欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文来介绍 实战TensorRT部署DETR。
本文介绍的实战 TensorRT 部署 DETR,提供完整的可以一键执行的项目工程源码,获取方式有两个:
(1) 本文工程项目资源下载,链接:https://download.csdn.net/download/weixin_42405819/87997220
(2) 【推荐】加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码下载,链接:https://t.zsxq.com/0aiNxERDq
本文的部署方法主要借助 yolov7_d2 仓库中一些工具,整理了项目代码和一些一键执行的脚本,配合本文中的实战步骤进行介绍,尽可能让大家踩更加少的坑获得跟我一样的效果。
在部署开始之前,先把依赖装上:
conda create -n yolov7_detr_py38 python=3.8
conda activate yolov7_detr_py38
pip install -i https://pypi.douban.com/simple opencv-python rich timm scipy onnx onnxruntime nbnb onnx_graphsurgeon onnx-simplifier
pip install torch torchvision在项目的 weights 目录里,已经下载好了原始的 detr-r50 的 pth 权重文件,但是这个权重不是基于 detection2 的,需要转换一下:
# run_convert_to_detr_r50.sh
python tools/convert_detr_to_d2.py --source_model weights/detr-r50-dc5-f0fb7ef5.pth --output_model weights/detr-r50.pth这里直接执行 run_convert_to_detr_r50.sh 就行,输出的部分日志如下:
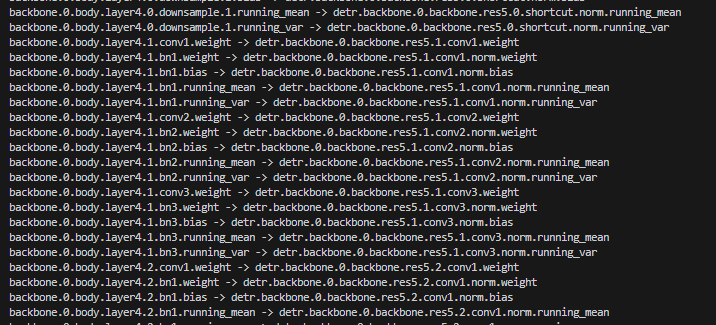
转换完了之后就会按脚本的输出指定获得一个名为 detr-r50.pth 的权重,但是现在你可能并不知道这个权重是否是有效的,可以用项目里的 demo.py 来验证一下,采用如下命令:
# run_detr_py_demo.sh
python demo.py --config-file configs/coco/detr/detrt_256_6_6_torchvision.yaml --input ./images -c 0.26 --opts MODEL.WEIGHTS weights/detr-r50.pth在执行这个脚本的时候 run_detr_py_demo.sh 可能会报错:ModuleNotFoundError: No module named 'detectron2',意思是需要先安装 detectron2 模块,用下面的方式进行安装:
# git clone https://github.com/facebookresearch/detectron2.git # 项目中已有
python -m pip install -i https://pypi.douban.com/simple -e detectron2然后还会继续报错 ModuleNotFoundError: No module named 'alfred',继续安装:
