Go语言基础知识
一、准备工作
1.1下载安装Go
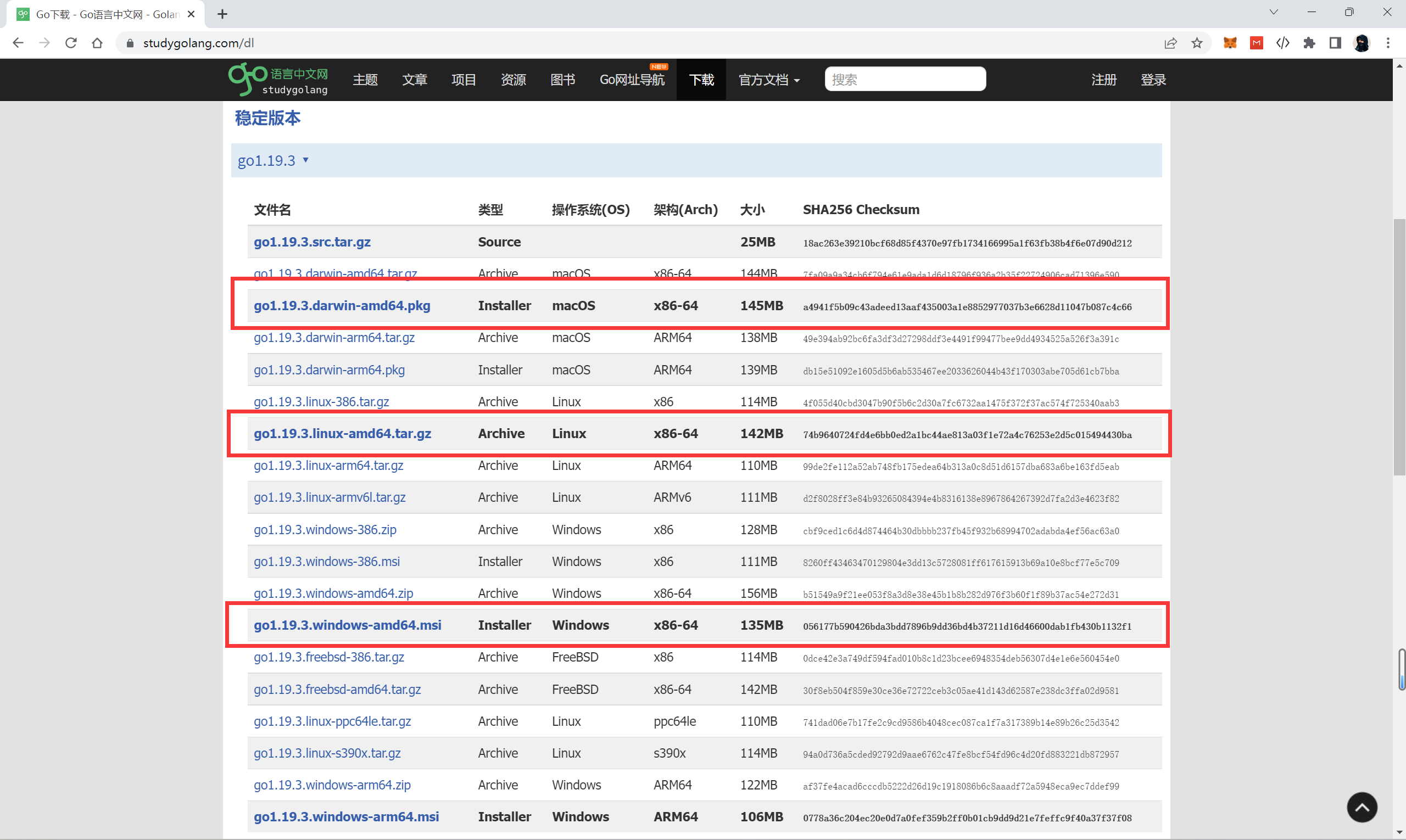
地址:https://studygolang.com/dl
1、根据系统来选择下载包
2、下载完成后直接双击运行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UPlbJuxF-1670464591346)(https://kevin-1311972042.cos.ap-chengdu.myqcloud.com/img/image-20221202164151509.png)]](https://img-blog.csdnimg.cn/5d1402cb996f46a68d53940e86cd28c3.png)
3、一路next,注意选择安装路径

4、在控制台窗口输入“go version”可查看Go版本,检测是否安装成功
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1Q0zMjEO-1670464591347)(https://kevin-1311972042.cos.ap-chengdu.myqcloud.com/img/image-20221202164611739.png)]](https://img-blog.csdnimg.cn/ad055bec76794975a7a28603310638af.png)
5、配置环境变量。Go需要一个安装目录,还需要一个工作目录,及GOROOT(安装目录)和GOPATH(保存工作路径的,将来所有的代码,包等都会放在GOPATH对应的路径下)
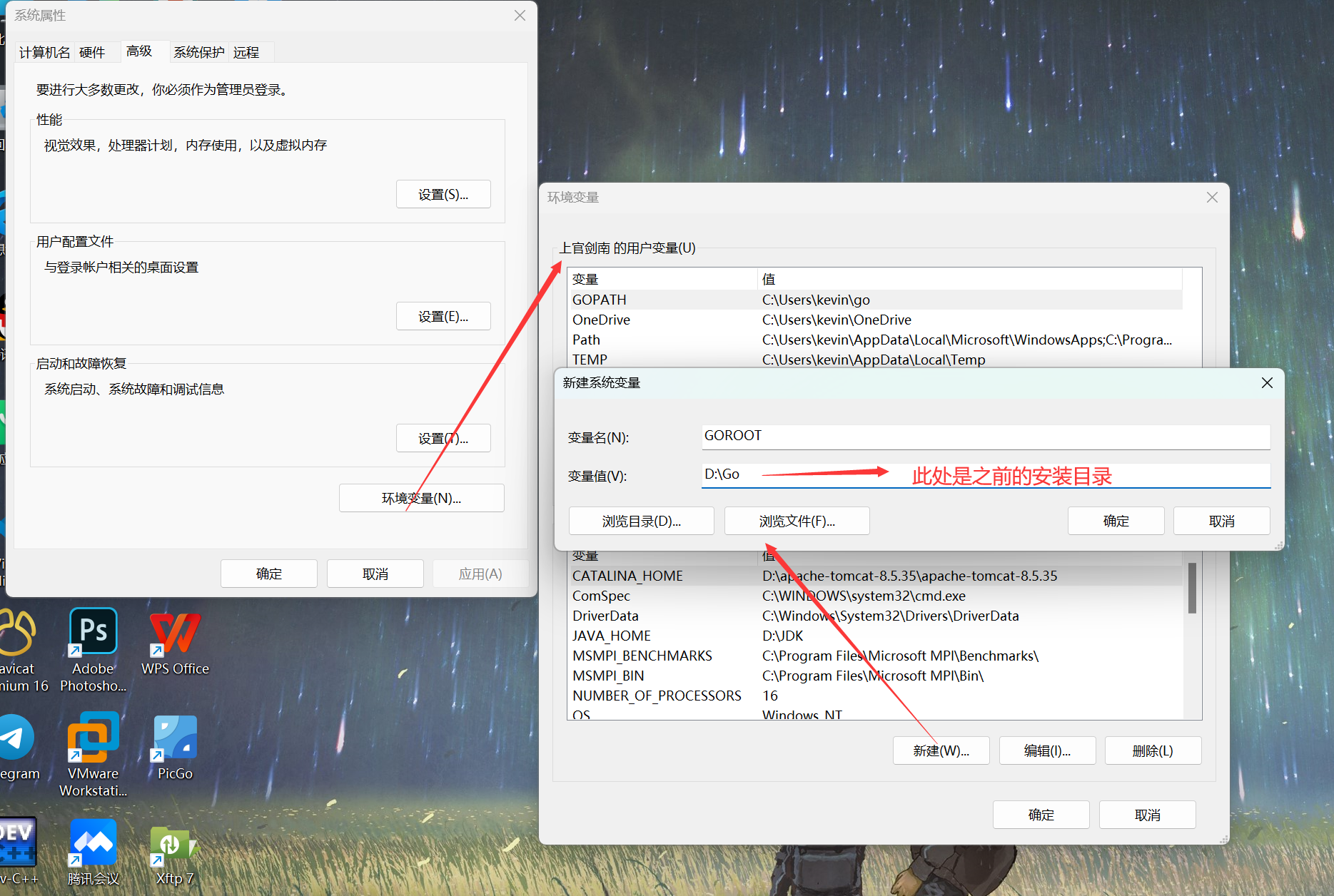
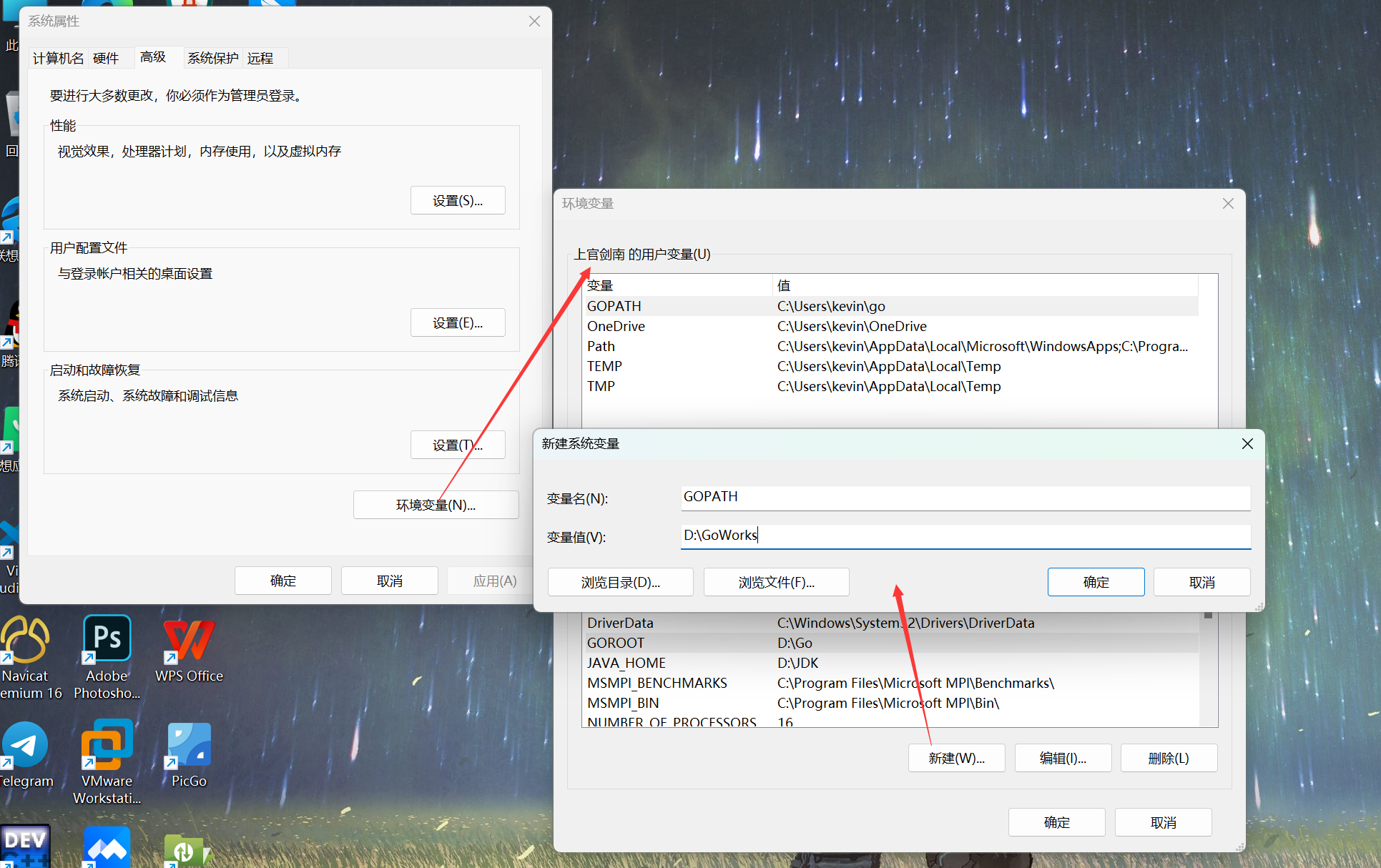
此处也需要改:
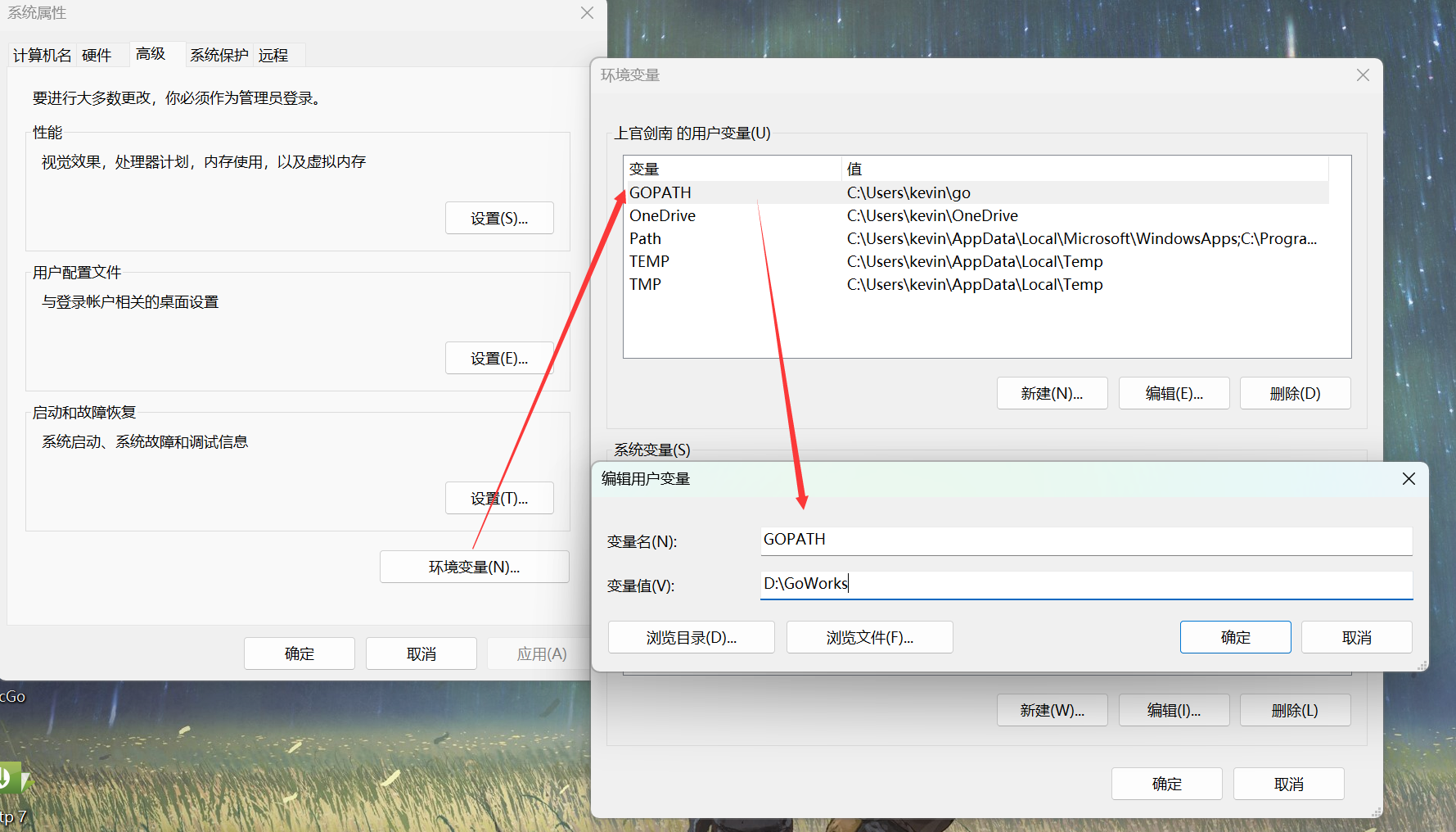
6、需要在GoWorks下新建三个包
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sJRVz3QX-1670465644613)(https://kevin-1311972042.cos.ap-chengdu.myqcloud.com/img/image-20221202165648936.png)]](https://img-blog.csdnimg.cn/dde59b7107e44cf9ac4152d9d36e2c80.png)
7、检查是否在PATH存在以下路径
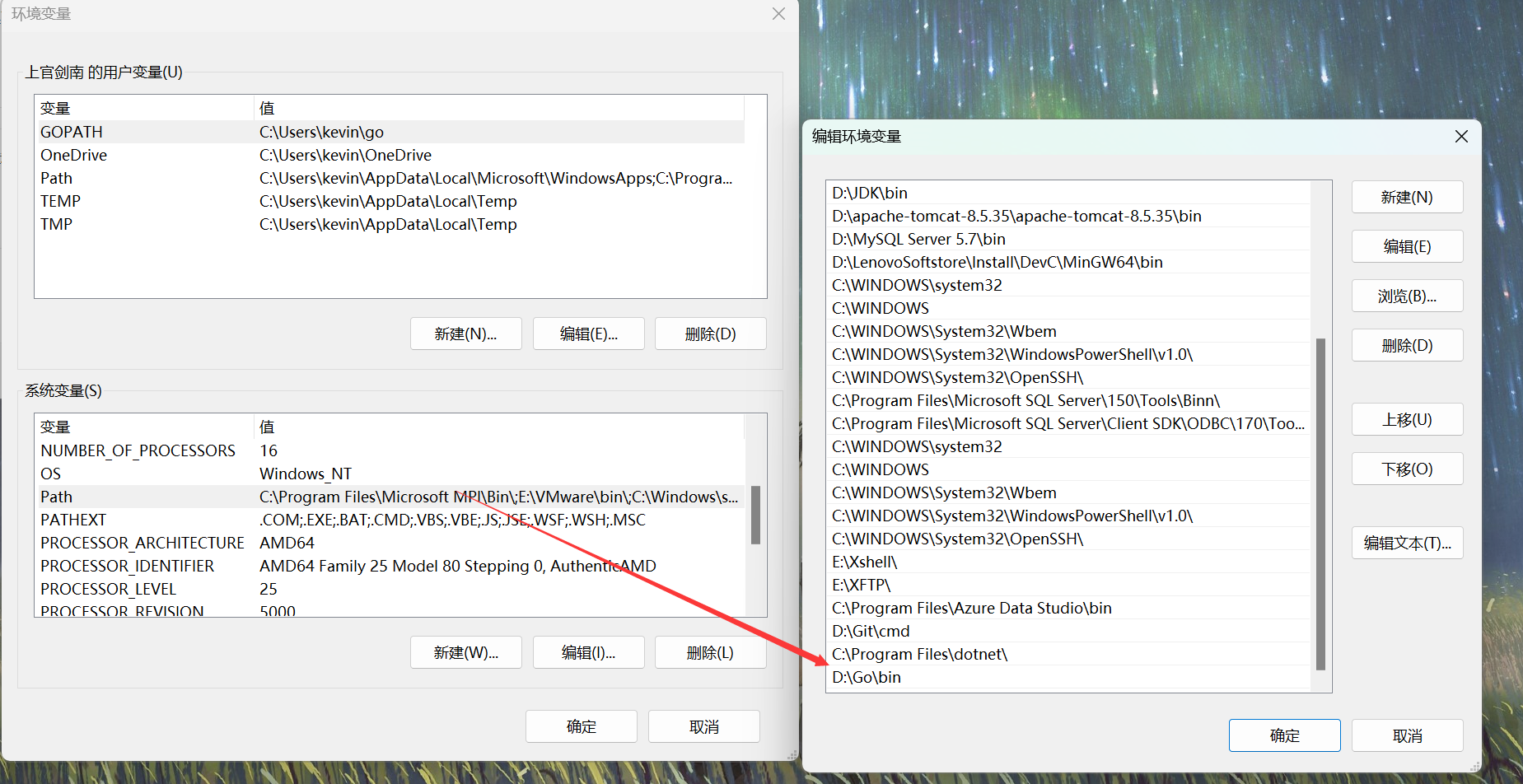
8、若存在,在控制台输入“go“命令,弹出以下内容即可
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9K2cLKlm-1670464591349)(https://kevin-1311972042.cos.ap-chengdu.myqcloud.com/img/image-20221202170056627.png)]](https://img-blog.csdnimg.cn/298582c72abe467e9391253aff39a2e7.png)
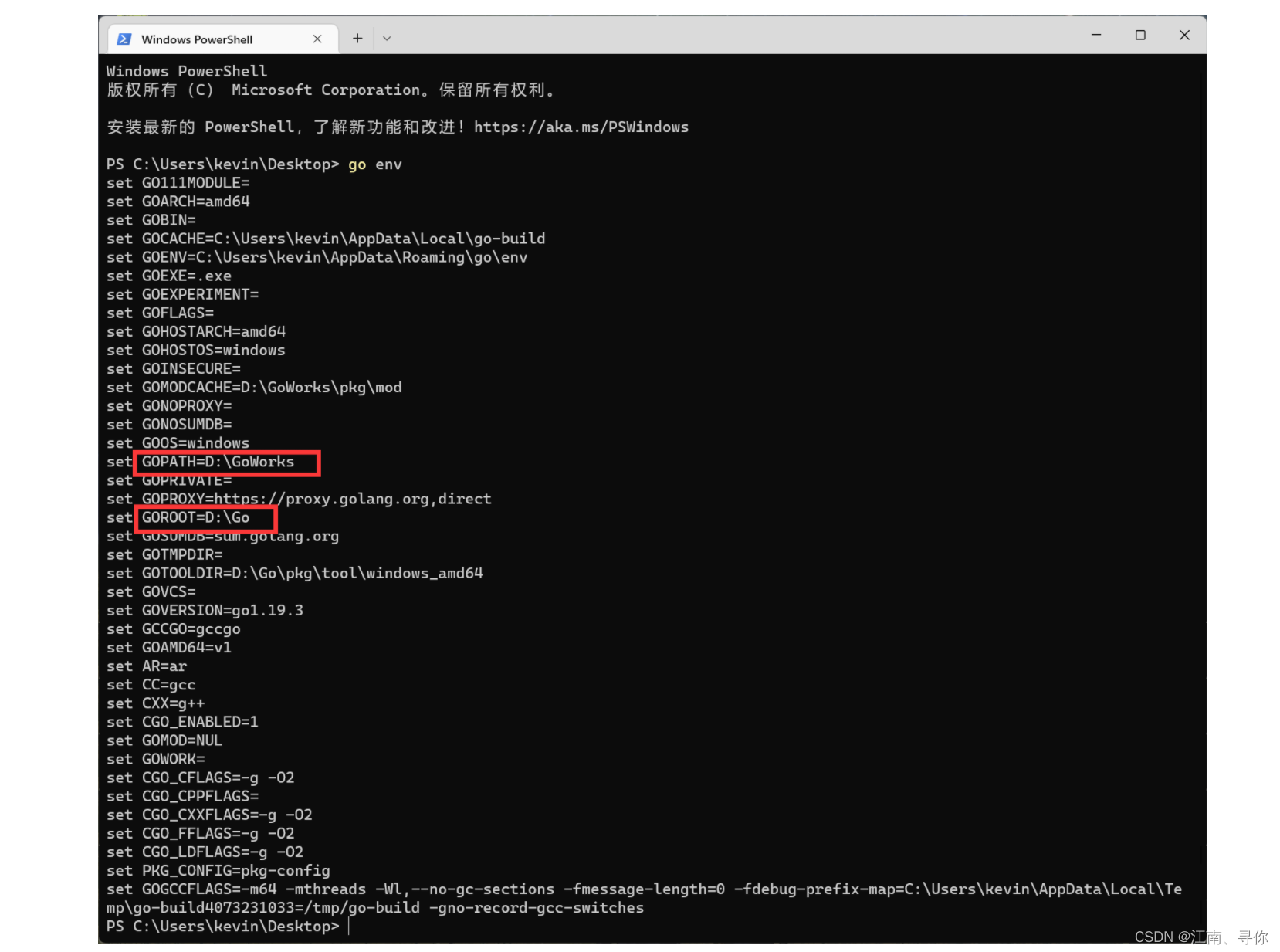
输入“go env”查看是否配置成功:
1.2下载开发工具GoLand
官网地址:https://www.jetbrains.com/go/
本人阿里云盘下载:
goland-2022.3.exe https://www.aliyundrive.com/s/PNVvvSWeS2W 点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速播放。
下载完成后,傻瓜式安装即可
破解链接:http://t.csdn.cn/uPEUU
1.3 Hello,World
记事本编写:hello.go
package main //代表main包,go语言中最重要的,最终你要打包成可执行的文件,就必须要放在main包下;一个程序中只能有一个main包
import "fmt" //导入一个系统包fmt用来输出语句
func main(){ //程序的主入口:main函数
fmt.Println("Hello World!") //打印输出 Hello World! 字符串
}
使用控制台执行hello.go
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i0amxyXl-1670464591354)(https://kevin-1311972042.cos.ap-chengdu.myqcloud.com/img/image-20221203141734395.png)]](https://img-blog.csdnimg.cn/6fece1b75c0147068690d376c806f23c.png)
使用GoLand输出
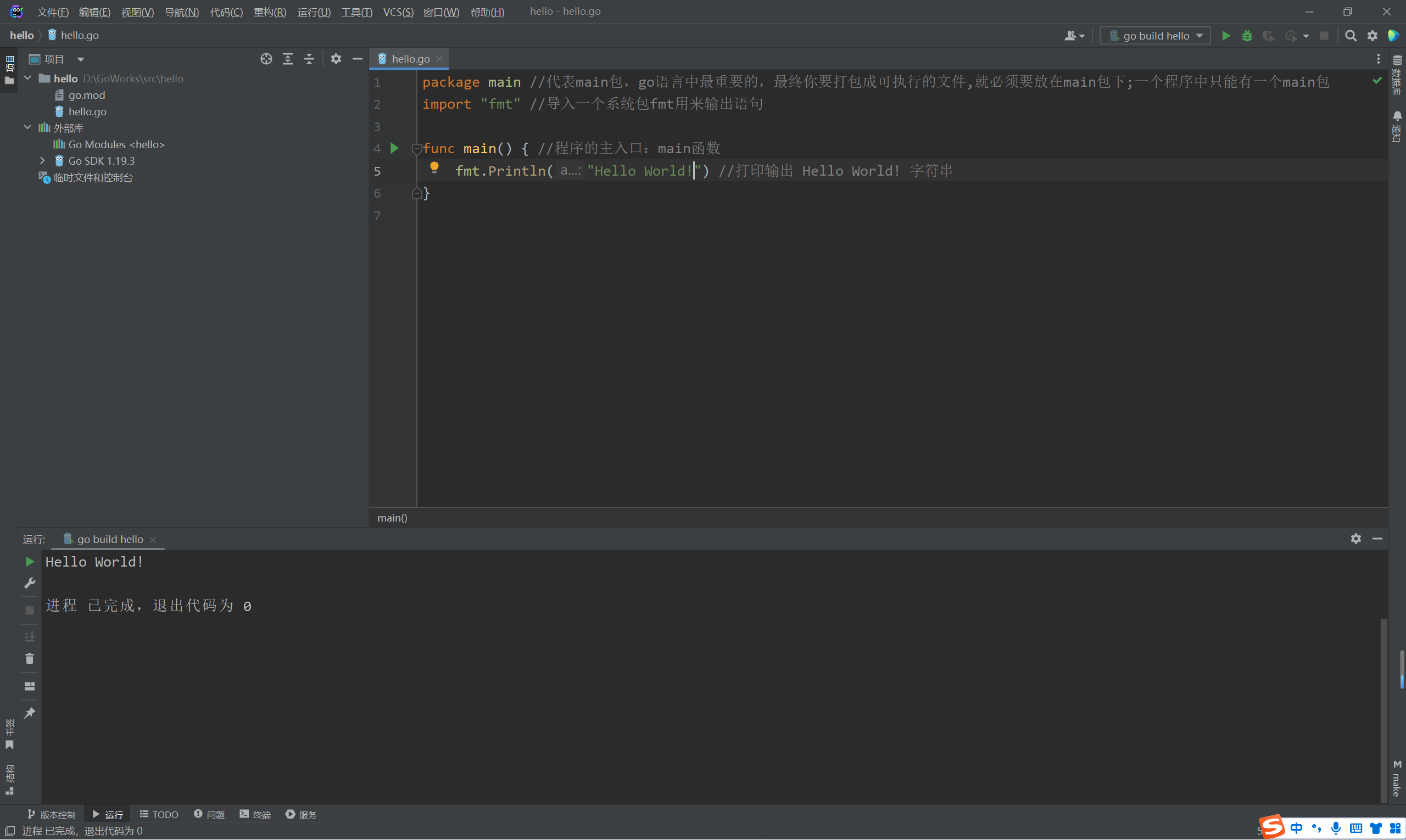
若输出不了,则在控制台执行如下命令
go env -w GO111MODULE=off
注意:GO111MODULE=off 这个代码中间不能有空格
将 GO111MODULE设置为off

二、基础语法学习
2.1 注释
单行注释
//我是单行注释
多行注释
/*我是多行注释*/
2.2 变量
2.2.1变量的定义
Go语言是静态类型语言,就是所有的类型我们都需要明确的去定义
在Go语言中,我们声明一个变量一般是使用var关键字,学过C#的朋友应该并不陌生,但是此处变量定义与C#又略有不同
变量声明以关键字 var 开头,后置变量类型,行尾无需分号
公式:var 变量名 变量类型 = 变量值
//var name type = value
//例如:
var name string = "xiaoshu"
如果你学过Java、C或者其他编程语言,第一次看到这样的操作肯定不舒服。Go语言和许多编程语言不同,它在声明变量时将变量的类型放在变量的名称之后。这样做的好处就是可以避免像C语言中那样含糊不清的声明形式,例如: int* a,b;。其中只有a是指针而b不是。如果你想要这两个变量都是指针,则需要将它们分开书写。而在Go中,则可以和轻松地将它们都声明为指针类型:
var a,b *int
变量的命名规则遵循骆驼命名法,即首个单词小写,每个新单词的首字母大写,例如: userFiles和systemInfo 。
