论文链接:https://arxiv.org/pdf/2003.00410.pdf![]() https://arxiv.org/pdf/2003.00410.pdf PF-Net是一个点云补全模型,整体网络为生成对抗网络(Gan)构成,G网络负责生成缺失的数据,D网络负责鉴别G网络生成的数据。
https://arxiv.org/pdf/2003.00410.pdf PF-Net是一个点云补全模型,整体网络为生成对抗网络(Gan)构成,G网络负责生成缺失的数据,D网络负责鉴别G网络生成的数据。
1、数据集的制作
PF-Net预测缺失的点云数据,因此在制作数据集时,需要随机扔掉一个方向的数据,代码如下。这里扔掉的点会记录作为lable与预测值进行loss计算。
# 对于每一个对象,在提供的5个区域中随机选择一个丢失的区域
choice = [torch.Tensor([1, 0, 0]), torch.Tensor([0, 0, 1]), torch.Tensor([1, 0, 1]), torch.Tensor([-1, 0, 0]), torch.Tensor([-1, 1, 0])]除此之外,作者在输入数据的时候,将点固定在2048个点,也就是说不论进来的数据是什么,都将被采样为2048个点,这里的采样方式为随机采样(踩坑:我改代码改为最远点采样方式后效果奇差)。
2、特征提取
输入G网络的数据将会被分为三份输入网络,由于每个点云数据所构成的点的数量是不一样的,为了方便网络提取特征,需要设定一个定值,通常需要采样,但是每次采样的方式又会影响网络训练效果,作者索性用三次采样,每次采样都采样固定的点数,这里分别为512、1024、2048。采样方式采用最远点采样,上面说到会随机丢到一部分的点,这里每个采样后的点会丢失的数量分别为64、128、512。如图1所示,一个点云数据的不同点数的最远点采样。
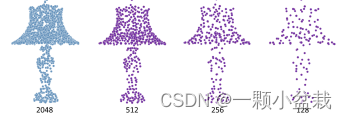
图1 最远点采样
特征提取方面,这里作者使用了一种叫CMLP的方法,这种方法其实类似于二维图像中的特征金字塔,CMLP在MLP的基础上加入了特征拼接,这里面就包含了浅层语义信息。如图2所示,左侧为MLP,右侧为CMLP。

图2 MLP和CMLP
前面说到,将会有同一数据的三次最远点采用的数据进入到G网络中,因此每个最远点采样后的数据都需要做一次CMLP,然后将做完的特征拼接起来,如图3所示。

图3 三次最远点采样的结果分别进行CMLP
接下来,对得到的特征进行进一步的特征提取,经过MLP和Linear后会得到三种不同长度的特征,分别为1024,512,256。这些特征会通过进一步的卷积得到预测点,如图4所示。
图4 G网络
其中,每一种长度的卷积结果还会和其他层相加进行预测,得到的预测点分别和真实的值做欧式距离(CD)计算。这里就会引入损失函数,即希望CD值越小越好。文章中的损失函数为:

3、D网络
鉴别器(D网络)主要鉴别生成器(G网络)生成的预测数据是否为真实的,为了能让D网络知道哪些是真实数据,哪些为假的的数据。因此,作者直接告诉了D网络,在生成数据部分,我么说过有真实的label,将这些真实的数据喂入D网络,希望D网络的损失值越小越好。同时我们也有G网络生成的数据喂给D网络,并且告知是假数据,这样的话就希望损失值越大约好。这里的损失函数为:

公式里第一部分求的是真实值,其loss越小越好,本来公式里的第二部分输入假数据希望求最大值的,取个反就变成求最小值了。
最后训练时,我们只需要追求一个统一的loss就可以了,把G、D网络的Loss加在一起计算最小值,公示如下:
![]()
两个入为权重系数,他们的合为1。再看下总体的图,如图5下面的虚线内为D网络。
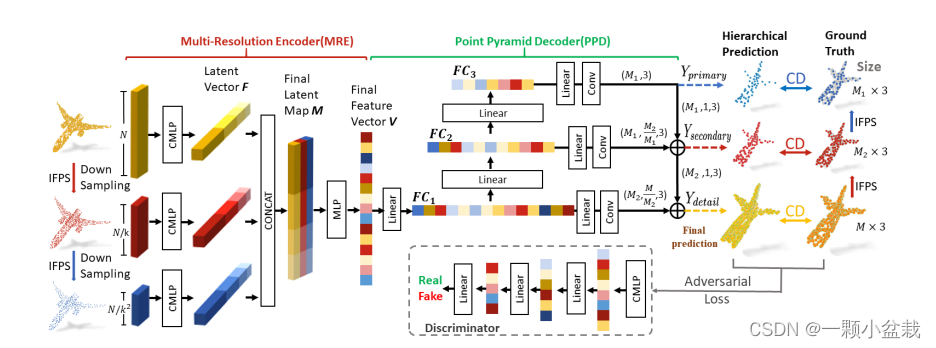
图5 PF-Net总体图
至此,网络讲解结束。
tips:原文的代码有些bug,需要代码的和实在有不懂的联系我1049632143,说明来意。