一 Hive基本概念
1 Hive简介
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WdaOJx7I-1688473420753)(/img/hive.jpg)]](https://img-blog.csdnimg.cn/82ab4124143b4297bb0851b53d626088.png)
学习目标
- 了解什么是Hive
- 了解为什么使用Hive
1.1 什么是 Hive
- Hive 由 Facebook 实现并开源,是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据映射为一张数据库表 ,并提供 HQL(Hive SQL)查询功能,底层数据是存储在 HDFS 上。
- Hive 本质: 将 SQL 语句转换为 MapReduce 任务运行,使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,是一款基于 HDFS 的 MapReduce 计算框架
- 主要用途:用来做离线数据分析,比直接用 MapReduce 开发效率更高。
1.2 为什么使用 Hive
-
直接使用 Hadoop MapReduce 处理数据所面临的问题:
- 人员学习成本太高
- MapReduce 实现复杂查询逻辑开发难度太大
-
使用 Hive
-
操作接口采用类 SQL 语法,提供快速开发的能力
-
避免了去写 MapReduce,减少开发人员的学习成本
-
功能扩展很方便
-
2 Hive 架构
2.1 Hive 架构图
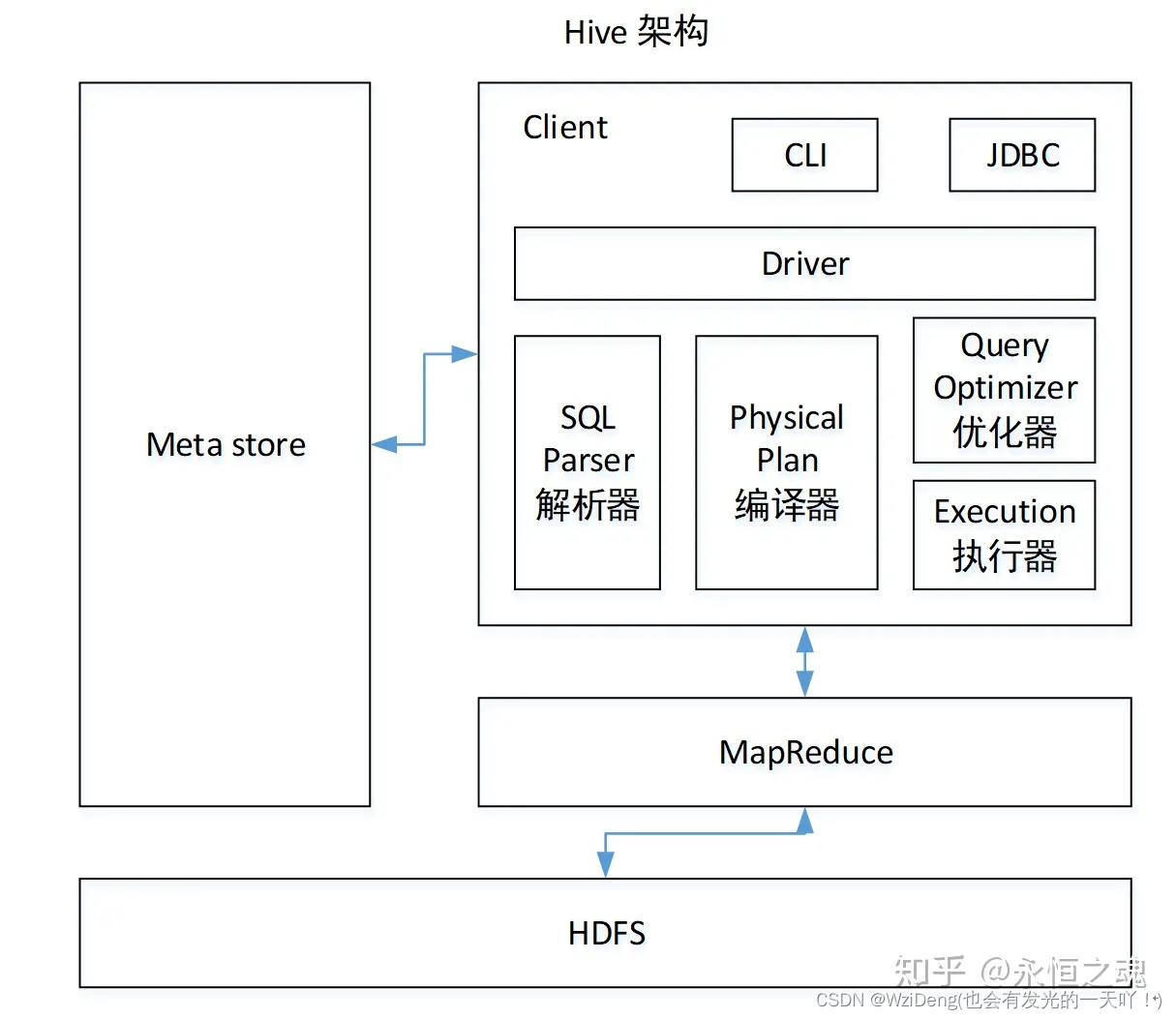
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iIsfJWo2-1688473420755)(/img/hive2.jpg)]](https://img-blog.csdnimg.cn/ffd37b6a4d4141098c837be4271ace8d.png)
2.2 Hive 组件
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。
- CLI(command line interface)为 shell 命令行
- JDBC/ODBC 是 Hive 的 JAVA 实现,与传统数据库JDBC 类似
- WebGUI 是通过浏览器访问 Hive。
- HiveServer2基于Thrift, 允许远程客户端使用多种编程语言如Java、Python向Hive提交请求
- 元数据存储:通常是存储在关系数据库如 mysql/derby 中。
- Hive 将元数据存储在数据库中。
- Hive 中的元数据包括
- 表的名字
- 表的列
- 分区及其属性
- 表的属性(是否为外部表等)
- 表的数据所在目录等。
- 解释器、编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行
2.3 Hive 与 Hadoop 的关系
Hive 利用 HDFS 存储数据,利用 MapReduce 查询分析数据。
3 Hive 与传统数据库对比
- hive 用于海量数据的离线数据分析。
| Hive | 关系型数据库 | |
|---|---|---|
| ANSI SQL | 不完全支持 | 支持 |
| 更新 | INSERT OVERWRITE\INTO TABLE(默认) | UPDATE\INSERT\DELETE |
| 事务 | 不支持(默认) | 支持 |
| 模式 | 读模式 | 写模式 |
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 执行 | MapReduce | Executor |
| 执行延迟 | 高 | 低 |
| 子查询 | 只能用在From子句中 | 完全支持 |
| 处理数据规模 | 大 | 小 |
| 可扩展性 | 高 | 低 |
| 索引 | 0.8版本后加入位图索引 | 有复杂的索引 |
- hive支持的数据类型
- 原子数据类型
- TINYINT SMALLINT INT BIGINT BOOLEAN FLOAT DOUBLE STRING BINARY TIMESTAMP DECIMAL CHAR VARCHAR DATE
- 复杂数据类型
- ARRAY
- MAP
- STRUCT
- 原子数据类型
- hive中表的类型
- 托管表 (managed table) (内部表)
- 外部表
4 Hive 数据模型
- Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式
- 在创建表时指定数据中的分隔符,Hive 就可以映射成功,解析数据。
- Hive 中包含以下数据模型:
- db:在 hdfs 中表现为 hive.metastore.warehouse.dir 目录下一个文件夹
- table:在 hdfs 中表现所属 db 目录下一个文件夹
- external table:数据存放位置可以在 HDFS 任意指定路径
- partition:在 hdfs 中表现为 table 目录下的子目录
- bucket:在 hdfs 中表现为同一个表目录下根据 hash 散列之后的多个文件
5 Hive 安装部署
