目录
一、思路
二、工具
三、代码处理
第一部分:发起请求+接收响应(不过多讲)
第二部分:解析HTML页面+提取数据
第三部分:处理数据
一、思路
分解步骤,化繁为简
爬虫分为五步走:
-
发起HTTP请求:爬虫使用HTTP协议向目标网址发送请求,请求获取特定的HTML页面。这可以通过使用编程语言中的HTTP库(例如Python中的requests库)来实现。
-
接收HTTP响应:目标服务器接收到请求后,将返回一个HTTP响应。该响应包含了所请求的HTML页面内容。
-
解析HTML页面:爬虫需要解析HTML页面以提取所需的数据。这可以通过使用HTML解析库(例如Python中的Beautiful Soup库或lxml库)来实现。
-
提取数据:一旦HTML页面被解析,爬虫可以根据特定的选择器或XPath表达式来提取所需的数据。这些选择器或表达式可以帮助定位和提取HTML页面中的元素,如标题、链接、文本等。
-
处理数据:在提取数据后,爬虫可以对数据进行进一步处理、清洗或存储,以便后续分析或展示。
二、工具
解析数据的工具:如xpath、Beautiful Soup、正则表达式等很多
1、安装Beautiful Soup
是 Python 的一个第三方库,可以用来解析网页数据
pip3 install beautifulsoup4官方文档:https://beautifulsoup.readthedocs.io/zh_CN/latest/

2、安装 lxml
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式
pip3 install lxml
三、代码处理
第一部分:发起请求+接收响应(不过多讲)
import requests
if __name__ == '__main__':
url1="https://beautifulsoup.readthedocs.io/zh_CN/latest/"
req=requests.get(url=url1)
req.encoding='utf-8'
print(req.text)
