一、无锁队列
1.1 什么是无锁队列
无锁队列(Lock-Free Queue)是一种并发数据结构,它允许多个线程在没有锁的情况下进行并发操作。
传统的队列通常通过互斥锁来实现线程安全的操作,但互斥锁在高并发情况下可能会造成竞争和性能瓶颈。为了避免使用锁,无锁队列采用了基于原子操作的并发算法。
无锁队列的设计目标是在保持线程安全的前提下提供高性能的并发操作。它通常使用 CAS(Compare and Swap)等原子指令来实现对队列头部和尾部指针的更新和操作。CAS 操作可以确保只有一个线程能够成功修改指针,其他线程则需要重试或者尝试其他操作。
需要注意的是,虽然无锁队列可以提高并发性能,但在特定的场景下可能会因为竞争条件或线程调度等因素导致性能下降。本文后面会测试对比有锁队列和无锁队列在不同情况下的性能,实际大部分是能用有锁队列的尽量使用有锁队列,除非在每秒处理的任务超过百万条 (ops > 100万) 等情况可以考虑无锁队列。
1.2 CAS锁
比较并交换(compare and swap, CAS),是原子操作的一种,可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。 该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。
bool CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return true ;
}
else
return false ;
}
1.3 为什么要无锁队列
锁会引起以下三个问题:
1)频繁线程抢占,导致cache损坏 / 失效。
2)在同步机制上争抢队列,导致任务将大量的时机浪费在获取保护队列数据的互斥锁,而不是处理队列中的数据。
3)多线程场景下的动态内存分配,会阻塞所有这个任务共享地址空间中的其他任务。
1.3.1 Cache损坏(Cache trashing)
CPU的运行速度比主存快很多,所以大量的处理器时间被浪费在处理器与主存的数据传输上。因此,在处理器和主存之间引入Cache。Cache是一种速度更快但容量更小的内存(也更加昂贵),当处理器要访问主存中的数据时,这些数据首先被拷贝到Cache中,因为这些数据在不久的将来可能又会被处理器访问。
但是在多线程有锁的情况下,线程切换时,保存和恢复上下文的过程中还隐藏了额外的开销:
Cache中的数据会失效,因为它缓存的是将被换出的任务数据,即被新的数据替换出去,那么处理器就需要频繁地从内存中读取数据,降低了缓存的效果。
频繁线程抢占导致的Cache misses对性能有非常大的影响,因为处理器访问Cache中的数据将比直接访问主存快得多。线程被频繁抢占产生的Cache损坏将导致应用程序性能下降。
1.3.2 在同步机制上的争抢队列
阻塞,其实挺浪费资源的。它会导致系统暂停当前的任务或使其进入睡眠状态(等待,不占用CPU资源),直到资源(例如锁机制)可用,被阻塞的任务才能解除阻塞状态(唤醒)。
在一个负载较重的应用程序中,使用这样的阻塞队列来在线程之间传递消息,会导致严重的争用问题。也就是说,任务将大量的时间(睡眠,等待,唤醒)浪费在获得保护队列数据的互斥锁,而不是处理队列中的数据上。
简单说,就是我们喝茶必须这么一个顺序:烧水 ~> 准备茶具 ~> 准备茶叶 ~> 泡茶。阻塞就是必须按顺序来,这不浪费时间嘛。非阻塞,就是烧水的时候干点别的,准备茶具和茶叶。
非阻塞机制下,任务之间不争抢任何资源。举个例子,我们可以在队列中预定一个位置,然后在这个位置上插入或提取数据。这种机制使用了CAS(比较和交换)操作,它可以原子的完成以下操作:它需要3个操作数m,A,B,其中m是一个内存地址,操作将m指向的内存中的内容与A比较,如果相等则将B写入到m指向的内存中并返回true,如果不相等则直接返回false。
volatile int a;
a = 1;
while (!CAS(&a, 1, 2))
{
;
}
如果a的值等于1,则将其原子地替换为2,并返回比较结果。如果比较成功(即a的值为1),则循环结束;否则继续进行下一次循环。
这段代码的目的是在多线程环境下,将a的值从1修改为2,并保证这个修改的原子性和可见性。volatile关键字确保写入操作对所有线程可见,而CAS操作提供了原子性的比较和交换。
1.3.3 动态内存分配
在多线程中,需要仔细考虑动态内存分配。当一个任务从堆中分配内存时,标准的内存分配机制会阻塞所有与这个任务共享地址空间的其他任务(进程中的其他线程)。这样做的原因是让处理更简单,且其工作很好。两个线程不会被分配到一块相同的地址的内存,因为它们没有办法同时执行分配请求。显然线程频繁分配内存会导致应用程序性能下降(必须注意,向标准队列或map插入数据的时候都会导致堆上的动态内存分配)。
二、ZeroMQ中无锁队列的实现
整个无锁队列由两部分组成,一个是yqueue负责队列的组织和操作;另一个是ypipe负责外部读写交互和对内yqueue队列操作。具体来说,yqueue_t可以理解为存储元素的数据结构,ypipe_t则理解为通过 cas+yqueue_t实现无锁队列。
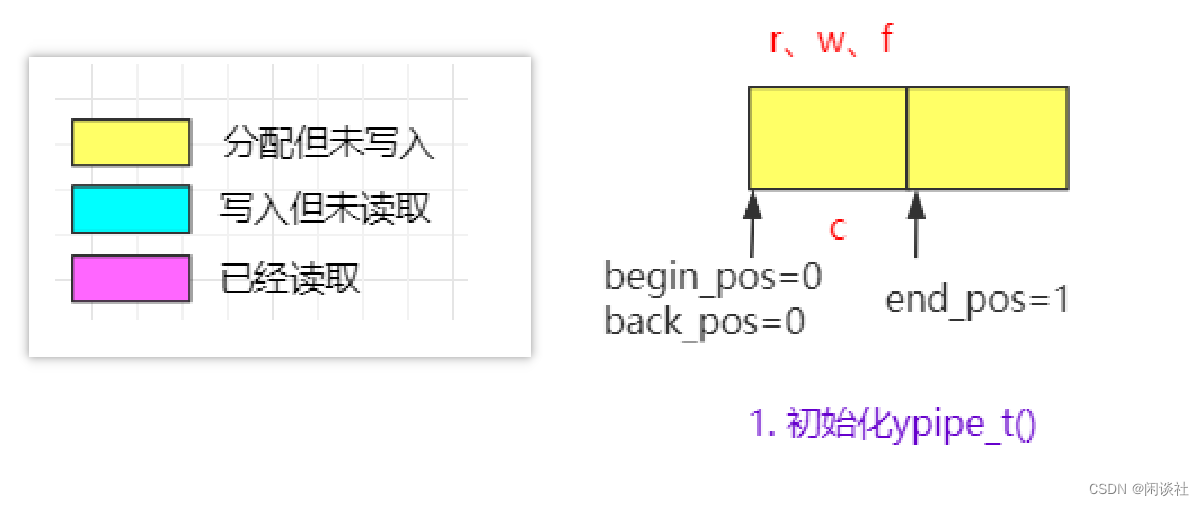
ZeroMQ中无锁队列yqueue的特点(建议看完yqueue之后再回头看一下,就会焕然大悟)
- 适用于一写一读的应用场景。1个epoll + 线程池里每个线程绑定一个唯一的队列
- 通过 chunk机制批量分配结点,减少因为动态分配内存导致的线程间的互斥。
- 通过 spare_ chunk 机制来降低 chunk的频繁分配和释放。消息队列水位的局部性原理。
- 通过预写机制,批量更新写入位置,减少 cas 的调用(同时读写消息队列竞争 cas )。
- 唤醒机制:读端没有数据可读时可以进入 wait状态。写端在写入数据时可以根据返回值获知写入数据前消息队列是否为空。如果队列为空(没有待读取的数据),则可以通过某种方式通知读端,以便读端能够及时得知新的数据到达,并进行相应的处理。
2.1 原子操作
template<typename T>
class atomic_ptr_t {
public:
void set(T *ptr_); // ⾮原⼦操作,设置该指针的值,使用者保证安全
T *xchg(T *val_); // 原⼦操作,设置⼀个新的值,然后返回旧的值
// 原来的值(ptr指向)如果和 comp_的值相同则更新为val_,并返回原来的ptr
// ○ 如果相等返回ptr设置之前的值,并把ptr更新为参数val_的值,;
// ○ 如果不相等直接返回ptr值。
T *cas(T *cmp_, T *val_);// 原⼦操作
private:
volatile T *ptr;
};
2.2 chunk机制
chunk就是一次性分配一个可以容纳多个元素的大块,每个chunk之间利用prev和next组织成一个双向的链表。yqueue_t内部由一个一个chunk组成,每个chunk保存N个元素。当队列空间不足时,每次分配一个chunk。
chunk机制主要是为了解决频繁动态分配内存的问题,减少内存的分配和释放。
struct chunk_t
{
T values[N]; //每个chunk_t可以容纳N个T类型的元素,以后就以一个chunk_t为单位申请内存
chunk_t *prev;
chunk_t *next;
};

2.3 spare_chunk策略
程序局部性原理是指在计算机程序的执行中,程序访问的数据和指令往往集中在某个较小的区域内,而不是均匀地分布在内存中。程序局部性原理可以分为以下两种类型:
1)时间局部性(Temporal Locality):时间局部性指的是程序在一段时间内多次访问相同的数据或指令。当一个数据或指令被访问后,它在短时间内可能被再次使用,因此缓存系统可以将其保留在高速缓存中,以便快速访问。
2)空间局部性(Spatial Locality):空间局部性指的是程序在一段时间内多次访问相邻的数据或指令。当一个数据或指令被访问时,其附近的数据或指令也很可能会很快被访问到,因此将附近的数据或指令一起加载到高速缓存中可以提高缓存的命中率。
在yqueue_t类中有一个spare_chunk用于保存最近的空闲块。在数据出队列后,队列有多余空间的时候,回收的chunk不是马上释放。而是根据局部性原理,先回收到spare_chunk里面,当再次需要分配chunk的时候从spare_chunk中获取。spare_chunk 只保存一个最近回收的 chunk,当有新的空闲块时,保存该空闲块释放之前的空闲块。
2.4 yqueue_t
2.4.1 类接口和变量
template<typename T, int N> // T 队列中元素类型,N 粒度
class yqueue_t {
public:
inline yqueue_t();
inline ~yqueue_t();
inline T &front(); // Returns reference to the front element of the queue.
