目录标题
- 1、为什么要对特征做归一化
- 2、对特征归一化的方法
- 2.1 线性函数归一化
- 2.2 零均值归一化
- 3、对数据预处理时,如何处理类别型特征
- 3.1 序号编码
- 3.2 独热编码
- 3.3 二进制编码
- 4、什么是组合特征?如何处理高维组合特征?
- 5、怎样有效地找到组合特征?
- 6、有哪些文本表示模型?它们各有什么优缺点?
- 6.1 词袋模型与N-gram模型
- 6.2 主题模型
- 6.3 词嵌入与深度学习模型
- 7、Word2Vec是如何工作的?它和LDA有什么区别与联系?
- 7.1 CBOW
往往数据和特征决定了结果的上限,模型与算法决定了结果的下限。
数据类型:
- 结构化数据(表)
- 非结构化数据(图像、语音、文本等)
1、为什么要对特征做归一化
为了消除数据特征的量纲影响,使得不同特征之间具有可比性。
例如一个人的身高与体重对健康的影响。m与kg做单位,1.4-1.9与40-100kg范围。如果不做归一化,结果会倾向于数值差别比较大的体重特征。
想要得到更为准确的结果,所以会做归一化,使得各指标处于同一数值量级,方便分析
2、对特征归一化的方法
2.1 线性函数归一化
它对原始数据进行线性变换,使结果映射到[0, 1]的范围,实现对原始数据的等比缩放。归一化公式如下:
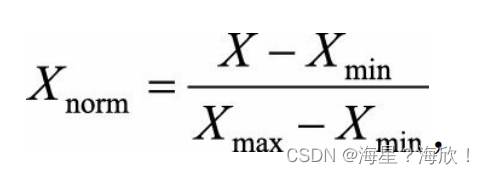
2.2 零均值归一化
它会将原始数据映射到均值为
0、标准差为1的分布上。具体来说,假设原始特征的均值为μ、标准差为σ,那么归一化公式定义为
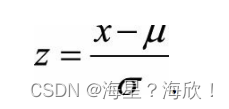
3、对数据预处理时,如何处理类别型特征
类别型特征(Categorical Feature)主要是指性别(男、女)、血型(A、B、AB、O)等只在有限选项内取值的特征。
3.1 序号编码
序号编码通常用于处理类别间具有大小关系的数据。
例如成绩,可以分为低、中、高三档,并且存在“高>中>低”的排序关系。序号编码会按照大小关系对别型特征赋予一个数值ID,例如高表示为3、中表示为2、低表示为1,转换后依然保留了大小关系。
3.2 独热编码
独热编码通常用于处理类别间不具有大小关系的特征。
例如血型,一共有4个取值(A型血、B型血、AB型血、O型血),独热编码会把血型变成一个4维稀疏向量,A型血表示为(1, 0, 0, 0),B型血表示为(0, 1, 0, 0),AB型表示为(0, 0,1, 0),O型血表示为(0, 0, 0, 1)。
当类别取值较多时,问题:
1,稀疏向量来节省空间。
2,配合特征选择来降低维度。
3.3 二进制编码
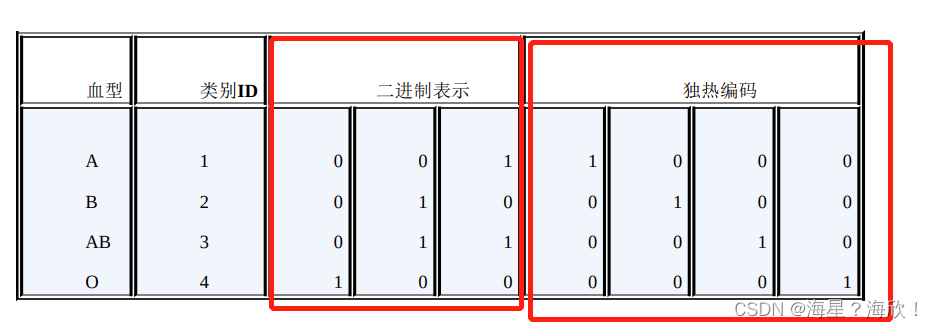
二进制编码主要分为两步,先用序号编码给每个类别赋予一个类别ID,然后将类别ID对应的二进制编码作为结果。
以A、B、AB、O血型为例,表1.1是二进制编码的过程。A型血的ID为1,二进制表示为001;B型血的ID为2,二进制表示为010;以此类推可以得到AB型血和O型血的二进制表示。可以看出,二进制编码本质上是利用二进制对ID进行哈希映射,最终得到0/1特征向量,且维数少于独热编码,节省了存储空间。
4、什么是组合特征?如何处理高维组合特征?
