AI人工智能
ANI 弱人工智能,狭义人工智能,指的是一种针对特定任务或领域进行优化的人工智能,例如语音识别、图像识别、自然语言处理、推荐系统
AGI 通用人工智能,强人工智能,
ASI 超级人工智能,超人工智能
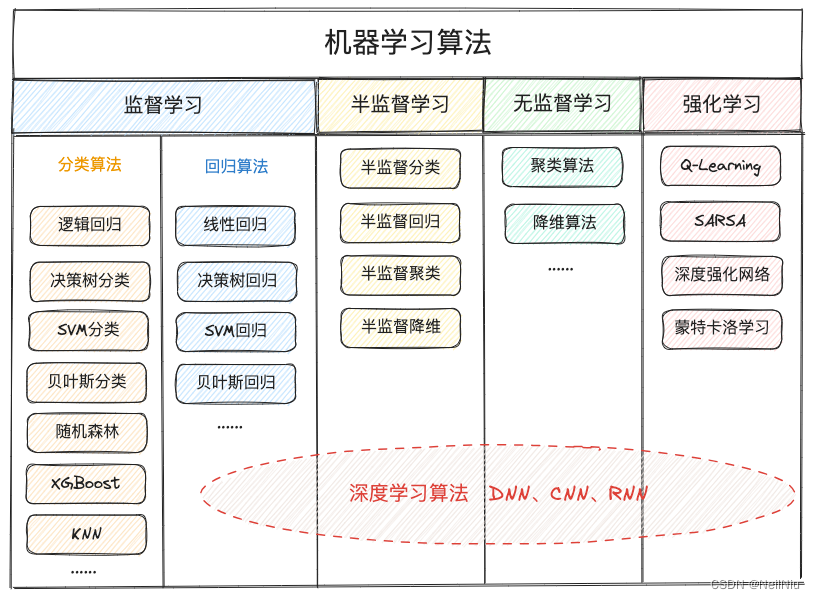
机器学习分类
1、数据集,一批具有特征和标签的数据的集合叫做数据集。又分为训练数据集、验证数据集、测试数据集。训练数据集作为训练的数据,通过训练数据集找到一个函数,同时会使用验证数据集验证和评估函数。测试数据就负责对训练和评估后的函数进行测试。
2、监督学习 ,训练数据集全部都有标签,根据标签特点,又分为回归问题和分类问题;回归问题:标签是连续的数值,是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析,说白了就是当自变量变化的时候,研究以下因变量是怎么跟着变化的,比如电商场景中的销量预测、客户生命周期价值预测。分类问题:标签是离散数值,就是将数据分为不同的类别标签,通常用于图像识别、文本分类等分类问题。
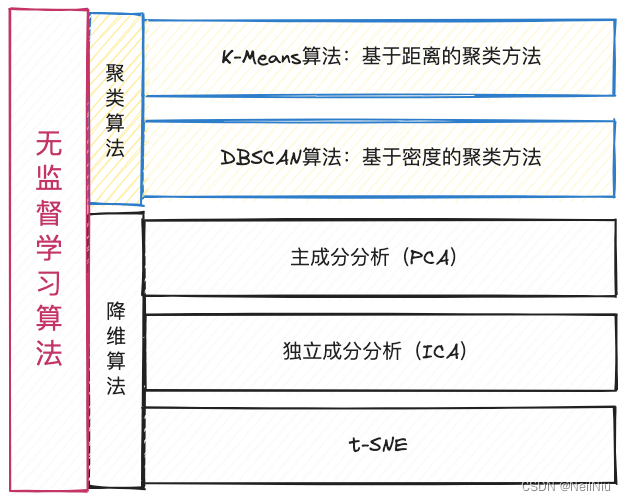
3、无监督学习,训练数据集全部没有标签
4、半监督学习,训练数据集有的有标签,有的没有标签
5、强化学习
6、深度学习
机器学习步骤
1、数据收集
2、数据预处理:
数据可视化(发现数据中的规律和问题)可视化工具 Matplotlib Seaborn、
数据清洗(让数据更干净)使用工具Pandas库下的DataFrame、
特征工程(让数据易于被机器理解,并发掘重要特征)特征工程简单讲就是发现对因变量y有明显影响作用的自变量x,特征工程的目的就是发现重要特征,基于业务特性,从众多的特征中发现对标签有明显作用的特征,而摒弃掉无用的特征,降低特征的维度,提升机器学习模型的性能。
创建特征集和标签集、数据集分特征集和标签集,把数据喂给模型,特征集就是自变量x的数据的集合,标签集就是因变量Y的数据的集合。举个例子猫狗分类,特征,像素值、颜色通道
拆分训练集验证集测试集(训练、验证、评估、测试模型),一些特征和标签组成了数据集,接下来就是拆分数据集,拆分原则一般20%或30%的数据集留做测试,剩余的70%和80%留作训练数据集和验证数据集。使用工具scikit-learn里的数据集拆分工具train-test-split。
3、选择算法,我们应该确定问题的类型,在四种机器学习类型中,确定问题属于哪种学习问题类型,然后确定数据集特征和标签的关系,是属于回归问题还是分类问题,然后就可以针对不同的问题类型,选择相应的算法建立模型。如果是简单的问题,一般使用线性回归算法可以取得较好的效果。
4、训练模型,确定好算法之后,就可以通过训练数据集中的特征和标签,根据样本数据的损失来拟合函数模型,来获取最优的模型参数来建立模型。拟合模型指通过训练数据集来找到一个能够最好描述数据之间关系的函数,通俗的说就是让,机器学习算法学习输入数据与输出数据之间的关系,并生成一个可以对新数据进行预测的模型。
机器学习每训练一次,就会计算损失,逐渐减小训练集上的损失的过程,就是寻找最优模型参数的过程。过拟合 和欠拟合,过拟合是机器学习模型在训练数据上表现良好,但在测试数据上表现较差的现象。过拟合是指模型在训练数据上过度拟合,导致不能很好泛化到测试数据和实际数据中。
5、评估、优化模型,训练模型是算法寻找最优的模型的内部参数,评估和优化模型是在验证集或测试集上进行模型效果评估的过程中,对模型的外部参数进行优化,超参数,是指在模型训练之前需要设置的参数,用户控制模型结构和训练过程中的一些超参数。常用的超参数:神经网络的层数、学习速率、优化器,这些超参数的选择会影响模型的复杂度和性能,因此需要进行调整和优化获取更好的模型性能。
评估模型优劣,使用scikit-learn 中常用的工具和指标,对验证集和测试集进行评估,进而计算当前的误差,比如r2 或者MSE指标,可以用于评估回归分析模型的优劣。
模型评估分数不理想,需要重新调整模型的超参数、来重新训练模型,如果还是不理想,就要更换算法。
6、部署模型
当模型经过评估和优化后满足业务诉求,之后就可以部署模型,部署模型就是将训练好的模型应用于生产环境中,需要考虑多个因素,包括模型的性能、可靠性、安全性、扩展性、可维护性。
广泛用于语音识别、计算机视觉、自然语言处理、智能机器人