inline T &back(); // Returns reference to the back element of the queue.
inline void push(); // Adds an element to the back end of the queue.
inline void pop(); // Removes an element from the front of the queue.
inline void unpush() // Removes element from the back end of the queue。
private:
// Individual memory chunk to hold N elements.
struct chunk_t {
T values[N];
chunk_t *prev;
chunk_t *next;
};
chunk_t *begin_chunk;
int begin_pos;
chunk_t *back_chunk;
int back_pos;
chunk_t *end_chunk;
int end_pos;
atomic_ptr_t<chunk_t> spare_chunk; //空闲块,读写线程的共享变量
};
2.4.2 数据结构逻辑
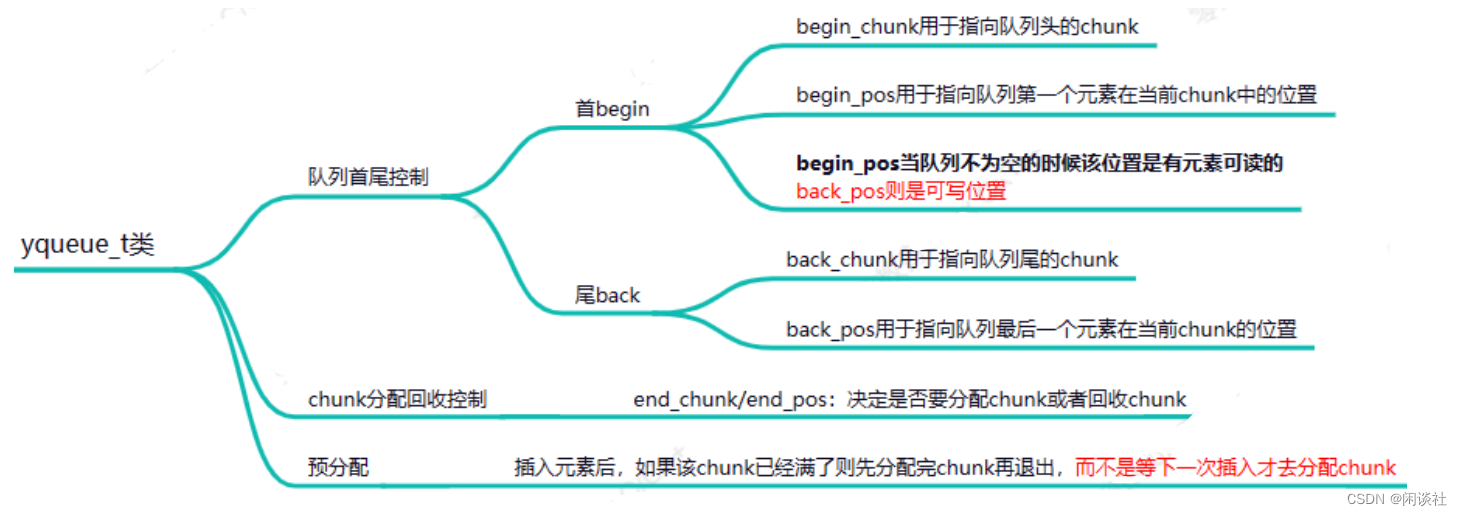
yqueue_t内部有三个chunk_t类型指针以及对应的索引位置
struct chunk_t
{
T values[N];
chunk_t *prev;
chunk_t *next;
};
chunk_t *_begin_chunk;
int _begin_pos;
chunk_t *_back_chunk;
int _back_pos;
chunk_t *_end_chunk;
int _end_pos;
atomic_ptr_t<chunk_t> _spare_chunk;
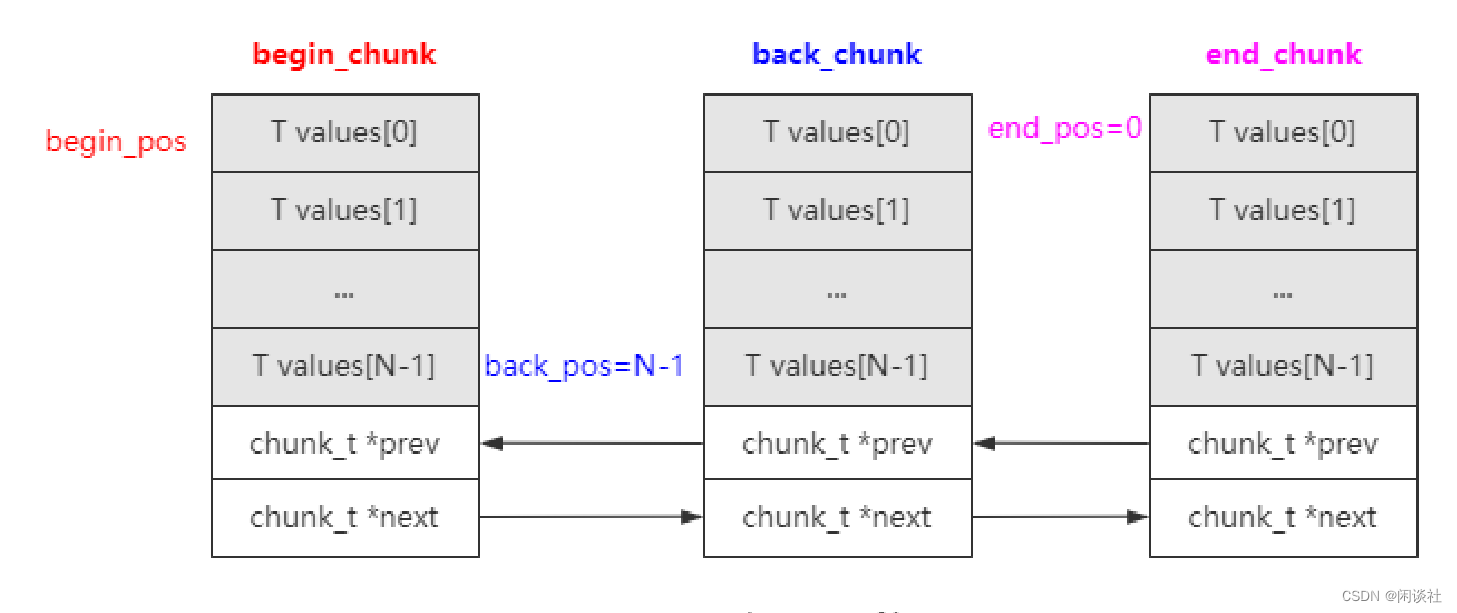
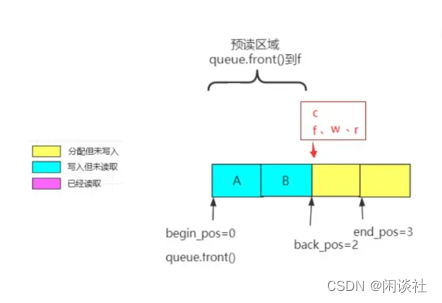
begin_chunk/begin_pos:begin_chunk用于指向队列头的chunk,begin_pos用于指向队列第一个元素在当前chunk中的位置。back_chunk/back_pos:back_chunk用于指向队列尾的chunk,back_pos用于指向队列最后一个元素在当前chunk的位置。end_chunk/end_pos:由于chunk是批量分配的,所以end_chunk用于指向分配的最后一个chunk位置。
注意区分 back_chunk/back_pos 和 end_chunk/end_pos 的作用。
back_chunk/back_pos:对应的是元素存储位置;end_chunk/end_pos:决定是否要分配chunk或者回收chunk。
具体来说,就是
- 若最后一个 chunk 未满,
back_chunk和end_chunk均指向最后一个 chunk,back_pos当前可写入位置,end_pos指向下次可写入的位置,即(back_pos +1) % N == end_pos - 若最后一个 chunk 满了,
end_chunk指向新分配的 chunk,back_pos指向 back_chunk 最后一个元素,end_pos指向 end_chunk 第一个元素,如下图所示
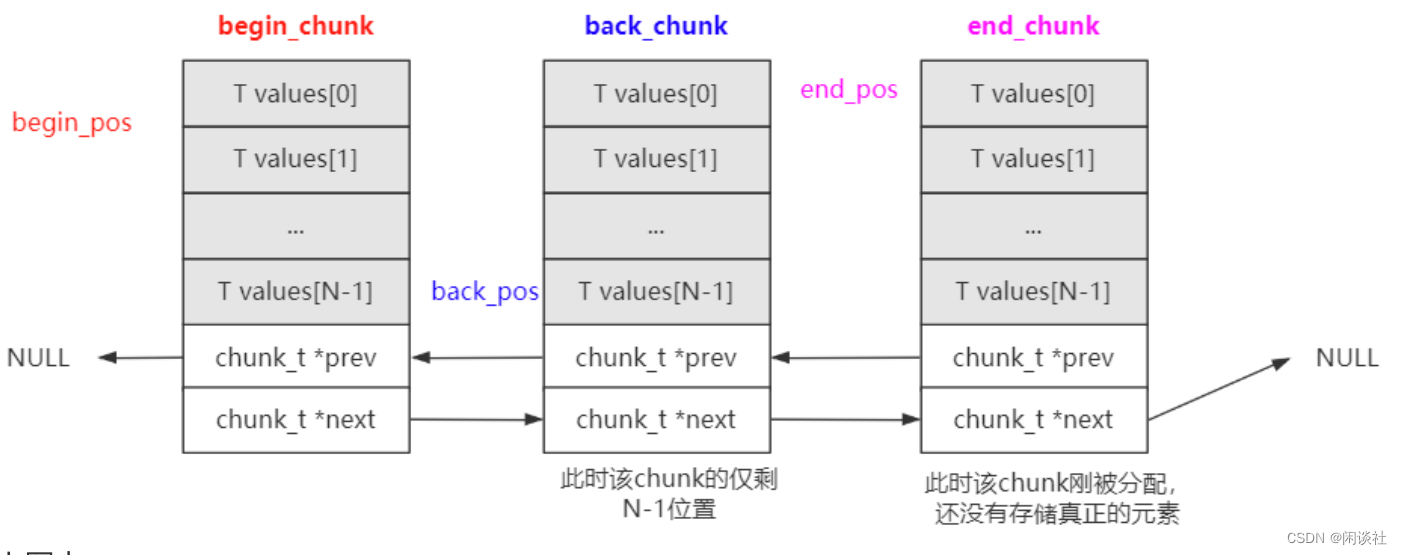
如果插入元素之后,最后一个 chunk 满了之后,需要预分配完新的chunk再退出,而不是等下一次插入才去分配。
另外还有一个spare_chunk指针,用于保存释放的chunk指针,当需要再次分配chunk的时候,会首先查看这里,从这里分配chunk。这里使用了原子的cas操作来完成,利用了操作系统的局部性原理。
2.4.3 构造函数
inline yqueue_t()
{
begin_chunk = (chunk_t *)malloc(sizeof(chunk_t)); // 预先分配chunk
alloc_assert(begin_chunk);
begin_pos = 0;
back_chunk = NULL; //back_chunk总是指向队列中最后一个元素所在的chunk,现在还没有元素,所
以初始为空
back_pos = 0;
end_chunk = begin_chunk; //end_chunk总是指向链表的最后一个chunk
end_pos = 0;
}
end_chunk总是指向最后分配的chunk,刚分配出来的chunk,end_pos也总是为0。
back_chunk需要chunk有元素插入的时候才指向对应的chunk。

2.4.4 front、back函数
函数返回的是左值引用,可以修改其值.