-
Hive 安装前需要安装好 JDK 和 Hadoop。配置好环境变量。
-
下载Hive的安装包 http://archive.cloudera.com/cdh5/cdh/5/ 并解压
tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C ~/app/ -
进入到 解压后的hive目录 找到 conf目录, 修改配置文件
cp hive-env.sh.template hive-env.sh vi hive-env.sh在hive-env.sh中指定hadoop的路径
HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0 -
配置环境变量
-
vi ~/.bash_profile -
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0 export PATH=$HIVE_HOME/bin:$PATH -
source ~/.bash_profile
-
-
根据元数据存储的介质不同,分为下面两个版本,其中 derby 属于内嵌模式。实际生产环境中则使用 mysql 来进行元数据的存储。
-
内置 derby 版:
bin/hive 启动即可使用
缺点:不同路径启动 hive,每一个 hive 拥有一套自己的元数据,无法共享 -
mysql 版:
-
上传 mysql驱动到 hive安装目录的lib目录下
mysql-connector-java-5.*.jar
-
vi conf/hive-site.xml 配置 Mysql 元数据库信息(MySql安装见文档)
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 插入以下代码 --> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value><!-- 指定mysql用户名 --> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value><!-- 指定mysql密码 --> </property> <property> <name>javax.jdo.option.ConnectionURL</name>mysql <value>jdbc:mysql://127.0.0.1:3306/hive</value> </property><!-- 指定mysql数据库地址 --> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value><!-- 指定mysql驱动 --> </property> <!-- 到此结束代码 --> <property> <name>hive.exec.script.wrapper</name> <value/> <description/> </property> </configuration>
-
-
二 Hive 基本操作
1 DDL 操作
1.1 创建表
-
建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], …)][COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], …)]
[CLUSTERED BY (col_name, col_name, …)
[SORTED BY (col_name [ASC|DESC], …)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
说明:
1、 CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;
用户可以用 IF NOT EXISTS 选项来忽略这个异常。
2、 EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据
的路径(LOCATION)。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,
仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的
元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
3、 LIKE 允许用户复制现有的表结构,但是不复制数据。
CREATE [EXTERNAL] TABLE [IF NOT EXISTS][db_name.]table_name LIKE existing_table;4、 ROW FORMAT DELIMITED
[FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char] | SERDE serde_name
[WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value,…)]
hive 建表的时候默认的分割符是’\001’,若在建表的时候没有指明分隔符,
load 文件的时候文件的分隔符需要是’\001’;若文件分隔符不是’001’,程序不会
报错,但表查询的结果会全部为’null’;