我们有时候会批量定义变量,如果每次都单独定义比较麻烦,Go语言支持批量定义变量
使用关键字var和括号,可以将一组变量定义放在一起。
var (
address string
phone string
)
var形式的声明语句往往是用于需要显式指定变量类型地方,或者因为变量稍后会被重新赋值而初始值无关紧要的地方。
当一个变量被声明之后,如果没有显示的给他赋值,系统自动赋予它该类型的零值:
-
整型和浮点型变量的默认值为0和0.0
-
字符串变量的默认值为空字符串
-
布尔型变量默认是false
-
切片、函数、指针变量的默认值为nil
package main
import "fmt"
func main() {
//公式:var 变量名 变量类型 = 变量值
var name string = "xiaoshu"
var age int = 18
name = "小舒"
fmt.Println(name, age)
fmt.Println("======================")
//定义多个变量
var (
address string
id int
d float64
b bool
phone string
sex string = "男"
)
fmt.Println(b, id, phone, d, address)
fmt.Println(d)
fmt.Println(sex)
}
输出
小舒 18
======================
false 0 0
0
男
2.2.2 变量的初始化
普通初始化
package main
import "fmt"
func main() {
//定义多个变量
var (
address string
id int
d float64
b bool
phone string
sex string = "男"
)
address = "北京"
id = 1
d = 1.5
b = true
phone = "15919498888"
fmt.Println(b, id, phone, d, address)
fmt.Println(d)
fmt.Println(sex)
}
输出
true 1 15919498888 1.5 北京
1.5
男
短变量声明并初始化
//短变量声明并初始化
apple := "苹果"
vc := 1
fmt.Printf("name:%s vc:%d", apple, vc)
fmt.Println()
fmt.Printf("name:%T vc:%T", apple, vc) //推导变量类型
输出
name:苹果 vc:1
name:string vc:int
这是Go语言的推导声明写法,编译器会自动根据右值类型推断出左值的对应类型。它可以自动的推导出一些类型,但是使用也是有限制的;
- 定义变量,同时显式初始化。
- 不能提供数据类型。
- 只能用在函数内部。不能随便到处定义(关于函数,我们后面会讲解,听一下就好这里)
因为简洁和灵活的特点,简短变量声明被广泛用于大部分的局部变量的声明和初始化。
注意:由于使用了:=,而不是赋值的=,因此推导声明写法的左值变量必须是没有定义过的变量;若定义过,将会发生编译错误。
//例:
var apple string
apple := "苹果" //报错:no new variables on left side of :=
2.2.3 理解变量的内存地址
package main
import "fmt"
func main() {
var num int
num = 1000
//%d:打印数字类型
//%s:打印字符串类型
//%p:打印内存地址
//&num:&变量名,取出对应变量的内存地址
//\n:表示换行 \t:制表符
fmt.Printf("num:%d\t内存地址:%p\n", num, &num)
num = 1
fmt.Printf("num:%d\t内存地址:%p", num, &num)
}
输出
num:1000 内存地址:0xc0000160c8
num:1 内存地址:0xc0000160c8
2.2.4 变量的交换
package main
import "fmt"
// 变量交换
func main() {
//a = 100
//b = 200
//temp = 0
//1、temp = a
//2、a = b
//3、b = temp
//go 语言的变量交换
var a int = 100
var b int = 200
a, b = b, a
fmt.Println(a, b)
}
输出
200 100
2.2.5 匿名变量
匿名变量的特点是一个下画线"_",“"本身就是一个特殊的标识符,被称为空白标识符。它可以像其他标识符那样用于变量的声明或赋值(任何类型都可以赋值给它),但任何赋给这个标识符的值都将被抛弃,因此这些值不能在后续的代码中使用,也不可以使用这个标识符作为变量对其它变量进行赋值或运算。使用匿名变量时,只需要在变量声明的地方使用下画线替换即可。例如
package main
import "fmt"
/*
定义一个test函数,它会返回两个int类型的值,每次调用将会返回100 和200 两个数值。
这里我们先不用管函数的定义,后面会讲解.
我们用这个函数来理解_这个匿名变量。
*/
func test() (int, int) {
return 100, 200
}
func main() {
a1, b1 := test()
fmt.Println(a1, b1)
a2, _ := test()
fmt.Println(a2)
_, b2 := test()
fmt.Println(b2)
a3, _ := test() //在第一行代码中,我们只需要获取第一个返回值,所以第二个返回值定义为匿名变量_
_, b3 := test() //在第二行代码中,我们只需要获取第二个返回值,所以第一个返回值定义为匿名变量_
fmt.Println(a3, b3)
//注:以后比如说一个对象:User,我们只需要user_name,就可以使用匿名变量去接收它
}
输出
100 200
100
200
100 200
在编码过程中,可能会遇到没有名称的变量、类型或方法。虽然这不是必须的,但有时候这样做可以极大地增强代码的灵活性,这些变量被统称为匿名变量。
匿名变量不占用内存空间,不会分配内存。匿名变量与匿名变量之间也不会因为多次声明而无法使用。
2.2.6 变量的作用域
一个变量(常量、类型或函数)在程序中都有一定的作用范围,称之为作用域。
了解变量的作用域对我们学习Go语言来说是比较重要的,因为Go语言会在编译时检查每个变量是否使用过,一旦出现未使用的变量,就会报编译错误。如果不能理解变量的作用域,就有可能会带来一些不明所以的编译错误。