begin_chunk->values[begin_pos]:返回队首可读元素
back_chunk->values[back_pos]:返回队尾可写元素
// 返回队列头部元素的引用,调用者可以通过该引用更新元素,结合pop实现出队列操作。
inline T &front() // 返回的是引用,是个左值,调用者可以通过其修改容器的值
{
return begin_chunk->values[begin_pos];
}
// 返回队列尾部元素的引用,调用者可以通过该引用更新元素,结合push实现插入操作。
// 如果队列为空,该函数是不允许被调用。
inline T &back() // 返回的是引用,是个左值,调用者可以通过其修改容器的值
{
return back_chunk->values[back_pos];
}
对于先进后出队列而言:
begin_chunk->values[begin_pos]代表队列头可读元素, 读取队列头元素即是读取begin_pos位置的元素;back_chunk->values[back_pos]代表队列尾可写元素,写入元素时则是更新back_pos位置的元素,要确保元素真正生效,还需要调用push函数更新back_pos的位置,避免下次更新的时候又是更新当前back_pos位置对应的元素。
2.4.5 push函数
更新下一次元素写入的位置。
push 操作前,要判断若执行 push 操作后该 chunk 是否还有空间。这里分为两种情况:
1)第一种情况:++end_pos != N,说明当前chunk还有空余的位置可以继续插入新元素。此时 back_pos和end_pos相差一个位置,即是 (back_pos +1)%N == end_pos。
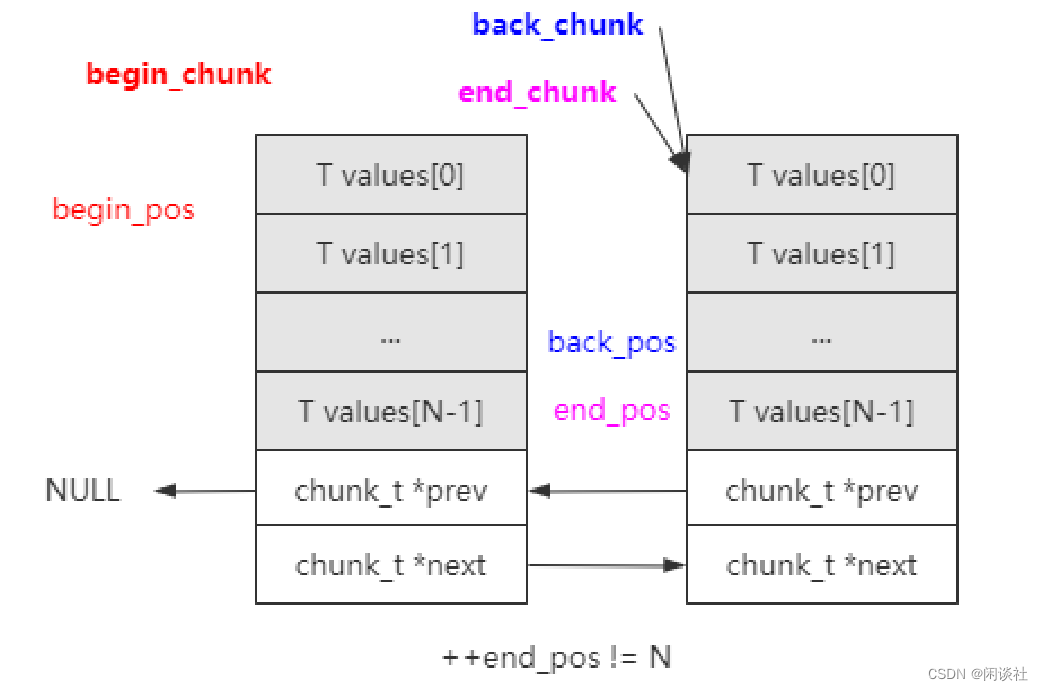
2)第二种情况:++end_pos == N,说明该chunk只有[N-1]的索引位置可以写入元素了,需要再分配一个chunk空间。需要新分配chunk时,先尝试从spare_chunk获取
- 如果获取到则直接使用,如果spare_chunk为NULL则需要重新分配chunk。
- 最后更新
end_chunk和end_pos。
// Adds an element to the back end of the queue.
inline void push() {
back_chunk = end_chunk;
back_pos = end_pos;
// 若执行 push 操作后该结点是否还有空间
// 1、若该 chunk 结点仍有空间,无需扩容
if (++end_pos != N) return;
// 2、若该 chunk 结点没有空间了,需要扩容
// 为什么设置为NULL? 因为如果把 spare chunk 取出则没有了,所以设置为NULL
chunk_t *sc = spare_chunk.xchg(NULL);
// 判断是否有 spare_chunk
// 2.1、如果有spare_chunk,则继续复用它
if (sc) {
end_chunk->next = sc;
sc->prev = end_chunk;
}
// 2.2、如果没有spare_chunk,则重新分配
else {
end_chunk->next = (chunk_t *)malloc(sizeof(chunk_t)); // 分配一个chunk
alloc_assert(end_chunk->next);
end_chunk->next->prev = end_chunk;
}
// 更新 end_chunk 和 end_pos
end_chunk = end_chunk->next;
end_pos = 0;
}
push()函数的使用:
(1)通过back()获取可写入位置,写入数据;
(2)通过push()更新下一个可写位置。
2.4.6 pop函数
更新下一次读取的位置,并检测是否需要释放chunk。
1)++begin_pos != N:还有元素没有取出,还要继续被使⽤;
2)++begin_pos == N:所有元素都已经取出,需要回收该 chunk。此时先保存到spare_chunk,然后检测spare_chunk返回值是否为空。如果返回值不为空说明之前有保存chunk,但我们只能保存一个chunk,所以把之前的chunk释放掉。
// Removes an element from the front end of the queue.
inline void pop() {
// 判断是否需要释放该 chunk,删除满一个chunk才会回收chunk
if (++begin_pos == N) {
chunk_t *o = begin_chunk;
// 重新设置当前 chunk
begin_chunk = begin_chunk->next;
begin_chunk->prev = NULL;
begin_pos = 0;
// spare_chunk 只保留一个 chunk
// 由于局部性原理,总是保存最新的空闲块而释放先前的空闲快
chunk_t *cs = spare_chunk.xchg(o);
free(cs);
}
}
这里有两个点需要注意:
1)pop掉的元素,其销毁工作交给调用者完成,即是pop前调用者需要通过front()接口读取并进行销毁(比如动态分配的对象)。
2)空闲块的保存,要求是原子操作。因为闲块是读写线程的共享变量,因为在push中也使用了spare_chunk。
push()函数的使用:
1)通过front()读取数据;
2)读完数据后通过pop()更新下一个可读位置。
2.4.7 源码
/*
Copyright (c) 2007-2013 Contributors as noted in the AUTHORS file
This file is part of 0MQ.
0MQ is free software; you can redistribute it and/or modify it under
the terms of the GNU Lesser General Public License as published by
the Free Software Foundation; either version 3 of the License, or
(at your option) any later version.
0MQ is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
#ifndef __ZMQ_YQUEUE_HPP_INCLUDED__
#define __ZMQ_YQUEUE_HPP_INCLUDED__
#include <stdlib.h>
#include <stddef.h>
// #include "err.hpp"
#include "atomic_ptr.hpp"
// yqueue is an efficient queue implementation. The main goal is
// to minimise number of allocations/deallocations needed. Thus yqueue
// allocates/deallocates elements in batches of N.
//
// yqueue allows one thread to use push/back function and another one
// to use pop/front functions. However, user must ensure that there's no
// pop on the empty queue and that both threads don't access the same
// element in unsynchronised manner.
//
// T is the type of the object in the queue. 队列中元素的类型
// N is granularity(粒度) of the queue (how many pushes have to be done till actual memory allocation is required).
// 即是yqueue_t一个结点可以装载N个T类型的元素, yqueue_t的一个结点是一个数组
template <typename T, int N>
class yqueue_t
{
public:
// 创建队列.
inline yqueue_t()
{
begin_chunk = (chunk_t *)malloc(sizeof(chunk_t));
alloc_assert(begin_chunk);
begin_pos = 0;
back_chunk = NULL; //back_chunk总是指向队列中最后一个元素所在的chunk,现在还没有元素,所以初始为空
back_pos = 0;
end_chunk = begin_chunk; //end_chunk总是指向链表的最后一个chunk
end_pos = 0;
}
// 销毁队列.
inline ~yqueue_t()
{
while (true)
{
if (begin_chunk == end_chunk)
{
free(begin_chunk);
break;
}
chunk_t *o = begin_chunk;
begin_chunk = begin_chunk->next;
free(o);
}
chunk_t *sc = spare_chunk.xchg(NULL);
free(sc);
}
// Returns reference to the front element of the queue.
// If the queue is empty, behaviour is undefined.