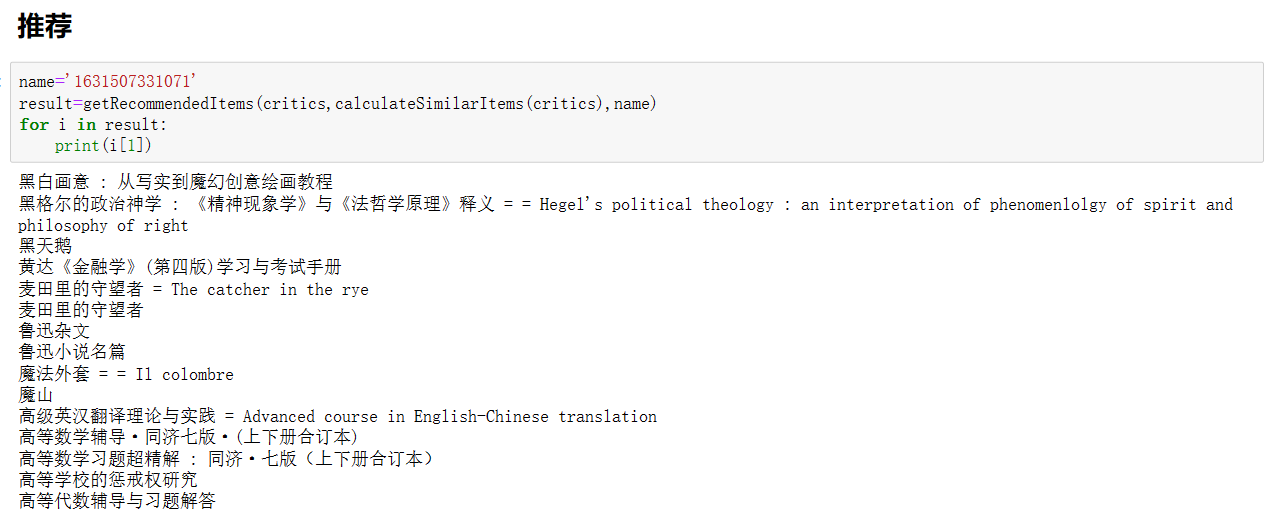
第二部分:解析HTML页面+提取数据
我们关心的数据都在标签里面
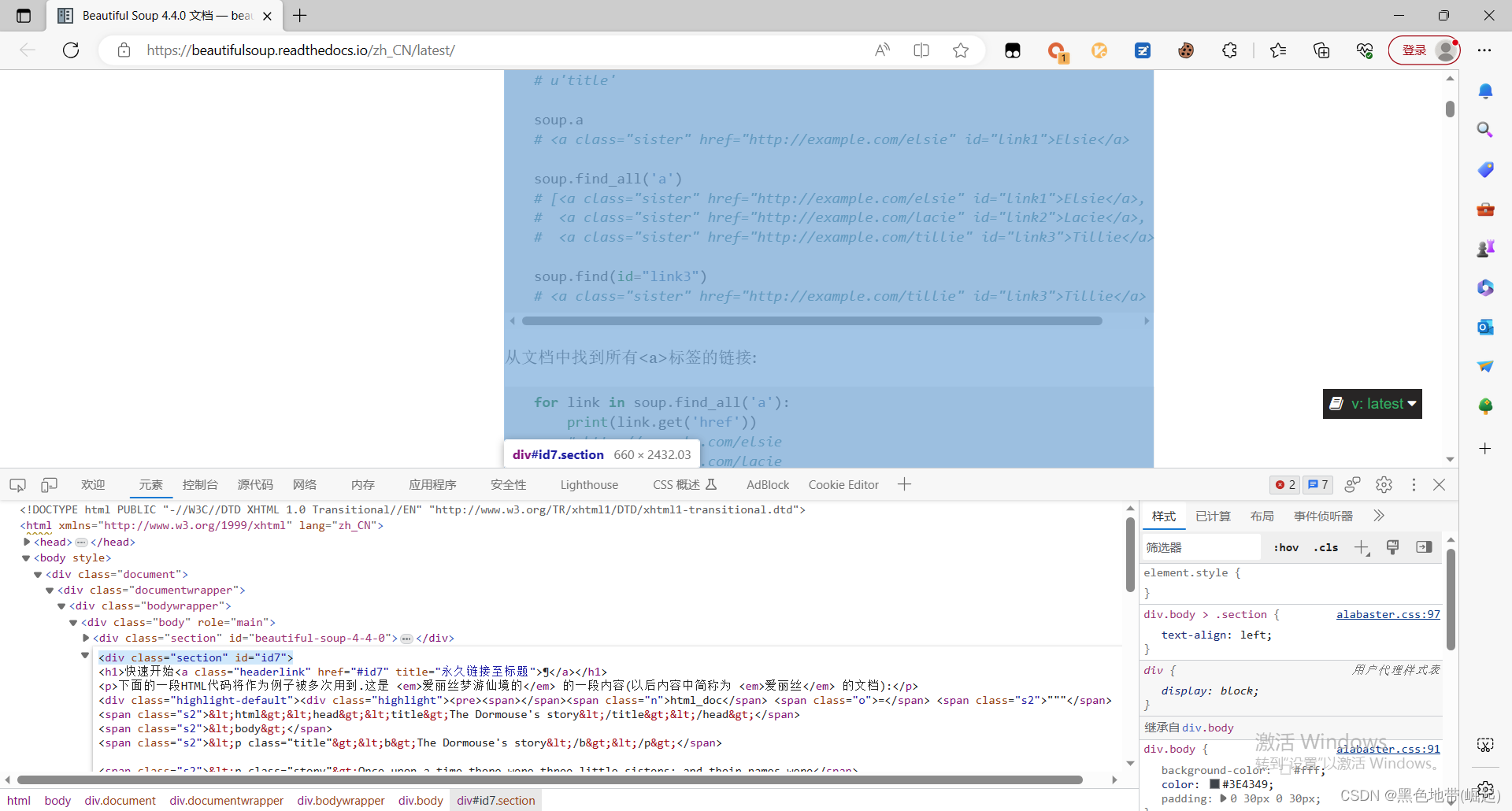
<div class="section" id="id7">
div 标签的属性有class、id
属性值分别为:section、id7
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
url = "https://beautifulsoup.readthedocs.io/zh_CN/latest/"
req = requests.get(url)
req.encoding = 'utf-8'
html = req.text # 将获取到的网页内容保存到变量html中
bs = BeautifulSoup(html, 'lxml')
text = bs.find('div',id="id7")
print(text)
第三部分:处理数据
(1)做到所有最小单位的数据所在的上一级标签

(2)找到每个最小单位的数据所处的同一级标签
(3)分析最小单位标签内的详细信息所在标签
(4)完整代码:
(为了方便大家一步一步来,很多地方没最优化)
import re
import requests
from bs4 import BeautifulSoup
def get_TYC_info():
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36'}
html = get_page(TYC_url)
soup = BeautifulSoup(html, 'lxml')
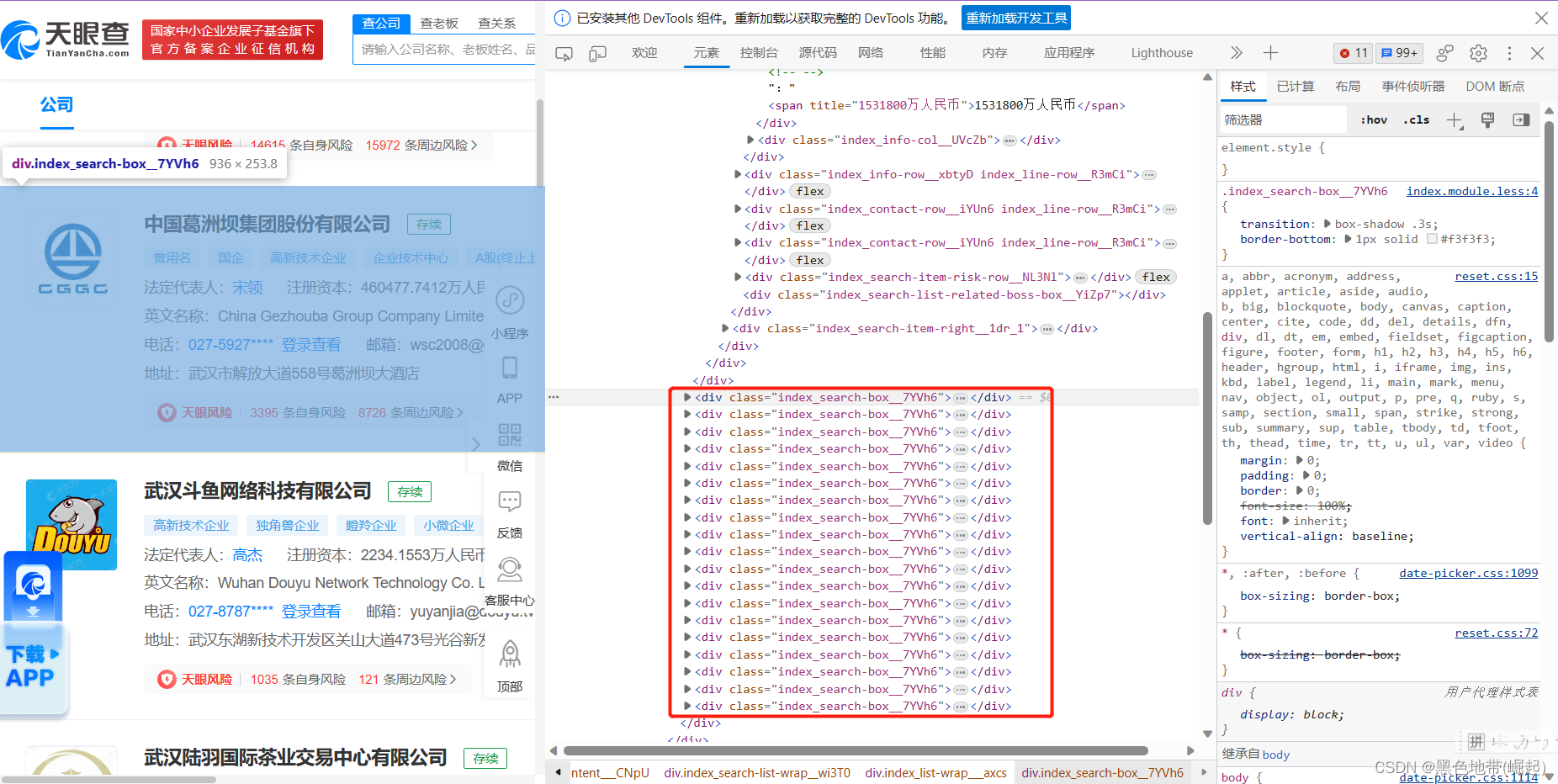
GS_list = soup.find('div', attrs={'class': 'index_list-wrap___axcs'})
GS_items = GS_list.find_all('div', attrs={'class': 'index_search-box__7YVh6'})