局部变量
在函数体内声明的变量称之为局部变量,它们的作用域只在函数体内,函数的参数和返回值变量都属于局部变量
package main
import "fmt"
//全局变量(函数之外)
var name string
func main() {
//局部变量(函数内部)
var num int
num = 1000
name = "小舒"
fmt.Println(name)
fmt.Println(num)
}
输出
小舒
1000
全局变量
在函数体外声明的变量称之为全局变量,全局变量只需要在一个源文件中定义,就可以在所有源文件中使用,当然,不包含这个全局变量的源文件需要使用"import"关键字引入全局变量所在的源文件之后才能使用这个全局变量。
全局变量声明必须以var关键字开头,如果想要在外部包中使用全局变量的首字母必须大写。
package main
import "fmt"
// 全局变量(函数之外)
var name string = "xiaoshu"
func main() {
//局部变量(函数内部)
var num int
num = 1000
var name string = "小舒"
fmt.Println(name)
fmt.Println(num)
}
输出
小舒
1000
注意:在go语言中,支持在全局变量定义了之后,再定义一个同名的局部变量(遵循就近原则,优先使用局部变量)
2.3 常量
常量是一个简单值的标识符,在程序运行时,不会被修改的量。
常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型。
const identifier [type] = value
你可以省略类型说明符[type],因为编译器可以根据变量的值来推断其类型。
-
显式类型定义:
const b string = "abc" -
隐式类型定义:
const b = "abc"
多个类型的声明可以简写为:
const var_name1,var_name2 = value1,value2
- 以下实例演示了常量的应用:
常量的定义:const
package main
import "fmt"
func main() {
const URL1 = "www.baidu.com" //隐式定义:可以自动推导常量的类型
const URL2 string = "www.baidu.com" //显示定义:在定义时加上常量的类型
//URL1 = "xiaoshu" 常量一旦定义就不能改变(即重新赋值)
fmt.Println(URL1, URL2)
//多个类型的声明
const a, b, c = 3.14, "xiaoshu", false
fmt.Println(a, b, c)
}
输出
www.baidu.com www.baidu.com
3.14 xiaoshu false
2.4 iota
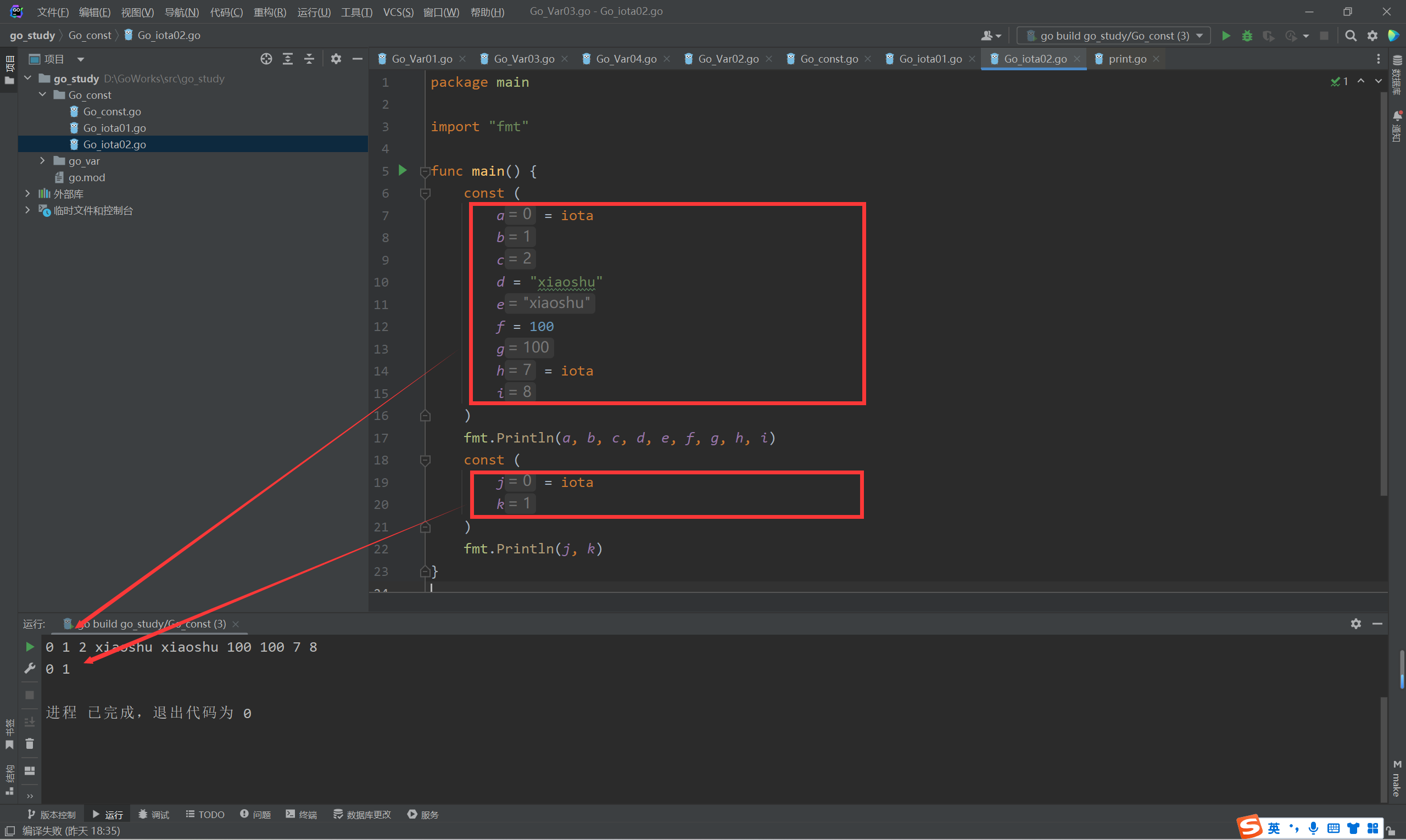
iota,特殊常量,可以认为是一个可以被编译器修改的常量。iota是go语言的常量计数器
iota在const关键字出现时将被重置为0(const内部的第一行之前),const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)
iota可以被用作枚举值:
const(
a = iota
b = iota
c = iota
)

第一个iota等于0,每当iota在新的一行被使用时,它的值都会自动加1;所以a=0,b=1,c=2可以简写为如下形式:
const(
//一组常量中,如果某个常量没有初始值,默认和上一行一致
a = iota
b
c
)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P6eEPnh5-1670464591356)(https://kevin-1311972042.cos.ap-chengdu.myqcloud.com/img/image-20221204002936223.png)]](https://img-blog.csdnimg.cn/37db06d34b4441a2ae252a634cd0fece.png)
综合测试,编译器很智能,大家直接看效果
2.5 数据类型
Go语言是一种静态类型的编程语言,在Go编程语言中,数据类型用于声明函数和变量。数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存。编译器在进行编译的时候,就要知道每个值的类型,这样编译器就知道要为这个值分配多少内存,并且知道这段分配的内存表示什么。
2.5.1 基本数据类型
布尔型
布尔型的值只可以是常量true或者false
//布尔型
var isFlag bool
var isSuccess bool = true
//默认值,flase
fmt.Printf("%t,类型:%T\n", isFlag, isFlag) //打印布尔型:%t
fmt.Printf("%t,类型:%T\n", isSuccess, isSuccess) //打印布尔型:%t
//输出
false,类型:bool
true,类型:bool
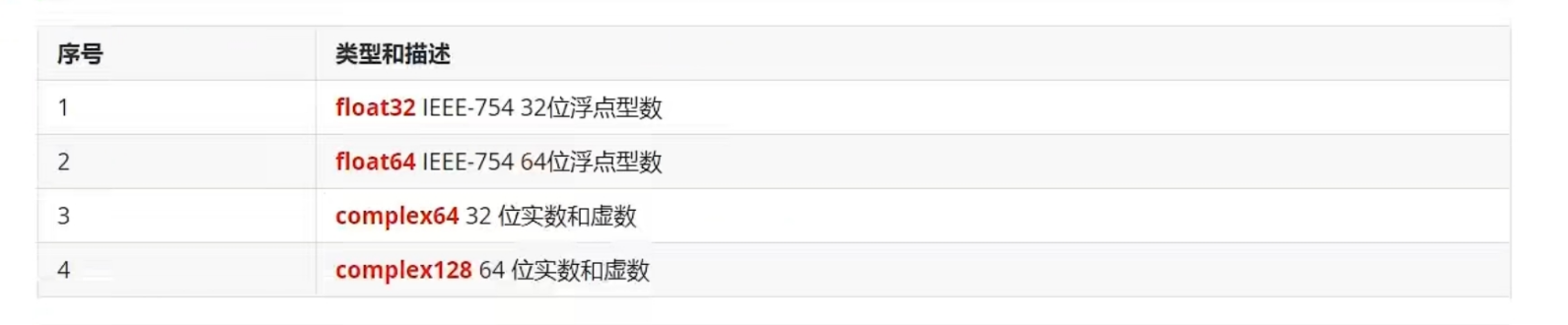
数值型
整型int和浮点型float32、float64,Go语言支持整型和浮点型数字,并且支持复数,其中位的运算采用补码。
整型
int,int8,int16,int32,int64,uint,uintptr,uint8,byte,uint16,uint32,uint64
Go也有基于架构的类型,例如:uint无符号、int有符号
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Yr2LWszh-1670464591356)(https://kevin-1311972042.cos.ap-chengdu.myqcloud.com/img/image-20221204151435391.png)]
//整型
var age int = 18
var id uint = 70
fmt.Printf("%d,类型:%T\n", age, age) //打印整型:%d
fmt.Printf("%d,类型:%T\n", id, id) //打印整型:%d
//输出
18,类型:int
70,类型:uint
浮点型
float32,float64,complex64,complex128