// 返回队列头部元素的引用,调用者可以通过该引用更新元素,结合pop实现出队列操作。
inline T &front() // 返回的是引用,是个左值,调用者可以通过其修改容器的值
{
return begin_chunk->values[begin_pos];
}
// Returns reference to the back element of the queue.
// If the queue is empty, behaviour is undefined.
// 返回队列尾部元素的引用,调用者可以通过该引用更新元素,结合push实现插入操作。
// 如果队列为空,该函数是不允许被调用。
inline T &back() // 返回的是引用,是个左值,调用者可以通过其修改容器的值
{
return back_chunk->values[back_pos];
}
// Adds an element to the back end of the queue.
inline void push()
{
back_chunk = end_chunk;
back_pos = end_pos; //
if (++end_pos != N) //end_pos!=N表明这个chunk节点还没有满
return;
chunk_t *sc = spare_chunk.xchg(NULL); // 为什么设置为NULL? 因为如果把之前值取出来了则没有spare chunk了,所以设置为NULL
if (sc) // 如果有spare chunk则继续复用它
{
end_chunk->next = sc;
sc->prev = end_chunk;
}
else // 没有则重新分配
{
// static int s_cout = 0;
// printf("s_cout:%d\n", ++s_cout);
end_chunk->next = (chunk_t *)malloc(sizeof(chunk_t)); // 分配一个chunk
alloc_assert(end_chunk->next);
end_chunk->next->prev = end_chunk;
}
end_chunk = end_chunk->next;
end_pos = 0;
}
// Removes element from the back end of the queue. In other words
// it rollbacks last push to the queue. Take care: Caller is
// responsible for destroying the object being unpushed.
// The caller must also guarantee that the queue isn't empty when
// unpush is called. It cannot be done automatically as the read
// side of the queue can be managed by different, completely
// unsynchronised thread.
// 必须要保证队列不为空,参考ypipe_t的uwrite
inline void unpush()
{
// First, move 'back' one position backwards.
if (back_pos) // 从尾部删除元素
--back_pos;
else
{
back_pos = N - 1; // 回退到前一个chunk
back_chunk = back_chunk->prev;
}
// Now, move 'end' position backwards. Note that obsolete end chunk
// is not used as a spare chunk. The analysis shows that doing so
// would require free and atomic operation per chunk deallocated
// instead of a simple free.
if (end_pos) // 意味着当前的chunk还有其他元素占有
--end_pos;
else
{
end_pos = N - 1; // 当前chunk没有元素占用,则需要将整个chunk释放
end_chunk = end_chunk->prev;
free(end_chunk->next);
end_chunk->next = NULL;
}
}
// Removes an element from the front end of the queue.
inline void pop()
{
if (++begin_pos == N) // 删除满一个chunk才回收chunk
{
chunk_t *o = begin_chunk;
begin_chunk = begin_chunk->next;
begin_chunk->prev = NULL;
begin_pos = 0;
// 'o' has been more recently used than spare_chunk,
// so for cache reasons we'll get rid of the spare and
// use 'o' as the spare.
chunk_t *cs = spare_chunk.xchg(o); //由于局部性原理,总是保存最新的空闲块而释放先前的空闲快
free(cs);
}
}
private:
// Individual memory chunk to hold N elements.
// 链表结点称之为chunk_t
struct chunk_t
{
T values[N]; //每个chunk_t可以容纳N个T类型的元素,以后就以一个chunk_t为单位申请内存
chunk_t *prev;
chunk_t *next;
};
// Back position may point to invalid memory if the queue is empty,
// while begin & end positions are always valid. Begin position is
// accessed exclusively be queue reader (front/pop), while back and
// end positions are accessed exclusively by queue writer (back/push).
chunk_t *begin_chunk; // 链表头结点
int begin_pos; // 起始点
chunk_t *back_chunk; // 队列中最后一个元素所在的链表结点
int back_pos; // 尾部
chunk_t *end_chunk; // 拿来扩容的,总是指向链表的最后一个结点
int end_pos;
// People are likely to produce and consume at similar rates. In
// this scenario holding onto the most recently freed chunk saves
// us from having to call malloc/free.
atomic_ptr_t<chunk_t> spare_chunk; //空闲块(把所有元素都已经出队的块称为空闲块),读写线程的共享变量
// Disable copying of yqueue.
yqueue_t(const yqueue_t &);
const yqueue_t &operator=(const yqueue_t &);
};
#endif
2.5 ypipe_t
ypipe_t在yqueue_t的基础上构建一个单写单读的无锁队列
2.5.1 类接口和变量
template<typename T, int N>
class ypipe_t {
public:
inline ypipe_t();
inline virtual ~ypipe_t();
// 写入数据,incomplete参数表示写入是否还没完成,在没完成的时候不会修改flush指针,即这部分数据不会让读线程看到。
inline void write(const T &value_, bool incomplete_);
inline bool unwrite(T *value_);
// 刷新所有已经完成的数据到管道,返回false意味着读线程在休眠,在这种情况下调用者需要唤醒读线程。
inline bool flush();
// 这里面有两个点,一个是检查是否有数据可读,一个是预取
inline bool check_read();
inline bool read(T *value_);
inline bool probe(bool (*fn)(T &));
protected:
yqueue_t<T, N> queue;
T *w; //指向第一个未刷新的元素,只被写线程使用
T *r; //指向第一个还没预提取的元素,只被读线程使用
T *f; //指向下一轮要被刷新的一批元素中的第一个
//读写线程共享的指针,指向每一轮刷新的起点(看代码的时候会详细说)。当c为空时,表示读线程睡眠(只会在读线程中被设置为空)
atomic_ptr_t<T> c;
ypipe_t(const ypipe_t &);
const ypipe_t &operator=(const ypipe_t &);
};
r: 可读指针,用来控制可读位置,指向第一个未预取的元素,读线程使用。注意区分,r-1位置可读取,r 位置位未预取,没能取出来则不能读取,读取到 r 位置就不能再读了w: 可写指针,用来控制是否需要唤醒读端,指向第一个未刷新的元素,写线程使用。当读端没有数据可以读取的时候,将c变量设置为NULL,w 由写端控制,只受 f 修改f: 刷新指针,用来控制写入位置,指向下一轮要被刷新的一批元素中的第一个。当该 f 被更新到 c 的时候,读端才能看到写入的数据c:读写线程共享的指针,指向每⼀轮刷新的起点。当 c == w 时,指向该轮刷新的起点;当 c == NULL 时,无数据可读,表示读线程睡眠(只会在读线程中被设置为空)。
2.5.2 构造函数
inline ypipe_t()
{
// Insert terminator element into the queue.
queue.push();//yqueue_t的尾指针加1,开始back_chunk为空,back_chunk指向第一个chunk_t块的第一个位置
// Let all the pointers to point to the terminator.
// (unless pipe is dead, in which case c is set to NULL).
r = w = f = &queue.back();//就是让r、w、f、c四个指针都指向这个end迭代器
c.set(&queue.back()); // 保存[0]索引的位置
}
2.5.3 write函数
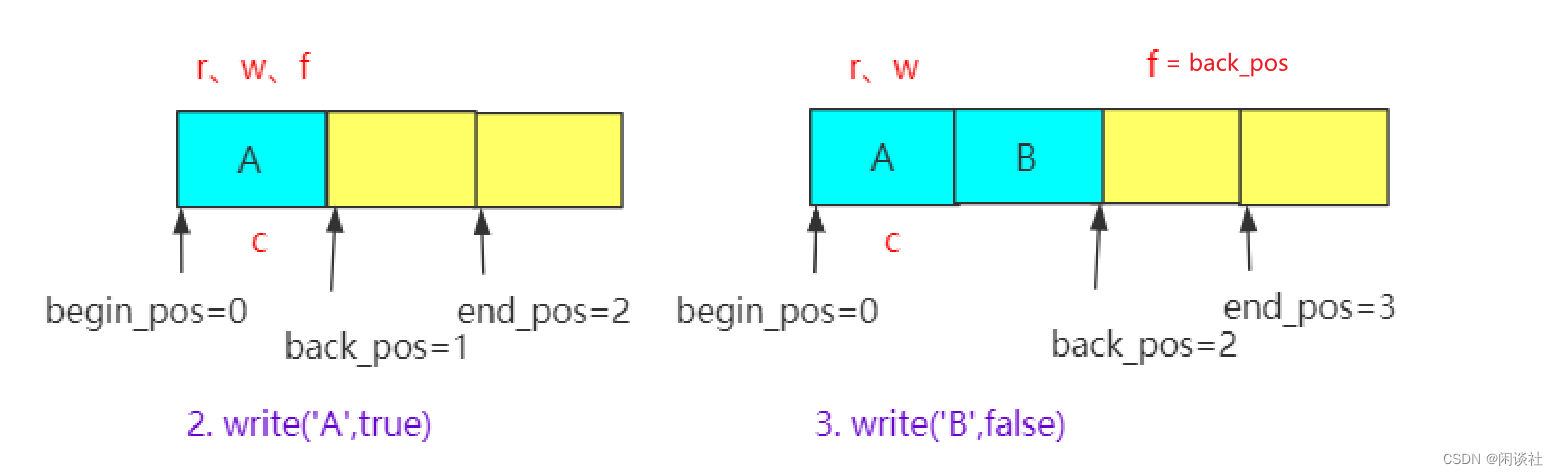
ypipe支持批量的写数据,写入数据时,将元素加入队列尾部。其中incomplete参数表示是否准备好,若为 true表示没有写完,只是负责队列加入数据。若为 false,则刷新,刷新指针f才被赋值为队列最后元素位置。才能被读线程看到。
// Write an item to the pipe. Don't flush it yet. If incomplete is
// set to true the item is assumed to be continued by items
// subsequently written to the pipe. Incomplete items are never flushed down the stream.
inline void write(const T &value_, bool incomplete_) {
// Place the value to the queue, add new terminator element.
// 写入数据:通过 back 获取可写位置并写入数据;通过 push 更新下一个可写位置
queue.back() = value_;
queue.push();
// Move the "flush up to here" poiter.
