构建数据集常用的步骤如下所示:
- 收集原始数据。
- 识别特征和标签来源。
- 选择抽样策略。
- 拆分数据。
这些步骤在很大程度上取决于你如何构建 ML 问题。本文主要介绍——数据收集-Collecting Data。
目录
1. 数据集的大小和质量
1.1 数据集的大小
1.2 数据集的质量
1.3 特征表示-Feature Representation
1.4 训练与预测
2.连接数据日志
2.1 日志类型
2.2 加入日志源
2.3 预测数据源 - 在线与离线
3.识别标签和来源
3.1直接 vs 派生标签
3.2 标签来源
3.2.1 事件的直接标签
3.2.2 属性的直接标签
3.3 注意事项
3.3.1 直接标签需要过去行为的日志
3.3.2. 如果没有要记录的数据怎么办?
3.3.3 为什么要使用人工标记数据?
3.3.4 提高质量
4.参考文献
1. 数据集的大小和质量
“垃圾进垃圾出”
这句话非常适用于机器学习。毕竟,模型的好坏取决于数据。但是如何衡量数据集的质量并改进它呢?我们需要多少数据才能获得有用的结果?答案取决于我们要解决的问题的类型。
1.1 数据集的大小
根据粗略的经验法则,模型应该在比可训练参数多至少一个数量级的示例上进行训练。大数据集上的简单模型通常会击败小数据集上的奇特模型。谷歌在大数据集上训练简单线性回归模型取得了巨大成功。那么,什么算作“大量”数据?这取决于项目。考虑这些数据集的相对大小——如下表所示的项目:数据集有多种大小。
| 数据集 | 大小(示例数量) |
|---|---|
| 鸢尾花数据集 | 150 |
| MovieLens(20M数据集) | 20,000,263 |
| 谷歌 Gmail 智能回复 | 238,000,000 |
| 谷歌图书 Ngram | 468,000,000,000 |
| 谷歌翻译 | 数万亿 |
1.2 数据集的质量
如果数据不好,那么再多的数据也是没有用的;质量也很重要。但什么才算“质量”呢?这是一个模糊的术语。考虑采用实证方法并选择产生最佳结果的选项。有了这种心态,高质量的数据集就可以让我们成功解决所关心的业务问题。换句话说,如果数据完成了预期的任务,那么它就是好的。
然而,在收集数据时,对质量有一个更具体的定义是有帮助的。质量的某些方面往往对应于性能更好的模型:
- 可靠性
- 特征表示
- 最小化偏差
1.2.1 可靠性
可靠性是指我们可以信任数据的程度。在可靠数据集上训练的模型比在不可靠数据上训练的模型更有可能产生有用的预测。在测量可靠性时,必须确定:
- 标签错误有多常见?例如,如果数据是由人类标记的,有时人类会犯错误。
- 特征有噪音吗?例如,GPS 测量值会波动。有些噪音是可以的。你永远无法清除数据集中的所有噪音。
- 数据是否针对问题进行了正确过滤?例如,数据集是否应该包含来自机器人的搜索查询?如果我们正在构建垃圾邮件检测系统,那么答案可能是肯定的,但如果你正在尝试改善人类的搜索结果,那么答案可能是否定的。
是什么导致数据不可靠?回顾一下 《机器学习工程落地注意事项-II(公平-Fairness)》 一文的内容:可知,以下一个或多个原因是不可靠的来源:
- 省略的值。例如,某人忘记输入房屋的年龄值。
- 重复的例子。例如,服务器错误地将相同的日志上传了两次。
- 不好的标签。例如,有人将橡树的图片错误地标记为枫树。
- 不良特征值。例如,有人输入了额外的数字,或者温度计被留在阳光下。
谷歌翻译注重可靠性,以选择其数据的“最佳子集”;也就是说,某些数据具有比其他部分更高的质量标签。
1.3 特征表示-Feature Representation
回想一下《机器学习7:特征工程》一文,表示(Representation)——是指将数据映射到有用的特征。需要考虑以下问题:
- 数据如何向模型显示?
- 需要 标准化 数值吗?
- 如何处理 异常值?
本文的“转换数据” 部分将重点关注特征表示。
1.4 训练与预测
如果离线获得了很好的结果,但在线实验中,这些结果却变差了。可能的原因是什么?
