1.概述
ElasticSearch是一个基于Lucene的搜索服务器,提供了一个分布式多用户能力的全文搜索引擎。它是基于JAVA语言开发,并且是基于RESTful web接口进行查询和结果返回,是一款非常流行的企业级搜索引擎。Elasticsearch的核心功能包括存储数据和快速搜索、分析数据。本文将从elasticsearch的基本属性和其使用方式进行分析,帮助大家快速理解(注意:本文演示的案例是基于单节点)。
2.Elasticsearch使用
Elasticsearch的安装可参考文章SpringCloud从入门到放弃之链路追踪二(Sleuth+Zipkin+Kafka+Logstash),正确安装并启动,访问地址:http://服务器IP:9200/,可得到如下数据(部分数据可根能会由于安装时配置和版本不一致有所区别):

安装成功之后,由于Elasticsearch默认不具备中文分词能力,因此需要安装中文分词器,安装方式如下。
2.1 安装中文分词器
由于Elasticsearch对中文的处理并非很擅长,因此需要安装中文分词器来帮助处理,本文基于centos 7.6安装了Elasticsearch 7.6.2 ik分词器,具体如下:
1.下载Elasticsearch中文分词器安装包
中文分词器的安装包在GitHub上,需要注意的是,分词器的版本需要和Elasticsearch的版本一致。例如我的Elasticsearch版本是7.6.2,则分词器也要下载对应的7.6.2版本。
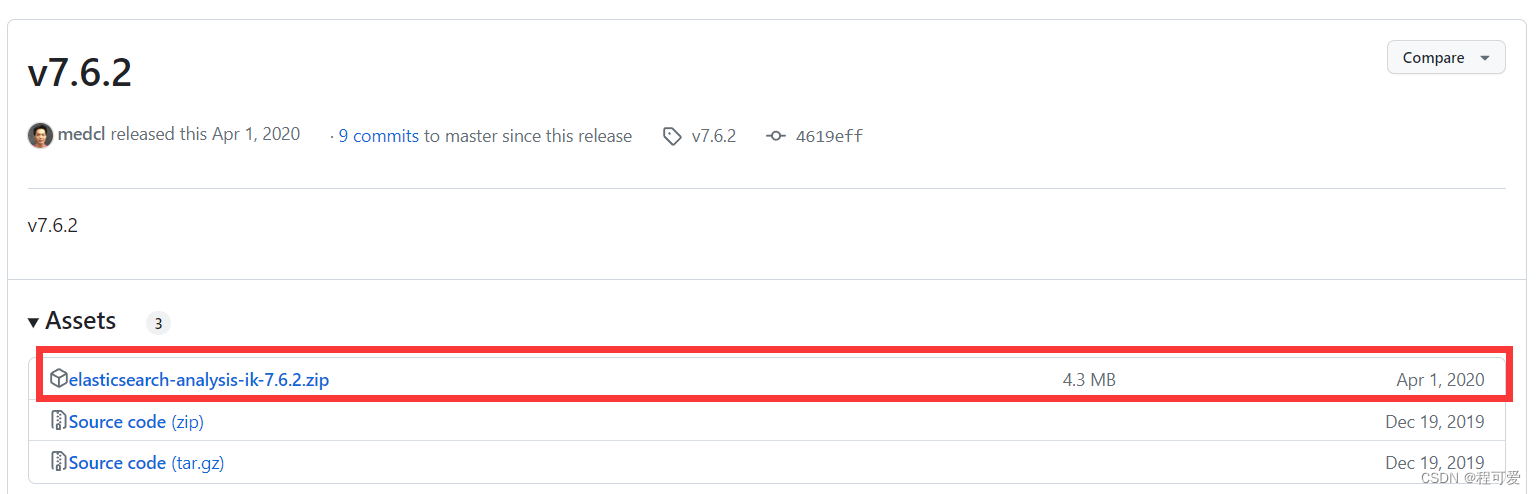
将上述中文分词包解压到Elasticsearch安装路径中plugins目录下,然后重启即可,Elasticsearch会自动加载分词包。下载时要需要下载zip包,然后到服务器上进行解压,下载source code会缺少配置。zip包解压后如下图所示:
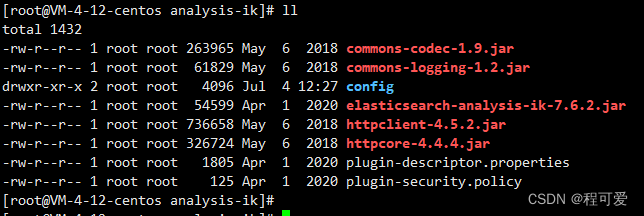
2.配置词库
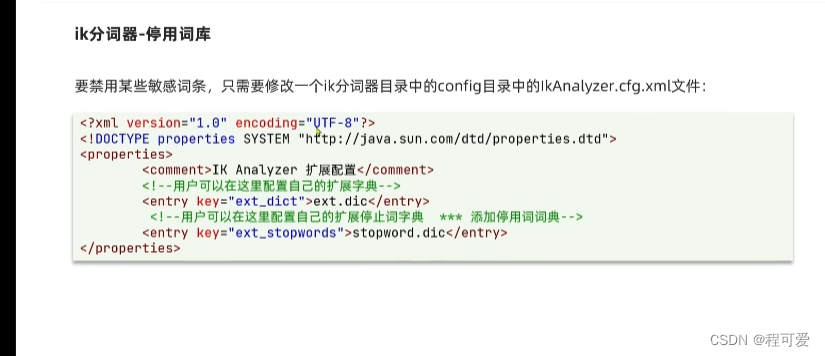
在ik分词器中,可以扩展自己的词典来适应某些场景,也可以禁用某些敏感词条,只需要修改ik分词器中的config目录中的IKAnalyzer.cfg.xml文件:
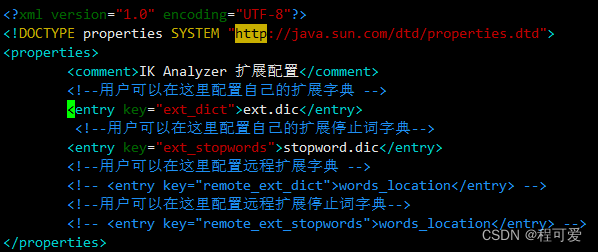
ext.dic和stopword.dic与IKAnalyzer.cfg.xml在同一路径下,ext.dic中添加需要扩容的词语(例如:奥里给、躺平等),stopword.dic添加一些禁用词条(例如:毛片等)。
2.2 Elasticsearch中核心概念介绍
| Elasticsearch | 关系型数据库 |
|---|---|
| 索引 | 数据库(database) |
| 类型 | 数据库表(table) |
| 文档 | 一行数据(row) |
| 字段 | 一列数据(column) |
| 映射 | 数据库的组织和结构(schema) |
针对上述概念的解释如下:
1.索引(index):索引是相似特征文档的集合,类似于关系型数据库中的数据库(database),一般同一个环境中索引名称具有唯一性,通常根据索引名称来对文档进行查询、添加、删除、修改等操作;