用 vi 编辑器 Ctrl+v 然后 Ctrl+a 即可输入’\001’ -----------> ^A
SerDe 是 Serialize/Deserilize 的简称,目的是用于序列化和反序列化。
Hive 读取文件机制:首先调用 InputFormat(默认 TextInputFormat),返回一条一条记录(默认是一行对应一条记录)。然后调用 SerDe(默认LazySimpleSerDe)的 Deserializer,将一条记录切分为各个字段(默认’\001’)。
Hive 写文件机制:将 Row 写入文件时,主要调用 OutputFormat、SerDe 的Seriliazer,顺序与读取相反。
可通过 desc formatted 表名;进行相关信息查看。
当我们的数据格式比较特殊的时候,可以自定义 SerDe。
5、 PARTITIONED BY
在 hive Select 查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了 partition 分区概念。
分区表指的是在创建表时指定的 partition 的分区空间。一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。表和列名不区分大小写。分区是以字段的形式在表结构中存在,通过 describe table 命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。6、 STORED AS SEQUENCEFILE|TEXTFILE|RCFILE
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,
使用 STORED AS SEQUENCEFILE。
TEXTFILE 是默认的文件格式,使用 DELIMITED 子句来读取分隔的文件。
7、CLUSTERED BY INTO num_buckets BUCKETS
对于每一个表(table)或者分,Hive 可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive 也是针对某一列进行桶的组织。Hive 采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如 JOIN 操作。对于 JOIN 操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行 JOIN 操作就可以,可以大大较少 JOIN 的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
1.2 修改表
- 增加分区:
ALTER TABLE table_name ADD PARTITION (dt=‘20170101’) location
‘/user/hadoop/warehouse/table_name/dt=20170101’; //一次添加一个分区
ALTER TABLE table_name ADD PARTITION (dt=‘2008-08-08’, country=‘us’) location
‘/path/to/us/part080808’ PARTITION (dt=‘2008-08-09’, country=‘us’) location
‘/path/to/us/part080809’; //一次添加多个分区 - 删除分区
ALTER TABLE table_name DROP IF EXISTS PARTITION (dt=‘2008-08-08’);
ALTER TABLE table_name DROP IF EXISTS PARTITION (dt=‘2008-08-08’, country=‘us’); - 修改分区
ALTER TABLE table_name PARTITION (dt=‘2008-08-08’) RENAME TO PARTITION (dt=‘20080808’); - 添加列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name STRING);
注:ADD 是代表新增一个字段,新增字段位置在所有列后面(partition 列前)
REPLACE 则是表示替换表中所有字段。 - 修改列
test_change (a int, b int, c int);
ALTER TABLE test_change CHANGE a a1 INT; //修改 a 字段名
// will change column a’s name to a1, a’s data type to string, and put it after column b. The new
table’s structure is: b int, a1 string, c int
ALTER TABLE test_change CHANGE a a1 STRING AFTER b;
// will change column b’s name to b1, and put it as the first column. The new table’s structure is:
b1 int, a ints, c int
ALTER TABLE test_change CHANGE b b1 INT FIRST; - 表重命名
