1.前言
logstash是一个相对较重的日志收集器,可以通过多种方式获取到日志数据,如tcp、日志文件、kafka、redis、rabbitmq等方式,还可以使用filter去过滤日志、转换日志为json格式,所以logstash是一个功能强大的日志收集器,logstash日志的收集都是通过配置文件去控制,所以需要更改收集方式,就更改配置文件,在重新使用新的配置文件启动即可
2.实践
通过tcp端口获取日志
可以用于收集微服务日志,微服务调用logstash日志框架直接将日志发送到logstash配置的端口中,logstash可以使用filter过滤需要的日志内容,也可以不过滤,若日志不是json格式,也可以通过filter去将日志做成json格式,在发送到elasticsearch中
vi /opt/logstash/logstash/config/logstash.conf
input {
tcp {
port => 5044 #接收日志的监听端口
codec => "json" #将输入的json日志结构化,输入的是json日志才需要配置此项,不是json日志配置此项可能会报错导致数据丢失
}
}
filter { #配置过滤日志,或者将日志配置为json日志
}
output {
# stdout{ #测试使用的功能,将数据输出到当前页面
# codec => rubydebug #将输出的数据写入到logstash日志中
# }
elasticsearch { #将数据输出到es中
hosts => ["http://10.1.60.114:9200","http://10.1.60.115:9200","http://10.1.60.118:9200"] #eslasticsearch集群地址
index => "java-log-%{+YYYY.MM.dd}" #eslasticsearch的索引名称,以时间的变量结尾,这样就会每天自动创建新的索引分割日志,默认是一主分片一副本分片,将数据写入到分片中,当eslasticsearch是单节点模式时,副本分片将不会被分配,索引状态显示yellow
}
}通过日志文件获取日志方式
此方式可以用于生成日志文件的应用收集日志,jar包、nginx等等应用,若是本来就是json格式的日志可以不用使用filter更改日志格式,直接输出到elasticsearch中,以下两个grok的内容分别是nginx access、nginx error日志的json模板,对于模板内容的解释会专门写一篇关于grok的
grok使用参考:grok使用(将日志结构化)_Apex Predator的博客-CSDN博客
vi /opt/logstash/logstash/config/logstash.conf
input {
file {
path => "/var/log/nginx/access.log" #日志文件路径
type => "nginx-access" #再有多个输入的情况下可以通过type去区分
}
file {
path => "/var/log/nginx/error.log" #日志文件路径
type => "nginx-error"
}
}
filter {
if [type] == "nginx-access" { #判断是哪一个日志
grok { #使用grok将日志重新做成json格式
match => { #nginx access日志的json格式模板,可以直接复制使用,不能确保完全匹配,还是需要根据自己的日志情况去更改模板