// 判断写操作是否已经完成
// 1、若写入完成,则刷新 flush 指针
if (!incomplete_) {
f = &queue.back(); // 记录要刷新的位置
}
// 2、若写入还未完成,不修改 flush 指针,read 没有数据
}
2.5.4 flush函数
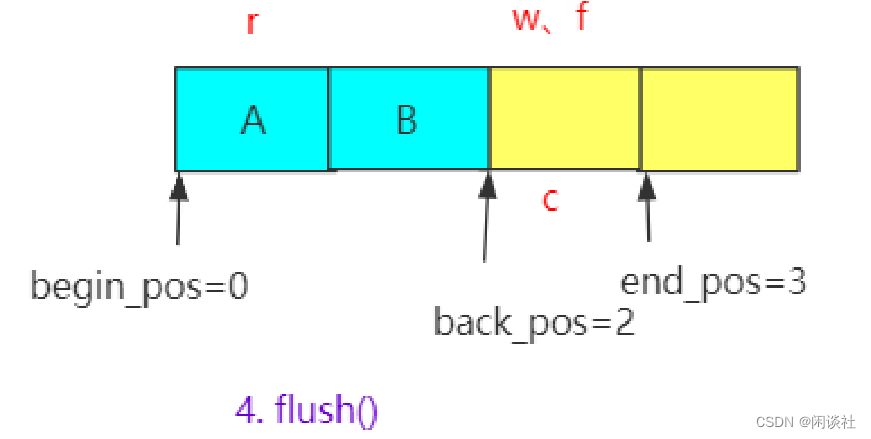
批量刷新已经写入的数据到管道,并将指针 c, w 更新到指针 f 的位置。
刷新数据是更新可写w指针的位置,
1)当可写指针w等于刷新指针f,表示没有可以更新的操作直接返回。
2)c值是唯一会被两个读写线程同时操作的值,引入一个cas原子操作更新c,做到线程安全。
- 当
c== w,表示当前读缓冲区有数据可以读,更新c = f。 - 当
c!= w,表示当前读缓冲区没有数据可以读,会返回一个false,这时候表示需要通知读线程已经来数据了,以便读端能够及时得知新的数据到达,并进行相应的处理。
// Flush all the completed items into the pipe. Returns false if
// the reader thread is sleeping. In that case, caller is obliged to
// wake the reader up before using the pipe again.
// 刷新所有已经完成的数据到管道,返回false说明读线程在休眠,此时需要调用者唤醒读线程。
// 批量刷新的机制, 写入批量后唤醒读线程;
inline bool flush() {
// If there are no un-flushed items, do nothing.
// 1、没有新元素加入,不需要更新
if (w == f) {
return true;
}
// Try to set 'c' to 'f'.
// 尝试将 c 设置为 f
// 注意:参考 read 函数,读端没有读取到数据,则 c = NULL,
// cas 操作:比较 c 和 w 是否相等。相等则 c = f,否则不做任何操作。返回旧的 c 值
// 1、若 c != w,说明读端没有读取到数据(c = NULL), 不做任何操作,返回NULL
if (c.cas(w, f) != w) {
// Compare-and-swap was unseccessful because 'c' is NULL.
// This means that the reader is asleep. Therefore we don't
// care about thread-safeness and update c in non-atomic
// manner. We'll return false to let the caller know
// that reader is sleeping.
c.set(f); // 更新 c,非原子操作(因为读线程睡眠,不存在竞争)
w = f; // 更新 w
return false; // 返回 false 需要唤醒读线程,这需要写业务去做处理
}
// 2、若 c == w,读端还有数据可读取,则自动更新 c = f(原子操作),返回c(w)
else {
// Reader is alive. Nothing special to do now. Just move
// the 'first un-flushed item' pointer to 'f'.
w = f; // 更新 w
return true;
}
}
2.5.5 check_read函数
读校验主要是进行读之前先判断是否可读
1)如果可读指针r和队头元素(r==&queue.front()),或者r没有指向任何元素(NULL),则说明队列中并没有可读的数据,尝试去预取数据。
2)预取数据就是令r = c,再根据flush函数,则有r = c = w = f,表示从 &queue.front() 到f这些位置的数据都被预取出来了。此后每次调用 read 都能取出一块数据,当 c== &queue.front()时,代表数据被取完了,这时将c置为 NULL,读线程睡眠,这也是写线程检查读线程是否睡眠的标志。
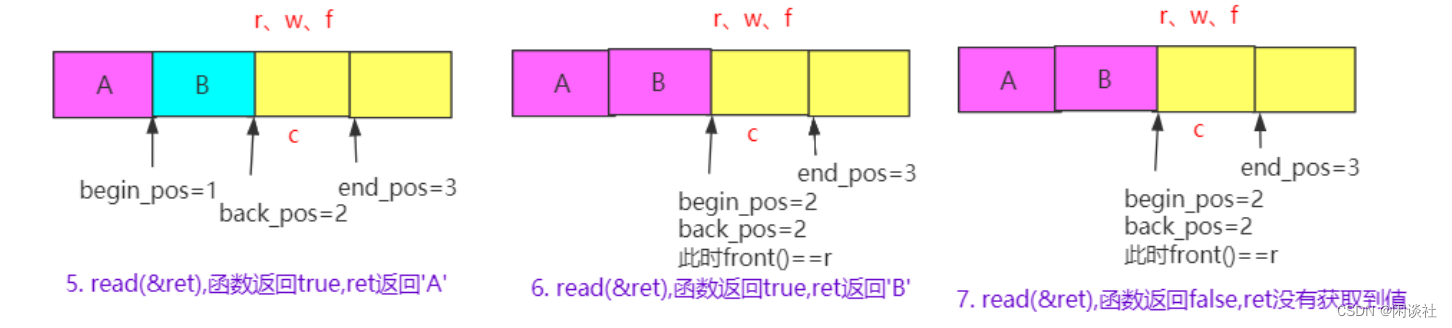
如图所示,第一次调用 read,先check_read 检测到没有数据可读,尝试预取数据成功(令r = c),更新 r = c = w = f,read 读出数据 A。第二次调用 read,check_read 检测到仍有数据可读,则 read 读出数据 B。第三次调用 read, check_read 检测到没有数据可读,尝试预取数据失败,更新 r = NULL,读线程休眠,read 返回 false,本次读取失败。
这里总结一下,读写线程共享的指针 c 值的情况
1)NULL:读线程设置,此时意味着已经没有数据可读,读线程在休眠
2)非零:写线程设置,分两种情况:
○ 旧值为 w,cas(w,f) 操作修改为 f,意味着如果旧值为 w,则原子性的修改为 f,表示有更多已被刷新的数据可读。
○ 旧值为 NULL,读线程休眠,因此可以安全的设置为当前 f 指针的位置。
// Check whether item is available for reading.
// 这里面有两个点,一个是检查是否有数据可读,一个是预取
inline bool check_read() {
// Was the value prefetched already? If so, return.
// 第一次 read 时,r == front,这里判断不成立
// 判断是否在前几次调用 read 函数时已经预取到数据了,return true
if (&queue.front() != r && r)
return true; // 有数据可以读
// There's no prefetched value, so let us prefetch more values.
// Prefetching is to simply retrieve the
// pointer from c in atomic fashion. If there are no
// items to prefetch, set c to NULL (using compare-and-swap).
// 尝试预取数据,更新 r = 旧的 c (w=f),分为两种情况
// 1. 如果此时还没有数据写入,c == &queue.front(), 将 c 置为 NULL
// 2. 如果此时已经有数据写入,c != &queue.front(),返回 c 的位置
r = c.cas(&queue.front(), NULL); // 尝试预取数据,r 指向可以读取到的位置
// If there are no elements prefetched, exit.
// During pipe's lifetime r should never be NULL, however,
// it can happen during pipe shutdown when items are being deallocated.
// 判断是否成功预取数据
// 若队列中无数据可读,r == front,当前队列为空;r == NULL,初始时队列为空
if (&queue.front() == r || !r)
return false;
// There was at least one value prefetched.
return true;
}
2.5.6 read函数
检测是否有数据可读,若有则读取队首元素并 pop 掉
// Reads an item from the pipe. Returns false if there is no value.
// available.
inline bool read(T *value_) {
// Try to prefetch a value.
// 检测是否有数据可以读取
if (!check_read())
return false;
// There was at least one value prefetched.
// Return it to the caller.
// 读取操作:front + pop
*value_ = queue.front();
queue.pop();
return true;
}
2.5.7 源码
/*
Copyright (c) 2007-2013 Contributors as noted in the AUTHORS file
This file is part of 0MQ.
0MQ is free software; you can redistribute it and/or modify it under
the terms of the GNU Lesser General Public License as published by
the Free Software Foundation; either version 3 of the License, or
(at your option) any later version.
0MQ is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
#ifndef __ZMQ_YPIPE_HPP_INCLUDED__
#define __ZMQ_YPIPE_HPP_INCLUDED__
#include "atomic_ptr.hpp"
#include "yqueue.hpp"
// Lock-free queue implementation.
// Only a single thread can read from the pipe at any specific moment.
// Only a single thread can write to the pipe at any specific moment.
// T is the type of the object in the queue.
// N is granularity of the pipe, i.e. how many items are needed to
// perform next memory allocation.
template <typename T, int N>
class ypipe_t
{
public:
// Initialises the pipe.
inline ypipe_t()
{
// Insert terminator element into the queue.
queue.push(); //yqueue_t的尾指针加1,开始back_chunk为空,现在back_chunk指向第一个chunk_t块的第一个位置
// Let all the pointers to point to the terminator.
// (unless pipe is dead, in which case c is set to NULL).
r = w = f = &queue.back(); //就是让r、w、f、c四个指针都指向这个end迭代器
c.set(&queue.back());
}
// The destructor doesn't have to be virtual. It is mad virtual
// just to keep ICC and code checking tools from complaining.
inline virtual ~ypipe_t()
{
}
// Following function (write) deliberately copies uninitialised data
// when used with zmq_msg. Initialising the VSM body for
// non-VSM messages won't be good for performance.
#ifdef ZMQ_HAVE_OPENVMS
#pragma message save
#pragma message disable(UNINIT)
#endif
// Write an item to the pipe. Don't flush it yet. If incomplete is
// set to true the item is assumed to be continued by items
// subsequently written to the pipe. Incomplete items are neverflushed down the stream.