为了提高复杂关系的拟合能力,在特征工程中经常会把一阶离散特征两两组合,构成高阶组合特征。
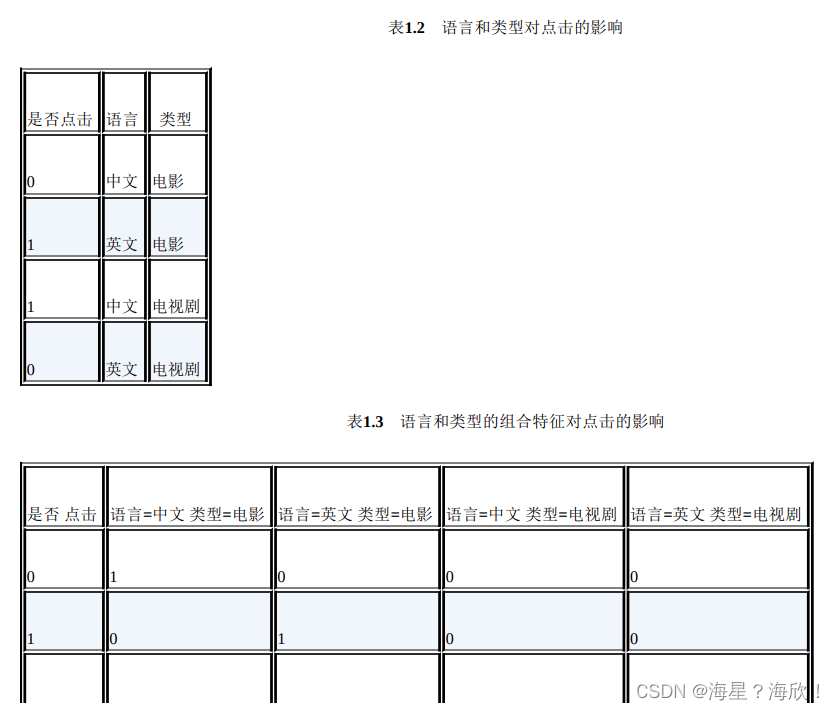
例子:以广告点击预估问题为例,原始数据有语言和类型两种离散特征,表1.2是语言和类型对点击的影响。为了提高拟合能力,语言和类型可以组成二阶特征,表1.3是语言和类型的组合特征对点击的影响。
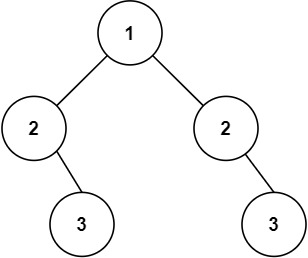
5、怎样有效地找到组合特征?
基于决策树的特征组合寻找方法。每一条从根节点到叶节点的路径都可以看成一种特征组合的方式。
例子:

具体来说,就有以下4种特征组合的方式。
(1)“年龄<=35”且“性别=女”。
(2)“年龄<=35”且“物品类别=护肤”。
(3)“用户类型=付费”且“物品类型=食品”。
(4)“用户类型=付费”且“年龄<=40”。
6、有哪些文本表示模型?它们各有什么优缺点?
6.1 词袋模型与N-gram模型
最基础的文本表示模型是词袋模型。顾名思义,就是将每篇文章看成一袋子词,并忽略每个词出现的顺序。具体地说,就是将整段文本以词为单位切分开,然后每篇文章可以表示成一个长向量,向量中的每一维代表一个单词,而该维对应的权重则反映了这个词在原文章中的重要程度。常用TF-IDF来计算权重,公式为TF-IDF(t,d)=TF(t,d)×IDF(t) ,
可以将连续出现的n个词(n≤N)组成的词组(N-gram)也作为一个单独的特征放到向量表示中去,构成N-gram模型。
6.2 主题模型
主题模型用于从文本库中发现有代表性的主题(得到每个主题上面词的分布特性),并且能够计算出每篇文章的主题分布
6.3 词嵌入与深度学习模型
由于词嵌入将每个词映射成一个K维的向量,如果一篇文档有N个词,就可以用一个N×K维的矩阵来表示这篇文档,但是这样的表示过于底层。
7、Word2Vec是如何工作的?它和LDA有什么区别与联系?
Word2Vec实际是一种浅层的神经网络模型,它有两种网络结构,分别是CBOW(Continues Bagof Words)和Skip-gram。
7.1 CBOW
CBOW的目标是根据上下文出现的词语来预测当前词的生成概率
而Skip-gram是根据当前词来预测上下文中各词的生成概率
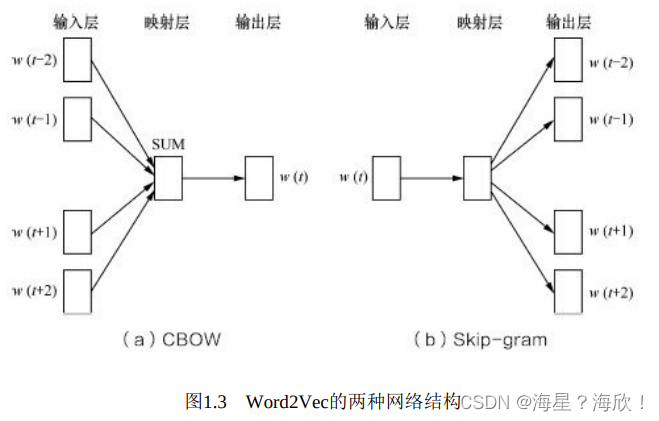
CBOW和Skip-gram都可以表示成由输入层(Input)、映射层(Projection)和输出层(Output)组成的神经网络。
输入层中的每个词由独热编码方式表示,即所有词均表示成一个N维向量,其中N为词汇表中单词的总数。在向量中,每个词都将与之对应的维度置为1,其余维度的值均设为0。
在映射层(又称隐含层)中,K个隐含单元(Hidden Units)的取值可以由N维输入向量以及连接输入和隐含单元之间的N×K维权重矩阵计算得到。在CBOW中,还需要将各个输入词所计算出的隐含单元求和。
同理,输出层向量的值可以通过隐含层向量(K维),以及连接隐含层和输出层之间的K×N维权重矩阵计算得到。输出层也是一个N维向量,每维与词汇表中的一个单词相对应。最后,对输出层向量应用Softmax激活函数,可以计算出每个单词的生成概率。Softmax激活函数的定义为

接下来的任务就是训练神经网络的权重,使得语料库中所有单词的整体生成概率最大化。