问题表明存在训练/服务偏差,即在训练时与服务时为指标计算出不同的结果。偏差的原因可能很微妙,但会对结果产生致命的影响。在实践中,我们必须谨慎选择模型使用的数据,在训练期间,仅使用在服务中可用的特征,并确保训练集能够代表真实服务流量。
黄金法则:像预测一样对待训练。也就是说,训练任务与预测任务越匹配,机器学习系统的性能就越好。
2.连接数据日志
组装训练集时,有时必须连接多个数据源。
2.1 日志类型
可以使用以下任何类型的输入数据:
- 事务日志
- 属性数据
- 汇总统计
事务日志——记录特定事件。例如,事务日志可能会记录进行查询的 IP 地址以及进行查询的日期和时间。事务事件对应于特定事件。
属性数据——包含信息快照。例如:用户人口统计、查询时的搜索历史记录。
属性数据并不特定于某个事件或某个时刻,但仍然可用于进行预测。对于与特定事件无关的预测任务(例如,预测用户流失,涉及一系列时间而不是单个时刻),属性数据可能是唯一的数据类型。
属性数据和事务日志是相关的。例如,可以通过聚合多个事务日志、创建聚合统计信息来创建一种属性数据。在这种情况下,可以查看许多事务日志来为用户创建单个属性。
汇总统计数据——从多个事务日志创建属性。例如:用户查询频率、特定广告的平均点击率。
2.2 加入日志源
每种类型的日志往往位于不同的位置。为机器学习模型收集数据时,我们必须将不同的源连接在一起以创建数据集。一些例子:
- 利用事务日志中的用户 ID 和时间戳来查找事件发生时的用户属性。
- 使用事务时间戳来选择查询时的搜索历史记录。
查找属性数据时使用事件时间戳至关重要。如果获取到最新的用户属性,训练数据将包含数据收集时的值,这会导致训练/服务偏差。如果你忘记对搜索历史记录执行此操作,则可能会将真实结果泄漏到训练数据中!
2.3 预测数据源 - 在线与离线
在 《机器学习21:机器学习工程落地注意事项-I》中 ,笔者介绍了在线服务与离线服务。两种不同的服务形式下,系统收集数据的方式也不一样,如下所示:
- 在线——延迟是一个问题,因此系统必须快速生成输入。
- 离线——可能没有计算限制,因此可以执行与训练数据生成类似的复杂操作。
例如,属性数据经常需要从其他系统查找,这可能会带来延迟问题。同样,动态计算聚合统计数据的成本可能很高。如果延迟是一个阻碍因素,一种可能性是预先计算这些统计数据。
3.识别标签和来源
3.1直接 vs 派生标签
当标签定义明确时,机器学习会更容易。最好的标签是你想要预测的内容的直接标签。例如,如果你想预测用户是否是周杰伦的粉丝,则直接标签就是“用户是周杰伦的粉丝”。
一个更简单的粉丝度测试——用户是否在 QQ 音乐上听过周杰伦的歌曲。标签“用户在 QQ 音乐上收听了周杰伦的歌曲”是一个派生标签,因为它不直接衡量要预测的内容。这个派生标签是用户喜欢周杰伦的可靠指标吗?应该是,但无论如何,需要明确的是——模型只能与派生标签和所需预测之间的连接一样好,换言之,派生标签与预测之间的关联越紧密,预测效果就越好。
3.2 标签来源
模型的输出可以是事件或属性。这会产生以下两种类型的标签:
- 事件的直接标签,例如“用户是否单击了顶部搜索结果?”
- 属性的直接标签,例如“广告商下周的支出是否会超过 X 美元?”
3.2.1 事件的直接标签
对于事件,直接标签通常很简单,因为你可以记录事件期间的用户行为以用作标签。当标记事件时,问自己以下问题:
- 日志是如何构造的?
- 日志中什么被视为“事件”?