"message" => "%{IP:ip} - (%{USERNAME:remote_user}|-) \[%{HTTPDATE:timestamp}\] \"%{WORD:request_method} %{URIPATHPARAM:request_url} HTTP/%{NUMBER:http_version}\" %{NUMBER:http_status} %{NUMBER:bytes} \"(%{DATA:referrer}|-)\" \"%{DATA:http_agent}\" \"(%{DATA:forwarded}|-)\""
}
}
}
else if [type] == "nginx-error" {
grok {
match => { #nginx error日志的json格式模板,可以直接复制使用,不能确保完全匹配,还是需要根据自己的日志情况去更改模板
"message" => "%{DATA:timestamp} \[%{WORD:severity}\] %{NUMBER:pid}#%{NUMBER:tid}: %{GREEDYDATA:prompt}"
}
}
}
}
output { #数据输出端
# stdout{
# codec => rubydebug
# }
elasticsearch {
hosts => ["http://10.1.60.114:9200","http://10.1.60.115:9200","http://10.1.60.118:9200"]
index => "%{[type]}-%{+YYYY.MM.dd}" #直接引用type字段创建索引,然后以时间结尾,这样的话每天都会自动分割日志了,还可以自动分配数据到合适的索引上
}
}通过filebeat获取日志
通过部署filebeat在每台需要收集日志的主机上,收集日志后统一传输到logstash中,logstash在input中配置监听端口去获取filebeat传输过来的日志
input {
beats { #配置为beats,供filebeat调用
port => 5044 #配置监听端口,用于接收filebeat传输过来的日志
codec => "json" #如果传输过来的是json格式日志则需要此项配置,否则就删掉此项配置
}
}
#若是收集得日志不是json格式,则通过以下filter配置为json格式,如果是json格式则不用要以下filter配置
filter {
if [fields][log_type] == "nginx-access-log" {
grok {
match => {
"message" => "%{IP:ip} - (%{USERNAME:remote_user}|-) \[%{HTTPDATE:timestamp}\] \"%{WORD:request_method} %{URIPATHPARAM:request_url} HTTP/%{NUMBER:http_version}\" %{NUMBER:http_status} %{NUMBER:bytes} \"(%{DATA:referrer}|-)\" \"%{GREEDYDATA:agent}\" \"(%{DATA:forwarded}|-)\""
}
}
}
else if [fields][log_type] == "nginx-error-log" {