// 写入数据,incomplete参数表示写入是否还没完成,在没完成的时候不会修改flush指针,即这部分数据不会让读线程看到。
inline void write(const T &value_, bool incomplete_)
{
// Place the value to the queue, add new terminator element.
queue.back() = value_;
queue.push();
// Move the "flush up to here" poiter.
if (!incomplete_)
{
f = &queue.back(); // 记录要刷新的位置 false 更新f
// printf("1 f:%p, w:%p\n", f, w);
}
else
{
// printf("0 f:%p, w:%p\n", f, w);
}
}
#ifdef ZMQ_HAVE_OPENVMS
#pragma message restore
#endif
// Pop an incomplete item from the pipe. Returns true is such
// item exists, false otherwise.
inline bool unwrite(T *value_)
{
if (f == &queue.back())
return false;
queue.unpush();
*value_ = queue.back();
return true;
}
// Flush all the completed items into the pipe. Returns false if
// the reader thread is sleeping. In that case, caller is obliged to
// wake the reader up before using the pipe again.
// 刷新所有已经完成的数据到管道,返回false意味着读线程在休眠,在这种情况下调用者需要唤醒读线程。
// 批量刷新的机制, 写入批量后唤醒读线程;
// 反悔机制 unwrite
inline bool flush()
{
// If there are no un-flushed items, do nothing.
if (w == f) // 不需要刷新,即是还没有新元素加入
return true;
// Try to set 'c' to 'f'.
// read时如果没有数据可以读取则c的值会被置为NULL
if (c.cas(w, f) != w) // 尝试将c设置为f,即是准备更新w的位置
{
// Compare-and-swap was unseccessful because 'c' is NULL.
// This means that the reader is asleep. Therefore we don't
// care about thread-safeness and update c in non-atomic
// manner. We'll return false to let the caller know
// that reader is sleeping.
c.set(f); // 更新w的位置
w = f;
return false; //线程看到flush返回false之后会发送一个消息给读线程,这需要写业务去做处理
}
else // 读端还有数据可读取
{
// Reader is alive. Nothing special to do now. Just move
// the 'first un-flushed item' pointer to 'f'.
w = f; // 只需要更新w的位置
return true;
}
}
// Check whether item is available for reading.
// 这里面有两个点,一个是检查是否有数据可读,一个是预取
inline bool check_read()
{
// Was the value prefetched already? If so, return.
if (&queue.front() != r && r) //判断是否在前几次调用read函数时已经预取数据了return true;
return true;
// There's no prefetched value, so let us prefetch more values.
// Prefetching is to simply retrieve the
// pointer from c in atomic fashion. If there are no
// items to prefetch, set c to NULL (using compare-and-swap).
// 两种情况
// 1. 如果c值和queue.front(), 返回c值并将c值置为NULL,此时没有数据可读
// 2. 如果c值和queue.front(), 返回c值,此时可能有数据度的去
r = c.cas(&queue.front(), NULL); //尝试预取数据
// If there are no elements prefetched, exit.
// During pipe's lifetime r should never be NULL, however,
// it can happen during pipe shutdown when items are being deallocated.
if (&queue.front() == r || !r) //判断是否成功预取数据
return false;
// There was at least one value prefetched.
return true;
}
// Reads an item from the pipe. Returns false if there is no value.
// available.
inline bool read(T *value_)
{
// Try to prefetch a value.
if (!check_read())
return false;
// There was at least one value prefetched.
// Return it to the caller.
*value_ = queue.front();
queue.pop();
return true;
}
// Applies the function fn to the first elemenent in the pipe
// and returns the value returned by the fn.
// The pipe mustn't be empty or the function crashes.
inline bool probe(bool (*fn)(T &))
{
bool rc = check_read();
// zmq_assert(rc);
return (*fn)(queue.front());
}
protected:
// Allocation-efficient queue to store pipe items.
// Front of the queue points to the first prefetched item, back of
// the pipe points to last un-flushed item. Front is used only by
// reader thread, while back is used only by writer thread.
yqueue_t<T, N> queue;
// Points to the first un-flushed item. This variable is used
// exclusively by writer thread.
T *w; //指向第一个未刷新的元素,只被写线程使用
// Points to the first un-prefetched item. This variable is used
// exclusively by reader thread.
T *r; //指向第一个还没预提取的元素,只被读线程使用
// Points to the first item to be flushed in the future.
T *f; //指向下一轮要被刷新的一批元素中的第一个
// The single point of contention between writer and reader thread.
// Points past the last flushed item. If it is NULL,
// reader is asleep. This pointer should be always accessed using
// atomic operations.
atomic_ptr_t<T> c; //读写线程共享的指针,指向每一轮刷新的起点(看代码的时候会详细说)。当c为空时,表示读线程睡眠(只会在读线程中被设置为空)
// Disable copying of ypipe object.
ypipe_t(const ypipe_t &);
const ypipe_t &operator=(const ypipe_t &);
};
#endif
三、基于循环数组的无锁队列
3.1 类接口和变量
#ifndef _ARRAYLOCKFREEQUEUE_H___
#define _ARRAYLOCKFREEQUEUE_H___
#include <stdint.h>
#ifdef _WIN64
#define QUEUE_INT int64_t