# git clone https://github.com/lucasjinreal/alfred.git # 项目中已有
cd alfred
python setup.py install继续执行验证脚本 run_detr_py_demo.sh,正确执行后输出如下:


可以看到输出是准确的。
话说回来,到这里好像咱们已经做了挺多,但是其实还是啥也没做,下面才是真正的开始。这里的 TensorRT 部署 DETR 的链路是:pytorch -> onnx -> tensorrt。
首先要做的就是要导出 DETR 的 onnx 模型。
这里还要再安装一下依赖:
pip install TensorRT-8.6.1.6/onnx_graphsurgeon/onnx_graphsurgeon-0.2.6-py2.py3-none-any.whl导出 onnx 模型:
# run_export_detr_onnx.sh
python export_onnx.py --config configs/coco/detr/detrt_256_6_6_torchvision.yaml --input ./images/COCO_val2014_000000002153.jpg --opts MODEL.WEIGHTS weights/detr-r50.pth 直接执行 run_export_detr_onnx.sh,就会在 weights 目录下得到 detr-r50.onnx、detr-r50_sim.onnx、detr-r50_sim.onnx_changed.onnx 三个 onnx 模型,很明显转换过程中用到了大老师的 onnx-sim 工具进行了简化,用 netron 打开最终的 detr-r50_sim.onnx_changed.onnx 模型后会发现它长得十分美丽,下面可窥探一斑:
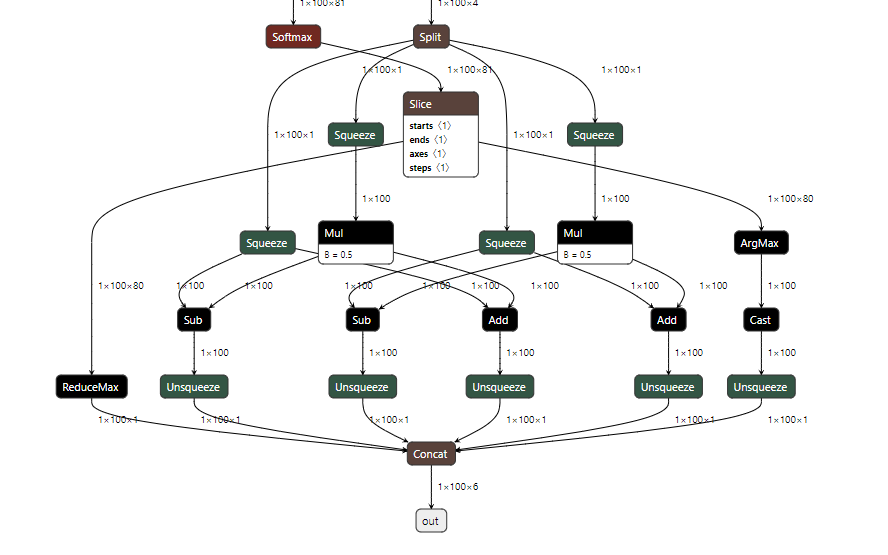
有了优化好了的 onnx 模型之后,咱们就可以采用 TensorRT 的 trtexec 工具转换为 TensorRT 的 plan 文件了。这里其实会有两个简单的方式进行模型转换,一个是直接采用 TensorRT tar 包里的 trtexec 工具,另外一个是采用 onnx2trt 工具,关于 onnx2trt 的编译可以查看我的文章:《极智开发 | ubuntu源码编译onnx2trt》。但是需要注意的是,不管采用哪个工具,这里会对对 TensorRT 的版本要求都比较严苛,都要求比较高,我尝试过 TensorRT7 和 TensorRT8.2,都是不行的,采用最新版的 TensorRT8.6 验证是可以的,所以在我提供的工程中也已经放了 TensorRT8.6 的 tar 包。这里的工程中,我采用了 trtexec 的方式进行模型转换,采用这个方式还会自动进行推理性能的测试。
# run_export_trt_plan.sh
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$PWD/TensorRT-8.6.1.6/lib