//浮点型:默认是6位小数打印
var money float64 = 1000.154
fmt.Printf("%f,类型:%T\n", money, money) //打印浮点型:%f
//打印浮点型及对应的小数位数:%.1f,.1表示只保留一位小数(会四舍五入)
fmt.Printf("%.1f,类型:%T\n", money, money)
//打印浮点型及对应的小数位数:%.2f,.2表示只保留两位小数(会四舍五入)
fmt.Printf("%.2f,类型:%T\n", money, money)
//输出
1000.154000,类型:float64
1000.2,类型:float64
1000.15,类型:float64
-
关于浮点数在机器中存放形式的简单说明,浮点数=符号位+指数位+尾数位
-
尾数部分可能丢失,造成精度损失。-123.0000901
var num1 float32 = -123.0000901 var num2 float64 = -123.0000901 //尽量使用 float64 来定义浮点类型的数据 fmt.Println("num1 =", num1, "num2 = ", num2)//输出 num1 = -123.00009 num2 = -123.0000901- 说明:float64的精度要比float32的准确
- 说明:如果我们要保存一个精度高的数,则应该选择float64
-
浮点数的存储,浮点数=符号位+指数位+尾数位 分为三部分,在存储的过程中可能存在精度丢失
-
golang的浮点型默认为float64,int型默认是int32
以下列出了其他更多的数字类型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NTf3ejT9-1670466213190)(https://kevin-1311972042.cos.ap-chengdu.myqcloud.com/img/image-20221204161048722.png)]](https://img-blog.csdnimg.cn/02b9e3f02cd040fd87db557e76dfb4df.png)
字符与字符串类型
字符串就是一串固定长度的字符连接起来的字符序列。
Go的字符串是由单个字节连接起来的。Go语言的字符串的字节使用UTF-8编码标识Unicode文本。
package main
import "fmt"
func main() {
var str1 string
str1 = "Hello,xiaoshu"
fmt.Printf("%s 类型:%T\n", str1, str1)
//单引号 字符——》对应的是整型
char1 := 'A'
char2 := '中'
str2 := "A"
fmt.Printf("%s 类型:%T\n", char1, char1) //输出错误,并不是我们想要的A:%!s(int32=65) 类型:int32
fmt.Printf("%d 类型:%T\n", char1, char1) //65 类型:int32 此处输出的65是A在ASCII表中对应的十进制值
//扩展:所有汉字的编码表,GBK编码表
//全世界的编码表:Unicode编码表
fmt.Printf("%d 类型:%T\n", char2, char2) //20013 类型:int32 此处输出的20013是中在GBK表中对应的十进制值
fmt.Printf("%s 类型:%T\n", str2, str2) //A 类型:string
//字符串连接 +
fmt.Println("你好" + ",北京")
//转义字符 \
fmt.Println("你好,\"北京\"") //\":打印双引号
fmt.Println("你好,'北京'") //单引号不需要转义
fmt.Println("你好\t北京") //\t:制表符,tab键
}
输出
Hello,xiaoshu 类型:string
%!s(int32=65) 类型:int32
65 类型:int32
20013 类型:int32
A 类型:string
你好,北京
你好,"北京"
你好,'北京'
你好 北京
数据类型转换
在必要以及可行的情况下,一个类型的值可以被转换成另一种类型的值。由于Go语言不存在隐式类型转换,因此所有的类型转换都必须显式的声明:
valueofTypeB = typeB(valueofTypeA)
类型B的值=类型B(类型A的值)
package main
import "fmt"
func main() {
var age1 int = 18
age2 := float64(age1)
fmt.Println(age1, age2)
fmt.Printf("%d,类型:%T\n%f,类型:%T\n", age1, age1, age2, age2)
fmt.Println()
a := 3
b := 5.0
fmt.Printf("%d,类型:%T\n%f,类型:%T\n", a, a, b, b)
//需求:将int类型的a转换成 float64 类型
c := float64(a)
d := int(b) //将 float64 类型的b转换成 int 类型
fmt.Printf("%f,类型:%T\n", c, c)
fmt.Printf("%d,类型:%T", d, d)
}
输出
18 18
18,类型:int
18.000000,类型:float64
3,类型:int
5.000000,类型:float64
3.000000,类型:float64
5,类型:int
类型转换只能在定义正确的情况下转换成功,例如从一个取值范围较小的类型转换到一个取值范围较大的类型(将int16转换为int32)。当从一个取值范围较大的类型转换到取值范围较小的类型时(将int32转换为int16或将float32转换为int),会发生精度丢失(截断)的情况。
注意:整型不能转换成bool类型,类型较大的转换成较小的会产生精度损失(例如:float64——》float32)
2.5.2 派生数据类型(后面会讲)
-
指针
-
数组
-
结构体
-
通道(channel)
-
切片(slice)
-
函数
-
接口(interface)
2.6 运算符
只需要记住一点,go语言中只有 i++(自增) i–(自减)而没有 ++i --i 。如果学过java或者其他语言的小伙伴,就会明白运算符都是一样的道理,所以算术运算符、关系运算符和逻辑运算符我就不多说了,没有学过的就自己学一下,我是学过的,这里就不做过多赘述,下面主要说一下位运算符!