grok {
match => {
"message" => "%{DATA:timestamp} \[%{WORD:severity}\] %{NUMBER:pid}#%{NUMBER:tid}: %{GREEDYDATA:prompt}"
}
}
}
}
output {
# stdout{
# codec => rubydebug
# }
elasticsearch {
hosts => ["http://10.1.60.114:9200","http://10.1.60.115:9200","http://10.1.60.118:9200"]
index => "%{[fields][log_type]}-%{+YYYY.MM.dd}"
}
}通过kafka获取日志方式
通过消息队列获取日志,通常需要和filebeat轻量级日志收集器搭配使用,filebeat将日志消息写入到消息队列中,logstash在input中去kafka的主题中获取日志信息,在通过filter将日志变成json格式,在输入到elasticsearch中
vi /opt/logstash/logstash/config/logstash.conf
input {
kafka { #配置为从kafka获取数据
bootstrap_servers => "10.1.60.112:9092,10.1.60.114:9092,10.1.60.115:9092" #kafka集群地址
client_id => "nginx" #消费者id
group_id => "nginx" #消费者组id,避免重复消费的关键
auto_offset_reset => "latest" #偏移量,设置latest为使用主题中最新的偏移量,避免重复消费,即使logstash宕机恢复后,也会消费完宕机的时间段产生的数据
consumer_threads => 1 #消费者线程1
decorate_events => true
topics => ["nginx-access-log","nginx-error-log"] #数据存放的主题
codec => json #将kafka的json数据结构化,这样的话在通过kibana展示的时候就可以通过字段查找数据
}
}
filter {
if [fields][topic] == "nginx-access-log" { #此处也是通过topic的变量去辨别是哪个主题,不过此处的变量参数和output中的topic变量有点区别
grok {
match => {
"message" => "%{IP:ip} - (%{USERNAME:remote_user}|-) \[%{HTTPDATE:timestamp}\] \"%{WORD:request_method} %{URIPATHPARAM:request_url} HTTP/%{NUMBER:http_version}\" %{NUMBER:http_status} %{NUMBER:bytes} \"(%{DATA:referrer}|-)\" \"%{DATA:http_agent}\" \"(%{DATA:forwarded}|-)\""
}
}
}
else if [fields][topic] == "nginx-error-log" {
grok {
match => {