ALTER TABLE table_name RENAME TO new_table_name
1.3 显示命令
- show tables;
显示当前数据库所有表 - show databases |schemas;
显示所有数据库 - show partitions table_name;
显示表分区信息,不是分区表执行报错 - show functions;
显示当前版本 hive 支持的所有方法 - desc extended table_name;
查看表信息 - desc formatted table_name;
查看表信息(格式化美观) - describe database database_name;
查看数据库相关信息
2 DML 操作
2.1 Load
在将数据加载到表中时,Hive 不会进行任何转换。加载操作是将数据文件移动到与 Hive
表对应的位置的纯复制/移动操作。
- 语法结构
LOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO
TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 …)] - 说明:
1、 filepath
相对路径,例如:project/data1
绝对路径,例如:/user/hive/project/data1
完整 URI,例如:hdfs://namenode:9000/user/hive/project/data1
filepath 可以引用一个文件(在这种情况下,Hive 将文件移动到表中),或者它可以是一个目录(在这种情况下,Hive 将把该目录中的所有文件移动到表中)。
2、 LOCAL
如果指定了 LOCAL, load 命令将在本地文件系统中查找文件路径。
load 命令会将 filepath 中的文件复制到目标文件系统中。目标文件系统由表
的位置属性决定。被复制的数据文件移动到表的数据对应的位置。
如果没有指定 LOCAL 关键字,如果 filepath 指向的是一个完整的 URI,hive
会直接使用这个 URI。 否则:如果没有指定 schema 或者 authority,Hive 会使
用在 hadoop 配置文件中定义的 schema 和 authority,fs.default.name 指定了
Namenode 的 URI。
3、 OVERWRITE
如果使用了 OVERWRITE 关键字,则目标表(或者分区)中的内容会被删除,
然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。
如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,
那么现有的文件会被新文件所替代。
2.2 Insert
- Hive 中 insert 主要是结合 select 查询语句使用,将查询结果插入到表中,例如:
insert overwrite table stu_buck
select * from student cluster by(Sno);
需要保证查询结果列的数目和需要插入数据表格的列数目一致. - 如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但
是不能保证转换一定成功,转换失败的数据将会为 NULL。
可以将一个表查询出来的数据插入到原表中, 结果相当于自我复制了一份数据。 - Multi Inserts 多重插入:
from source_table
insert overwrite table tablename1 [partition (partcol1=val1,partclo2=val2)]
select_statement1
insert overwrite table tablename2 [partition (partcol1=val1,partclo2=val2)]
select_statement2… - Dynamic partition inserts 动态分区插入:
INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] …)
select_statement FROM from_statement - 动态分区是通过位置来对应分区值的。原始表 select 出来的值和输出 partition
的值的关系仅仅是通过位置来确定的,和名字并没有关系。 - 导出表数据
语法结构
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 SELECT … FROM …
multiple inserts:
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] …
数据写入到文件系统时进行文本序列化,且每列用^A 来区分,\n 为换行符
2.3 Select
-
基本的 Select 操作
-
语法结构
SELECT [ALL | DISTINCT] select_expr, select_expr, …
FROM table_reference
JOIN table_other ON expr[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list]
[SORT BY| ORDER BY col_list]