例如,系统是否记录用户点击搜索结果或用户何时进行搜索?如果你有点击日志,请注意,如果没有点击,你将永远不会看到展示(本质是确认日志的有效性)。你需要其中事件为展示次数的日志,以便涵盖用户看到热门搜索结果的所有情况。
3.2.2 属性的直接标签
假设标签是:“广告客户下周将花费超过 X 美元。” 通常,我们会使用前几天的数据来预测接下来几天会发生什么。例如,下图显示:使用 10 天训练数据训练模型,而后对随后 7 天进行预测。
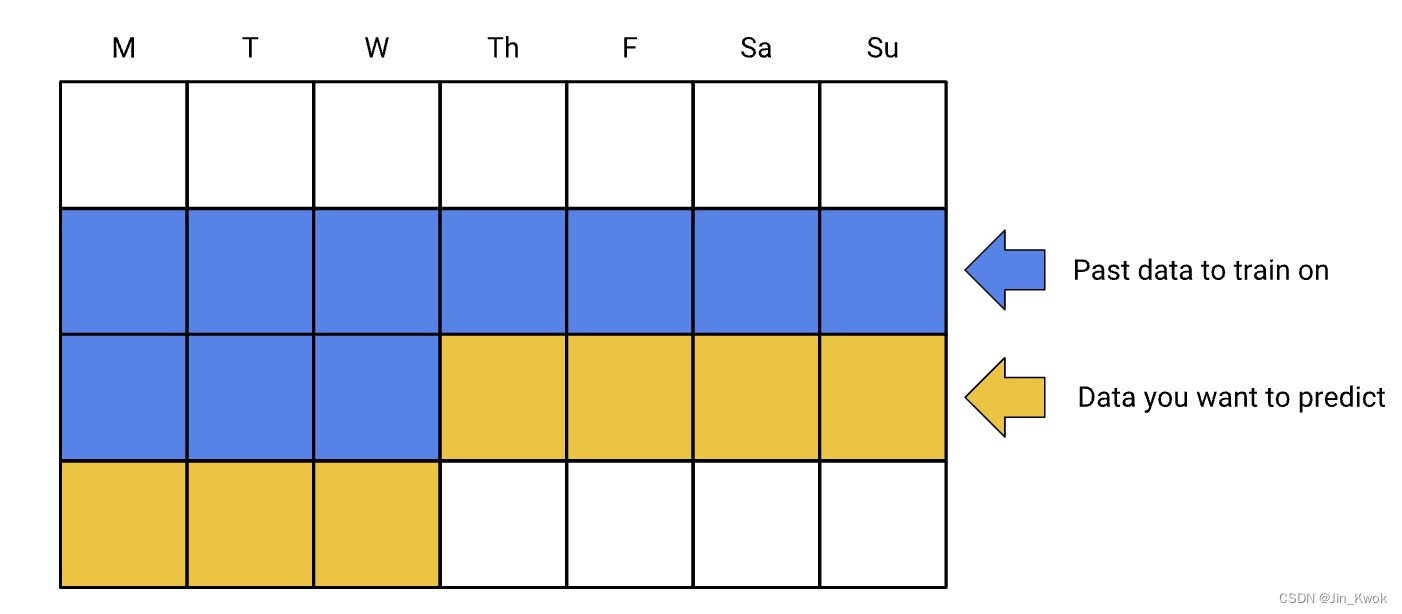
在实践中,需要考虑季节性或周期性影响;例如,广告商可能会在周末花费更多,因此可能更愿意使用 14 天的窗口;或者使用日期作为特征以便模型可以学习每年的影响。
3.3 注意事项
3.3.1 直接标签需要过去行为的日志
在前面的情况下,请注意我们需要有关真实结果的数据。无论是广告商花费了多少,还是哪些用户收听了周杰伦的音乐,我们都需要历史数据来使用监督机器学习。机器学习根据过去发生的事情进行预测,因此,如果没有过去的日志,则需要获取它们。
3.3.2. 如果没有要记录的数据怎么办?
也许你的产品尚不存在,因此你没有任何可记录的数据——俗称 “冷启动”。在这种情况下,你可以采取以下一项或多项操作:
- 首次启动时使用启发式方法,然后根据记录的数据训练系统。
- 使用类似问题的日志来引导您的系统。
- 使用人工评分者通过完成任务来生成数据。
3.3.3 为什么要使用人工标记数据?
使用人工标记数据有优点也有缺点。
优点
- 估者可以执行广泛的任务。
- 数据可以清晰地定义问题。
缺点
- 对于某些领域来说,数据是昂贵的。
- 好的数据通常需要多次迭代。
3.3.4 提高质量
经常检查人工评估者的工作。例如,你自己标记 1000 个示例,然后查看你标记的结果与评分者的结果是否匹配。(自己标记数据也是了解数据的一个很好的练习。)如果出现差异,避免盲目预判你的评级是正确的,尤其是在涉及价值判断的情况下。如果人工评分者引入了错误,需要考虑添加说明来帮助他们,然后重新标注。
无论你如何获取数据,手动查看数据都是一个很好的练习。
4.参考文献
链接-https://developers.google.cn/machine-learning/data-prep/construct/collect/data-size-quality


![NSS [NSSRound#7 Team]ec_RCE](https://img-blog.csdnimg.cn/img_convert/b9222844f88799ad5e9a5cf5dda55ded.png)