"message" => "%{DATA:timestamp} \[%{WORD:severity}\] %{NUMBER:pid}#%{NUMBER:tid}: %{GREEDYDATA:prompt}"
}
}
}
}
output {
# stdout{
# codec => rubydebug
# }
elasticsearch {
hosts => ["http://10.1.60.114:9200","http://10.1.60.115:9200","http://10.1.60.118:9200"]
index => "%{[@metadata][kafka][topic]}-%{+YYYY.MM.dd}" #通过topic和时间的变量去分别设置索引名称
}
} 以上是logstash收集日志的其中三种方式,配置收集的时候可以参考
3.json格式日志收集展示
更改nginx配置文件,将日志改为json格式日志
vi /etc/nginx/nginx.conf
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
#上面部分是nginx默认的输出日志格式,包括参数
#下面部分是按照原日志中的参数,改为json格式
log_format log_json '{ "time_local": "$time_local", '
'"remote_addr": "$remote_addr", '
'"referer": "$http_referer", '
'"request": "$request", '
'"status": $status, '
'"bytes": $body_bytes_sent, '
'"agent": "$http_user_agent", '
'"x_forwarded": "$http_x_forwarded_for", '
'"up_addr": "$upstream_addr", '
'"up_host": "$upstream_http_host", '
'"up_resp_time": "$upstream_response_time", '
'"request_time": "$request_time" }';
#此处也需要将nginx日志引用到输出的日志文件中
access_log /var/log/nginx/access.log log_json;
优雅重载nginx配置
ngins -s reload
通过http去访问一下nginx的80端口,查看一下日志
curl 10.1.60.115
tail -f /var/log/nginx/access.log

可以对比一下上下两条日志,上一条是nginx默认的日志格式,在logstash中需要通过filter去更改为json格式,而下面一条是直接在nginx配置文件就修改nginx的日志格式为json格式,主要是如果不改json格式,在kibana中就没法通过字段去查询需要的内容,展示的日志内容就是一长串的日志,根据以上配置我们输出到eslasticsearch看一下,额外再多收集一个默认格式error报错日志作为对比
我们就是用从file收集日志的logstash配置
vi /opt/logstash/logstash/config/logstash.conf
input {
file {
path => "/var/log/nginx/access.log"
type => "nginx-access"
codec => "json"
}
file {