2.类型(type):一个类型通常是一个索引的一个逻辑分类或分区(类似于关系型数据库中的表),允许在一个索引下存储不同类型的文档,例如:用户类型、角色类型、菜单类型等;从6.0.0开始单个索引中只能有一个类型,7.0.0以后将将不建议使用,8.0.0 以后完全不支持;目前Type已经被Deprecated,在7.0开始,一个索引只能建一个Type为_doc;现阶段index反而更像一张表;
3.文档(document):一个文档是可以被索引的基础信息单元(类似于关系型数据库中一行数据)。文档可以存储JSON格式数据,数据可以嵌套,在一个所以在,可以存储多个文档,且文档必须被索引;
4.字段(field):
组成文档信息的最小单元(类似于关系型数据库中的列),比如用户类型中的姓名、年龄;
5.映射(mapping):用来定义文档及其所包含的字段如何被存储和索引(类似于关系型数据库中的schema)。mapping常见的属性有:type(数据类型)、index(是否索引)、analyzer(分词器)、properties(子字段)。
核心概念还包括集群、节点和分片,如下所示:
| 名称 | 概念 |
|---|---|
| 集群 | ElasticSearch集群实际上是一个分布式系统,与所有分布式系统类似,它是为了保证数据和服务的高可用性,一个集群有多个节点,随着请求量和数据量的不断增长,系统可以将数据均匀分布到不同节点,实现横向扩展 。 |
| 节点 | 每个节点就是一个ElasticSearch服务,也就是一个JAVA进程,它是组成集群的最小单位,每个节点都有一个唯一名字,默认在节点启动时生成一个uuid作为节点名(也可以指定名称),每个集群可以由任意多个节点组成,如果只启动一个节点,则就是单节点的集群。 |
| 分片 | 分片是用来解决节点的容量上限问题,通过主分片可以将数据分布到集群内所有节点,类似于关系型数据库中的水平分表,一个分片就是一个Lucene实例,数据都会被索引到分片中,程序都是直接对index进行操作(而不是分片)。 |
2.2 SpringBoot整合Elasticsearch
springboot与elasticsearch对应的版本信息如下图所示:
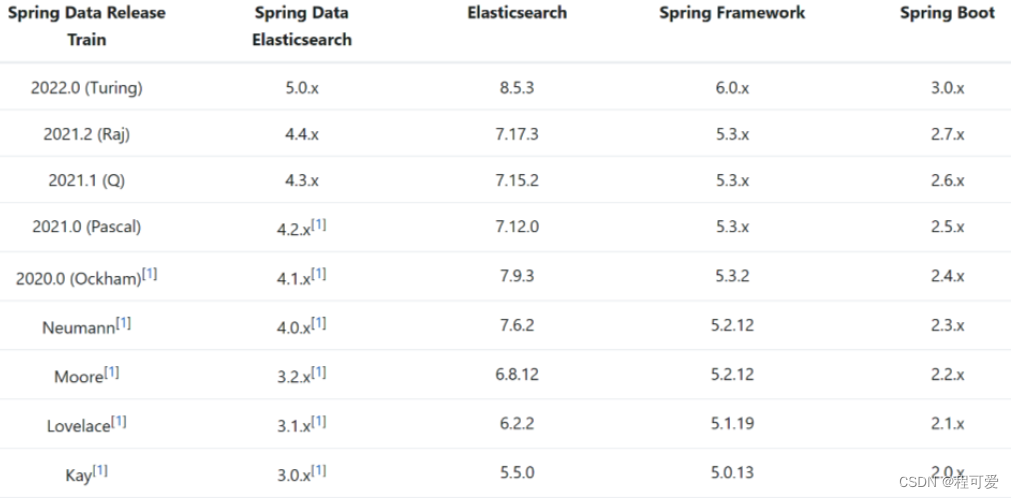
本文使用的是Elasticsearch版本是7.6.2,因此对应的SpringBoot的版本为2.3.7版本。
2.2.1 引入pom
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2.2.2 操作ElasticSearch
本文使用RestHighLevelClient来对ElasticSearch进行操作演示,具体RestHighLevelClient对象创建与销毁如下所示(演示用,生产环境不建议使用):
//创建RestHighLevelClient对象
@Before
public void setUp() {
this.restHighLevelClient = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://127.0.0.1:9200")
));
log.info("创建RestHighLevelClient");
}
//销毁RestHighLevelClient对象
@After
public void clear() {
try {
this.restHighLevelClient.close();
log.info("销毁RestHighLevelClient");