for item in GS_items:
title = item.a.text.replace(item.a.span.text, "")
link = item.a['href']
company_type = item.find('div', attrs={'class': 'index_tag-list__wePh_'}).find_all('div', attrs={'class': 'index_tag-common__edIee'})[0].text
money = item.find('div', attrs={'class': 'index_info-col__UVcZb index_narrow__QeZfV'}).span.text
print(title.strip())
print(link)
print(company_type)
print(money)
def get_page(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36'}
response = requests.get(url, headers=headers, timeout=10)
return response.text
except:
return ""
if __name__ == '__main__':
TYC_url = "https://www.tianyancha.com/search?key=&base=hub&city=wuhan&cacheCode=00420100V2020&sessionNo=1688108233.45545222"
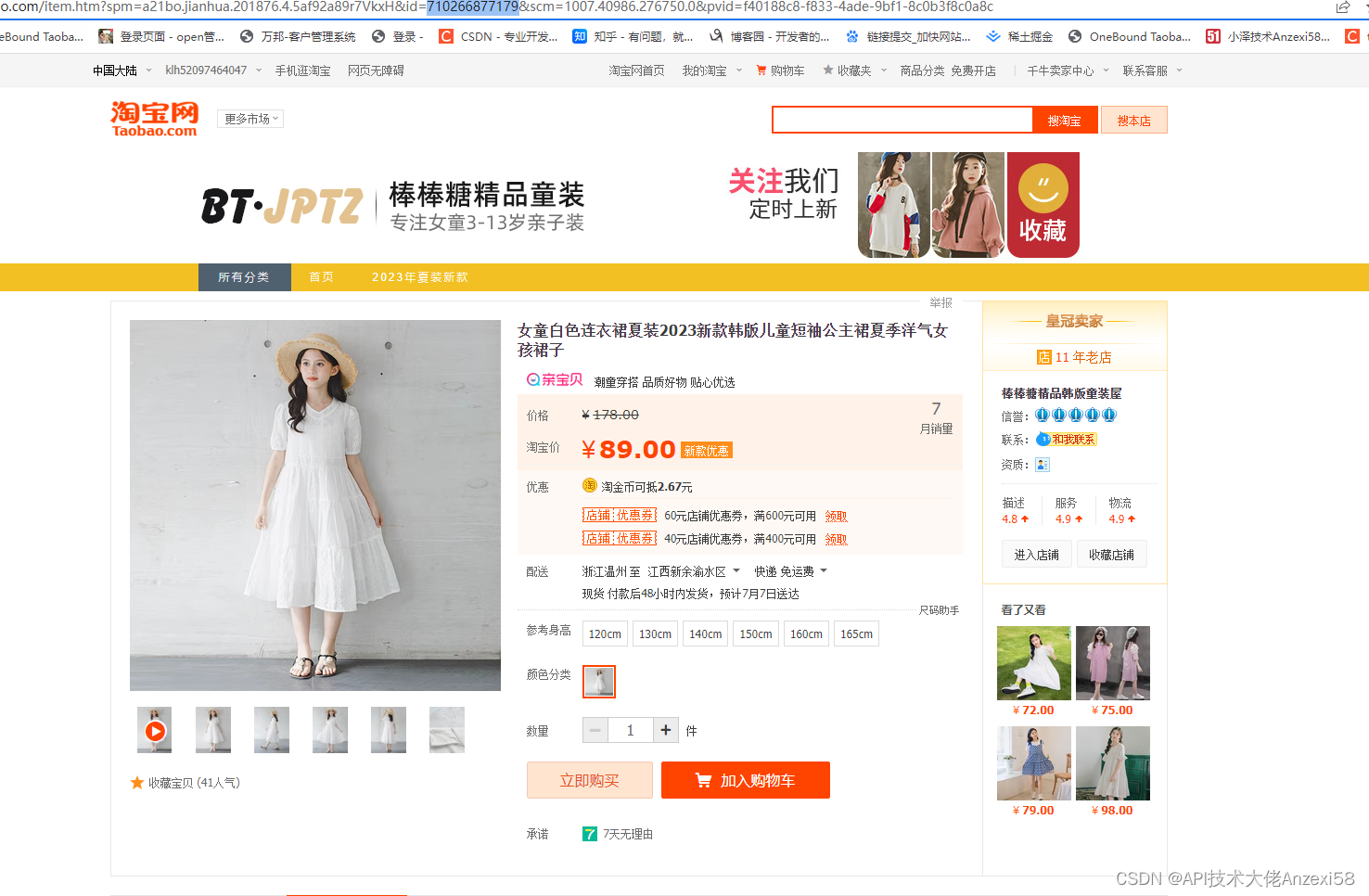
get_TYC_info()结果如图:
(5)逐行解释
1、导入了需要使用的模块:re用于正则表达式操作,requests用于发送HTTP请求,BeautifulSoup用于解析HTML。
import re
import requests
from bs4 import BeautifulSoup
