TDsql增量merge导入load_data
项目组最近用了腾讯的TencentDB分布式数据库作为传统关系型数据库来保存少量应用数据。因此需要开发相对应的ETL功能代码,根据新数据库特性,使用自带的工具load_data作为导入的工具
准备表
使用load_data导入的表,必须要有主键,不然replace或者说mode3替换模式无法识别,最终导致导入的时候会数据重复
Create table default.testA(
Id decimal(1),
Name varchar(10),
Primary key(id)
);
准备数据
Insert into default.testA values(1,’tony’);
Insert into default.testA values(2,’tom’);
Insert into default.testA values(3,’tata’);
Insert into default.testA values(4,’tang’);

准备测试文件
-
新增一条不重复的文件按记录
/home/zhouchen/testFileAdd.txt
5|tim -
新增四条记录,分别是需要更新,插入,去重
/home/zhouchen/testFileMerge.txt
1|chew
5|tim
6|tingting
6|tingting
自增导入
load_data mode3 --ip=${TDSQL_HOST} --port=${TDSQL_PORT} --user=${TDSQL_USER} --password=${TDSQL_PSWD} --db_name=default.testA
–file= /home/zhouchen/testFileAdd.txt
–field_terminated=”|”
–lines_terminated=”\n”
–chunk_size=512
–replace_duplicates=true
–skip_error=true
参数说明:
- mode0:load_data的原理是分割数据,然后导入数据,mode0是先分割数据不进行导入。
- mode0:只分割数据,不进行导入,一般用于调试。
- mode1:分割数据,然后对应load data语句中IGNORE模式导入数据,正式导入数据使用 mode1 指令。
- mode2:在mode1基础上,忽略导入行错误,继续导入。
- mode3:分割数据,然后对应load data语句中REPLACE模式导入数据。
- mode4:在mode2基础上,忽略导入行错误,继续导入。
- chunk_size: 导入块大小(KB),默认值为与文件大小相关的一个分段函数,当设置的chunk_size<=1280k时,其都是以128k运行的
- replace_duplicates: 是否开启替换模式,替换已存在的记录
- skip_error: 是否跳过错误,即当发生错误时,是停止导入(0)还是跳过错误(1)
导入结果:
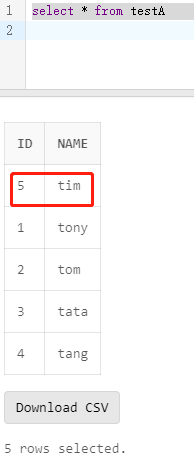
merge导入
load_data mode3 –ip=
T
D
S
Q
L
H
O
S
T
–
p
o
r
t
=
{TDSQL_HOST} –port=
TDSQLHOST–port={} –user=
–
p
a
s
s
w
o
r
d
=
{} –password=
–password={} –db_name= default.testA
–file= /home/zhouchen/testFileAdd.txt
–field_terminated=”|”
–lines_terminated=”\n”
–chunk_size=512
–replace_duplicates=true
–skip_error=true
导入结果:
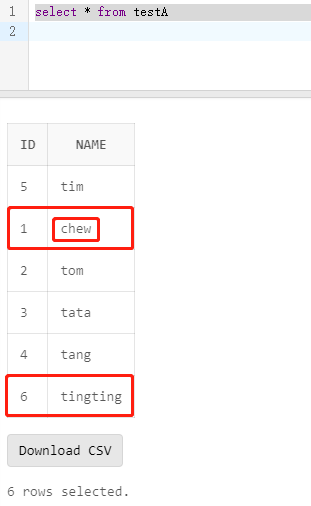
总结
使用TDsql自带的load_data导入数据的时候,使用replace模式配置skip_error可以实现merge导入:
- 根据id主键update数据1的name值为chew;
- 去重两条id为5的数据;
- 新增导入id为5的数据和id为6的数据;