} catch (IOException e) {
e.printStackTrace();
}
}
1.创建index
ES中通过Restful API接口来请求操作索引库、文档,请求内容用DSL来表示。创建索引库和mapping的语法如下所示(创建一个名称为book的index):
PUT /book
{
"mappings" : {
"properties" : {
"brand" : {
"type" : "keyword"
},
"category" : {
"type" : "keyword"
},
"id" : {
"type" : "keyword"
},
"images" : {
"type" : "keyword",
"index" : false
},
"price" : {
"type" : "double"
},
"title" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"address" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"publisher" : {
"type" : "keyword"
}
}
}
}
mapping是对索引库中文档的约束,常见的mapping属性包括:
(1)type:字段数据类型,常见的简单类型有字符串、数值、布尔类型。
字符串:text(可分词的文本)、keyword(精确值,例如:国家、城市、ip地址等);
数值包括byte、short、integer、long、double、float,布尔类型只有boolean;日期类型是date,对象类型为object(内部可包含属性),基本与JAVA语法中类型一致;
这部分与JAVA中变量类型一致。
(2)index:是否创建索引,默认为true;
(3)analyzer:使用哪种分词器,默认为英文分词器,中文分词器包括:ik_max_word(常用模式,将文本做最细粒度拆分);ik_smart(将文本做最粗粒度拆分);
(4)properties:该字段的子字段;
对应利用SpringBoot创建index的代码为:
@Test
public void testCreateBookIndex() throws Exception {
CreateIndexRequest request = new CreateIndexRequest("book");
request.source(Constants.BOOK_STRING, XContentType.JSON);
restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println(restHighLevelClient);
}
//对应常量Constants中BOOK_STRING
public class Constants {
public static final String BOOK_STRING = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"title\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" },\n" +