2、自定义一个函数get_TYC_info(),用于获取天眼查(TYC)的信息
def get_TYC_info():3、定义了请求头(headers),以模拟浏览器发送请求。
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36'}4、调用自定义的get_page()函数,将TYC_url作为参数传递给它,并将返回的HTML内容赋值给变量html
html = get_page(TYC_url)5、使用BeautifulSoup模块解析HTML,创建一个BeautifulSoup对象soup,参数'lxml'表示使用lxml解析器。
soup = BeautifulSoup(html, 'lxml')6、从解析后的HTML中找到class属性为index_list-wrap___axcs的div元素,并将其赋值给变量GS_list
GS_list = soup.find('div', attrs={'class': 'index_list-wrap___axcs'})7、从GS_list中找到class属性为index_search-box__7YVh6的所有div元素,并将它们存储在列表GS_items中
GS_items = GS_list.find_all('div', attrs={'class': 'index_search-box__7YVh6'})8、遍历GS_items列表,对于每个元素,提取标题、链接、公司类型和金额信息,并打印输出。其中,title通过替换掉item.a下的span标签内的文本为空字符串来获得。link是item.a标签的href属性值。company_type通过在item内进行查找,找到class属性为index_tag-list__wePh_的div元素,然后在这个div元素下的所有class属性为index_tag-common__edIee的div元素中获取第一个元素的文本内容。money通过在item内进行查找,找到class属性为index_info-col__UVcZb index_narrow__QeZfV的div元素,然后获取其中的span标签的文本内容。
for item in GS_items: title = item.a.text.replace(item.a.span.text, "")
link = item.a['href']
company_type = item.find('div', attrs={'class': 'index_tag-list__wePh_'}).find_all('div', attrs={'class': 'index_tag-common__edIee'})[0].text
money = item.find('div', attrs={'class': 'index_info-col__UVcZb index_narrow__QeZfV'}).span.text print(title.strip())
print(link)
print(company_type)
print(money)9、自定义了一个名为get_page()的函数,用于发送HTTP请求并返回响应的HTML内容。
def get_page(url):10、在get_page()函数内部,首先定义了请求头(headers),然后使用requests模块发送GET请求,传递URL和请求头,并设置超时时间为10秒。如果请求成功,返回响应的HTML内容;如果出现异常,则返回
try:
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36'}
response = requests.get(url, headers=headers, timeout=10)
return response.text
except:
return ""11、入口程序
if __name__ == '__main__':
TYC_url = "https://www.tianyancha.com/search?key=&base=hub&city=wuhan&cacheCode=00420100V2020&sessionNo=1688108233.45545222"
get_TYC_info()