起来单机多卡仅仅多了几行代码。比如数据的分布式采样以及模型的分布式,简单说就是每张显卡都有模型或者副本以及数据,然后反向传播的时候这些模型的梯度会同步下降,保证不同显卡上的模型权重相同。不过也可以看出为了DDP我们还是做了一些看起来没有太大必要的事情,比如保证dist.init_process_group来实现不同显卡之间的通信,而且手动去设置模型以及数据的分布式貌似也不是那么省事(对于我这个懒人),更不合理的地方在于如果我为了单机多卡训练写好的代码,换到单卡环境还得重新改写代码,反之亦然。
是否有更好的封装能够完美兼容pytorch的训练呢?真的有,那就是Accelerate
通过Accelerate,我们可以写一套单机单卡的代码仅仅修改几句,然后在任何环境下都可以运行。还记得一开始的那个单机单卡demo吗?现在我们用Accelerate来完善一下。
from accelerate import Accelerator
def get_dataloader():
transform = transforms.Compose([
transforms.ToTensor(),
])
dataset = torchvision.datasets.MNIST("./", train=True, transform=transform, download=True)
dataloader = DataLoader(dataset, batch_size=256, shuffle=True, num_workers=12, pin_memory=True)
return dataloader
def train(epochs=10, ckpt_save_path='./best.pt'):
model = Model(10).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
dataloader = get_dataloader()
model, optimizer, dataloader = accelerator.prepare(model, optimizer, dataloader)
best_acc = -torch.inf
start = time.time()
for epoch in range(epochs):
labels_list = []
prediction_list = []
loss_list = []
model.train()
for _, (images, labels) in tqdm(enumerate(dataloader), total=len(dataloader), leave=True):
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
accelerator.backward(loss)
optimizer.step()
loss_list.append(loss)
outputs = torch.max(outputs, dim=1)[1]
prediction_list.extend(outputs)
labels_list.extend(labels)
acc = accuracy_score(labels.cpu().detach().numpy(), outputs.cpu().detach().numpy())
print(f'Epoch: {epoch + 1} \t loss: {sum(loss_list) / len(loss_list)} \t acc: {acc}')
if acc > best_acc:
best_acc = acc
print(f"best acc:{best_acc} model save!")
torch.save(model.state_dict(), ckpt_save_path)
return time.time() - start
def main():
print(f"Accelerate training cost:{train(epochs=10)}")
if __name__ == '__main__':
accelerator = Accelerator()
device=accelerator.device
main()
几乎一模一样,只需要一个accelerator.prepare和accelerator.backward就可以实现一次代码多处使用,这不就是大家都喜欢的“跨平台”特性吗?再来看看训练速度,只需要一行代码运行accelerate launch --multi_gpu --num_processes=2 train2.py
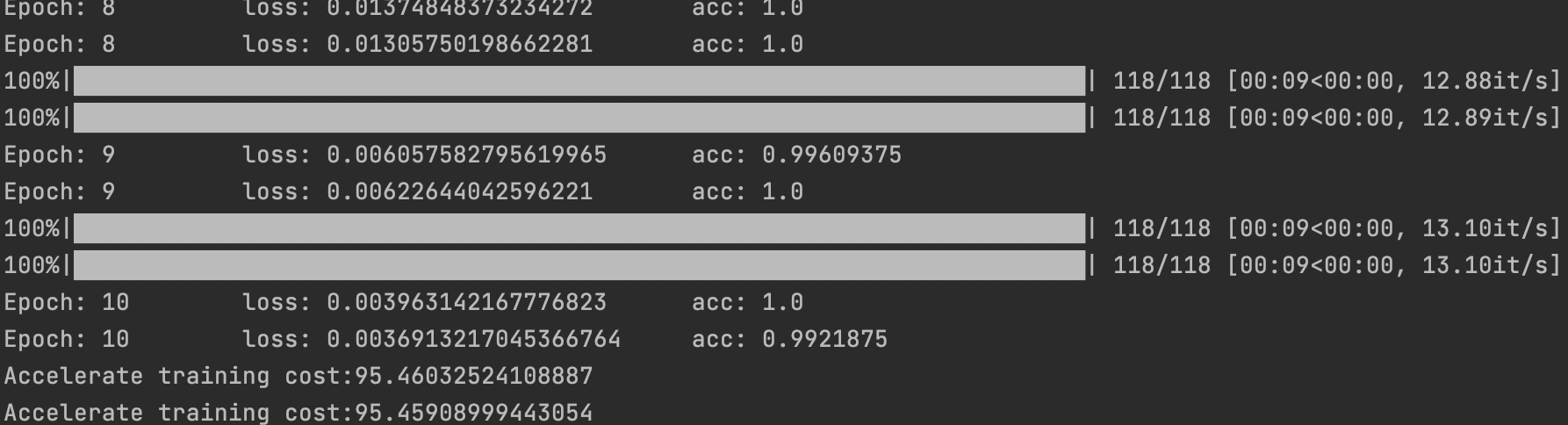
看起来和pytorch的ddp训练时间差不多,时间测试不算准确毕竟没有取多次平均,但是如此方便的特性谁又会在乎慢几秒呢。况且在训练过程中可以直接设置fp16,只需要加上--mixed_precision=fp16,而不用自己写amp和scaler那几行,更加适合把精力放在模型优化而不是训练上。
总结
其实不光Pycharm,VsCode安装remote插件同样可以实现远程操作,这里主要是考虑文件同步问题,一定要记得上传!!! 分布式训练有的时候一些Bug确实非常恼人,但是Accelerate算是给出了一种很好的解决方案。想到这就想发散一点,封装其实也是制定了一些硬性规则,如果这些规则足够易用用户还是能接受的。反观国内一些库,一个库依赖另一个库版本还要匹配,想要去修改一点点东西牵一发而动全身属实够恶心的,用起来更多的感受是心累。