][LIMIT number]
-
说明:
1、order by 会对输入做全局排序,因此只有一个 reducer,会导致当输入规模较大时,
需要较长的计算时间。
2、sort by 不是全局排序,其在数据进入 reducer 前完成排序。因此,如果用 sort by 进
行排序,并且设置 mapred.reduce.tasks>1,则 sort by 只保证每个 reducer 的输出有序,不保
证全局有序。
3、distribute by(字段)根据指定字段将数据分到不同的 reducer,分发算法是 hash 散列。
4、Cluster by(字段) 除了具有 Distribute by 的功能外,还会对该字段进行排序。
如果 distribute 和 sort 的字段是同一个时,此时,cluster by = distribute by + sort by
-
3 Hive join
Hive 中除了支持和传统数据库中一样的内关联、左关联、右关联、全关联,还支持 LEFT SEMI JOIN 和 CROSS JOIN,但这两种 JOIN 类型也可以用前面的代替。
Hive 支持等值连接(a.id = b.id),不支持非等值(a.id>b.id)的连接,因为非等值连接非常难转化到 map/reduce 任务。另外,Hive 支持多 2 个以上表之间的 join。
写 join 查询时,需要注意几个关键点:
-
join 时,每次 map/reduce 任务的逻辑:
reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统。这一实现有助于在 reduce 端减少内存的使用量。实践中,应该把最大的那个表写在最后(否则会因为缓存浪费大量内存)。 -
LEFT,RIGHT 和 FULL OUTER 关键字用于处理 join 中空记录的情况
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
对应所有 a 表中的记录都有一条记录输出。输出的结果应该是 a.val, b.val,当a.key=b.key 时,而当 b.key 中找不到等值的 a.key 记录时也会输出:a.val, NULL所以 a 表中的所有记录都被保留了;“a RIGHT OUTER JOIN b”会保留所有 b 表的记录。 -
Join 发生在 WHERE 子句之前。
如果你想限制 join 的输出,应该在 WHERE 子句中写过滤条件——或是在 join 子句中写。这里面一个容易混淆的问题是表分区的情况:
SELECT a.val, b.val FROM a
LEFT OUTER JOIN b ON (a.key=b.key)
WHERE a.ds=‘2009-07-07’ AND b.ds=‘2009-07-07’
这会 join a 表到 b 表(OUTER JOIN),列出 a.val 和 b.val 的记录。WHERE 从句中可以使用其他列作为过滤条件。但是,如前所述,如果 b 表中找不到对应 a 表的记录,b 表的所有列都会列出 NULL,包括 ds 列。也就是说,join 会过滤 b 表中不能找到匹配 a 表 join key 的所有记录。这样的话,LEFT OUTER 就使得查询结果与 WHERE 子句无关了。解决的办法是在 OUTER JOIN 时使用以下语法:
SELECT a.val, b.val FROM a LEFT OUTER JOIN bON (a.key=b.key AND
b.ds=‘2009-07-07’ AND
a.ds=‘2009-07-07’)
这一查询的结果是预先在 join 阶段过滤过的,所以不会存在上述问题。这一逻辑也
可以应用于 RIGHT 和 FULL 类型的 join 中。 -
Join 是不能交换位置的。
无论是 LEFT 还是 RIGHT join,都是左连接的。
SELECT a.val1, a.val2, b.val, c.val
FROM a
JOIN b ON (a.key = b.key)
LEFT OUTER JOIN c ON (a.key = c.key)
先 join a 表到 b 表,丢弃掉所有 join key 中不匹配的记录,然后用这一中间结果和 c 表做 join。
三 Hive 参数配置
1 Hive 命令行
-
输入$HIVE_HOME/bin/hive –H 或者 –help 可以显示帮助选项:
说明:
1、 -i 初始化 HQL 文件。
2、 -e 从命令行执行指定的 HQL
3、 -f 执行 HQL 脚本
4、 -v 输出执行的 HQL 语句到控制台
5、 -p connect to Hive Server on port number
6、 -hiveconf x=y Use this to set hive/hadoop configuration variables.例如:
$HIVE_HOME/bin/hive -e ‘select * from tab1 a’
$HIVE_HOME/bin/hive -f /home/my/hive-script.sql
$HIVE_HOME/bin/hive -f hdfs://:/hive-script.sql
$HIVE_HOME/bin/hive -i /home/my/hive-init.sql
$HIVE_HOME/bin/hive -e ‘select a.col from tab1 a’
