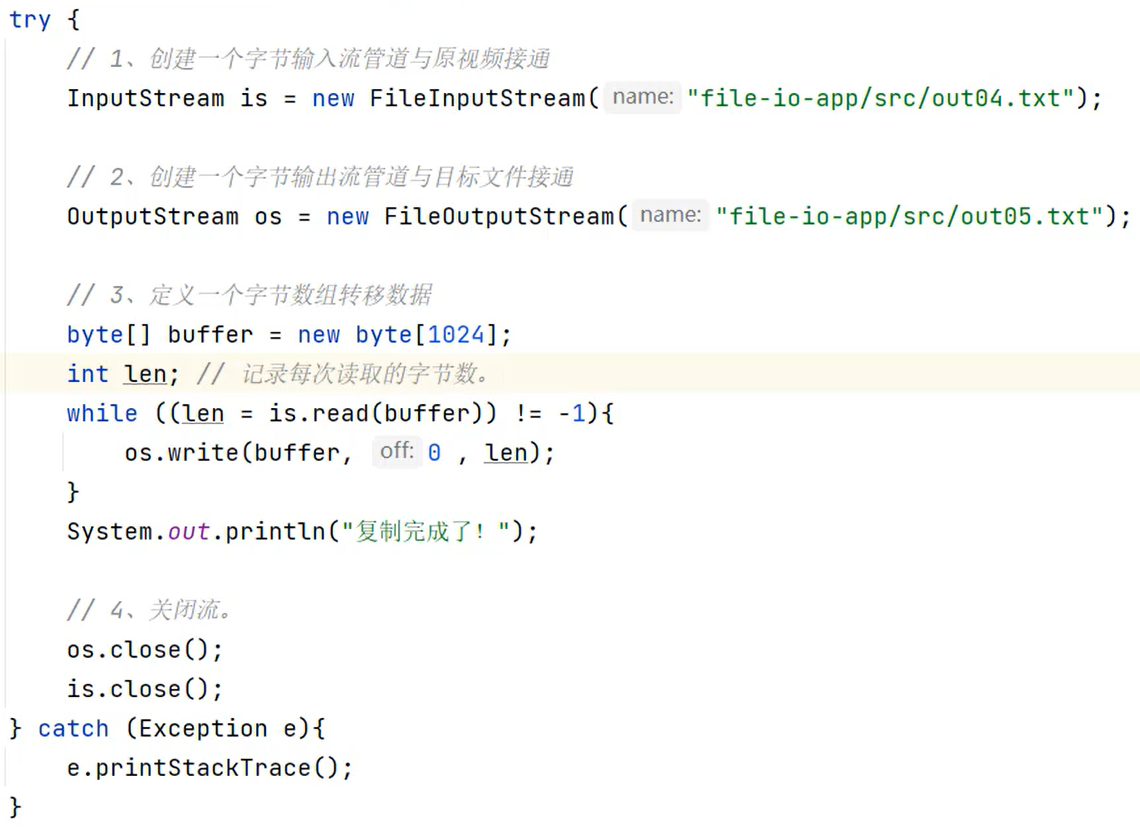
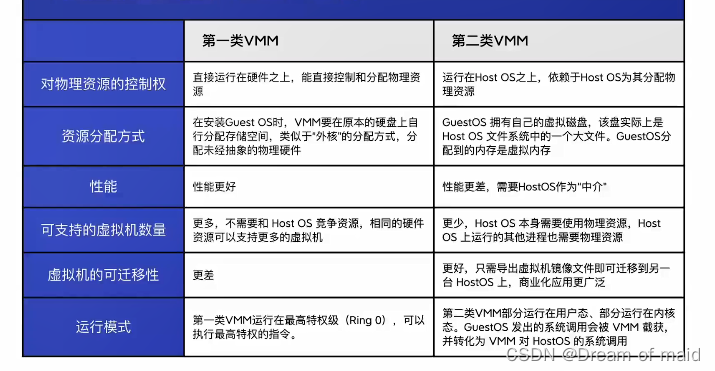
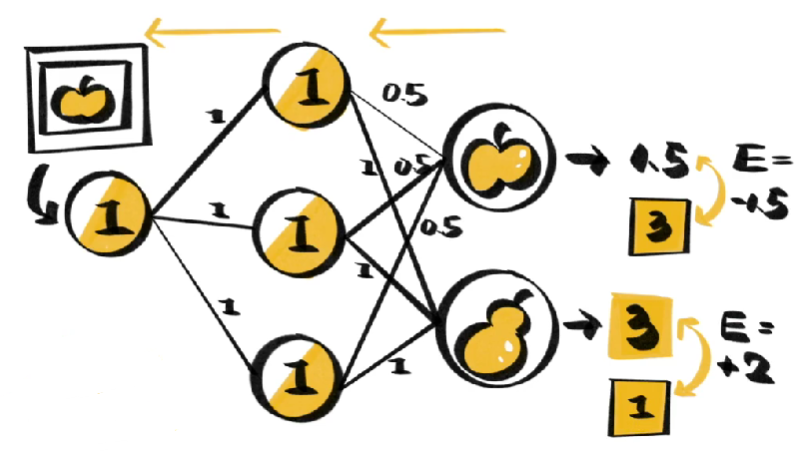
-
XPhoneBERT|文本到语音转换的音素表示的预训练多语言模型
XPhoneBERT: A Pre-trained Multilingual Model for Phoneme Representations for Text-to-Speech
Linh The Nguyen, Thinh Pham, Dat Quoc Nguyen
Github地址:https://github.com/VinAIResearch/XPhoneBERT
论文地址:https://arxiv.org/abs/2305.19709
XPhoneBERT是第一个预先训练用于学习下游文本到语音(TTS)任务的音素表示的多语言模型。我们的XPhoneBERT具有与BERT基础相同的模型架构,使用RoBERTa预训练方法对近100种语言和地区的3.3亿音素级句子进行训练。
使用XPhoneBERT作为输入音素编码器,在自然性和韵律方面显著提高了强神经TTS模型的性能,还有助于在训练数据有限的情况下产生相当高质量的语音。
XPhoneBERT可以与HuggingFace的变压器库一起使用。此外,我们还使用我们的XPhoneBERT编码器扩展了强神经TTS基线的实现。
-
人机视频对话|Video-LLaMA多模态框架,使大型语言模型具备了理解视频内容的能力
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, Lidong Bing
[Alibaba Group]Video-LLaMA:面向视频理解的指令微调音频-视觉语言模型
动机:为了赋予大型语言模型(LLM)理解视频中的视觉和听觉内容的能力,提出了一种新的多模态框架Video-LLaMA。与之前关注静态图像理解的视觉-LLM不同,Video-LLaMA解决了视频理解中的两个挑战:捕捉视觉场景的时序变化和集成音频-视觉信号。
方法:使用Video Q-former将预训练的图像编码器扩展为视频编码器,引入视频到文本生成任务学习视频和语言之间的对应关系。同时,利用预训练的音频编码器ImageBind,在一个共享的嵌入空间中对齐不同模态的输出。通过在大规模视觉描述数据集和大量视觉指令微调数据集上训练Video-LLaMA,使其能感知和理解视频内容。
优势:论文的主要优势是提出了Video-LLaMA框架,使得大型语言模型具备了理解视频内容的能力,并能生成与视频中的视听信息相关的有意义的回应。这突显了Video-LLaMA作为有潜力的音视频AI助手的潜力。
本文提出了Video-LLaMA,一种多模态框架,通过连接语言解码器和预训练的单模态模型,实现了人机之间基于视频的对话,为大型语言模型赋予了视频理解能力。
https://arxiv.org/abs/2306.02858
-
谷歌|面向弱监督学习的局部增强
Local Boosting for Weakly-Supervised Learning