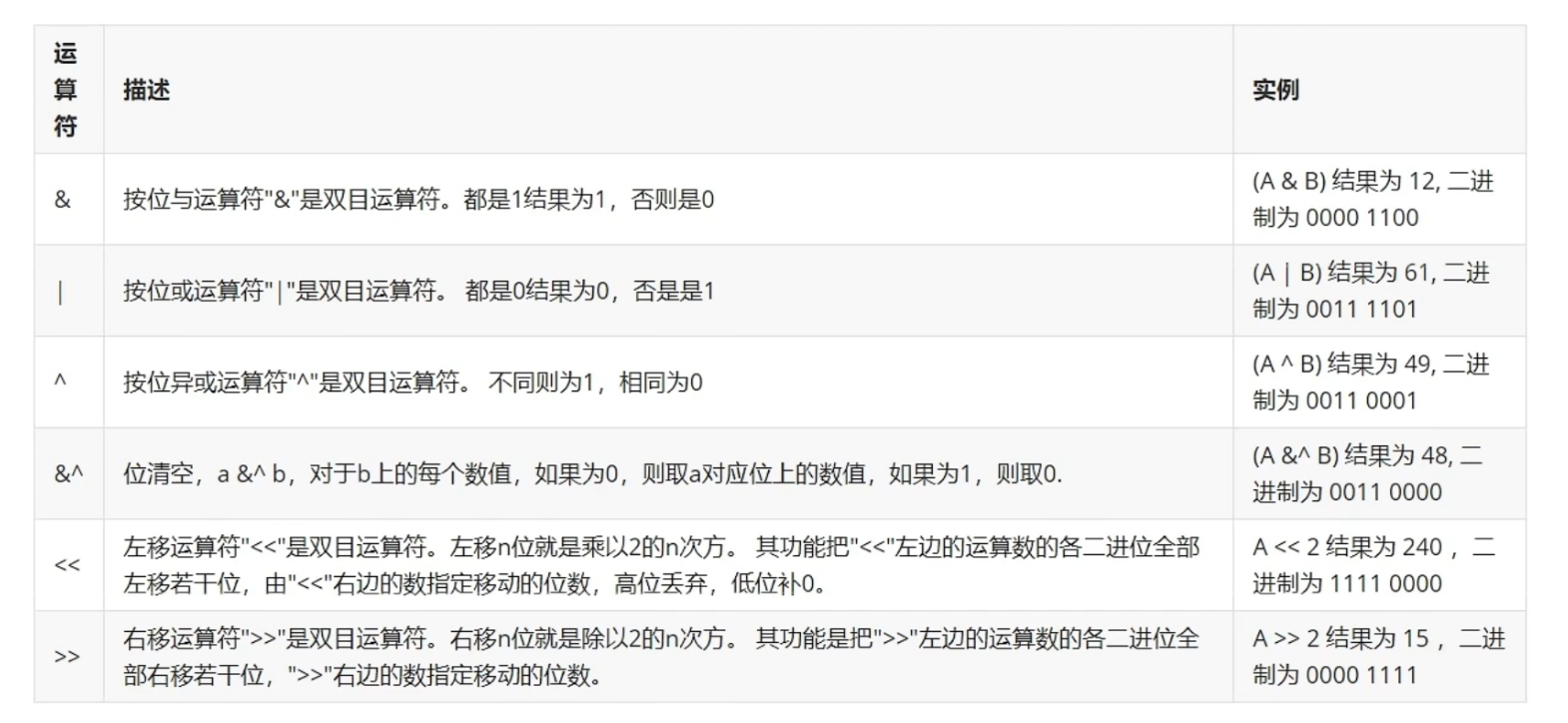
位运算符
Go语言支持的位运算符如下表所示。假定A为60,B为13:
package main
import "fmt"
func main() {
//位运算:二进制上的 0 false 1 true
// 60: 0011 1100
// 13: 0000 1101
// -------------
// & 0000 1100 60 & 13 = 12 我和你,同时满足
// | 0011 1101 60 | 13 = 61 我或你,满足一个即可
// ^ 0011 0001 60 ^ 13 = 49 不同为1,相同为0
//左移 << 2:数字2,代表左移两位
//右移 >> 2:数字2,代表右移两位
var a uint = 60
var b uint = 13
var c uint = 0
var d uint = 0
var e uint = 0
c = a & b
d = a | b
e = a ^ b
fmt.Printf("%d,二进制:%b\n", c, c) //%b:binary,输出某个十进制数的二进制值
fmt.Printf("%d,二进制:%b\n", d, d) //%b:binary,输出某个十进制数的二进制值
fmt.Printf("%d,二进制:%b\n", e, e) //%b:binary,输出某个十进制数的二进制值
//a左移两位 240,二进制:11110000
fmt.Printf("%d,二进制:%b\n", a<<2, a<<2) //%b:binary,输出某个十进制数的二进制值
//a右移两位 15,二进制:1111
fmt.Printf("%d,二进制:%b\n", a>>2, a>>2) //%b:binary,输出某个十进制数的二进制值
}
输出
12,二进制:1100
61,二进制:111101
49,二进制:110001
240,二进制:11110000
15,二进制:1111
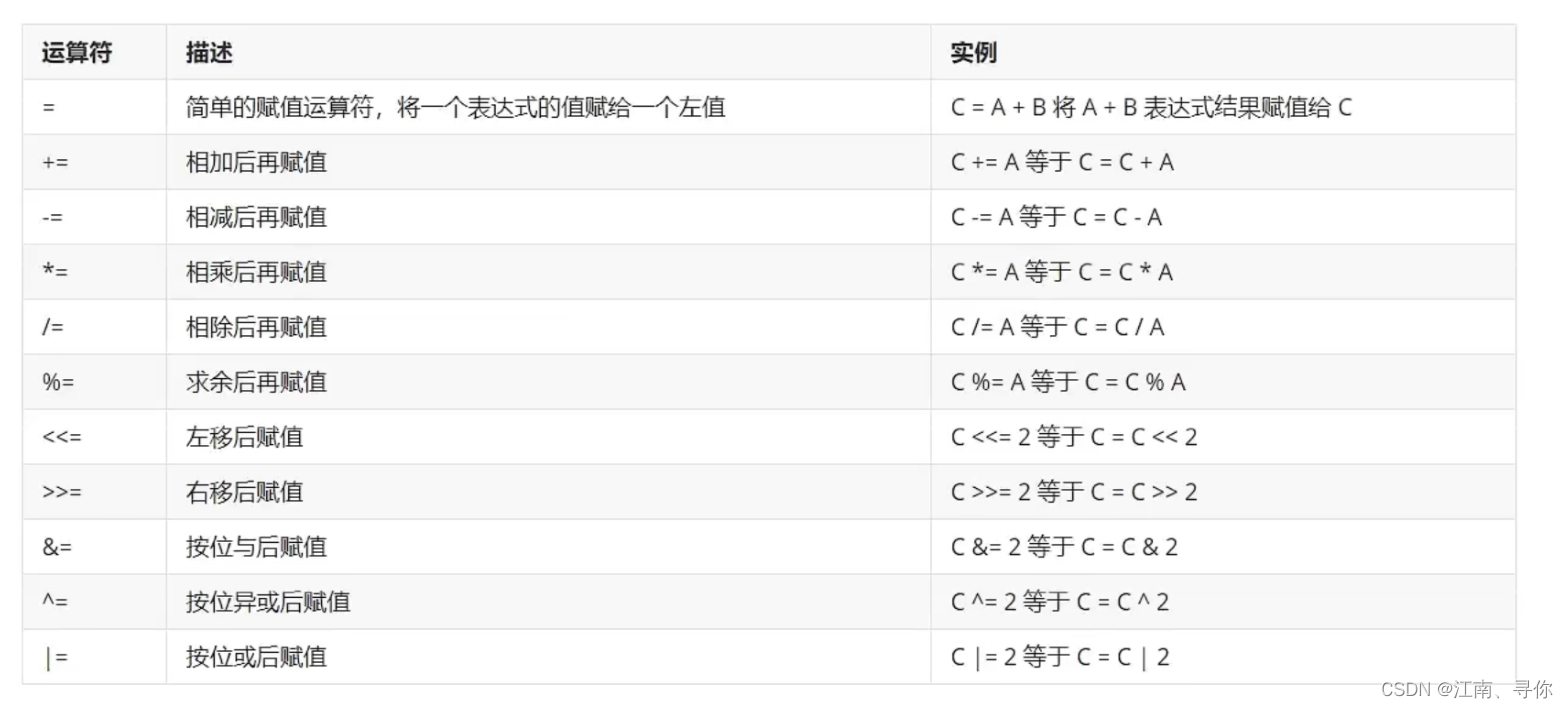
赋值运算符
下表列出了所有Go语言的赋值运算符
其他运算符
下表列出了所有Go语言的其他运算符

package main
import "fmt"
func main() {
var a int = 4
/*var b int32
var c float32*/
var ptr *int
//& 和 * 运算符
ptr = &a //ptr 包含了 a 变量的地址
fmt.Printf("a的类型:%T a的值:%d\n", a, a) //int 4 ——》猜测成功,输出是:a的类型:int a的值:4
//*int 猜测:应该是一个内存地址——》猜测成功,输出是:ptr的类型:*int ptr的值:0xc0000160c8
fmt.Printf("ptr的类型:%T ptr的值:%p\n", ptr, ptr)
//int 0 ——》猜测错误,输出是:*ptr的类型:int *ptr的值:4
fmt.Printf("*ptr的类型:%T *ptr的值:%d\n", *ptr, *ptr)
}
2.7 扩展之获取键盘输入
package main
import "fmt"
func main() {
/**
输入和输出:fmt包
1、输出:
fmt.Println()//打印换行
fmt.Print()//打印不换行
fmt.Printf()//格式化打印
2、输入:
fmt.Scanf()
fmt.Scanln()
fmt.Scan()
*/
var x int
var y float64
fmt.Println("请输入两个数:1、整数 2、浮点数")
//定义了两个变量,想用键盘来录入这两个变量
//接收需要地址,变量取地址:&变量名
fmt.Scanln(&x, &y) //Scanln():阻塞等待用户的键盘输入
fmt.Printf("输出:\n")
fmt.Println("x =", x)
fmt.Println("y =", y)
}
输出
请输入两个数:1、整数 2、浮点数
110 100.123
输出:
x = 110
y = 100.123
2.8 编码规范
为什么需要编码规范
- 代码规范不是强制的,也就是你不遵循代码规范写出来的代码运行也是完全没有问题的
- 代码规范目的是方便团队形成一个统一的代码风格,提高代码的可读性,规范性和统一性。本规范将从命名规范,注释规范,代码风格和GO语言提供的常用的工具这几个方面做一个说明。
- 规范并不是唯一的,也就是说理论上每个公司都可以制定自己的规范,不过一般来说整体上规范差异不会很大。
代码规范
命名规范
命名是代码规范中很重要的一部分,统一的命名规则有利于提高的代码的可读性,好的命名仅仅通过命名就可以获取到足够多的信息。
-
当命名(包括常量、变量、类型、函数名、结构字段等等)以一个大写字母开头,如: Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的public) ;
-
命名如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的private )
包名: package
保持package的名字和目录名保持一致,尽量采取有意义的包名,简短,有意义,尽量和标准库不要冲突。包名应该为小写单词,不要使用下划线或者混合大小写。
package model
package main
文件名
尽量采取有意义的文件名,简短,有意义,应该为小写单词,使用下划线分隔各个单词(蛇形命名)。
注释规范
统─使用中文注释,对于中英文字符之间严格使用空格分隔,这个不仅仅是中文和英文之间,英文和中文标点之间也都要使用空格分隔,例如:
// 从 Redis 中批量读取属性,对于没有读取到的 id ,记录到一个数组里面,准备从 DB中读取
上面Redis 、 id 、DB和其他中文字符之间都是用了空格分隔。
- 建议全部使用单行注释
- 和代码的规范一样,单行注释不要过长,禁止超过120字符。
函数注释格式:函数名 函数作用
// add 加法函数(函数调用时将鼠标光标移动到函数名上,函数前面的注释会显示在函数名下面)
func add(a int, b int /*简写:a,b int*/) (sum int) {
sum = a + b
return sum
}
import规范
import在多行的情况下,goimports会自动帮你格式化,但是我们这里还是规范一下import的一些规范,如果你在一个文件里面引入了一个package,还是建议采用如下格式:
import (
"fmt"
)
如果你的包引入了三种类型的包,标准库包,程序内部包,第三方包,建议采用如下方式进行组织你的包:
import (
"encoding/json"
"strings"
"myproject/models"
"myproject/controller"
"myproject/utils"
"github.com/astaxie/beego"
"github.com/go-sq]-driver/mysql"
)
有顺序的引入包,不同的类型采用空格分离,第一种实标准库,第二是项目包,第三是第三方包。在项目中不要使用相对路径引入包:
// 这是不好的导入
import "../net"
// 这是正确的做法
import "github.com/repo/proj/src/net"
三、程序的流程控制
程序的流程控制结构一共有三种:顺序结构,选择结构,循环结构
顺序结构:从上到下,逐行执行。默认的逻辑
选择结构:条件满足某些代码才会执行
-
if
-
switch
-
select,后面 channel再讲
循环结构: 条件满足某些代码会被反复执行0-N次
- for(go语言没有while循环,可以使用for完成)
3.1 if语句
条件语句需要开发者通过指定一个或多个条件,并通过测试条件是否为true来决定是否执行指定语句,并在条件为false的情况在执行另外的语句。
下图展示了程序语言中条件语句的结构:
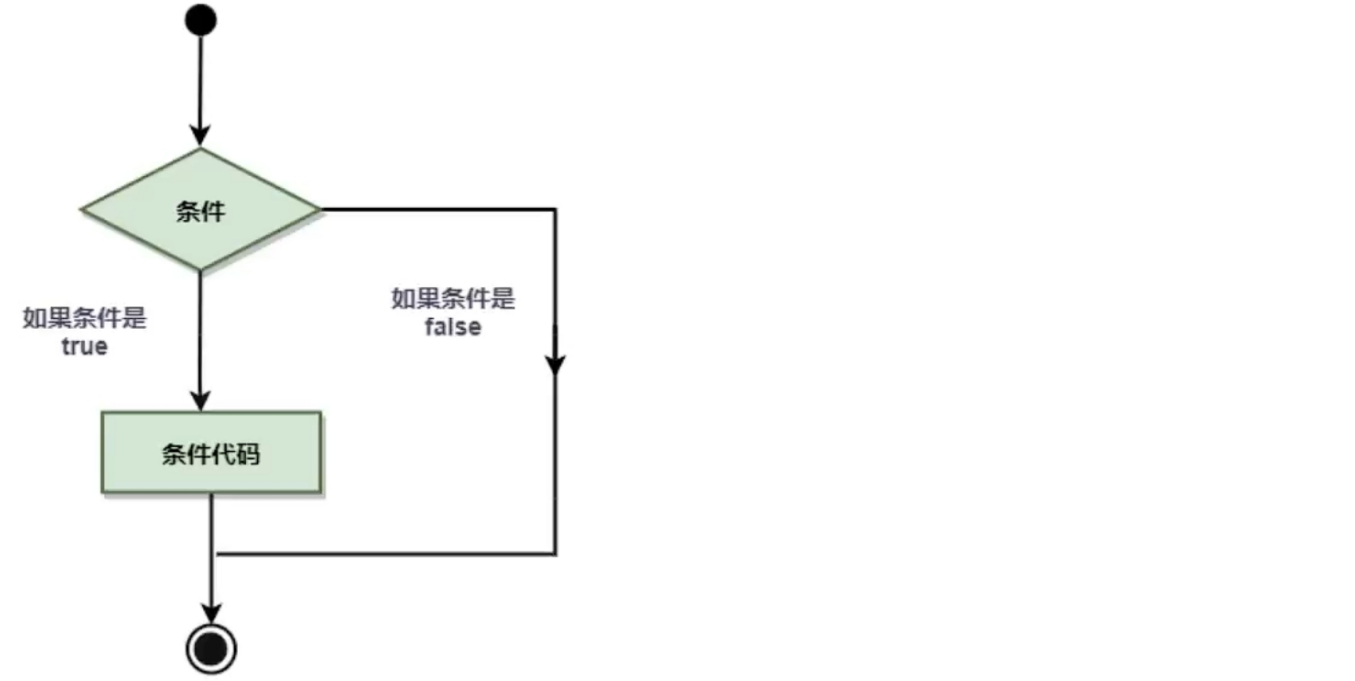
普通if语句
package main
import "fmt"
func main() {
var a int = 6
//判断a是不是5
if a == 5 {
fmt.Printf("a是%d", a)
} else {
fmt.Printf("a不是5,a是%d", a)
}
}
输出
a不是5,a是6
if嵌套语句
//if嵌套语句
if 布尔表达式1{
//在布尔表达式1为true时执行
if 布尔表达式2{
//在布尔表达式2为true时执行
}
}
package main
import "fmt"
func main() {
var a int = 6
//var a int = 12
var b int = 10
//if嵌套语句
//在a等于6,b等于10的情况下输出b
if a == 6 {
//在布尔表达式1为true时执行
if b == 10 {
//在布尔表达式2为true时执行
fmt.Printf("a的值是:%d时,b的值是:%d\n", a, b)
}
} else {
fmt.Printf("a不是6,a是%d\n", a)
}
}
输出
a的值是:6时,b的值是:10
验证密码小练习
package main
import "fmt"
func main() {
//业务:验证密码
var a, b int
pwd := 2022
fmt.Println("请输入密码:")
fmt.Scan(&a)
if a == pwd {
fmt.Println("请再次输入密码:")
fmt.Scan(&b)
if b == pwd {
fmt.Println("登录成功")
} else {
fmt.Println("登录失败!第二次输入的密码错误,请重新输入")
}
} else {
fmt.Println("登录失败!密码错误,请重新输入")
}
}
输出
请输入密码:
2022
请再次输入密码:
2022
登录成功
3.2 switch语句
switch 语句用于基于不同条件执行不同动作,每一个case 分支都是唯一的,从上至下逐一测试,直到匹配为止。
switch var {
case val1:
...
case val2:
...
default:
...
}
注意:
go语言与java,C#不同,它的每个case后不需要加break;而是在需要穿透的时候使用fallthrough 关键字。而java、C#不加的话会产生case穿透现象
switch 语句执行的过程从上至下,直到找到匹配项,匹配项后面也不需要再加 break。switch 默认情况下case 最后自带 break语句
package main
import "fmt"
func main() {
//判断键盘输入的A B C D 对应的分数范围:
var score string
fmt.Println("请需要查询的等级(A B C D):")
fmt.Scan(&score)
switch score {
case "A":
fmt.Println("达到A需要90分以上")
case "B":
fmt.Println("达到B需要80~90分")
case "C":
fmt.Println("达到C需要60~80分")
default:
fmt.Println("达到D需要0~60分")
}
fmt.Println()
//switch后面什么都不写,默认为bool类型的true
switch {
case true:
fmt.Println("true")
case false:
fmt.Println("false")
default:
fmt.Println("其他")
}
}
输出
请输入需要查询的等级(A B C D):
C
达到C需要60~80分
true
fallthrough 贯穿;直通
switch 默认情况下匹配成功后就不会执行其他 case,如果我们需要执行后面的 case,可以使用 fallthrough 穿透case
使用fallthrough 会强制执行后面的case 语句,fallthrough 不会判断下一条case 的表达式结果是否为 true。
package main
import "fmt"
func main() {
a := true
//switch后面什么都不写,默认为bool类型的true
switch a {
case true:
fmt.Println("true")
fallthrough //case穿透,不管下一个条件(只穿透下一个case)满不满足都会执行
case false:
fmt.Println("false")
default:
if a == false {
break //终止case穿透
}
fmt.Println("其他")
}
fmt.Println()
switch !a {
case true:
fmt.Println("true")
case false:
fmt.Println("false")
fallthrough
default:
if !a == false {
break //终止case穿透,不执行下面的输出语句
}
fmt.Println("其他")
}
}
输出
true
false