" \"category\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"brand\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"images\": {\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"price\": {\n" +
" \"type\": \"double\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
}
代码创建成功结果返回如下:

2.判断index是否存在
请求restful接口操作如下:
GET /索引名
查询索引为book,若存在,返回结果如下:
{
"book" : {
"aliases" : { },
"mappings" : {
"properties" : {
"brand" : {
"type" : "keyword"
},
"category" : {
"type" : "keyword"
},
"id" : {
"type" : "keyword"
},
"images" : {
"type" : "keyword",
"index" : false
},
"price" : {
"type" : "double"
},
"title" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1688459211404",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "inX1UEwZSGyB3fovFAzt2g",
"version" : {
"created" : "7060299"
},
"provided_name" : "book"
}
}
}
}
在springboot中可用如下代码进行判断:
@Test
public void testExistBookIndex() throws Exception {
GetIndexRequest request = new GetIndexRequest("book");
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
log.info("exists :{}", (exists ? "索引库已经存在" : "索引库不存在"));
}
若存在索引,则运行结果如下:

3.删除索引
删除索引库语法如下:
DELETE /索引名称
在springboot中利用代码删除如下:
@Test
public void testDeleteBookIndex() throws Exception {
DeleteIndexRequest request = new DeleteIndexRequest("book");
restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
log.info("索引删除成功");
}
运行结果如下:

4.更新索引库
索引库和mapping一旦创建无法修改,但是可用添加新的字段,语法如下:
PUT /book/_mapping
{
"properties": {
"name": {
"type": "keyword",
"index": false
}
}
}
es的操作类RestHighLevelClient不提供直接修改索引的操作方法。
5.添加文档
添加文档的语法如下:
POST /索引名称/_doc/文档id
{
"address" : "杭州市西湖区",
"brand" : "莫言文学",
"category" : "世界文学",
"id" : 2,
"images" : "http://1288779/1.image",
"price" : 109.0,
"publisher" : "浙江鲁迅文学出版社",
"title" : "《丰乳肥臀》"
}
添加成功返回结果为:

利用springboot添加文档操作如下:
@Test
public void testAddBookDocument() throws Exception {
IndexRequest request = new IndexRequest("book").id("2");
Book book1 = new Book();
book1.setBrand("莫言文学出版社");
book1.setCategory("世界文学");
book1.setId(2L);
book1.setImages("http://1288779/1.image");
book1.setPrice(109.0);
book1.setTitle("《丰乳肥臀》");
book1.setPublisher("浙江鲁迅文学出版社");
book1.setAddress("杭州市西湖区");
request.source(JSON.toJSONString(book1), XContentType.JSON);
restHighLevelClient.index(request, RequestOptions.DEFAULT);
log.info("添加书籍书籍成功:{}", JSON.toJSONString(book1));
}
6.根据id查询文档
根据id查询文档语法如下:
GET /索引名称/_doc/id
springboot根据id查询文档方式如下:
@Test
public void testSearchBookDocument() throws Exception {
GetRequest request = new GetRequest("book", "1");
GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);
String result = response.getSourceAsString();
log.info("查询返回结果为:{}", result);
if (StringUtils.isNotBlank(result)) {
Book book = JSON.parseObject(result, Book.class);
log.info("book:{}", book.toString());
}
}
查询结果如下:
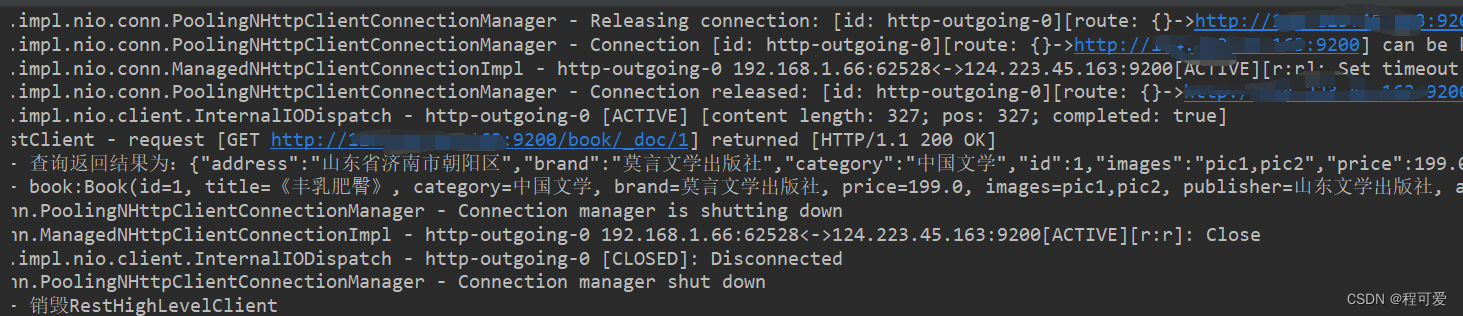
7.修改文档
修改文档主要有两种方式:一种是全量修改(删除旧文档,添加新文档);另一种是增量修改(修改指定字段值)。全量修改的语法如下所示:
PUT /索引库名/_doc/文档id
{
"doc":{
"字段1" : "值1",
"字段2" : "值2",
//......
}
}
增量修改的语法如下所示:
POST /索引库名/_update/文档id
{
"doc":{
"字段1" : "值1",
"字段2" : "值2",
//......