Rongzhi Zhang, Yue Yu, Jiaming Shen, Xiquan Cui, Chao Zhang
[Georgia Institute of Technology & Google Research]面向弱监督学习的局部增强
动机:提出一种针对弱监督学习的局部增强(LocalBoost)框架,以改进弱监督学习中的性能表现,因为在弱监督学习中,数据通常通过弱的、含噪的来源进行标记,因此设计有效的增强方法是具有挑战性的。
方法:提出一种名为LocalBoost的弱监督增强框架,通过两个维度(源内和源间)迭代增强集合模型。其中,源内增强引入局部性,让基础学习器专注于特定的特征域,并通过在不同粒度的错误域上训练新的基础学习器。源间增强利用条件函数指示样本更有可能出现在哪个弱源中。为了处理弱标签,还设计了一种估计-修改方法来计算模型权重。优势:提出一种针对弱监督学习的新型增强框架LocalBoost,该框架在七个数据集上实验证明明显优于传统增强方法和其他弱监督学习方法。
提出一种名为LocalBoost的局部增强框架,解决了弱监督学习中的性能问题,通过引入局部性和处理弱标签等创新点,实现了优于传统方法和其他弱监督学习方法的效果。
论文地址:https://arxiv.org/abs/2306.02859
-
斯坦福|多任务无需标注,基于反事实世界建模的统一机器视觉
Unifying (Machine) Vision via Counterfactual World Modeling
Daniel M. Bear, Kevin Feigelis, Honglin Chen, Wanhee Lee, Rahul Venkatesh, Klemen Kotar, Alex Durango, Daniel L.K. Yamins
[Stanford University]
基于反事实世界建模的统一(机器)视觉
论文地址:https://arxiv.org/abs/2306.01828
动机:通过构建一个视觉基础模型来统一(机器)视觉领域。现有的机器视觉方法在不同任务上采用不同的架构,并在昂贵的任务特定标注数据集上进行训练。这种复杂性阻碍了机器人等领域在鲁棒的任务通用感知方面的进展。与之相反,自然语言领域的“基础模型”展示了大型预训练神经网络如何提供零样本解决方案来执行广泛的明显不同的任务。本论文引入反事实世界建模(CWM),一个构建视觉基础模型的框架:一个统一的无监督网络,可以通过提示执行各种视觉计算。
所提出的Counterfactual World Modeling(CWM)框架包含两个基本概念,建立在基础模型的两个基本组成部分之上:1. 通过结构化掩码预测进行预训练。研究发现,简单但非平凡的掩码变体能够产生高度不同的学习表示,从而使模型能够对场景、物体和动态的物理结构进行编码。2. 通过反事实提示建立通用任务接口。研究表明,通过对视觉输入进行简单修改并观察扰动后的模型响应,可以以零样本的方式提取核心计算机视觉概念。这些反事实可以数学上形式化为基础预测模型本身的导数,从而提供了识别“自然”反事实提示和使用自动求导方法高效实现的方式。