false
3.3 for循环
在不少实问题中有许多具有规律性的重复操作,因此在程序中就需要重复执行某些语句。
for 循环是一个循环控制结构,可以执行指定次数的循环。
package main
import "fmt"
func main() {
//for 给控制变量赋初值;循环条件;给控制变量增量或减量
//扩展:for{} 无限循环
//方法1:
for a := 0; a < 10; a++ {
fmt.Print(a)
fmt.Print(" ")
}
fmt.Println()
//方法2:;循环条件;
var j int = 0
for ;j < 10; {
fmt.Print(j)
j++
fmt.Print(" ")
}
fmt.Println()
//方法3:给控制变量赋初值;循环条件;给控制变量增量或减量
var i int
for i = 9; i < 10; i-- {
fmt.Print(i)
fmt.Print(" ")
//需要给一个终止条件,否则会一直减下去
if i == 0 {
break //终止循环
}
}
//注意:for循环没有下面这种使用方法;只能使用上面的两种方法
/*
for var j int = 0; j < 10; i++ {
fmt.Print(i)
}
*/
}
输出
0 1 2 3 4 5 6 7 8 9
0 1 2 3 4 5 6 7 8 9
9 8 7 6 5 4 3 2 1 0
思考:计算1到10的数字之和
package main
import "fmt"
func main() {
//计算1到10的数字之和
var sum int
for i := 0; i <= 10; i++ {
sum += i
}
fmt.Printf("1到10的数字之和:%d", sum)
}
输出
1到10的数字之和:55
打印一个方阵
package main
import "fmt"
/*
打印一个方阵(5行5列):
* * * * *
* * * * *
* * * * *
* * * * *
* * * * *
*/
func main() {
//i控制行
for i := 0; i < 5; i++ {
//j控制列
for j := 0; j < 5; j++ {
fmt.Print("* ")
}
fmt.Println()
}
}
输出
* * * * *
* * * * *
* * * * *
* * * * *
* * * * *
打印九九乘法表
package main
import "fmt"
// 打印九九乘法表
func main() {
//i控制行
for i := 1; i < 10; i++ {
//j控制列
for j := 1; j < 10; j++ {
var res int
res = i * j
fmt.Printf("%d * %d = %d\t", j, i, res)
if i == j {
break //结束内层循环,继续执行外层循环
}
}
fmt.Println()
}
}
break和continue
-
break 结束当前整个循环
-
continue 结束当次循环,继续执行下一次循环
break在九九乘法表中用过就不再演示,下面演示一下continue
package main
import "fmt"
func main() {
for a := 0; a < 10; a++ {
//当a等于5时不打印输出
if a == 5 {
continue
}
fmt.Print(a)
fmt.Print(" ")
}
}
输出
0 1 2 3 4 6 7 8 9
3.4 string
什么是string
Go中的字符串是一个字节的切片,可以通过将其内容封装在 ”“ 中来创建字符串,Go中的字符串是 Unicode 兼容的,并且是UTF-8 编码
字符串是一些字节的集合。
使用for循环遍历string
package main
import "fmt"
func main() {
str := "xiaoshu"
fmt.Println("字符串:", str)
//获取字符串的长度 len(字符串类型的变量名)
fmt.Println("字符串的长度为:", len(str))
//获取指定的字节
fmt.Println("字符串中第1个字符打印:", str[0]) //字节打印: 120 此处的120,是ASCII编码表中x对应的数值
fmt.Printf("字符编码打印;%d 字符打印:%c", str[0], str[0]) //%c:打印字符
fmt.Println()
//遍历string
//方法一:
for i := 0; i < len(str); i++ {
fmt.Printf("%c ", str[i])
}
fmt.Println("\n------------------------")
//方法二
//输入str.for回车,即for range循环,遍历数组、切片;返回下标和对应的值
for j := range str {
fmt.Print(j) //只打印j,输出的是:0123456 为str的下标
}
fmt.Println()
for _, v := range str {
fmt.Printf("%c", v) //只打印v,输出的是:xiaoshu
}
fmt.Println()
//同时打印 j,v,输出的是:0x 1i 2a 3o 4s 5h 6u
for j, v := range str {
fmt.Print(j)
fmt.Printf("%c ", v)
}
//string字符串是不能修改的,说白了就是不能给str的每一个字符重新赋值
//str[2] = 'A'
fmt.Println()
fmt.Println(str)
}
输出
字符串: xiaoshu
字符串的长度为: 7
字符串中第1个字符打印: 120
字符编码打印;120 字符打印:x
x i a o s h u
------------------------
0123456
xiaoshu
0x 1i 2a 3o 4s 5h 6u
xiaoshu
四、函数
4.1 什么是函数
- 函数是基本的代码块,用于执行一个任务。
- Go 语言最少有个 main() 函数。
- 你可以通过函数来划分不同功能,逻辑上每个函数执行的是指定的任务
- 函数声明告诉了编译器函数的名称,返回类型,和参数。
4.2 函数的基础知识
Go语言函数定义格式如下:
func function_name( [parameter list] ) [return_types] {
函数体
}
package main
import "fmt"
// 主函数
func main() {
//调用函数,形参与实参要一一对应,顺序,个数,类型
var sum int = add(1, 2)
fmt.Println(sum)
}
//函数定义格式:
// func 函数名(参数列表)(函数调用后的返回值){
// 函数体:执行一段代码
// return xxx
// }
// add 两个int型数字相加(函数调用时将鼠标光标移动到函数名上,函数前面的注释会显示在函数名下面)
// 形式参数:定义函数时,用来接收外部传入数据的参数,就是形式参数,简称形参。例如add()函数中的a,b
// 实际参数:调用函数时,传给形参的实际数据叫做实际参数,简称实参。例如主函数中,调用add()函数传入的1,2
func add(a int, b int /*简写:a,b int*/) (sum int) {
sum = a + b
//一个函数定义上有返回值,那么函数中必须使用return语句
//函数调用处需要使用变量来接收该结果
return sum
}
输出
3
函数定义中的几种常见类型
-
无参无返回值函数
-
有一个参数的函数
-
有两个参数的函数
-
有一个返回值的函数
-
有多个返回值的函数
package main
import "fmt"
func main() {
//函数调用
noParamsNoReturn()
haveOneParam(1)
haveTwoParams(1, "xiaoshu")
fmt.Println()
sum := haveOneReturn(1)
fmt.Println(sum)
plus, sub := haveManyReturns(10, 5)
//plus, _ := haveManyReturns(10, 5) //只接收一个plus(匿名变量的使用)
fmt.Printf("%d,%d", plus, sub)
}
// 无参无返回值函数
func noParamsNoReturn() {
fmt.Println("这是一个无参无返回值函数")
}
// 有一个参数的函数
func haveOneParam(a int) {
fmt.Println("这是有一个参数的函数,这个参数是:", a)
}
// 有两个参数的函数
func haveTwoParams(a int, str string) {
fmt.Printf("这是有两个参数的函数,第一个参数是:%d,第二个参数是:%s", a, str)
}
// 有一个返回值的函数
func haveOneReturn(a int) (sum int) {
sum = a + 1
fmt.Print("这是有一个返回值的函数:")
return sum
}
// 有多个返回值的函数
func haveManyReturns(a, b int) (plus int, sub int) {
plus = a + b
sub = a - b
fmt.Print("这是有两个返回值的函数:")
return plus, sub
}
输出
这是一个无参无返回值函数
这是有一个参数的函数,这个参数是: 1
这是有两个参数的函数,第一个参数是:1,第二个参数是:xiaoshu
这是有一个返回值的函数:2
这是有两个返回值的函数:15,5
函数中的可变参数
概念:一个函数的参数类型确定,但个数不确定,就可以使用可变参数
//arg ...int 告诉go这个函数接收不定数量的参数,类型全部是int
func myfunc(arg ...int) {
}
package main
import "fmt"
func main() {
sum := getSum(1, 2, 3, 4, 5)
fmt.Printf("sum:%d", sum)
}
// ... 可变参数
func getSum(nums ...int) (sum int) {
sum = 0
for i := 0; i < len(nums); i++ {
fmt.Println(nums[i])
sum += nums[i]
}
return sum
}
输出
1
2
3
4
5
sum:15
注意:
- 如果一个函数的参数是可变参数,同时还有其他的参数,可变参数要放在列表的最后
- 一个函数的参数列表中最多只能有一个可变参数
4.3 参数传递
按照数据的存储特点来分:
- 值类型的数据:操作的是数据本身:int、string、bool、float64、array
- 引用类型的数据:操作的是数据的地址:slice、map、channel
值传递
package main
import "fmt"
func main() {
/*
值传递:
arr2的数据是从arr1复制来的,所以是不同的内存空间
修改arr2并不会影响arr1
小结:
值传递:传递的是数据的副本,修改数据,对于原始的数据没有影响
值类型的数据,默认值传递:基础类型,array,struct
*/
//定义一个数组,格式:[数组大小]数组类型
arr1 := [4]int{1, 2, 3, 4}
fmt.Printf("arr1数组:%d,arr1内存空间地址:%p\n", arr1, &arr1) //打印数组arr1
//值传递:拷贝arr1
update(arr1)
fmt.Printf("\n调用更新数组方法后的arr1数组:%d,更新方法后arr1的内存空间地址:%p\n", arr1, &arr1)
}
func update(arr2 [4]int) {
fmt.Printf("\n更新前arr2数组:%d,arr2内存空间地址:%p\n", arr2, &arr2)
arr2[0] = 100
fmt.Printf("更新后arr2数组:%d,arr2内存空间地址:%p\n", arr2, &arr2)
}
输出
arr1数组:[1 2 3 4],arr1内存空间地址:0xc0000a4060
更新前arr2数组:[1 2 3 4],arr2内存空间地址:0xc0000a40c0
更新后arr2数组:[100 2 3 4],arr2内存空间地址:0xc0000a40c0
调用更新数组方法后的arr1数组:[1 2 3 4],更新方法后arr1的内存空间地址:0xc0000a4060
引用传递
package main
import "fmt"
func main() {
/*
引用传递:
先将arr1的数据拷贝到arr2,arr2重新赋值后,再将数据拷贝到arr1(双向拷贝数据:arr1到arr2,arr2再到arr1)
*/
//切片,是一个可以扩容的数组;简单来说,就是不去设置数组的大小(数组:定义了数组的大小)
s1 := []int{1, 2, 3, 4}
