Bert:Bidirectional Encoder Representations from Transformers
Transformer中双向Encoder表达学习。BERT被设计为通过在所有层中对左右上下文进行联合调节,从未标记文本中预训练深度双向表示。预训练的BERT模型可以通过仅一个额外的输出层进行微调,从而为广泛的任务创建最先进的模型。Bert paper
借鉴CV中的大规模预训练然后进行迁移学习就能得良好的效果,因此BERT也是两部分,预训练,然后微调。在预训练中,模型在不同任务无标签的数据上进行。微调则是以预训练的参数进行初始化,然后再用下游任务有标签的数据进行训练。每个下游任务都有各自微调的模型,尽管他们初始化时用的同样预训练参数。如下则是示例:

可见除了输出层,预训练模型和微调模型使用的结构都是一样的,CLS是每个句子/输入开头都有的特殊符号(huggingface中说为分类器token,The classifier token which is used when doing sequence classification (classification of the whole sequence instead of per-token classification). It is the first token of the sequence when built with special tokens.) ,SEP则是分隔符。
attention is all you need:此paper中Transformer的结构也是BERT的基本结构,BERT base模型恰好是12层(也就是L=12,encoder 6层,decoder 6层??存疑哈),隐层参数H=768,self-attention head有12个,A=12,头还挺多的。总参数110M,bert-large L=24层(猜测encoder和decoder各12层),H=1024,A=16,总参数340M。Bert-base大小是为了与OpenAI,GPT对比。严格的说,Bert 的Transformer结构中使用的双向self-attention,而GPT的Transformer是使用的受限的self-attention,也就是说每个token只能与它左边的context进行attention。本文中注释为:前者这种双向的attention是Transformer encoder,而后者只能左边attention的记为Transformer decoder(因为它能用于文本生成)。
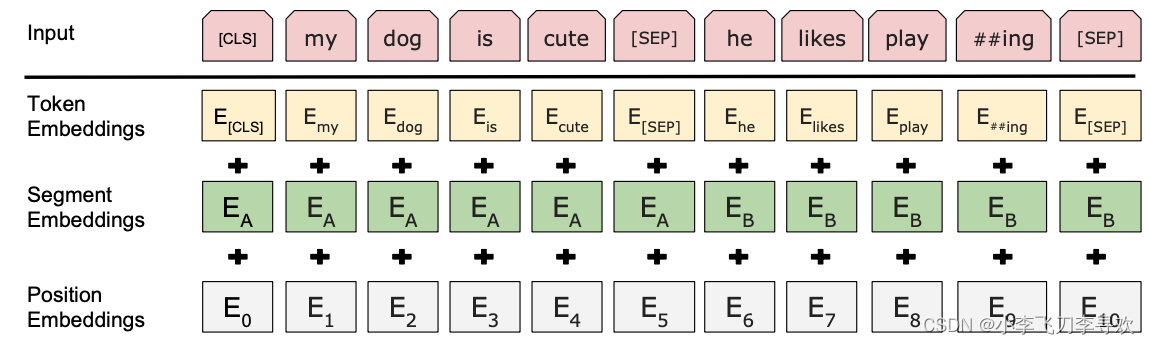
输入和输出表示:为了处理更多下游任务,输入形式必须明确,可以是单个sentence,也可以是一对sentence,此sentence是泛指,可以是单个句子,也可以是多个连续的句子。采用wordPiece embedding,词典大小30k,每个句子第一个token是一个classification token [CLS],在分类任务中这个token最后的隐层状态是用来聚合sentence表达。sentence对则集中成一个sentence,区别这些sentence有两种方式,1,采用特殊token[SEP]分割;2,增加一个embedding给每个token,表明他们是属于sentenceA还是sentenceB,正如上图左边所示,C就是CLS token的,对于一个给定的输入,三个embedding相加后得到输入表达,三个embedding分别为position embedding,segment embedding,token embedding,position embedding和token embedding都很好理解,只有segment embedding,它是表示token属于哪个sentence的embedding,同样,这三个embedding维度都一样,不然不能元素相加,如下:
预训练Bert:并不是传统的从左边到右边,或从右边到左边的语言模型去预训练,而是第一个图中的两个任务,1):MLM,直观上,一个深度双向model是比一个left-to-right或者left-to-right和right-to-left 浅concat 要更有power。不巧的是,标准的条件语言模型(conditional language model)只能以left-to-right 或者right-to-left方式进行训练,因为双向的条件会使得每个词间接地“see itself”,模型会很容易预测出目标词。为了训练一个深度双向表达,简单的随机掩盖一些比例的输入,然后预测这些掩盖的词,这就是Masked LM,最终的mask token的隐层向量被喂到所有词典之上的输出softmax,意思就是拿词典中所有的词进行softmax。每个句子随机mask 15% 的WordPiece token。这种方式获得的预训练模型可能在微调中不匹配,因为,mask 的token可能在微调中没有出现。为此,并不是一直以实际的[mask] token替代实际被掩盖的词,即,训练集随机选择15%的token位置预测,如果第i个选中,80%可能性以[MASK]替代,10%可能性以随机token,10%并不改变。
2)NSP(Next sentence prediction),上述语言模型并不能获取像QA,NLI(自然语言推断inference)的信息。为了是训练的模型理解sentence之间的关系,预训练了一个二分类任务,也就是下一个sentence的预测。对句子A和B预训练时,50%可能B就是出现在A的后面,label为IsNext,50%可能是语料中的随机句子,label 为NotNext。正如图1中的C,它用于NSP预训练。然而,在先前的工作中,只有语句嵌入被传递到下游任务,其中BERT传递所有参数以初始化最终任务模型参数。
预训练数据:采用BooksCorpus(800M词)和英语维基百科(2500M词),后者只提取文本信息,忽略列表,和表头。而且严格使用文本级别语料,而不是打乱顺序的句子级别语料。
微调Bert:对于涉及文本对的应用程序,一种常见的模式是在应用双向交叉注意力之前独立地对文本对进行编码。BERT使用自我注意机制来统一这两个阶段,因为用自我注意编码串联文本对有效地包括两个句子之间的双向交叉注意力。在输入端,来自预训练的句子A和句子B类似于(1)释义中的句子对,(2)暗示中的假设前提对,(3)问答中的问题-段落对,以及(4)退化文本-∅ 文本分类或序列标记中的配对。在输出端,token表示被送入token级任务的输出层,如序列标记或问题回答,[CLS]表示被送入输出层进行分类,如修饰或情感分析。相对于预训练,微调相对划算。所有的paper都可在预训练模型基础上用几个小时单个GPU进行复现。