./TensorRT-8.6.1.6/bin/trtexec --onnx=./weights/detr-r50.onnx --saveEngine=weights/detr-r50.trt执行 run_export_trt_plan.sh,正确转换获得如下输出:
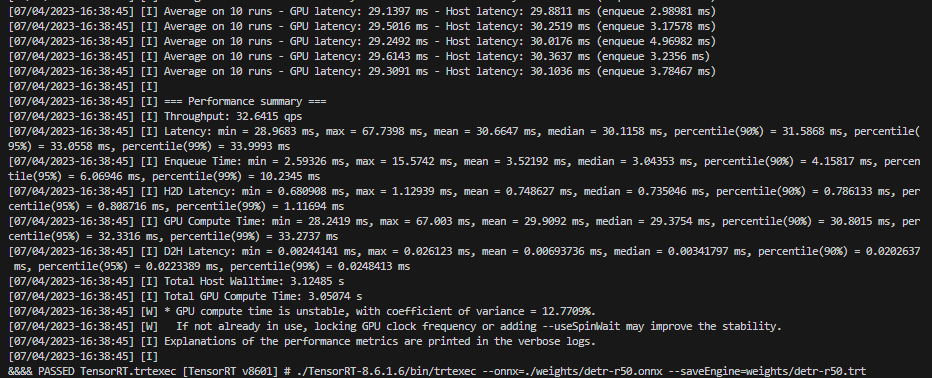
来看下推理耗时:
[07/04/2023-16:38:45] [I] GPU Compute Time: min = 28.2419 ms, max = 67.003 ms, mean = 29.9092 ms, median = 29.3754 ms, percentile(90%) = 30.8015 ms, percentile(95%) = 32.3316 ms, percentile(99%) = 33.2737 ms可以看到平均耗时是 29.9092ms,我的显卡是 RTX2060,batch 是单图,这个速度你能接受吗。其实我们可以简单优化一下,让它采用 fp16 进行推理,脚本如下:
# run_export_trt_plan_fp16.sh
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$PWD/TensorRT-8.6.1.6/lib
./TensorRT-8.6.1.6/bin/trtexec --onnx=./weights/detr-r50.onnx --saveEngine=weights/detr-r50.trt --fp16直接执行 run_export_trt_plan_fp16.sh,正确执行获得如下输出:
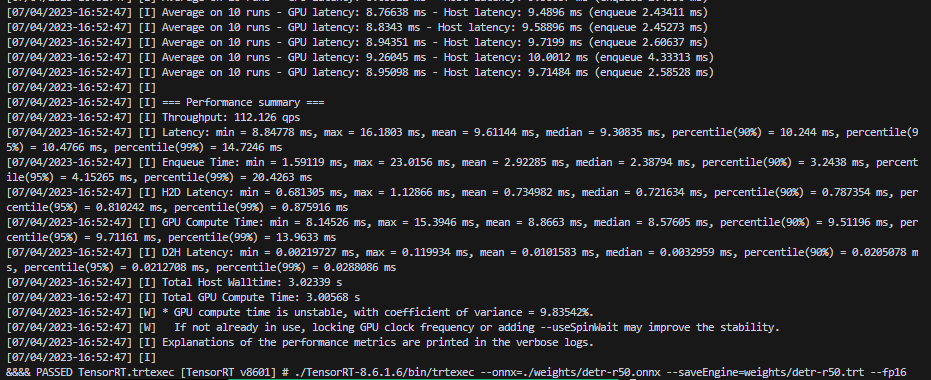
来看下 fp16 的推理耗时:
[07/04/2023-16:52:47] [I] GPU Compute Time: min = 8.14526 ms, max = 15.3946 ms, mean = 8.8663 ms, median = 8.57605 ms, percentile(90%) = 9.51196 ms, percentile(95%) = 9.71161 ms, percentile(99%) = 13.9633 ms可以看到单图推理性能提升地十分明显,从 fp32 的 29ms 提升到了 fp16 的 8.8ms。这其实可以很明显看出,低比特对于推理加速的重要性。更进一步地,其实还可以进行 int8 的推理,性能应该还会进一步提升。
到这里其实已经到达了 pytorch -> onnx -> trt -> 性能测试 的目的了,但是要说是完整的部署 DETR,其实还需要写一个调用 trt 模型进行精度测试的工程,这个主要还涉及前处理后处理,还是稍微有点复杂,考虑到篇幅这篇就先到这了,后续会提供 DETR 精度测试的项目工程,敬请期待。
好了,以上分享了 实战TensorRT部署DETR。希望我的分享能对你的学习有一点帮助。
【极智视界】
《极智项目 | 实战TensorRT部署DETR》
畅享人工智能的科技魅力,让好玩的AI项目不难玩。邀请您加入我的知识星球,星球内我精心整备了大量好玩的AI项目,皆以工程源码形式开放使用,涵盖人脸、检测、分割、多模态、AIGC、自动驾驶、工业等。不敢说会对你学习有所帮助,但一定非常好玩,并持续更新更加有趣的项目。https://t.zsxq.com/0aiNxERDq