#else
#define QUEUE_INT unsigned long
#endif
#define ARRAY_LOCK_FREE_Q_DEFAULT_SIZE 65535 // 2^16
template <typename ELEM_T, QUEUE_INT Q_SIZE = ARRAY_LOCK_FREE_Q_DEFAULT_SIZE>
class ArrayLockFreeQueue
{
public:
ArrayLockFreeQueue();
virtual ~ArrayLockFreeQueue();
QUEUE_INT size();
bool enqueue(const ELEM_T &a_data);//入队
bool dequeue(ELEM_T &a_data);// 出队
bool try_dequeue(ELEM_T &a_data);//尝试入队
private:
ELEM_T m_thequeue[Q_SIZE];
volatile QUEUE_INT m_count;//队列的元素个数
volatile QUEUE_INT m_writeIndex;//新元素入队时存放位置在数组中的下标
volatile QUEUE_INT m_readIndex;//下一个出队元素在数组中的下标
volatile QUEUE_INT m_maximumReadIndex;// 最后一个已经完成入队操作的元素在数组中的下标
inline QUEUE_INT countToIndex(QUEUE_INT a_count);
};
#include "ArrayLockFreeQueueImp.h"
#endif
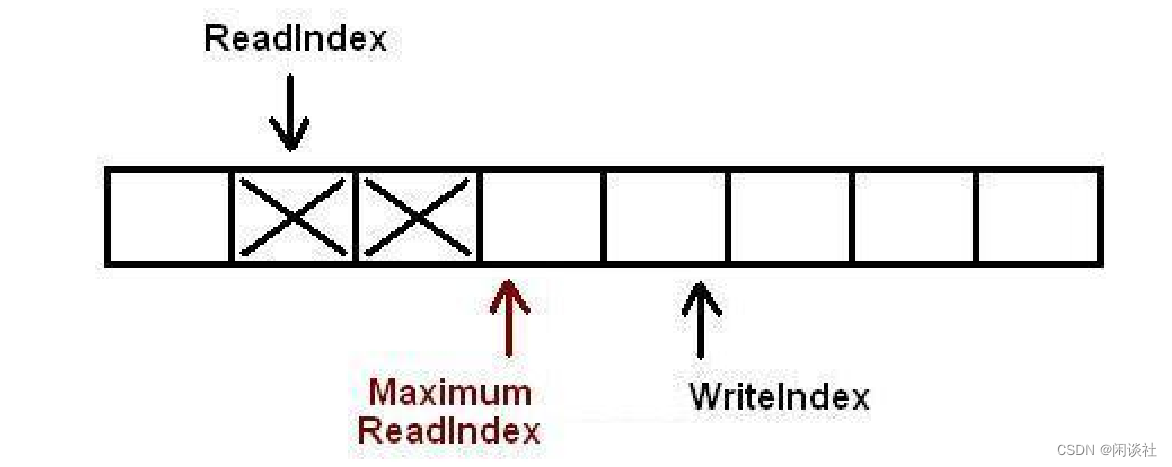
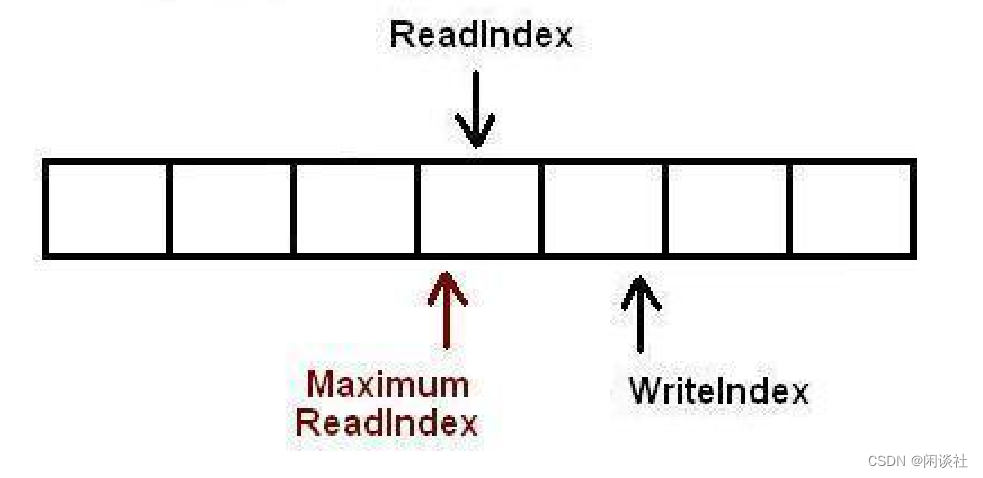
m_count:队列元素的个数。m_writeIndex:指向新元素入队(可写入)的位置。只表示写请求成功并申请空间,并不代表数据已经写入,不能用于读取。m_readIndex:指向下一个出队(可读出)元素的位置。m_maximumReadIndex:指向存放最后一个有效数据(已经完成写入)的位置,即可读位置的边界。如果它的值跟m_writeIndex不一致,表明有写请求尚未完成。这意味着,有写请求成功申请了空间但数据还没完全写进队列。所以如果有线程要读取,必须要等到写线程将数据完全写入到队列之后。
[readIndex, maximumReadIndex)这一范围内的数据都可以读取。

3.2 enqueue入队列
以下插图展示了对队列执行操作时各下标是如何变化的。如果一个位置被标记为X,标识这个位置里存放了数据。空白表示位置是空的。对于下图的情况,队列中存放了两个元素。WriteIndex指示的位置是新元素将会被插入的位置。ReadIndex指向的位置中的元素将会在下一次pop操作中被弹出。

1)当生产者准备将数据插入到队列中,它首先通过增加WriteIndex的值来申请空间MaximumReadIndex指向最后一个存放有效数据的位置(也就是实际的队列尾)。
2)一旦空间的申请完成,生产者就可以将数据拷贝到刚刚申请到的位置中。完成之后增MaximumReadIndex使得它与WriteIndex的一致。
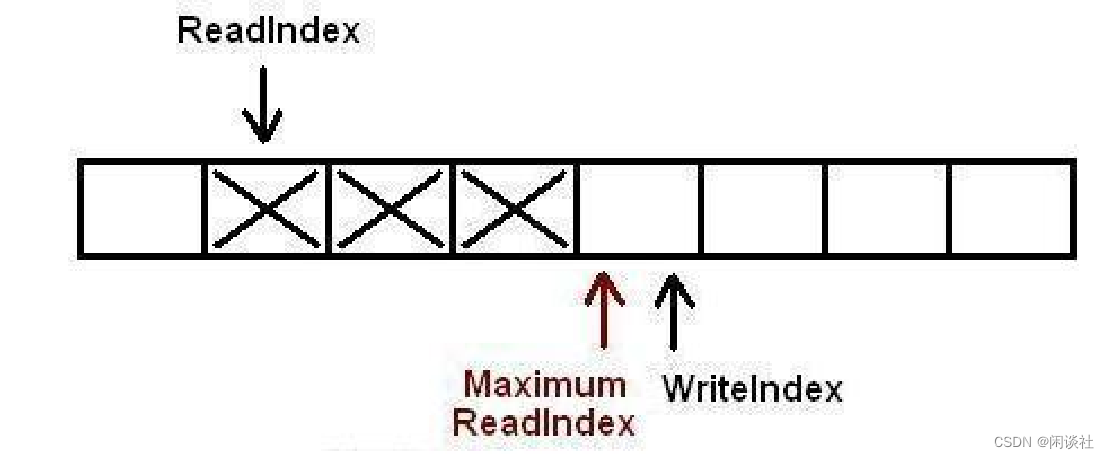
3)现在队列中有3个元素,接着又有一个生产者尝试向队列中插入元素。
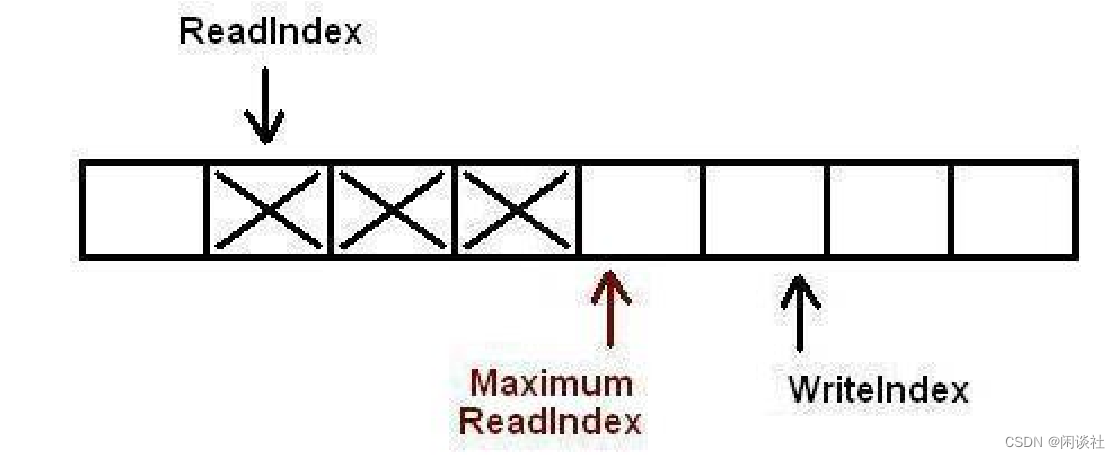
4)在第一个生产者完成数据拷贝之前,又有另外一个生产者申请了一个新的空间准备拷贝数据。现在有两个生产者同时向队列插入数据。

5)现在生产者开始拷贝数据,在完成拷贝之后,对MaximumReadIndex的递增操作必须严格遵循一个顺序:第一个生产者线程首先递增MaximumReadIndex,接着才轮到第二个生产者。这个顺序必须被严格遵守的原因是,我们必须保证数据被完全拷贝到队列之后才允许消费者线程将其出列。
while(!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1)))
{
sched_yield(); // cas 更新失败后,让出 cpu
}
让出cpu的目的也是为了让排在最前面的生产者完成m_maximumReadIndex的更新)
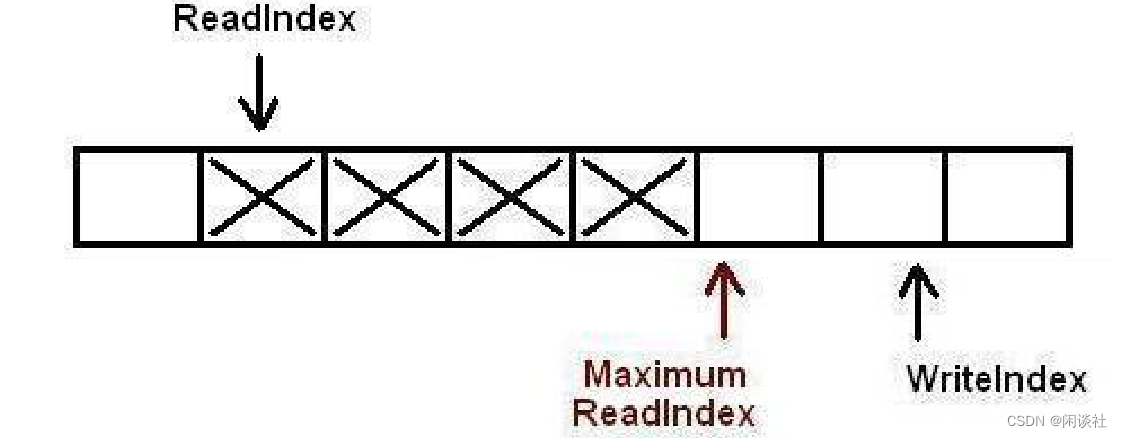
6)第一个生产者完成了数据拷贝,并对MaximumReadIndex完成了递增,现在第二个生产者可以递增
MaximumReadIndex了。
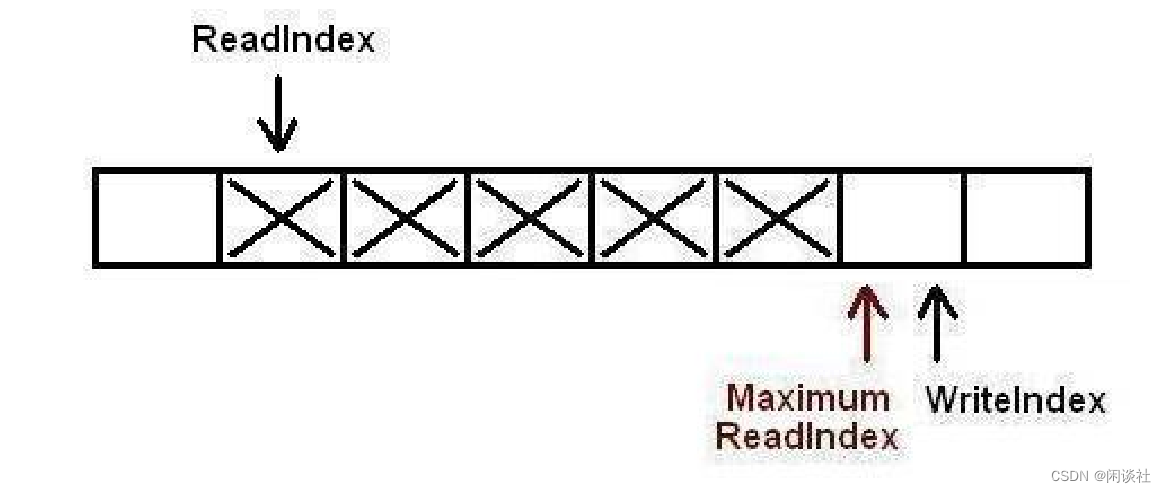
7)第二个生产者完成了对MaximumReadIndex的递增,现在队列中有5个元素。
在多于一个生产者线程的情况下,sched_yield() 操作将 cpu 让给其他线程是很有必要的。
无锁算法和通过阻塞机制同步的算法的一个主要区别在于无锁算法不会阻塞在线程同步上。多线程环境下,多生产者线程向并发的往队列中存放数据,每个生产者线程所执行的 cas 操作都必须严格遵循 FIFO 次序,一个用于申请空间,另一个用于通知消费者数据已经写入完成可以被读取了。
如果我们的应用程序只有唯一的生产者操作这个队列,sche_yield()将永远没有机会被调用,第2个CAS操作永远不会失败。因为在一个生产者的情况下没有人能破坏生产者执行这两个CAS操作的FIFO顺序。而当多于一个生产者线程往队列中存放数据的时候,问题就出现了。
例如第一个 cas 操作的执行顺序是线程1,2,3,第二个 cas 操作的执行顺序也必须是线程1,2,3。若线程1执行第二个 cas 操作的时候被抢占,那么线程2,3只能在 cpu 上忙等(它们忙等,不让出处理器,线程1也就没机会执行,它们就只能继续忙等)。而这就是问题产生的根源。
这就是需要sche_yield()所,应当尽快让出 cpu,让线程1先执行。这样线程2和3才能继续完成它们的操作。
template <typename ELEM_T, QUEUE_INT Q_SIZE>
bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::enqueue(const ELEM_T &a_data)
{
QUEUE_INT currentWriteIndex;
QUEUE_INT currentReadIndex;
// 1、获取可写入的位置(CAS)
do
{
// 获取当前读写指针的位置
currentWriteIndex = m_writeIndex;
currentReadIndex = m_readIndex;
// 判断队列是否满了,(write + 1) % Q_SIZE == read
if(countToIndex(currentWriteIndex + 1) ==
countToIndex(currentReadIndex))
{
return false;
}
// 获取可写入的位置(CAS),cas 更新失败则继续循环
} while(!CAS(&m_writeIndex, currentWriteIndex, (currentWriteIndex+1)));
// 2、写入数据
m_thequeue[countToIndex(currentWriteIndex)] = a_data;
// 3、更新可读的位置(CAS),多线程环境下生产者线程按序更新可读位置
while(!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1)))
{
sched_yield(); // cas 更新失败后,让出 cpu
}
// 原子操作;队列中元素数量+1
AtomicAdd(&m_count, 1);
return true;
}
3.3 dequeue出队列
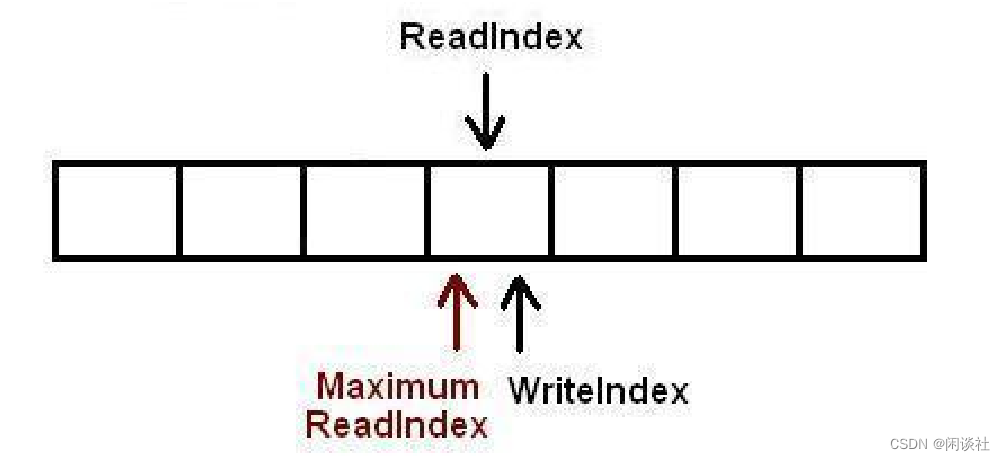
以下插图展示了元素出列的时候各种下标是如何变化的,队列中初始有2个元素。WriteIndex指示的位置是新元素将会被插入的位置。ReadIndex指向的位置中的元素将会在下一次pop操作中被弹出。

1)消费者线程拷贝数组ReadIndex位置的元素,然后尝试用CAS操作将ReadIndex加1。如果操作成功消费者成功的将数据出列。因为CAS操作是原子的,所以只有唯一的线程可以在同一时刻更ReadIndex的值。如果操作失败,读取新的ReadIndex值,以重复以上操作(copy数据,CAS)。

2)现在又有一个消费者将元素出列,队列变成空。
3)现在有一个生产者正在向队列中添加元素。它已经成功的申请了空间,但尚未完成数据拷贝。任何其它企图从队列中移除元素的消费者都会发现队列非空(因为writeIndex不等于readIndex)。但它不能读取readIndex所指向位置中的数据,因为readIndex与MaximumReadIndex相等。消费者将会在do循环中不断的反复尝试,直到生产者完成数据拷贝增加MaximumReadIndex的值,或者队列变成空(这在多个消费者的场景下会发生)。
4)当生产者完成数据拷贝,队列的大小是1,消费者线程可以读取这个数据了.
emplate <typename ELEM_T, QUEUE_INT Q_SIZE>
bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::dequeue(ELEM_T &a_data)
{
QUEUE_INT currentMaximumReadIndex;
QUEUE_INT currentReadIndex;
do
{
// 获取当前可读位置[m_readIndex, m_maximumReadIndex)
currentReadIndex = m_readIndex;