}
}
springboot增量修改代码如下:
@Test
public void testUpdateBookDocument() throws Exception {
UpdateRequest request = new UpdateRequest("book", "1");
request.doc((jsonBuilder()
.startObject()
.field("brand", "山东文学出版社")
.endObject()));
restHighLevelClient.update(request, RequestOptions.DEFAULT);
log.info("更新数据成功!");
}
更新后查询返回结果如下:
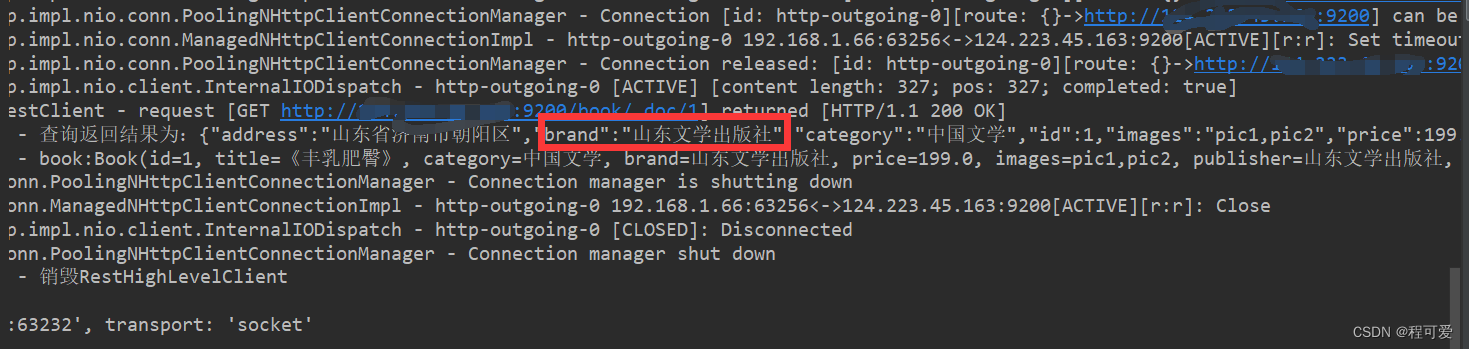
8.根据Id删除文档
删除文档语法如下:
DELETE /索引名称/_doc/id
springboot根据id删除文档代码如下:
@Test
public void testDeleteBookDocument() throws Exception {
DeleteRequest request = new DeleteRequest("book", "1");
restHighLevelClient.delete(request, RequestOptions.DEFAULT);
log.info("删除数据成功!");
//testSearchProductDocument();
}
9.批量添加文档
@Test
public void testBulkBookDocument() throws Exception {
BulkRequest bulkRequest = new BulkRequest();
IndexRequest request = new IndexRequest("book").id("2");
Book book1 = new Book();
book1.setBrand("莫言文学出版社");
book1.setCategory("中国文学");
book1.setId(1L);
book1.setImages("pic1,pic2");
book1.setPrice(99.0);
book1.setTitle("《蛙》");
request.source(JSON.toJSONString(book1), XContentType.JSON);
log.info("添加数据成功!");
IndexRequest request1 = generateBook();
log.info("添加数据成功!");
bulkRequest.add(request);
bulkRequest.add(request1);
//批量添加
restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
//testSearchProductDocument();
}
//CURL+ALT+M 抽取方法
private IndexRequest generateBook() {
IndexRequest request1 = new IndexRequest("book").id("3");
Book book2 = new Book();
book2.setBrand("莫言文学出版社");
book2.setCategory("中国文学");
book2.setId(1L);
book2.setImages("pic1,pic2");
book2.setPrice(99.0);
book2.setTitle("《酒国》");
request1.source(JSON.toJSONString(book2), XContentType.JSON);
return request1;
}
批量添加会使用restHighLevelClient中的bulk方法,通过将组装好的IndexRequest对象加入BulkRequest 对象中,最后调用bulk方法统一入库。
2.3 DSL查询语法
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
(1)查询所有:查询出所有数据,一般测试用,例如:match_all;
(2)全文检索查询(full text):利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:match_query、multi_match_query;
(3)精确查询:根据精确词条值查找数据,一般是keyword、数值、日期、boolean等类型字段。例如:ids,range,term;
(4)地理查询(geo):根据经纬度查询。例如:geo_distance,geo_bounding_box;
(5)复合查询(compound):复合条件是将上述各种查询条件组合起来,合并查询条件。例如:bool、function_score;
2.3.1 match_all
match_all查询语法如下:
GET /index/_search
{
"query": {
"match_all": {}
}
}
springboot中的代码为:
@Test
public void testMatchAll() throws Exception {
SearchRequest searchRequest = new SearchRequest("book");
searchRequest.source().query(QueryBuilders.matchAllQuery());
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("result:{}", response);
SearchHits hits = response.getHits();
TotalHits totalHits = hits.getTotalHits();
log.info("总数为total:{}", totalHits);
SearchHit[] hitsList = hits.getHits();
for (SearchHit documentFields : hitsList) {
String sourceAsString = documentFields.getSourceAsString();
log.info("查询结果:{}", sourceAsString);
}
}
运行结果为:

2.3.2 全文检索查询
全文检索查询,会对用户输入内容分词,常用于搜索框搜索。全文检索主要有:match、multi_match。match会对用户输入内容分词,然后去倒排索引库检索,语法如下:
GET /book/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}
multi_match与match查询类似,只不过允许同事查询多个字段,语法如下:
GET /book/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1","FIELD2"]
}
}
}
match是根据一个字段去查询,multi_match是根据多个字段去查询(查询字段越多性能越差),在使用中应尽量多使用match。
springboot中match查询代码如下:
@Test
public void testMatchQuery() throws Exception {
SearchRequest searchRequest = new SearchRequest("book");
searchRequest.source().query(QueryBuilders.matchQuery("all", "莫言"));
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("result:{}", response);
SearchHits hits = response.getHits();
TotalHits totalHits = hits.getTotalHits();
log.info("总数为total:{}", totalHits);
SearchHit[] hitsList = hits.getHits();
for (SearchHit documentFields : hitsList) {
String sourceAsString = documentFields.getSourceAsString();
log.info("查询结果:{}", sourceAsString);
}
}
2.3.3 精确查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段,所以不会对搜索条件分词。常见的精确查询有term和range,term是根据词条精确值查询,range是根据值得范围查询。
//查询价格为109的书籍
GET /book/_search
{
"query": {
"term": {
"price": {
"value": 109
}
}
}
}
springboot使用term查询代码如下:
@Test
public void testBooleanQuery() throws Exception {
SearchRequest searchRequest = new SearchRequest("book");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.termQuery("price", 109));
//range是范围查询
//boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gt(100));
searchRequest.source().query(boolQueryBuilder);
//分页
searchRequest.source().from(0).size(10);
//排序
//searchRequest.source().sort("price", SortOrder.ASC);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("result:{}", response);
SearchHits hits = response.getHits();
TotalHits totalHits = hits.getTotalHits();
log.info("总数为total:{}", totalHits);
SearchHit[] hitsList = hits.getHits();
for (SearchHit documentFields : hitsList) {
String sourceAsString = documentFields.getSourceAsString();
log.info("查询结果:{}", sourceAsString);
}
}
结果如下:

range查询语法如下:
GET /book/_search
{
"query": {
"range": {
"price": {
"gte": 100,
"lte": 200
}
}
}
}
2.3.4 地理查询
地理查询主要根据经纬度来查询,使用场景包括:微信附近的人、附近的酒店、附近的商家等。查询语法如下:
GET /book/_search
{
"query": {
"geo_distance": {
"distance": "10km",
"FIELD": "31.21,121.5"
}
}
}
2.3.5复合查询
1.算分函数
复合查询就是将多种条件组合,实现更复杂的搜索。例如:function score(算分函数)。
算分函数可用控制文档的相关性算分,控制文档排名。查询语法如下:
GET /book/_search
{
"query": {
"function_score": {
"query": {
"match": {
"brand": "莫言文学"
}
},//原始查询条件,搜索相关文档并进行打分
"functions": [
{"filter": {
"term": {
"id": "1"
}
},//过滤条件,复合条件的文档才会被重新打分
"weight": 10 //算分函数,算分函数会得到计算结果function score,将来会与query score运算,得到新算分
}
],
"boost_mode": "multiply" //加权模式,定义function score与query score的运算方式,multiply是两者相乘,还有sum、avg、max等
}
}
}
结果如下:
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 3.791412,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 3.791412,
"_source" : {
"brand" : "莫言文学出版社",
"category" : "中国文学",
"id" : 1,
"images" : "pic1,pic2",
"price" : 99.0,
"score" : 0.0,
"title" : "《蛙》"
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 3.791412,
"_source" : {
"brand" : "莫言文学出版社",
"category" : "中国文学",
"id" : 1,
"images" : "pic1,pic2",
"price" : 99.0,
"score" : 0.0,
"title" : "《酒国》"
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.47436732,