优势:通过CWM构建了高质量的视觉概念输出,包括关键点估计、光流、遮挡、目标分割和相对深度等多个任务,而无需任何标注数据。CWM的反事实物理推理能力适用于涉及模型预测控制和规划的应用,如机器人领域。还展示了CWM框架如何在现代基础模型框架中综合多种经典计算机视觉概念,为生物系统中这些能力的统一计算理论提供了实践解决方案。
提出了Counterfactual World Modeling(CWM)框架,通过结构化掩码预测和反事实提示,构建了一个统一的、无监督的视觉基础模型,能执行各种视觉计算。
-
Jim Fan等|Nvidia创建Minecraft机器人,使用GPT-4来解决游戏中的问题
Nvidia团队包括该公司的机器学习总监兼加州理工学院教授Anima Anandkumar,他们创建了一个名为Voyager的Minecraft机器人,该机器人使用GPT-4来解决游戏中的问题。语言模型生成帮助代理探索游戏的目标,以及随着时间的推移提高机器人游戏技能的代码https://voyager.minedojo.org。
芯片制造商Nvidia的人工智能研究员Jim Fan与一些同事合作,设计了一种方法来设置强大的语言模型GPT-4——ChatGPT背后的“大脑”和越来越多的其他应用程序和服务——视频游戏《我的世界》。
该项目最新颖的部分是GPT-4生成的代码,以向Voyager添加行为。如果最初建议的代码不能完美运行,Voyager将尝试使用错误消息、游戏反馈和GPT-4生成的代码描述来完善它。
Voyager构建了一个代码库,研究人员创建的图表显示了与其他《我的世界》代理相比,它的能力有多强。旅行者获得的物品数量是旅行者的三倍多;探索的距离是旅行者旅行者者多一倍的物品;构建工具的速度是其他人工智能代理的15倍。Fan说,随着系统加入游戏中视觉信息的方式,这种方法在未来可能会得到改进。
我们介绍了Voyager,这是Minecraft中第一个由LLM驱动的体现性终身学习代理,它不断探索世界,获得各种技能,并在没有人类干预的情况下做出新的发现。
项目地址:https://voyager.minedojo.org
论文地址:https://arxiv.org/abs/2305.16291
-
微软|Orca:从GPT-4的复杂解释轨迹中渐进式学
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, Ahmed Awadallah
[Microsoft Research]Orca:从GPT-4的复杂解释轨迹中渐进式学习
要点:
动机:针对小型模型通过模仿学习提高性能的问题。现有模型存在一系列问题,包括从浅层大型基础模型输出获取有限的模仿信号、小规模同质化训练数据,以及缺乏严格评估导致高估小模型的能力。因此,需要解决这些挑战。
方法:开发了Orca,一个拥有130亿参数的模型,学习模仿大型基础模型的推理过程。Orca从GPT-4获得丰富的信号,包括解释轨迹、逐步思维过程和其他复杂指令,通过ChatGPT的教师辅助进行指导。为了促进这种渐进式学习,论文利用大规模和多样化的模仿数据进行精心的采样和选择。