currentMaximumReadIndex = m_maximumReadIndex;
// 若队列为空,返回 false
if(countToIndex(currentReadIndex) ==
countToIndex(currentMaximumReadIndex))
{
return false;
}
// 读取数据
a_data = m_thequeue[countToIndex(currentReadIndex)];
// 更新可读的位置(CAS)
if(CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1)))
{
AtomicSub(&m_count, 1); // 原子操作,元素-1
return true;
}
} while(true);
assert(0);
return false;
}
3.4 源码
// ArrayLockFreeQueue.h
#ifndef _ARRAYLOCKFREEQUEUE_H___
#define _ARRAYLOCKFREEQUEUE_H___
#include <stdint.h>
#ifdef _WIN64
#define QUEUE_INT int64_t
#else
#define QUEUE_INT unsigned long
#endif
#define ARRAY_LOCK_FREE_Q_DEFAULT_SIZE 65535
template <typename ELEM_T, QUEUE_INT Q_SIZE = ARRAY_LOCK_FREE_Q_DEFAULT_SIZE>
class ArrayLockFreeQueue
{
public:
ArrayLockFreeQueue();
virtual ~ArrayLockFreeQueue();
QUEUE_INT size();
bool enqueue(const ELEM_T &a_data);
bool dequeue(ELEM_T &a_data);
bool try_dequeue(ELEM_T &a_data);
private:
ELEM_T m_thequeue[Q_SIZE];
volatile QUEUE_INT m_count;
volatile QUEUE_INT m_writeIndex;
volatile QUEUE_INT m_readIndex;
volatile QUEUE_INT m_maximumReadIndex;
inline QUEUE_INT countToIndex(QUEUE_INT a_count);
};
#include "ArrayLockFreeQueueImp.h"
#endif
// ArrayLockFreeQueueImp.h
#ifndef _ARRAYLOCKFREEQUEUEIMP_H___
#define _ARRAYLOCKFREEQUEUEIMP_H___
#include "ArrayLockFreeQueue.h"
#include <assert.h>
#include "atom_opt.h"
template <typename ELEM_T, QUEUE_INT Q_SIZE>
ArrayLockFreeQueue<ELEM_T, Q_SIZE>::ArrayLockFreeQueue() :
m_writeIndex(0),
m_readIndex(0),
m_maximumReadIndex(0)
{
m_count = 0;
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
ArrayLockFreeQueue<ELEM_T, Q_SIZE>::~ArrayLockFreeQueue()
{}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
inline QUEUE_INT ArrayLockFreeQueue<ELEM_T, Q_SIZE>::countToIndex(QUEUE_INT a_count)
{
return (a_count % Q_SIZE);
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
QUEUE_INT ArrayLockFreeQueue<ELEM_T, Q_SIZE>::size()
{
QUEUE_INT currentWriteIndex = m_writeIndex;
QUEUE_INT currentReadIndex = m_readIndex;
if(currentWriteIndex>=currentReadIndex)
return currentWriteIndex - currentReadIndex;
else
return Q_SIZE + currentWriteIndex - currentReadIndex;
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::enqueue(const ELEM_T &a_data)
{
QUEUE_INT currentWriteIndex;
QUEUE_INT currentReadIndex;
do
{
currentWriteIndex = m_writeIndex;
currentReadIndex = m_readIndex;
if(countToIndex(currentWriteIndex + 1) ==
countToIndex(currentReadIndex))
{
return false;
}
} while(!CAS(&m_writeIndex, currentWriteIndex, (currentWriteIndex+1)));
m_thequeue[countToIndex(currentWriteIndex)] = a_data;
while(!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1)))
{
sched_yield();
}
AtomicAdd(&m_count, 1);
return true;
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::try_dequeue(ELEM_T &a_data)
{
return dequeue(a_data);
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::dequeue(ELEM_T &a_data)
{
QUEUE_INT currentMaximumReadIndex;
QUEUE_INT currentReadIndex;
do
{
currentReadIndex = m_readIndex;
currentMaximumReadIndex = m_maximumReadIndex;
if(countToIndex(currentReadIndex) ==
countToIndex(currentMaximumReadIndex))
{
return false;
}
a_data = m_thequeue[countToIndex(currentReadIndex)];
if(CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1)))
{
AtomicSub(&m_count, 1); // 真正读取到了数据,元素-1
}
} while(true);
assert(0);
return false;
}
#endif
四、测试结果

1、对于耗时短的任务
- 无锁队列有明显的优势。
- 线程不是越多越好。因为线程切换开销也不小。
2、对于耗时大的任务
- 无锁队列优势不明显,甚至略弱于有锁
- 可以适当增加线程,有助于效率提升
五、结论
对于耗时比较短的任务,无锁队列通常能够提供更好的性能,原因如下:
-
减少锁开销:无锁队列通过使用原子操作等技术来实现线程安全,避免了显式的锁操作。相比之下,有锁队列需要在进入和离开临界区时获取和释放锁,这涉及到较多的上下文切换和系统调用,造成额外的开销。在任务耗时短的情况下,这些开销会占据较大的比例,从而影响性能。
-
高并发性:无锁队列的设计通常能够支持更高的并发性,因为多个线程可以同时访问和修改队列,而无需互斥地获取锁。这样可以减少竞争和调度开销,提高整体的并行度和吞吐量。对于耗时短的任务,这种高并发性能够更好地利用系统资源,实现更高的性能。
然而,对于耗时比较长的任务,无锁队列可能不如有锁队列的原因主要包括以下几点:
-
内存和处理器开销:无锁队列通常需要通过原子操作等技术来保证线程安全,这可能增加了额外的内存访问和处理器指令。而耗时较长的任务会使得这些开销相对不那么显著,反而增加了系统的负担。
-
数据一致性:无锁队列的设计通常较为复杂,需要保证数据的一致性和正确性。在耗时较长的任务中,多线程并发访问和修改数据的机会增加,这可能导致更多的数据竞争和冲突,进而增加了数据一致性的难度和复杂性。
总结下来就是:
- 能用有锁队列的尽量使用有锁队列
- 什么时候使用无锁队列,满足以下的条件可考虑无锁队列(注意是可考虑):
○ 所处理的任务没有阻塞,纯cpu密集型; (如果有mysql数据库操作,有redis操作就没有必要)
○ 每秒处理的任务超过百万条(ops > 100万);
○ 生产者不存在io阻塞 (每秒产生任务 1万多也没有必要, 如果有锁队列影响io的吞吐量也可以使
用无锁)。
○ 生产者最好和消费者是1:1对应关系,不要出现 多写1读的情况。







![NSS [NSSRound#7 Team]ec_RCE](https://img-blog.csdnimg.cn/img_convert/b9222844f88799ad5e9a5cf5dda55ded.png)