文章目录
- 2022
- TransCrowd: weakly-supervised crowd counting with transformers
- An End-to-End Transformer Model for Crowd Localization
- 参考
2022
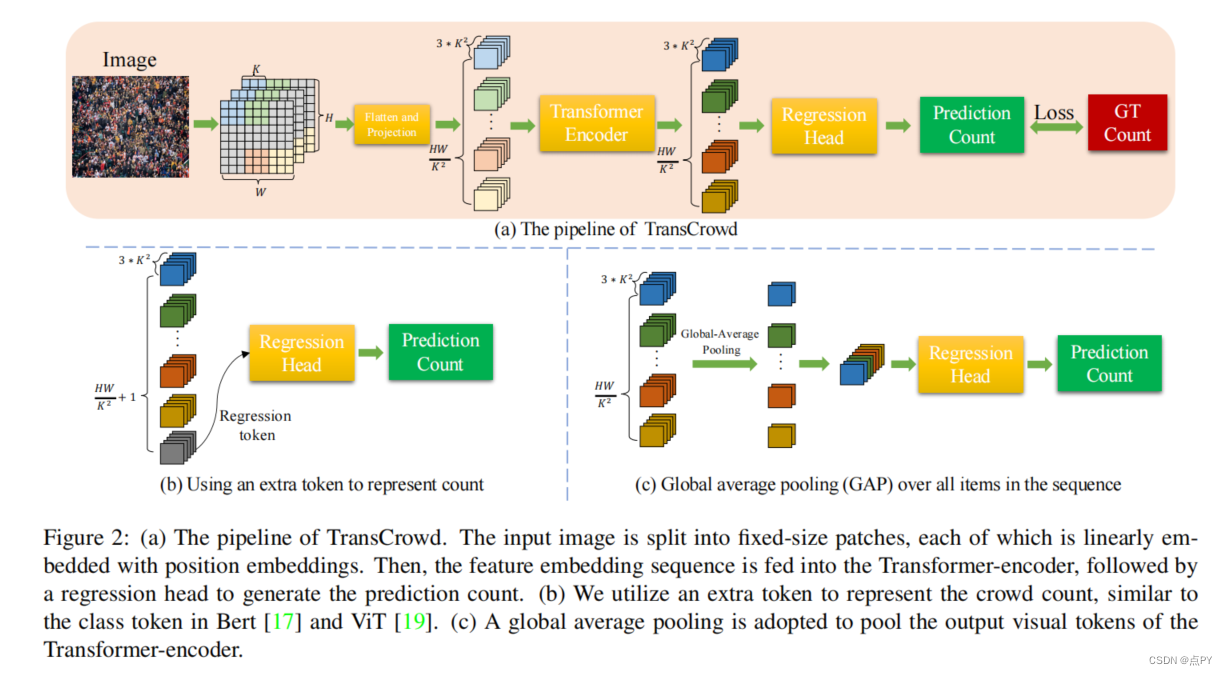
TransCrowd: weakly-supervised crowd counting with transformers
code: https://github.com/dk-liang/TransCrowd
摘要:主流的人群计数方法通常利用卷积神经网络(CNN)来回归密度图,需要点级的注释。然而,用一个点来注释每个人是一个昂贵而费力的过程。在测试阶段,不考虑点级注释来评估计数的准确性,这意味着点级注释是冗余的。因此,我们希望开发仅依赖于计数级注释的弱监督计数方法,这是一种更经济的标记方法。目前的弱监督计数方法采用CNN通过图像计数范式回归人群总数。然而,对于上下文建模的接受域有限是这些基于弱监督的基于cnn的方法的内在局限性。因此,这些方法不能达到令人满意的性能,在实际字的应用有限。变压器是自然语言处理中一种流行的序列-序列预测模型,它包含一个全局接受域。在本文中,我们提出了变换群集,它从基于变压器的序列到计数的角度重新提出了弱监督群体计数问题。我们观察到,所提出的跨群体算法利用变压器的自注意机制可以有效地提取语义群体信息。据我们所知,这是第一个采用纯变压器进行人群计数研究的工作。在5个基准数据集上的实验表明,与所有基于弱监督的ncrowdcnn的性能,与一些流行的全监督计数方法相比,具有较高的计数性能。

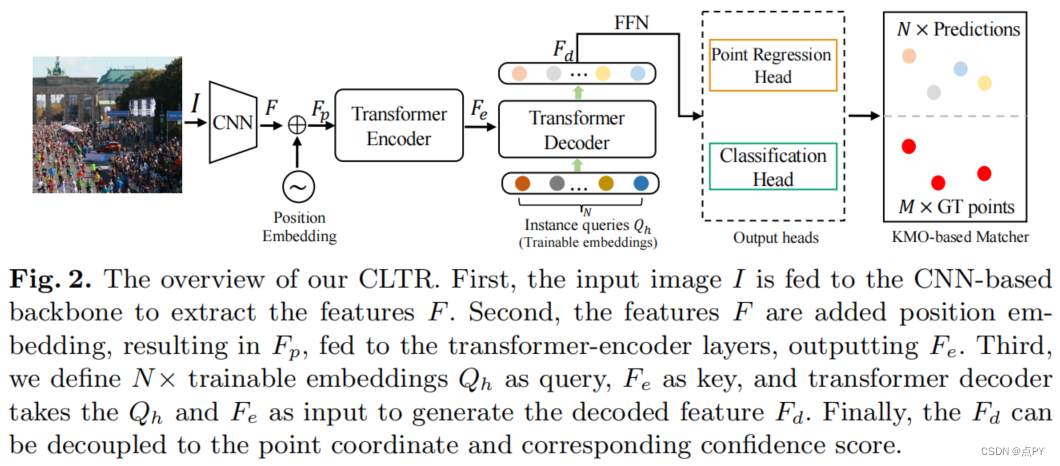
An End-to-End Transformer Model for Crowd Localization
code: https://github.com/dk-liang/CLTR
摘要: 人群定位,即预测头部位置,是一项比简单的计数更实用、更高级的任务。现有的方法采用伪边界框或预先设计的定位图,依靠复杂的后处理来获得头部位置。在本文中,我们提出了一个优雅的、端到端人群本地化转换器,名为CLTR,它解决了基于回归的范式中的任务。该方法将人群定位视为一个直接集预测问题,将提取的特征和可训练的嵌入作为变压器-解码器的输入。为了减少模糊点,产生更合理的匹配结果,我们引入了一个基于KMO的匈牙利匹配器,它采用附近的上下文作为辅助匹配代价。在不同数据设置下的5个数据集上进行的大量实验表明了该方法的有效性。特别是,该方法在NWPU-Crowd、UCF-QNRF和上海科技A部分数据集上取得了最好的定位性能。
参考
https://github.com/gjy3035/Awesome-Crowd-Counting/blob/master/src/Transformer.md







![[github-100天机器学习]day2 simple linear regression](https://img-blog.csdnimg.cn/740f485a014f4d4781a83af908cd3e66.png)