"_source" : {
"address" : "杭州市西湖区",
"brand" : "莫言文学",
"category" : "世界文学",
"id" : 2,
"images" : "http://1288779/1.image",
"price" : 109.0,
"publisher" : "浙江鲁迅文学出版社",
"title" : "《丰乳肥臀》"
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.47436732,
"_source" : {
"address" : "上海市静安区",
"brand" : "莫言文学",
"category" : "中国文学",
"id" : 3,
"images" : "pic1,pic2",
"price" : 109.0,
"publisher" : "北京文学出版社",
"title" : "《红高粱》"
}
}
]
}
}
常见的算分函数有:
(1)weight:给一个指定常量值,作为函数结果(function score);
(2)field_value_factor:用文档中的某个字段值作为函数结果;
(3)random_score:随机生成一个值,作为函数结果; (4)script_score:自定义计算公式,公式结果作为函数结果。
2.布尔查询
布尔查询时一个或者多个查询子句的组合,子查询的组合方式有:
(1)must:必须匹配每个子查询,类似“与”;
(2)should:选择性匹配子查询,类似“或”;
(3)must_not:必须不匹配,不参与算分,类似于“非”;
(4)filter:必须匹配,不参与算分。
查询语句如下:
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"brand": "莫言文学"
}}
],
"should": [
{"term": {
"id": {
"value": 1
}
}
},
{"term": {
"id": {
"value": 1
}
}
}
],
"must_not": [
{
"range": {
"price": {
"lt": 100
}
}}
]
}
}
}
查询结果如下:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.47436732,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.47436732,
"_source" : {
"address" : "杭州市西湖区",
"brand" : "莫言文学",
"category" : "世界文学",
"id" : 2,
"images" : "http://1288779/1.image",
"price" : 109.0,
"publisher" : "浙江鲁迅文学出版社",
"title" : "《丰乳肥臀》"
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.47436732,
"_source" : {
"address" : "上海市静安区",
"brand" : "莫言文学",
"category" : "中国文学",
"id" : 3,
"images" : "pic1,pic2",
"price" : 109.0,
"publisher" : "北京文学出版社",
"title" : "《红高粱》"
}
}
]
}
}
3.高亮字段
高亮字段其实就是给指定查询字段返回一个标签,前端可根据这个标签编写css样式,来达到高亮或其它目的。高亮语法如下:
GET /book/_search
{
"query": {
"match": {
"brand": "莫言文学" //查询字段
}
},
//需要高亮的字段,添加前置和后置标签
"highlight": {
"fields": {
"brand": {
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}
springboot中代码为:
@Test
public void testHighlightQuery() throws Exception {
SearchRequest searchRequest = new SearchRequest("book");
searchRequest.source().query(QueryBuilders.matchQuery("brand", "莫言文学"));
//高亮
searchRequest.source().highlighter(new HighlightBuilder().field("brand").requireFieldMatch(false));
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("result:{}", response);
SearchHits hits = response.getHits();
TotalHits totalHits = hits.getTotalHits();
log.info("总数为total:{}", totalHits);
SearchHit[] hitsList = hits.getHits();
for (SearchHit hit : hitsList) {
String sourceAsString = hit.getSourceAsString();
Book book = JSON.parseObject(sourceAsString, Book.class);
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField highlightField = highlightFields.get("brand");
String string = highlightField.getFragments()[0].string();
book.setBrand(string);
log.info("查询结果:{}", string);
}
}
结果如下:

3.小结
1.ik分词器可以帮助es更好地识别中文模式;
2.elasticsearch、kibana、springboot使用时要注意版本一致性;
3.ES中通过Restful API接口来请求操作索引库、文档,请求内容用DSL来表示。
4.参考文献
1.https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html
2.https://www.bilibili.com/video/BV1LQ4y127n4
3.https://www.elastic.co/cn/downloads/past-releases/kibana-7-6-2
5.附录
1.https://gitee.com/Marinc/nacos.git