–hiveconf hive.exec.compress.output=true
–hiveconf mapred.reduce.tasks=32
2 Hive 参数配置方式
Hive 参数大全:
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
开发 Hive 应用时,不可避免地需要设定 Hive 的参数。设定 Hive 的参数可以调优 HQL 代码的执行效率,或帮助定位问题。然而实践中经常遇到的一个问题是,为什么设定的参数没有起作用?这通常是错误的设定方式导致的。
对于一般参数,有以下三种设定方式:
- 配置文件 (全局有效)
- 命令行参数 (对 hive 启动实例有效)
- 参数声明 (对 hive 的连接 session 有效)
配置文件
用户自定义配置文件:$HIVE_CONF_DIR/hive-site.xml
默认配置文件:$HIVE_CONF_DIR/hive-default.xml
用户自定义配置会覆盖默认配置。
另外,Hive 也会读入 Hadoop 的配置,因为 Hive 是作为 Hadoop 的客户端启动的,
Hive 的配置会覆盖 Hadoop 的配置。
配置文件的设定对本机启动的所有 Hive 进程都有效。
命令行参数
启动 Hive(客户端或 Server 方式)时,可以在命令行添加-hiveconf 来设定参数
例如:bin/hive -hiveconf hive.root.logger=INFO,console
设定对本次启动的 Session(对于 Server 方式启动,则是所有请求的 Sessions)有效。
参数声明
可以在 HQL 中使用 SET 关键字设定参数,这一设定的作用域也是 session 级的。
比如:
set hive.exec.reducers.bytes.per.reducer= 每个 reduce task 的平均负载数据量
set hive.exec.reducers.max= 设置 reduce task 数量的上限
set mapreduce.job.reduces= 指定固定的 reduce task 数量
但是,这个参数在必要时<业务逻辑决定只能用一个 reduce task> hive 会忽略
上述三种设定方式的优先级依次递增。即参数声明覆盖命令行参数,命令行参数覆盖配
置文件设定。注意某些系统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因
为那些参数的读取在 Session 建立以前已经完成了
四 Hive 函数
1 内置运算符
在 Hive 有四种类型的运算符:
-
关系运算符
-
算术运算符
-
逻辑运算符
-
复杂运算
(内容较多,见《Hive 官方文档》或者《hive 常用运算和函数.doc》)
2 内置函数
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
- 简单函数: 日期函数 字符串函数 类型转换
- 统计函数: sum avg distinct
- 集合函数
- 分析函数
- show functions; 显示所有函数
- desc function ***
- desc function extanded ***
3 Hive 自定义函数和 Transform
-
UDF
-
当 Hive 提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
-
TRANSFORM,and UDF and UDAF
it is possible to plug in your own custom mappers and reducers
A UDF is basically only a transformation done by a mapper meaning that each row should be mapped to exactly one row. A UDAF on the other hand allows us to transform a group of rows into one or more rows, meaning that we can reduce the number of input rows to a single output row by some custom aggregation.
UDF:就是做一个mapper,对每一条输入数据,映射为一条输出数据。
UDAF:就是一个reducer,把一组输入数据映射为一条输出数据。
一个脚本至于是做mapper还是做reducer,又或者是做udf还是做udaf,取决于我们把它放在什么要的hive操作符中。放在select中的基本就是udf,放在distribute by和cluster by中的就是reducer。
We can control if the script is run in a mapper or reducer step by the way we formulate our HiveQL query.
The statements DISTRIBUTE BY and CLUSTER BY allow us to indicate that we want to actually perform an aggregation.