fmt.Printf("s1切片:%d,s1切片的内存空间:%p\n", s1, &s1)
updateSlice(s1)
fmt.Printf("\n调用后的s1切片:%d,调用后的s1切片的内存空间:%p\n", s1, &s1)
}
func updateSlice(s2 []int) {
fmt.Printf("\ns2切片:%d,s2切片的内存空间:%p\n", s2, &s2)
s2[1] = 100
fmt.Printf("更新后的s2切片:%d,更新后的s2切片的内存空间:%p\n", s2, &s2)
}
输出
s1切片:[1 2 3 4],s1切片的内存空间:0xc000008078
s2切片:[1 2 3 4],s2切片的内存空间:0xc0000080a8
更新后的s2切片:[1 100 3 4],更新后的s2切片的内存空间:0xc0000080a8
调用后的s1切片:[1 100 3 4],调用后的s1切片的内存空间:0xc000008078
4.4 函数中变量的作用域
作用域:变量可以使用的范围
局部变量:函数内部定义的变量,叫做局部变量
全局变量:函数外部定义的变量,叫做全局变量
package main
import "fmt"
var i int = 20 //全局变量,不能使用简写:j:= 20
// 函数作用域
func main() {
fmt.Println("全局变量:", i) //全局变量,在任何函数中都可以使用
a()
b()
//函数体内的局部变量
temp := 100 //这种简写方法只能用于局部变量的定义
if j := 1; j < i { //声明了一个作用域在 if语句 中的局部变量j,初值为1;并且判断条件为j<i
//if语句内的局部变量
temp := 50
fmt.Println("if语句内的局部变量:", temp) //局部变量,遵循就近原则
fmt.Println("if语句内的局部变量:", j)
}
//fmt.Println(j) //局部变量:不能使用在其他函数内定义的变量
fmt.Println("main函数体内的局部变量:", temp)
}
func a() {
fmt.Println("全局变量:", i) //全局变量,在任何函数中都可以使用
str := "a"
fmt.Println("a函数中的局部变量:", str) //局部变量:不能使用在其他函数内定义的变量
}
func b() {
fmt.Println("全局变量:", i) //全局变量,在任何函数中都可以使用
//fmt.Println(temp) //局部变量:不能使用在其他函数内定义的变量
//fmt.Println(i) //局部变量:不能使用在其他函数内定义的变量
}
输出
全局变量: 20
全局变量: 20
a函数中的局部变量: a
全局变量: 20
if语句内的局部变量: 50
if语句内的局部变量: 1
main函数体内的局部变量: 100
4.5 递归函数
定义:一个函数自己调用自己,就叫做递归函数
注意:
- 递归函数需要有一个出口,逐渐向出口靠近,没有出口就会形成死循环
- 十分耗内存,尽量不要使用
package main
import "fmt"
func main() {
//计算10的阶乘
res := factorial(10)
fmt.Println(res)
}
/*
factorial:计算阶乘的函数
i:需要计算的阶乘数
res:返回一个结果
*/
func factorial(i int64) (res int64) {
/*
例如:i==5
5!=5*4!
=5*4*3!
=5*4*3*2!
=5*4*3*2*1!
=5*4*3*2* (1*1)
*/
//自己想的方法:
if i == 1 {
return 1
} else {
res = i * factorial(i-1)
}
//大牛解答:
/*if i == 1 {
return 1
}
res = i * factorial(i-1)*/
return res
}
输出
3628800
4.6 defer延迟函数
defer语义: 推迟、延迟
在go语言中,使用defer关键字来延迟一个函数或者方法的执行。
defer函数或者方法:一个函数或方法的执行被延迟了
-
你可以在函数中添加多个defer语句,当函数执行到最后时,这些defer语句会按照逆序执行,最后该函数返回,特别是当你在进行一些打开资源的操作时,遇到错误需要提前返回,在返回前你需要关闭相应的资源,不然很容易造成资源泄露等问题。
-
如果有很多调用 defer,那么 defer 是采用后进先出 (栈) 模式
package main
import "fmt"
func main() {
defer printInfo("1")
printInfo("2")
defer printInfo("3") //将函数放到最后执行,如果存在多个就逆序执行
printInfo("4")
defer printInfo("5") //将函数放到最后执行,如果存在多个就逆序执行
printInfo("6")
defer printInfo("7") //将函数放到最后执行,如果存在多个就逆序执行
printInfo("8")
defer printInfo("9") //将函数放到最后执行,如果存在多个就逆序执行
printInfo("10")
}
func printInfo(str string) {
fmt.Print(str + " ")
}
输出
2 4 6 8 10 9 7 5 3 1
思考:参数是什么时候传递进参数的呢?
package main
import "fmt"
// defer 关闭操作
func main() {
a := 10
fmt.Println("a=", a)
defer printNum(a) //这时候参数就已经传递进去了,只是函数被延迟执行了
a++
fmt.Println("a++ 之后的 a=", a)
}
func printNum(i int) {
fmt.Print(i)
}
a= 10
a++ 之后的 a= 11
10
4.7 函数的数据类型
函数的类型:func (参数类型)(返回值类型)
示例:
func(string) string
函数本身也是一种数据类型
package main
import "fmt"
// func() 本省就是一个数据类型
func main() {
//不能加上括号:不加括号,函数就是一个变量;加上括号:f(),就成函数的调用了
fmt.Printf("%T\n", f) //func(string, string) string
fmt.Printf("%T\n", 10) //int
fmt.Printf("%T\n", "xiaoshu") //string
//定义一个函数类型的函数变量
var f1 func(string, string) string
f1 = f //引用类型的
//两个变量指向的是同一个地址
fmt.Println(f1) //0x10fea0
fmt.Println(f) //0x10fea0
str := f1("hello", "xiaoshu")
fmt.Println(str)
}
func f(str1 string, str2 string) (res string) {
res = str1 + " " + str2
return res
}
输出
func(string, string) string
int
string
0x10fea0
0x10fea0
hello xiaoshu
函数在Go语言中是复合类型,可以看做是一种特殊的变量
函数名:指向函数体的内存地址,一种特殊类型的指针变量
4.8 匿名函数
package main
import "fmt"
func main() {
f1()
f2 := f1 //函数本身也是一个变量
f2()
//匿名函数:没有名字的函数
f3 := func() {
fmt.Println("我是f3函数")
}
f3()
//匿名函数直接进行调用,自己调用自己
func() {
fmt.Println("我是f4函数")
}()
//匿名函数传参
func(a, b int) {
fmt.Println(a, b)
fmt.Println("我是f5函数")
}(1, 2)
//匿名函数的返回值
sum := func(a, b int) int {
fmt.Println("我是f6函数")
return a + b
}(1, 2)
fmt.Println(sum)
}
func f1() {
fmt.Println("我是f1函数")
}
输出
我是f1函数
我是f1函数
我是f3函数
我是f4函数
1 2
我是f5函数
我是f6函数
3
Go语言支持函数式编程
- 将匿名函数作为另外一个函数的参数,回调函数
- 将匿名函数作为另外一个函数的返回值,可以形成闭包结构
4.9 回调函数
高阶函数: 根据go语言的数据类型的特点,可以将一个函数作为另外一个函数的参数。
fun1(),fun2()
将 fun1函数作为 fun2这个函数的参数
fun2函数: 就叫做高阶函数,接收了一个函数作为参数的函数
fun1函数: 就叫做回调函数,作为另外一个函数的参数
package main
import "fmt"
func main() {
sum := addNums(1, 2)
fmt.Println(sum)
res1 := operator(1, 2, addNums)
fmt.Println(res1)
res2 := operator(1, 2, sub)
fmt.Println(res2)
res3 := operator(1, 2, mul)
fmt.Println(res3)
//除法:直接传一个匿名函数
res4 := operator(8, 2, func(a int, b int) int {
if b == 0 {
fmt.Println("除数不能为0")
return 0
}
return a / b
})
fmt.Println(res4)
}
// 高阶函数,接收了一个函数作为参数的函数
func operator(a, b int, fun func(int, int) int) int {
sum := fun(a, b)
return sum
}
// 回调函数,作为另外一个函数的参数
func addNums(a, b int) int {
return a + b
}
// 回调函数,作为另外一个函数的参数
func sub(a, b int) int {
return a - b
}
// 回调函数,作为另外一个函数的参数
func mul(a, b int) int {
return a * b
}
输出
3
3
-1
2
4
4.10 闭包
一个外层函数中,有内层函数,该内层函数中,会操作外层函数的局部变量,并且该外层函数的返回值就是这个内层函数。这个内层函数和外层函数的局部变量,统称为闭包结构
局部变量的生命周期就会发生改变,正常的局部变量会随着函数的调用而创建,随着函数的结束而销毁;但是闭包结构中的外层函数的局部变量并不会随着外层函数的结束而销毁,因为内层函数还在继续使用
package main
import "fmt"
func main() {
//返回一个函数res1
res1 := increment()
fmt.Println("res1函数:", res1) //返回的是一个匿名函数(即内层函数,但是还没有执行)
v1 := res1() //执行内层函数
fmt.Println("res1函数返回值:", v1)
v2 := res1()
fmt.Println("res1函数返回值:", v2)
//返回一个函数res2
res2 := increment()
fmt.Println("res2函数:", res2) //返回的是一个匿名函数(即内层函数,但是还没有执行)
v3 := res2() //执行内层函数
fmt.Println("res2函数返回值:", v3)
//分析:闭包结构中的外层函数的局部变量并不会随着外层函数的结束而销毁,因为内层函数还在继续使用(因为它有回调函数)
fmt.Println("res1函数返回值:", res1())
v4 := res2()
fmt.Println("res2函数返回值:", v4)
}
// 自增
func increment() func() int {
//局部变量
i := 0
fun := func() int { //内层函数,只是定义了并没有执行
i++
return i
}
return fun
}
输出
res1函数: 0x74e8a0
res1函数返回值: 1
res1函数返回值: 2
res2函数: 0x74e880
res2函数返回值: 1
res1函数返回值: 3
res2函数返回值: 2
五、泛型
Go并不是一种静止的、一成不变的编程语言。新的功能是在经过大量的讨论和实验后慢慢采用的。
最初的Go1.0发布以来,Go语言习惯的模式已经发生了重大变化
1.7的context、1.11的modules、1.13error嵌套等
Go的 1.18 版本包括了类型参数的实现,也就是俗称的泛型
泛型虽然很受期待,但实际上推荐的使用场景也并没有那么广泛
但是我们作为学习者,一定要了解学会,遇到了至少不懵逼!