几个数据集:
The General Language Understanding Evaluation -GLUE多样的自然语言理解任务
The Stanford Question Answering Dataset -SQuAD v1.1 100k问答对。
The Situations With Adversarial Generations -SWAG 113k基础常识句子对
几个任务:也可能是数据集
Multi-Genre Natural Language Inference -MNLI 给定一对句子,目标是预测第二个句子相对于第一个句子是隐含的、矛盾的还是中性的。
Quora Question Pairs -QQP 二分类任务,目标是确定Quora上的两个问题在语义上是否相等
Question Natural Language Inference -QNLI 斯坦福QA数据集,二分类任务,正例是(疑问句、句子)对,其中包含正确答案,反例是来自同一段落的(疑问句),其中不包含答案。
The Stanford Sentiment Treebank -SST-2 二分类任务,从电影评论中提取的句子,以及情感注释
The Corpus of Linguistic Acceptability -CoLA 二分类任务(单句),目标是预测英语句子在语言上是否“可接受”
The Semantic Textual Similarity Benchmark -STS-B 从新闻标题和其他来源提取的句子对的集合,语义相似性分数,从1~5
Microsoft Research Paraphrase Corpus -MRPC 从网上新闻提取的句子对,并且有注释这两个句子对在语义上是否一样。
Recognizing Textual Entailment -RTE 类似于MNLI,二分类,但训练集少、
Winograd NLI -WNLI 小的NLI数据集
Bert 与GPT训练时如何不同:Bert用BooksCorpus(800M词)和维基百科(2500M词),而GPT只用前者。也就是数据集GPT少了很多。
Bert学习SEP,CLS以及sentence A/B 的embedding在预训练中,而GPT只在微调时引入SEP,CLS。
batch_size不同:Bert 128k词一个batch,而GPT 32k词一个batch
学习率不同:Bert 选择适合微调任务的最好的学习率,而GPT使用lr=5e-5的学习率在所有微调任务中。
codes:此代码是预训练的bert及预训练的模型。
先看Bert模型:其中并没有decoder阶段,因此上面所说的L=12仅指encoder阶段,(主要为self-attention 然后是ResNet和LayerNorm,其中也有dense阶段)这个算一层,12层即可。
WordPiece tokenization:的先是空白分词,然后对一些词再分词,比如john johanson ' s , → john johan ##son ' s
自有数据预训练及微调:采用现成的句子分割工具spacy,然后用create tfrecord (如下示例)也可加入2%的噪声,生成的tfrecord用于预训练(如下run_pretraining)
python create_pretraining_data.py \
--input_file=./sample_text.txt \
--output_file=/tmp/tf_examples.tfrecord \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--do_lower_case=True \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5
python run_pretraining.py \
--input_file=/tmp/tf_examples.tfrecord \
--output_dir=/tmp/pretraining_output \
--do_train=True \
--do_eval=True \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--train_batch_size=32 \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--num_train_steps=20 \
--num_warmup_steps=10 \
--learning_rate=2e-5测试预训练的模型:示例
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/glue
python run_classifier.py \
--task_name=MRPC \
--do_train=true \
--do_eval=true \
--data_dir=$GLUE_DIR/MRPC \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/tmp/mrpc_output/微调示例:
python run_squad.py \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--do_train=True \
--train_file=$SQUAD_DIR/train-v1.1.json \
--do_predict=True \
--predict_file=$SQUAD_DIR/dev-v1.1.json \
--train_batch_size=12 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=/tmp/squad_base/预训练需要注意的点:
1)修改 bert_config.json中的vocab_size ,否则可能出现NaN
2)在已有Bert模型基础上再预训练lr应该降低(原本是1e-4),可以试试2e-5
3)长序列开销很大,因为attention是其长度的平方复杂度。64个序列长度为512的seqs比256个序列长度为128的seqs更难训练。
4)预训练花费巨大,时间长达2weeks,花费TPU约 $500