path => "/var/log/nginx/error.log"
type => "nginx-error"
}
}
filter {
}
output {
# stdout{
# codec => rubydebug
# }
elasticsearch {
hosts => ["http://10.1.60.114:9200","http://10.1.60.115:9200","http://10.1.60.118:9200"]
index => "%{[type]}-%{+YYYY.MM.dd}"
}
}以上output配置中,可以先禁用输出到elasticsearch中,启用stdout配置项输出到日志中查看一下日志是否配置正确,使用该配置文件启动logstash服务
nohup /opt/logstash/logstash/bin/logstash -f /opt/logstash/logstash/config/logstash.conf > /opt/logstash/logstash/logstash.log &
先访问nginx的80端口,让nginx写入日志数据
curl 10.1.60.115
查看logstash的日志,看输出的日志数据格式是否正确
tail -f /opt/logstash/logstash/logstash.log

可以看到能正常获取到正确的日志数据格式
此时需要将logstash配置文件中的stdout配置注释,将elasticsearch取消注释,再次重启logstash服务即可,重启的话先kill掉正在运行的logstash服务,在启动新的logstash服务,然后再次访问nginx去产生日志,查看kibana输出
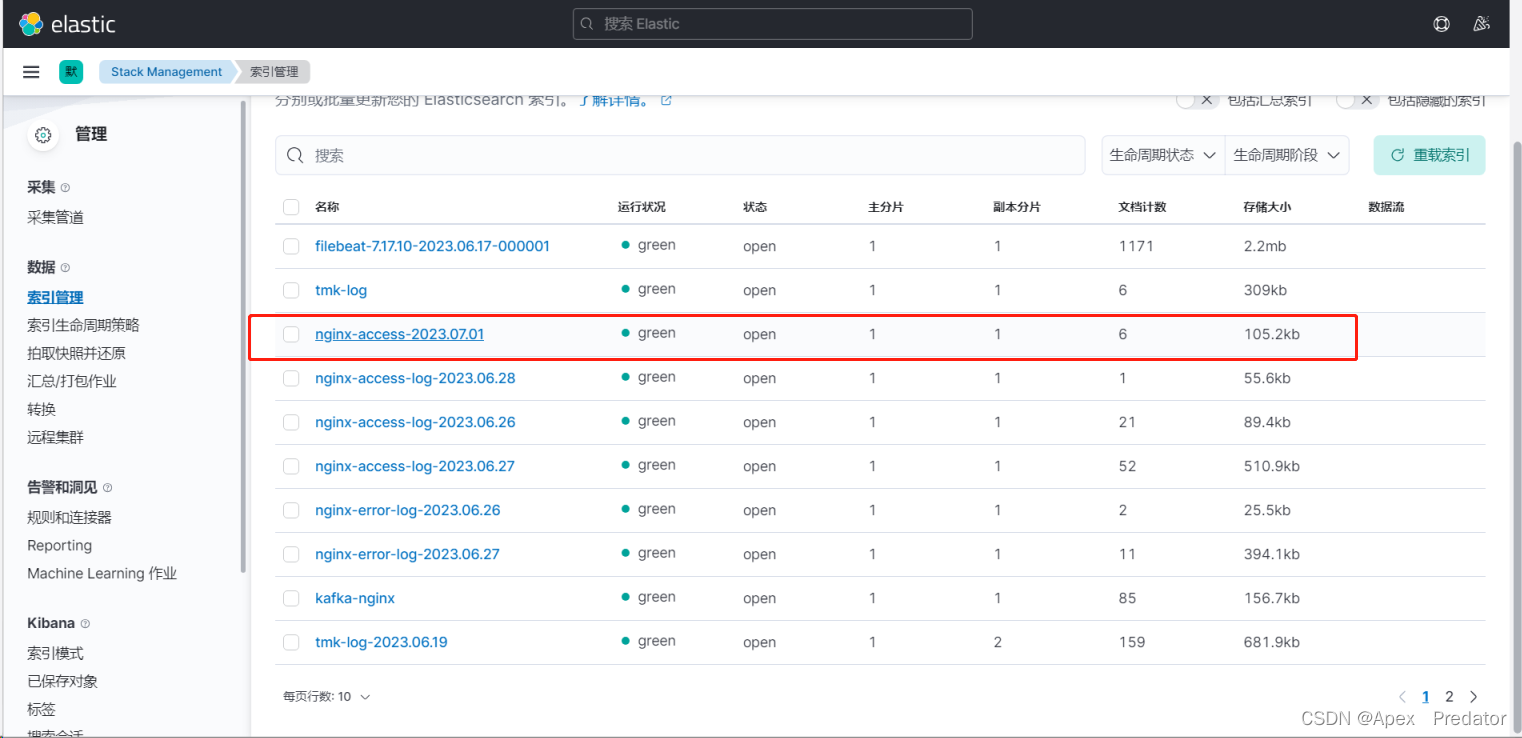
可以看到nginx生成访问日志后,elasticsearch 也自动创建了符合配置规则的索引,并将日志写入,查看一下日志数据
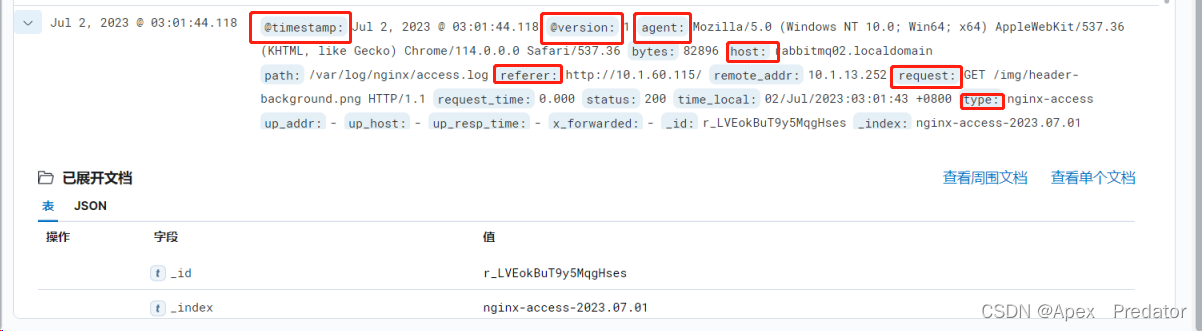
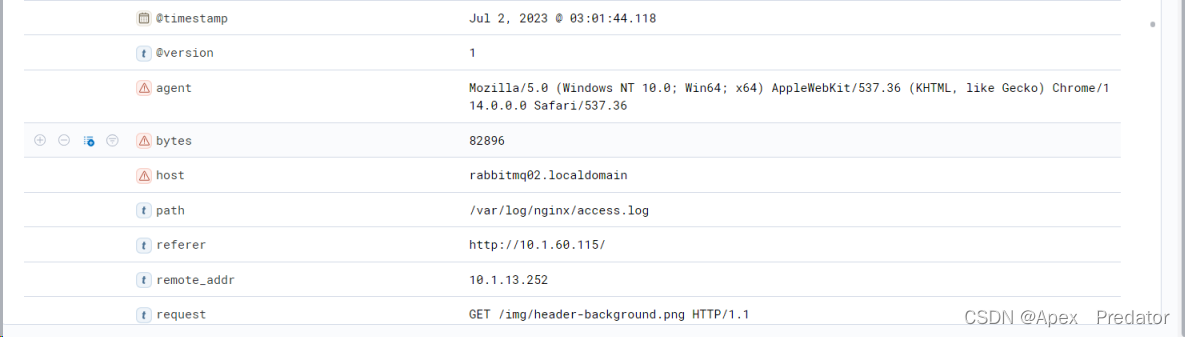
可以看到蓝色标签的都是json日志的字段,并且都包含了nginx日志配置的字段,kibana可以通过字段搜索到想要的内容
接下再来生成一下没有json格式的nginx error日志看看效果
先更改nginx的配置文件,随便往里面写入一些字母,再优雅重载nginx配置文件,因为配置文件有问题,重载nginx配置会生成错误日志
vi /etc/nginx/nginx.conf
nginx -s reload
通过kibana看一下效果
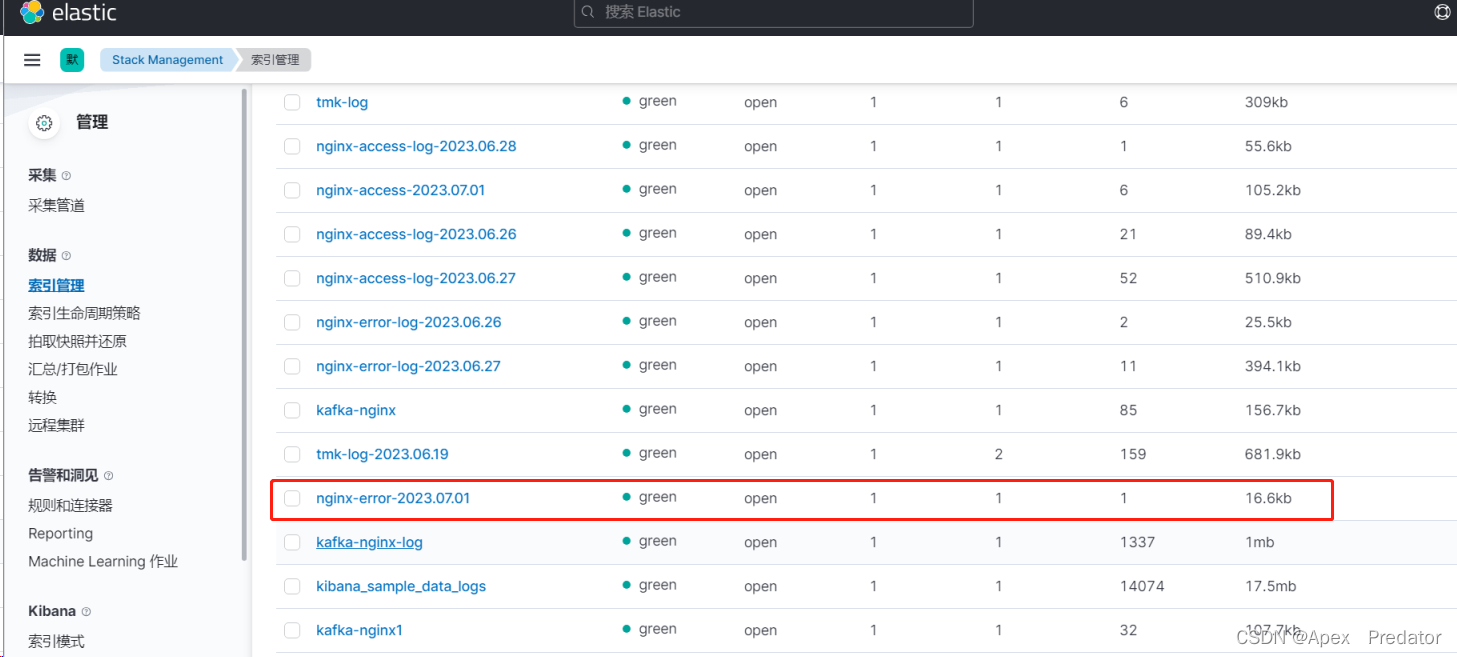
可以看到nginx生成报错日志后,elasticsearch 也自动创建了符合配置规则的索引,并将日志写入,查看一下日志数据


message字段就是nginx的error日志,因为日志不是json格式的原因,所以是没有字段的,只有一长条日志,若是需要将日志修改为json格式就需要用到logstash的filter去将日志更改为json格式







![[Visual Studio 报错] error 找不到指定的 SDK“Microsoft](https://img-blog.csdnimg.cn/img_convert/f453b0ee14720ffeb38cc9cf2febf1eb.png)