5.1 什么是泛型
package main
import "fmt"
func main() {
//声明一个数组并打印输出
var arr [4]int = [4]int{1, 2, 3, 4}
for i := 0; i < len(arr); i++ {
fmt.Println(arr[i])
}
fmt.Println("======================")
//声明一个切片(可变长数组:不确定数组大小的数组)并打印输出
var slice []int = []int{1, 2}
for i := 0; i < len(slice); i++ {
fmt.Println(arr[i])
}
fmt.Println("======================")
//利用函数进行打印
strs := []string{"Hello World!"}
//printArray(str) //尝试1———失败!:cannot use str (variable of type []string) as type []interface{} in argument to printArray
printStringArray(strs) //尝试2:打印[]string类型数组——成功!
ints := []int{1, 2} //尝试2:打印[]int类型数组——失败!编译不报错,运行报错:panic: interface conversion: interface {} is []int, not []string
//printStringArray(ints) //尝试2:打印[]int类型数组——失败!
fmt.Println("======================")
printStringIntArray(strs) //尝试3:使用泛型——成功!
printStringIntArray(ints) //尝试3:使用泛型——成功!
}
// 引入泛型:
// 尝试1:让传入的数组是任意类型的:arr []interface{}———失败!
func printArray(arr []interface{}) {
for _, v := range arr {
fmt.Println(v)
}
}
// 尝试2:类型断言:只能打印指定类型的数组,需要做不同的适配,比较麻烦————成功!
func printStringArray(arr interface{}) {
//类型断言:X.(T) 其实就是判断 T 是否实现了 X 接口;如果实现了,就把 X 接口类型具体化为 T 类型
for _, v := range arr.([]string) {
fmt.Println(v)
}
}
// 尝试3:泛型:我们不限定它的类型,让调用者自己去定义类型
// printAllArray[T string | int]:函数名后面的,[T string | int]是泛型约束,指定可以打印什么类型的泛型
/*
内置的泛型类型any和comparable:
any: 表示go里面所有的内置基本类型,等价于 interface{}
comparable: 表示go里面所有内置的可比较类型:基本数据类型+派生数据类型
*/
// arr []T:[]T 是形式类型,实际传入的是实际类型(跟形参和实参是一样的道理)
func printStringIntArray[T string | int](arr []T) {
for _, v := range arr {
fmt.Println(v)
}
}
// T any: any, 表示go里面所有的内置基本类型,等价于 interface{}
func printAnyArray[T any](arr []T) {
for _, v := range arr {
fmt.Println(v)
}
}
// comparable: 表示go里面所有内置的可比较类型:基本数据类型+派生数据类型
func printComparableArray[T comparable](arr []T) {
for _, v := range arr {
fmt.Println(v)
}
}
输出
1
2
3
4
======================
1
2
======================
Hello World!
======================
Hello World!
1
2
小结:泛型的作用
泛型减少重复代码并提高类型安全性
在下面的情景的时候非常适合使用泛型:当你需要针对不同类型书写同样的逻辑,使用泛型来简化代码是最好的
5.2 定义泛型类型
观察下面这个简单的例子:
type s1 []int
var a s1 = []int{1,2,3} //正确
var b s1 = []float{1.0,2.0,3.0} //错误,因为IntSlice的底层类型是[]int,浮点类型的切片无法赋值
这里定义了一个新的类型intSlice,它的底层类型是 []int,理所当然只有int类型的切片能赋值给 IntSlice 类型的变量。
接下来如果我们想要定义一个可以容纳 float32 或 string 等其他类型的切片的话该怎么办?很简单,给每种类型都定义个新类型
type s1 []int
type s2 []float32
type s3 []float64
但是这样做的问题显而易见,它们结构都是一样的只是成员类型不同就需要重新定义这么多新举型。
那么有没有一个办法能只定义一个举型就能代表上面这所有的类型呢?答案是可以的,这时候就需要用到泛型了:
type Slice[T any] []T
type Slice[T int|float32|float64] []T
不同于一般的类型定义,这里类型名称 Slice 后带了中括号,对各个部分做一个解说就是:
-
T 就是上面介绍过的类型形参(Type parameter),在定义Slice类型的时候 T 代表的具体类型并不确定,类似一个占位符
-
int|float32|float64这部分被称为类型约束(Type constraint,中间的 | 的意思是告诉编器,类型形参只可以接收 int 或float32或float64 这三种类型的实参
-
中括号里的 T int|float32|float64 这一整串因为定义了所有的类型形参(在这个例子里只有一个类型形参T),所以我们称其为 类型形参列表(type parameter list)
-
这里新定义的类型名称叫 Slice[T]
内置的泛型类型any和comparable:
any: 表示go里面所有的内置基本类型,等价于 interface{}
comparable: 表示go里面所有内置的可比较类型:基本数据类型+派生数据类型
这种类型定义的方式中带了类型形参,很明显和普通的类型定义非常不一样,所以我们将这种类型定义中带 类型形参 的类型,称之为 泛型类型
package main
import "fmt"
func main() {
//定义一个泛型类型Slice[T],格式:type 泛型名[T 类型约束] 类型
type Slice[T int | float32 | float64] []T //[]T:表示数组类型
var a Slice[int] = []int{1, 2, 3}
fmt.Printf("Type name:%T", a) //输出:Type name:main.Slice[int] 分析:赋值给它什么类型就是什么类型
fmt.Println()
for _, v := range a {
fmt.Println(v)
}
fmt.Println("=======================")
var b Slice[float32] = []float32{1, 2, 3}
fmt.Printf("Type name:%T", b) //输出:Type name:main.Slice[float32] 分析:赋值给它什么类型就是什么类型
fmt.Println()
for _, v := range b {
fmt.Println(v)
}
// × 错误:因为变量a的类型是 Slice[int],b的类型是 Slice[float32],两者类型不同
//a = b
// × 错误:Slice[T]是泛型类型,不可直接使用必须实例化为具体的类型
//var c Slice[T] = []float64{1, 2, 3}
fmt.Println("=======================")
type MyMap[KEY int | float32, VALUE string] map[KEY]VALUE
var mymap MyMap[int, string] = map[int]string{
1: "Go", 2: "JAVA",
}
fmt.Println(mymap)
}
输出
Type name:main.Slice[int]
1
2
3
=======================
Type name:main.Slice[float32]
1
2
3
=======================
map[1:Go 2:JAVA]
解析:
KEY和VALUE是类型形参
int|float32是KEY的类型约束,string是VALUE的类型约束
KEY int | float32, VALUE string 整个一串文本因为定义了所有形参所以被称为类型形参列表Map[KEY,VALUE] 是泛型类型,类型的名字就叫 Map[KEY,VALUE]
var mymap MyMap[int, string] = xx 中的int和string是类型实参,用于分别替换KEY和VALUE,实例化出了具体的类型 MyMap[int,string]
所有类型定义都可使用类型形参,所以下面这种结构体以及接口的定义也可以使用类型参数
//一个泛型类型的结构体。可用 int 或 string 类型实例化
type Mystruct[T int|string] struct {
Id T //1 uuid
name string
}
//一个泛型接口
type IPrintData[T int|float32|string] interface {
Print(data T)
}
//一个泛型通道,可用类型实参 int 或 string 实例化
type MyChan[T int|string] chan T
特殊的泛型类型
这里讨论种比较特殊的泛型类型,如下:
//特殊的泛型类型
type Wow[T int | string] int
var w1 Wow[int] = 123 // 编译正确
fmt.Println(w1)
var w2 Wow[string] = 123 // 编译正确
fmt.Println(w2)
//var w3 Wow[string] = "he11o" // 编译错误,因为"hel1o"不能赋值给底层类型int
输出:
123
123
这里虽然使用了类型形参,但因为类型定义是 type Wow[T int | string] int ,所以无论传入什么类型实参,实例化后的新类型的底层类型都是int。所以int类型的数字123可以赋值给变量a和b,string类型的字符串“hello”不能赋值给c
这个例子没有什么具体意义,但是可以让我们理解泛型类型的实例化的机制
5.3 泛型函数
// Add 泛型函数
func Add[T int | float64 | string](a T, b T) T {
return a + b
}
这种带类型形参的函数被称为泛型函数
它和普通函数的点不同在于函数名之后带了类型形参。这里的类型形参的意义、写法和用法因为与泛型类型是一模一样的,就不再赘述了和泛型类型一样,泛型函数也是不能直接调用的,要使用泛型函数的话必须传入类型实参之后才能调用。
package main
import "fmt"
// MySlice 定义一个自己的切片类型
type MySlice[T int | float64] []T
func main() {
//泛型方法
var s MySlice[int] = []int{1, 2, 3}
fmt.Println(s.Sum())
fmt.Println("================")
//泛型函数
fmt.Println(Add[int](1, 2))
//可自动推导类型
fmt.Println(Add(1, 2))
fmt.Println(Add[string]("Hello ", "World"))
//可自动推导类型
fmt.Println(Add("Hello ", "World"))
}
// Sum 给泛型添加方法
func (s MySlice[T]) Sum() T {
var sum T
for _, v := range s {
sum += v
}
return sum
}
/*func Add(a,b int) int{
return a+b
}*/
// Add 泛型函数
func Add[T int | float64 | string](a T, b T) T {
return a + b
}
或许你会觉得这样每次都要手动指定类型实参太不方便了。所以Go还支持类型实参的自动推导:
fmt.Println(Add[int](1, 2))
//可自动推导类型
fmt.Println(Add(1, 2))
fmt.Println(Add[string]("Hello ", "World"))
//可自动推导类型
fmt.Println(Add("Hello ", "World"))
自动推导的写法就好像免去了传入实参的步骤一样,但请记住这仅仅只是编译器帮我们推导出了类型实参,实际上传入实参步骤还是发生了的
Go的泛型(或者类型形参)目前可使用在3个地方
1、泛型类型-类型定义中带类型形参的类型
2、泛型receiver-泛型类型的receiver(即,给泛型增加方法)
3、泛型函数 带类型形参的函数
5.4 自定义泛型类型
如果类型太多了怎么办呢?这时候我们就可以自定义泛型类型
package main
import "fmt"
type newInt8 int8 //自定义类型名:给类型起一些别名
// MyInt 自定义泛型约束:像声明接口一样声明,叫做泛型的约束
type MyInt interface {
//int | int8 | int16 | int32 | int64 //不写newInt8就会报错
//方式一:直接添加newInt8
//int | int8 | int16 | int32 | int64 | newInt8
//方式二: ~int8,在某个类型前面加上~,表示支持它的所有衍生类型(newInt8就属于int8的衍生类型)
int | ~int8 | int16 | int32 | int64
}
// T的类型为声明的MyInt
func getMaxNum[T MyInt](a, b T) T {
if a > b {
return a
}
return b
}
func main() {
fmt.Println(getMaxNum(2, 5)) //自动推导
fmt.Println(getMaxNum[int](2, 5))
fmt.Println()
var a newInt8 = 2
var b newInt8 = 4
fmt.Println(getMaxNum[newInt8](a, b))
}
输出
5
5
4