优势:Orca在复杂的零样本推理基准测试中超过了传统的最先进微调模型,如Vicuna-13B,提升了100%以上,并在AGIEval上提升了42%。此外,Orca在BBH基准测试上达到了与ChatGPT相当的水平,并在SAT、LSAT、GRE和GMAT等专业和学术考试中显示出竞争性能。研究表明,从逐步解释中学习是改进模型能力和技能的有希望的方向。
介绍了Orca,一个拥有130亿参数的模型,通过学习大型基础模型的推理过程,提高了小型模型的性能和能力。
https://arxiv.org/abs/2306.02707
-
真低代码!首个基于ChatGPT的自然语言开发框架PromptAppGPT:全自动编译、运行、界面生成
最近,CCF理论计算机科学技术委员会委员张长旺,开发了一个基于低代码提示语的快速应用开发框架PromptAppGPT,可以实现基于GPT的自然语言快速应用开发。
PromptAppGPT包含的功能有:低代码提示语(Prompt)应用开发、GPT文本生成、DALL-E图像生成、在线代码编辑器+编译器+运行器、自动用户界面生成、支持插件扩展等。
项目网站:https://promptappgpt.wangzhishi.net/
项目代码:https://github.com/mleoking/PromptAppGPT
PromptAppGPT提供多任务条件触发、结果验证和失败重试能力,可以让原本需要多步骤的手动生成任务变成自动完成。
同时,用户不再需要自己记忆和输入繁琐的Prompt咒语,只输入任务核心必要信息就可以轻松完成任务。
-
谷歌公开自家「AI+软件工程」框架DIDACT:数千名开发者内部测试,用了都说生产力高
最近,Google公布了自家的DIDACT(Dynamic Integrated Developer ACTivity,动态集成开发人员活动)框架,用AI技术增强软件工程,将软件开发的中间状态作为训练数据,辅助开发人员编写、修改代码,并实时了解软件开发的动态。
DIDACT是一个多任务模型,在编辑、调试、修复和代码审查在内的开发活动上进行训练
研究人员在内部构建并部署了三个DIDACT工具,注释解析、构建修复和提示预测,每个工具都集成在开发工作流程的不同阶段。
-
OpenAI霸榜前二!大模型代码生成排行榜出炉,70亿LLaMA拉跨,被2.5亿Codex吊打
最近,Matthias Plappert的一篇推文点燃了LLMs圈的广泛讨论。
Plappert是一位知名的计算机科学家,他在HumanEval上发布了自己对AI圈主流的LLM进行的基准测试结果。
他的测试偏向代码生成方面。
结果令人大为不震撼,又大为震撼。

意料之内的是,GPT-4毫无疑问霸榜,摘得第一。
意料之外的是,OpenAI的text-davinci-003异军突起,拿了个第二。
Plappert表示,text-davinci-003堪称一个「宝藏」模型。
为震撼。
[外链图片转存中…(img-r0dgKxEx-1688477926544)]
意料之内的是,GPT-4毫无疑问霸榜,摘得第一。
意料之外的是,OpenAI的text-davinci-003异军突起,拿了个第二。
Plappert表示,text-davinci-003堪称一个「宝藏」模型。
而耳熟能详的LLaMA在代码生成方面却并不出色。