User-Defined Functions (UDFs) for transformations and even aggregations which are therefore called User-Defined Aggregation Functions (UDAFs)
-
-
UDF示例(运行java编写的UDF)
hadoop fs -mkdir /user/hive/lib hadoop fs -put hive-contrib-2.0.1.jar /user/hive/lib/ hive> add jar hdfs:///user/hive/lib/hive-contrib-2.0.1.jar; hive> CREATE TEMPORARY FUNCTION row_sequence as 'org.apache.hadoop.hive.contrib.udf.UDFRowSequence' Select row_sequence(),* from test; CREATE FUNCTION test.row_sequence as 'org.apache.hadoop.hive.contrib.udf.UDFRowSequence' using jar 'hdfs:///user/hive/lib/hive-contrib-2.0.1.jar' -
Python UDF
-
编写map风格脚本
import sys for line in sys.stdin: line = line.strip() fname , lname = line.split('\t') l_name = lname.upper() print '\t'.join([fname, str(l_name)]) -
ADD file
CREATE table u( fname STRING, lname STRING); insert into table u values('asdf','asdf'); insert into table u values('asdf2','asdf'); insert into table u values('asdf3','asdf'); insert into table u values('asdf4','asdf'); hadoop fs -put udf.py /user/hive/lib/ ADD FILE hdfs:///user/hive/lib/udf.py; -
Transform
SELECT TRANSFORM(fname, lname) USING 'udf.py' AS (fname, l_name) FROM u; SELECT TRANSFORM(fname, lname) USING 'python2.6 udf.py' AS (fname, l_name) FROM u;
-
-
Python UDAF
-
准备数据
USE test; CREATE TABLE foo (id INT, vtype STRING, price FLOAT); INSERT INTO TABLE foo VALUES (1, "car", 1000.); INSERT INTO TABLE foo VALUES (2, "car", 42.); INSERT INTO TABLE foo VALUES (3, "car", 10000.); INSERT INTO TABLE foo VALUES (4, "car", 69.); INSERT INTO TABLE foo VALUES (5, "bike", 1426.); INSERT INTO TABLE foo VALUES (6, "bike", 32.); INSERT INTO TABLE foo VALUES (7, "bike", 1234.); INSERT INTO TABLE foo VALUES (8, "bike", null); -
hdfs中安装pandas numpy
pip install virtualenv virtualenv --no-site-packages -p /usr/local/Python-2.7.11/bin/python penv27 -p:指定使用的pytohn版本号 source venv/bin/activate pip install pandas cd venv tar zcvfh ../penv27.tar ./ “-h”的参数:它会把符号链接文件视作普通文件或目录,从而打包的是源文件 hadoop fs -put penv27.tar /user/hive/lib/ hadoop fs -ls /user/hive/lib hadoop fs -put udaf.py /user/hive/lib/ hadoop fs -put udaf.sh /user/hive/libhdfs中运行脚本
#!/bin/bash set -e (>&2 echo "Begin of script") source ./penv27.tar/bin/activate (>&2 echo "Activated venv") ./penv27.tar/bin/python udaf.py (>&2 echo "End of script") -
编写reduce风格脚本
import sys import logging from itertools import groupby from operator import itemgetter import numpy as np import pandas as pd SEP = ',' NULL = '\\N' _logger = logging.getLogger(__name__) def read_input(input_data): for line in input_data: yield line.strip().split(SEP) def main(): logging.basicConfig(level=logging.INFO, stream=sys.stderr) data = read_input(sys.stdin) for vtype, group in groupby(data, itemgetter(1)): _logger.info("Reading group {}...".format(vtype)) group = [(int(rowid), vtype, np.nan if price == NULL else float(price)) for rowid, vtype, price in group] df = pd.DataFrame(group, columns=('id', 'vtype', 'price')) output = [vtype, df['price'].mean(), df['price'].std()] print(SEP.join(str(o) for o in output)) if __name__ == '__main__': main() -
ADD file
DELETE ARCHIVE hdfs:///user/hive/lib/penv27.tar; ADD ARCHIVE hdfs:///user/hive/lib/penv27.tar; DELETE FILE hdfs:///user/hive/lib/udaf.py; ADD FILE hdfs:///user/hive/lib/udaf.py; DELETE FILE hdfs:///user/hive/lib/udaf.sh; ADD FILE hdfs:///user/hive/lib/udaf.sh; -
Transform
USE test; SELECT TRANSFORM(id, vtype, price) USING 'udaf.sh' AS (vtype STRING, mean FLOAT, var FLOAT) FROM (SELECT * FROM foo CLUSTER BY vtype) AS TEMP_TABLE;
-